

Welcome back to this 2nd part of our blog where we want to share some basic technical information about the SAS Viya platform on Red Hat OpenShift platform. While we have been discussing the reference architecture and details on the deployment process in the first part of the blog, we now want to dive deeper into security and storage topics, which are at the core of any deployment.
Security Considerations
As discussed in the first part of this blog, the SAS Viya analytical platform is not just a single application, but a suite of integrated applications. While most services are microservices following the 12-factor-app pattern, SAS also uses compute engines and stateful services which are essential for the platform. SAS integrates with the standard security approach that applies to OpenShift, namely the use of Security Context Constraints (SCCs).
Following Red Hat guidelines, most SAS Viya platform pods are deployed in the restricted SCC, which applies the highest level of security. However, there are a few exceptions: two other OpenShift predefined SCCs (nonroot and hostmount-anyuid) may be required for specific SAS services depending on use case. In addition, a few custom SCCs are either required by essential SAS Viya platform components, such as the CAS server, or associated with specific SAS offerings that might be included in your software order.
All custom SCCs which might be applied to the SAS deployment are shipped as part of the SAS deployment assets collection of files and templates, so there is no need to create them manually. As OpenShift administrators often want to review the content of these SCCs, the following command might be helpful to quickly see which custom SCCs are available and where they can be found:
# change to the top-level folder of the deployment
# directory and list all available SCCs
cd $deploy
find ./sas-bases -name "*scc*.yaml"
NOTE: You must have cluster-admin privileges to manage SCCs.
A SCC acts like a request for privileges from the OpenShift API. In an OpenShift environment, each Kubernetes pod starts up with an association with a specific SCC, which limits the privileges that the pod can request.
An administrator configures each pod to run with a certain SCC by granting the corresponding service account for that pod access to the SCC. For example, if pod A requires its own SCC, an administrator must grant access to that SCC for the service account under which pod A is launched.
Use the OpenShift CLI tool (oc) to apply the SCC, and to assign the SCC to a service account. Refer to the SCC example files provided in the $deploy/sas-bases/examples folder.
- Apply the SCC with the following command:
oc apply -f example-scc.yaml
- Bind the SCC to the service account with the following command:
oc -n <name-of-namespace> adm policy add-scc-to-user <scc name> -z <service account name>
For additional details about SCCs, please see the following:
- For a full list and description of the required SCCs, see Security Context Constraints and Service Accounts in the SAS Viya Platform Deployment Guide.
- For SCC types, see SCCs and Pod Service Accounts in System Requirements for the SAS Viya Platform.
- For more information for each SCC, see the
README.mdfile (for Markdown format) below the$deploy/sas-bases/examplesfolder or below$deploy/sas-bases/docs(for HTML format). - For more information about applying SCCs with OpenShift, see the Red Hat blog Managing SCCs in OpenShift.
The following table gives an overview of all cases where a custom SCC (or an SCC other than restricted) is used:

* Every deployment on OpenShift must apply one of the SCCs for the CAS server. By default, in a greenfield SAS Viya deployment for a new customer, we expect CAS to use cloud native storage and not need host launch capabilities. So, at a minimum, the cas-server-scc SCC would be applied.
** These are standard SCCs defined by OpenShift.
*** The OpenSearch team recommends to change the vm.max_map_count kernel parameter. The SAS deployment uses an init container to implement this change which requires elevated privileges. Once the init-container terminates, the privileges are dropped and the runtime container uses the restricted SCC. It is possible to disable the mmap support completely, however this is discouraged since doing so will negatively impact performance and may result in out of memory exceptions.
OPENSEARCH SYSCTL MACHINECONFIG
If privileged containers are not allowed in your environment, a MachineConfig can be used to set the vm.max_map_count kernel parameter for OpenSearch, as an alternative to using the sas-opendistro SCC with the init container. All nodes that run workloads in the stateful workload class are affected by this requirement.
Perform the following steps; see Adding kernel arguments to nodes in the OpenShift documentation.
List existing
MachineConfigobjects for your OpenShift Container Platform cluster to determine how to label your machine config:oc get machineconfig
Create a
MachineConfigobject file that identifies the kernel argument (for example,05-worker-kernelarg-vm.max_map_count.yaml)apiVersion: machineconfiguration.openshift.io/v1
kind: MachineConfig
metadata:
labels:
machineconfiguration.openshift.io/role: worker
name: 05-worker-kernelarg-vmmaxmapcount
spec:
kernelArguments:
- vm.max_map_count=262144Create the new machine config:
oc create -f 05-worker-kernelarg-vm.max_map_count.yaml
Check the machine configs to see that the new one was added:
oc get machineconfig
Check the nodes:
oc get nodes
You can see that scheduling on each worker node is disabled as the change is being applied.
Check that the kernel argument was applied by going to one of the worker nodes and verifying with the
sysctlcommand, or by listing the kernel command line arguments in the/proc/cmdlinefile on the host:oc debug node/vsphere-k685x-worker-4kdtl
sysctl vm.max_map_count
exitExample output
Starting pod/vsphere-k685x-worker-4kdtl-debug ...
To use host binaries, run 'chroot /host'
sh-4.2\# sysctl vm.max_map_count
vm.max_map_count=262144
sh-4.2# exitIf listing the
/proc/cmdlinefile, you should see thevm.max_map_count=262144argument added to the other kernel arguments.
OpenShift Machine Management
You can use machine management to flexibly work with underlying infrastructure of cloud platforms like vSphere to manage the OpenShift Container Platform cluster. You can control the cluster and perform auto-scaling, such as scaling up and down the cluster based on specific workload policies.
The OpenShift Container Platform cluster can horizontally scale up and down when the load increases or decreases. It is important to have a cluster that adapts to changing workloads.
Machine management is implemented as a CRD object that defines a new unique object Kind in the cluster and enables the Kubernetes API server to handle the object’s entire lifecycle. The Machine API Operator provisions the following resources: Machine, MachineSet, ClusterAutoScaler, MachineAutoScaler, and MachineHealthCheck.
NOTE: You must have cluster-admin privileges to perform machine management.
As a cluster administrator, you can perform the following tasks with compute machine sets:
- Create a compute machine set on vSphere.
- Manually scale a compute machine set by adding or removing a machine from the compute machine set
- Modify a compute machine set through the
MachineSetYAML configuration file. - Delete a machine.
- Create infrastructure compute machine sets.
- Configure and deploy a machine health check to automatically fix damaged machines in a machine pool
Red Hat OpenShift provides machine management as an automation method for managing the underlying cloud platform through a machine object, which is a subset of the node object. This allows for the definition of compute machine sets that can be sized and matched to workload classes, and scaled to meet workload demand.
1. Workload Placement
Part 1 of this blog detailed the SAS Viya workload classes and node pools that can be used to place the workloads on appropriate nodes within the cluster. The workload placement configuration, from the SAS Viya Platform Operations Guide, provides the node labels and taints that can be included within the compute MachineSet definitions, so they are preconfigured at compute Machine creation time.
Refer to the ClusterAutoScaler, MachineAutoScaler and MachineSet definition examples provided in the Example Machine Management YAML Files section below.
MachineSet
To deploy the machine set, you create an instance of the MachineSet resource.
Create a MachineSet definition YAML file for each SAS Viya workload class needed.
Create a YAML file for the
MachineSetresource that contains the customized resource definition for your selected SAS Viya workload class, using the examples mentioned earlier. Ensure that you set the<clusterID>and<role>parameter values that apply to your environment.If you are not sure which value to set for a specific field, you can check an existing machine set from your cluster:
oc get machinesets -n openshift-machine-api
Check values of a specific machine set:
oc get machineset <machineset_name> -n openshift-machine-api -o yaml
Create the new
MachineSetCR:oc create -f cas-smp-machineset.yaml
View the list of machine sets:
oc get machineset -n openshift-machine-api
When the new machine set is available, the DESIRED and CURRENT values match. If the machine set is not available, wait a few minutes and run the command again.
For more information about defining MachineSets, see Creating a compute machine set on vSphere in the OpenShift documentation.
2. Autoscaling
Autoscale your cluster to ensure flexibility to changing workloads. To autoscale your OpenShift Container Platform cluster, you must first deploy a cluster autoscaler, and then deploy a machine autoscaler for each compute machine set.
- The cluster autoscaler increases and decreases the size of the cluster based on deployment needs.
- The machine autoscaler adjusts the number of machines in the machine sets that you deploy in your OpenShift Container Platform cluster.
ClusterAutoScaler
Applying autoscaling to an OpenShift Container Platform cluster involves deploying a cluster autoscaler and then deploying machine autoscalers for each machine type in your cluster.
To deploy the cluster autoscaler, you create an instance of the ClusterAutoscaler resource.
Create a YAML file for the
ClusterAutoscalerresource that contains the customized resource definition (for example,clusterautoscaler.yaml).Create the resource in the cluster:
oc create -f clusterautoscaler.yaml
IMPORTANT: Be sure that the maxNodesTotal value in the ClusterAutoscaler resource definition that you create is large enough to account for the total possible number of machines in your cluster. This value must encompass the number of control plane machines and the possible number of compute machines that you might scale to across all machine sets.
NOTE: By default, when the cluster autoscaler removes a node, it does not cordon the node when draining the pods from the node. You can configure the cluster autoscaler to cordon the node before draining and moving the pods by setting the spec.scaleDown.cordonNodeBeforeTerminating parameter to enabled in the ClusterAutoscaler CR. This parameter is disabled by default. It is recommended to enable this parameter in production clusters because of the risk of data loss, application errors, pods getting stuck in the terminating state, or other issues if the cluster autoscaler removes a node when the parameter is disabled. Leaving this parameter disabled, which can result in faster node removal, might be appropriate in clusters that run only stateless workloads.
For more information about defining the ClusterAutoscaler resource definition, see Applying autoscaling to an OpenShift Container Platform cluster in the OpenShift documentation.
MachineAutoScaler
To deploy the machine autoscaler, you create an instance of the MachineAutoscaler resource.
Create a YAML file for the
MachineAutoscalerresource that contains the customized resource definition (for example,cas-mpp-autoscaler.yaml).Create the resource in the cluster:
oc create -f cas-mpp-autoscaler.yaml
For more information about defining the MachineAutoScaler resource definition, see Configuring the machine autoscalers in the OpenShift documentation.
Example Machine Management YAML Files
Example YAML files for the ClusterAutoScaler, MachineAutoScaler and MachineSet definitions are available from the following repo: https://github.com/redhat-gpst/sas-viya-openshift
The following table provides the details about the example MachineAutoScaler and MachineSetdefinition files provided for each of the SAS Viya Workload Classes, based on the minimum sizing recommendations for OpenShift.
| Workload Class | Example MachineSet file | Example MachineAutoScaler file |
|---|---|---|
CAS workloads (SMP) | ||
CAS workloads (MPP) | cas-mpp-machineset.yaml | cas-mpp-autoscaler.yaml |
| Connect workloads | connect-machineset.yaml | connect-autoscaler.yaml |
| Compute workloads | compute-machineset.yaml | compute-autoscaler.yaml |
| Stateful workloads | stateful-machineset.yaml | stateful-autoscaler.yaml |
| Stateless workloads | stateless-machineset.yaml | stateless-autoscaler.yaml |
SAS Viya Storage Requirements
Before we close off this blog series, we would like to spend a few words on the storage requirements of SAS Viya. If you’ve made it so far, you might already expect that a software stack like SAS Viya, which focuses on Data Management and Analytics, comes with the need for persistent (and ephemeral) storage.
This is one of the most important topics to be discussed when preparing the deployment on OpenShift, as choosing a suitable storage configuration usually makes a key difference for the user experience. SAS compute sessions have always been heavily dependent on good disk I/O performance and this requirement has not changed with the latest SAS platform.
Many SAS Viya components require highly performant storage, and SAS generally recommends a sequential I/O bandwidth of 90-120 MB per second, per physical CPU core. Normally this would be achieved by utilizing a storage system that is backed by using SSD or NVMe disks. SAS provides an automated utility script -- rhel_iotest.sh, that uses UNIX/Linux dd commands to measure the I/O throughput of a file system in a Red Hat Enterprise Linux (RHEL) environment. This script can be used to compare the measured throughput of the storage in your environment to the recommendation. For more information, refer to How to run the rhel_iotest.sh script on an OpenShift cluster.
Since this is a rather complex topic with lots of facets, here's a picture which hopefully helps you to keep your orientation for the rest of this section:
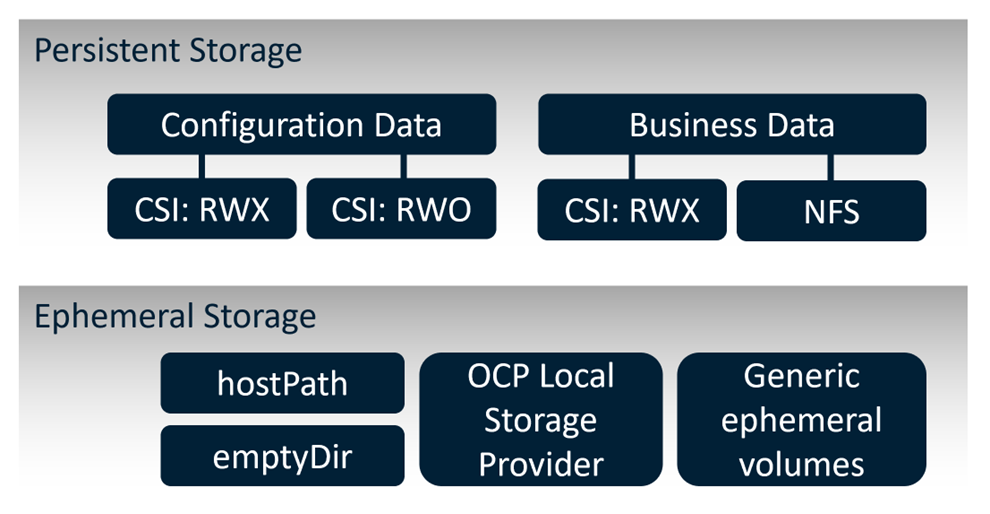
Figure 1 summarizes the key storage requirements for SAS Viya, using persistent storage and ephemeral storage.
Persistent storage, is required for two purposes with SAS Viya:
Stateful services configuration data (Consul, Redis, etc.). his storage requirement is mandatory for the deployment; made available through the Kubernetes CSI API for persistent volumes in both RWO and RWX access modes.
File-based business data. Optional, but it’s a very common situation that existing file shares with business data (SAS datasets, CSV files, Excel etc.) need to be made available to the SAS compute pods. These collections of files are either accessed through the CSI API (in RWX mode) or could also be mounted directly to the pods using a direct NFS configuration, etc. It’s important to state that poor disk I/O performance can turn into a real bottleneck for users of the Viya platform.
Dynamic volume provisioning is provided by the in-tree and CSI vSphere storage provider for OpenShift on VMware vSphere. OpenShift Data Foundation (ODF) provides added flexibility as it can also provide file, block and object storage with both RWO and RWX access modes.
Ephemeral storage is a major requirement for the SAS compute engine and the CAS server. Both engines heavily rely on fast storage for storing intermediate data which is no longer needed after the session has ended. Like what was said above, I/O performance is crucial for this storage to prevent it from turning into a bottleneck for users.
There are a few technical options available to provide this ephemeral storage, using Local storage on the worker node:
hostPathconfiguration. While it would be easy to configure, this is often rejected for security reasons.OpenShift Local Storage Operator. If you’re interested in learning more about this option, see the SAS blog SAS Viya Temporary Storage on Red Hat OpenShift – Part 1.
emptyDir. This seems to be a tempting option at first, and it certainly can be used for test environments, but it is strictly not recommended for production or near-production clusters.Generic ephemeral volumes. This is a new configuration option introduced with OpenShift 4.11 / Kubernetes 1.23. This configuration uses the
volumeClaimTemplatekeyword in pod manifests to create per-pod volumes “on-the-spot".
There are a couple of SAS blogs available that describe how to configure ephemeral general volumes for the SAS compute engine and the CAS server:
Cloud Native Storage Integration
In addition to the storage solutions mentioned in this section, there are additional CSI Driver Operators available for storage solutions that are suitable for use with OpenShift and SAS Viya. For more information, see the Red Hat Ecosystem Catalog. The assumption is that whatever solution is used, it would need to meet the performance and volume access mode requirements for SAS Viya mentioned in the previous section.
OpenShift on VMware vSphere supports dynamic provisioning and static provisioning of VMware vSphere volumes with the in-tree and the Container Storage Interface (CSI) vSphere storage provider.
If the underlying vSphere environment supports the vSAN file service, then the vSphere CSI Driver Operator installed by OpenShift supports provisioning of ReadWriteMany (RWX) volumes. If vSAN file service is not configured, then ReadWriteOnce (RWO) is the only access mode available.
Red Hat OpenShift Data Foundation (ODF) is a persistent software-defined, container-native storage solution that’s integrated with and optimized for Red Hat OpenShift Container Platform. ODF is now included as part of OpenShift Platform Plus. In addition to Red Hat OpenShift Container Platform, OpenShift Platform Plus also includes Red Hat OpenShift Advanced Cluster Management for Kubernetes, Red Hat OpenShift Advanced Cluster Security for Kubernetes, Red Hat Quay container registry platform, and OpenShift Data Foundation for persistent data services.
Deployed, consumed, and managed through the Red Hat OpenShift administrator console, the ODF platform is built on Ceph petabyte-scale persistent cloud storage, the Rook Kubernetes storage operator, and NooBaa multicloud object gateway technology supporting file, block, and object storage. ODF runs anywhere that Red Hat OpenShift does -- on-premises or in hybrid cloud environments. Dynamic, stateful, and highly available container-native storage can be provisioned and deprovisioned on demand with OpenShift Data Foundation.
Deploying ODF with OpenShift on VMware VMs can use dynamic storage devices from the VMware vSphere storage provider, and provides you with the option to create the internal cluster storage resources during deployment. This results in the internal provisioning of the base services, and the additional storage classes available to applications. ODF provides ReadWriteOnce RWO (file, block) and ReadWriteMany RWX (shared file, shared block) volume modes.
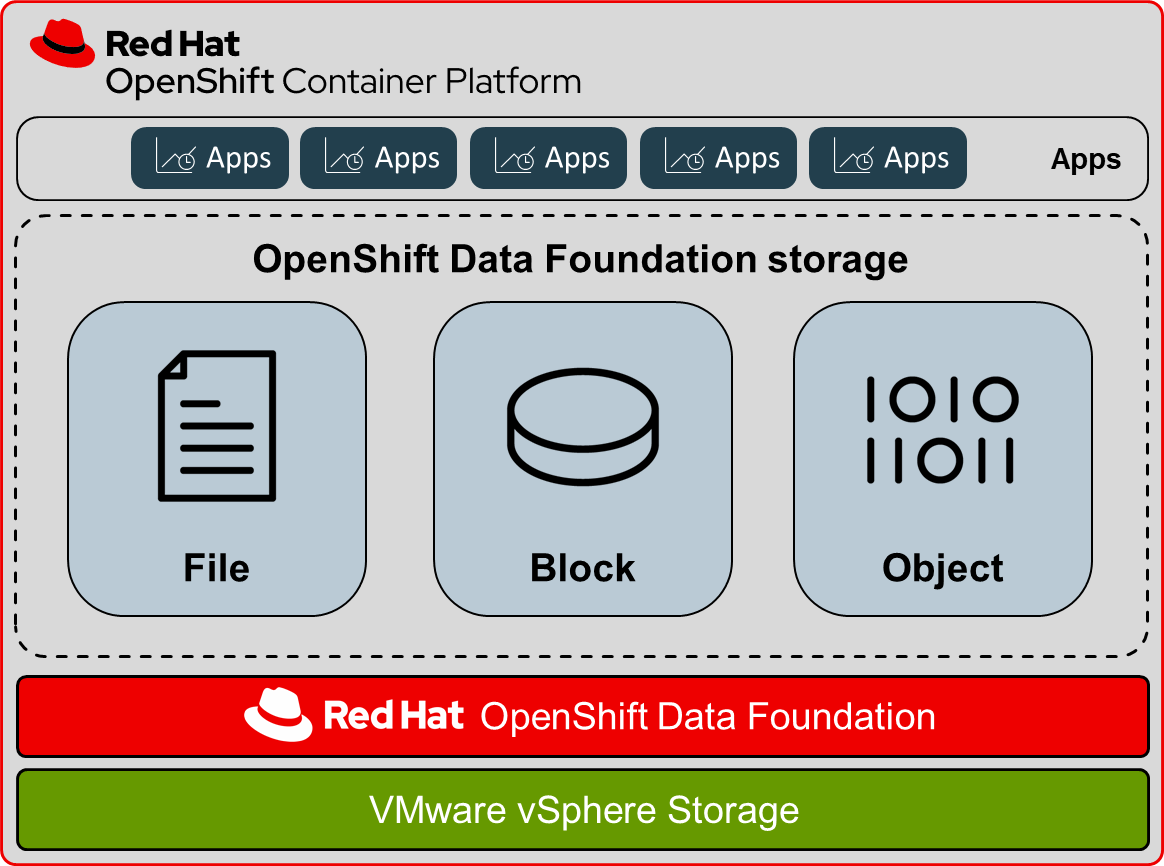
The following table summarizes two of the persistent storage solutions that may be used with OpenShift when deployed on VMware vSphere, including their supported volume access modes.
| Volume Plugins | ReadWriteOnce (RWO) | ReadWriteMany (RWX) |
|---|---|---|
| VMware vSphere |

|
* |
| Red Hat OpenShift Data Foundation |
|
|
* If the underlying vSphere environment supports the vSAN file service, then the vSphere Container Storage Interface (CSI) Driver Operator installed by OpenShift Container Platform supports provisioning of ReadWriteMany (RWX) volumes. If you do not have vSAN file service configured, and you request RWX, the volume fails to get created and an error is logged. For more information, see VMware vSphere CSI Driver Operator and ReadWriteMany vSphere volume support in the OpenShift documentation.
Conclusion
With this we’re coming to the end of our blog series about deploying SAS Viya on the Red Hat OpenShift container platform. In the first installment of the blog, we started with giving an overview, described a reference architecture and discussed the deployment process, while in this part of the blog we focused on security considerations, cluster topology automation and storage requirements.
We hope that you enjoyed reading the blogs and would like to invite you to get in touch with us if you have any questions or feedback.
Sugli autori
Patrick is an Associate Principal Ecosystem Solutions Architect with the Global Solution Architecture team at Red Hat. He joined Red Hat in 2019 and currently works with our OEM and ISV partner ecosystem. Patrick is passionate about creating AI/ML, infrastructure and platform solutions with OpenShift.
Hans has been supporting SAS customers in Germany, Austria and Switzerland as a Presales Consultant and Solutions Architect since he joined SAS in 2002. Currently he is working in an international team of architects and DevOps engineers which takes care of the EMEA region. His work is focused on Enterprise Architecture, Kubernetes and cloud technologies.
Altri risultati simili a questo
Smetti di gestire il passato e inizia a costruire il futuro dell'IT
Dall'inferenza agli agenti: scalabilità dell'IA in azienda con Red Hat AI 3.4
Technically Speaking | Inside open source AI strategy
Technically Speaking | Build a production-ready AI toolbox
Ricerca per canale

Automazione
Novità sull'automazione IT di tecnologie, team e ambienti

Intelligenza artificiale
Aggiornamenti sulle piattaforme che consentono alle aziende di eseguire carichi di lavoro IA ovunque

Hybrid cloud open source
Scopri come affrontare il futuro in modo più agile grazie al cloud ibrido

Sicurezza
Le ultime novità sulle nostre soluzioni per ridurre i rischi nelle tecnologie e negli ambienti

Edge computing
Aggiornamenti sulle piattaforme che semplificano l'operatività edge

Infrastruttura
Le ultime novità sulla piattaforma Linux aziendale leader a livello mondiale

Applicazioni
Approfondimenti sulle nostre soluzioni alle sfide applicative più difficili
Virtualizzazione
Il futuro della virtualizzazione negli ambienti aziendali per i carichi di lavoro on premise o nel cloud