Mentre l'IA diventa un motore per la competitività nazionale, il concetto di IA sovrana, ovvero la capacità di gestire sistemi di IA senza influenze esterne, assume sempre maggiore rilevanza, ma il percorso verso l'adozione è ricco di sfide. Un recente sondaggio sull'adozione dell'IA, condotto su oltre 900 leader IT e ingegneri specializzati, evidenzia un significativo "value gap", mostrando che, nonostante il grande entusiasmo (72%), solo il 7% delle organizzazioni in Europa, Medio Oriente e Africa (EMEA) sta ottenendo risultati.
Il sondaggio evidenzia che la privacy dei dati e i “silos” infrastrutturali stanno paralizzando le iniziative di sviluppo dell'IA. Di conseguenza, l'IA sovrana si è rapidamente trasformata da una "sfida cloud" teorica in una necessità pratica. Mitigando i rischi specifici identificati nel sondaggio Red Hat, l'IA sovrana consente alle aziende regolamentate di passare con sicurezza dalla fase pilota alla produzione senza compromettere i seguenti aspetti.
- Conformità normativa: adesione a normative rigorose come il Regolamento generale sulla protezione dei dati (GDPR), l'EU AI Act e le leggi sulla residenza dei dati, che impongono di conservare i dati dei cittadini entro confini specifici.
- Resilienza operativa: la capacità di continuare a operare in situazioni di instabilità geopolitica o di disconnessione dalla rete Internet globale.
- Autonomia strategica: le organizzazioni evitano il vendor lock-in e mantengono il pieno controllo sulla proprietà intellettuale, come modelli e pesi, generata da dati sensibili.
Red Hat OpenShift AI fornisce una base per questa sovranità, consentendo alle organizzazioni di creare una factory di IA "air-gap" mantenendo il controllo assoluto su sicurezza, dati, modelli e risultati.
In questo articolo esaminiamo esempi specifici di sfide relative all'IA sovrana che i nostri clienti si trovano ad affrontare, astraiamo i temi principali che devono essere affrontati e proponiamo una soluzione a questi problemi.
La storia di un utente: il dilemma dell'indipendenza dell'IA
Il protagonista: Dott. Aris (personaggio basato su sfide reali dei clienti), chief data officer presso il Ministero della Salute di una nazione europea di medie dimensioni.
La sfida: il Ministero possiede una miniera d'oro di dati, contenente decenni di cartelle cliniche anonimizzate, sequenze genomiche e storia epidemiologica locale. Dott. Aris vuole creare un "National Health LLM" per aiutare i medici a diagnosticare malattie rare specifiche della loro popolazione.
Ancora più importante, il Ministero si trova ad affrontare un problema di "shadow AI". Ricercatori frustrati caricano segretamente snippet anonimi su LLM pubblici per portare a termine il lavoro, rischiando così fughe di dati. Hanno bisogno di una piattaforma interna autorizzata, completamente sicura e facile da usare tanto quanto il cloud pubblico.
Il conflitto:
- la trappola del cloud. I principali provider di IA che offrono Models-as-a-Service (MaaS) richiedono che i dati sensibili vengano caricati su cloud pubblici con sede negli Stati Uniti. Ciò può violare il Regolamento generale sulla protezione dei dati (GDPR), le leggi sulla residenza dei dati e i protocolli di sicurezza nazionali.
- L'incubo del fai da te. Il Dott. Aris tenta di creare la piattaforma da zero. Il suo team viene rapidamente paralizzato dal caos operativo dovuto alla gestione degli accessi al cluster da 500 GPU, generando una costante contesa per le risorse e in attese indefinite per gli esperimenti critici, mentre l'hardware riservato rimane inattivo.
La soluzione: il Ministero crea una piattaforma di IA sovrana basata su OpenShift AI, utilizzando anche Kubeflow e Feast.
- Il cambiamento: invece di fare affidamento su API cloud proprietarie, il team del dott. Aris crea una "fabbrica di modelli" sulla propria infrastruttura protetta e air-gap. OpenShift AI, che include i componenti Kubeflow, astrae l'hardware del cluster GPU, consentendo al team di addestrare modelli di grandi dimensioni senza inviare un singolo byte oltre confine. Feast aiuta a centralizzare la gestione delle feature tra addestramento e inferenza, in modo che le funzionalità che alimentano i modelli siano definite in modo coerente, consentendo governance e tracciabilità.
- Il risultato: un data scientist invia semplicemente una richiesta di addestramento e il sistema avvia automaticamente un cluster distribuito, recupera le feature da Feast, addestra il modello e lo sopprime, il tutto all'interno del data center nazionale air-gap. Il Dott. Aris raggiunge l'autonomia dell'IA utilizzando una piattaforma di IA scalabile e disconnessa secondo i termini del suo paese.
I tre pilastri dell'IA sovrana
Per passare da una "colonia digitale" (una nazione o comunità che fa così tanto affidamento su un'infrastruttura tecnologica straniera da perdere il controllo sulla propria economia digitale, sui dati e sullo sviluppo futuro) alla "sovranità digitale", una nazione deve controllare tre livelli chiave dello stack tecnologico dell'IA.
Sovranità tecnica (le basi)
Principio: la sovranità impone una catena di custodia trasparente e resilienza contro l'uso improprio della supply chain. Adottando un livello di piattaforma indipendente dall'hardware, le nazioni possono ottimizzare i propri progressi nell'IA attraverso una strategia multi-vendor, in modo da preservare la propria autonomia strategica indipendentemente dai cambiamenti nella supply chain globale. La piattaforma sovrana deve disaccoppiare il software dall'hardware e combinare la rigida proprietà dell'infrastruttura con la flessibilità necessaria per adattarsi alla disponibilità del mercato. Aderendo agli standard open source, le capacità di IA di un'organizzazione possono essere ispezionate, verificate e gestite indipendentemente dalla roadmap di un singolo fornitore o dal monopolio dell'hardware, mantenendo la piena autorità sulla continuità del servizio.
Convalida: il sondaggio Red Hat sull'IA conferma che il 92% dei leader IT considera l'open source enterprise fondamentale per la propria strategia di IA. Offre la coerenza e la trasparenza necessarie per controllare la supply chain dell'IA.
Sovranità dei dati (l'asset)
Principio: la gravità dei dati è assoluta. I dati sensibili devono risiedere su supporti di storage fisicamente situati all'interno del perimetro sovrano ed essere soggetti esclusivamente alle leggi locali. La sfida consiste nel fornire ai data scientist la facilità di selezione e recupero dei dati che si trova nel cloud, limitando al contempo fisicamente il movimento dei dati a una rete interna sicura.
Sovranità operativa (il controllo)
Principio: il "piano di controllo" deve essere locale. I workflow critici non possono fare affidamento su una console Software-as-a-Service (SaaS) ospitata in un altro continente per gestire le risorse di elaborazione o l'accesso degli utenti. Una piattaforma sovrana richiede un piano di controllo autonomo che gestisca l'Identity Access Management (IAM) e l'orchestrazione delle risorse interamente all'interno del perimetro locale.
Soluzione tecnica
La nostra soluzione si basa su un'architettura a livelli in cui Red Hat AI funge da piattaforma sovrana unificante, orchestrando le funzionalità di addestramento di Kubeflow e la gestione dei dati di Feast.
Questa soluzione si basa su standard open source, in particolare Red Hat OpenShift, che fornisce una base Kubernetes, e il progetto Kubeflow. Utilizzando i componenti inclusi (Model Registry, KServe, Pipeline and Training e Feast per il feature serving), le organizzazioni possono mantenere la piena proprietà del proprio stack tecnologico. Questa trasparenza consente alle organizzazioni di ispezionare il codice alla ricerca di vulnerabilità e di contribuire direttamente alla roadmap del progetto. Il nostro obiettivo qui è illustrare come Kubeflow Trainer e Feast supportano questi requisiti di sovranità.
Il blueprint aperto per la sovranità dell'IA: Red Hat AI
Per raggiungere una vera sovranità, la piattaforma alla base deve essere affidabile tanto quanto i dati che elabora. Red Hat AI offre una base consolidata di livello enterprise che soddisfa le esigenze specifiche delle factory di IA protette e autonome.
Red Hat AI garantisce la completa indipendenza dell'infrastruttura. Supporta la distribuzione su bare metal air-gap, cloud privati o partner di cloud sovrano affidabili. Ciò consente a un'organizzazione di scegliere i propri fornitori di hardware (ad esempio, NVIDIA, Intel, AMD) e di mantenere la piena autorità sulla continuità del servizio.
- Supply chain del software affidabile: la sovranità inizia dalla fonte. Red Hat AI offre un catalogo di strumenti di IA certificati, sottoposti a scansione delle vulnerabilità e firmati digitalmente, in modo che il software in esecuzione all'interno del perimetro air-gap sia privo di vulnerabilità note, un requisito fondamentale per la sicurezza nazionale.
- Piano di controllo MLOps unificato: la piattaforma consolida lo stack tecnologico di IA frammentato in un'unica interfaccia. Aiuta a gestire le complesse dipendenze tra il sistema operativo (Red Hat Enterprise Linux), l'hardware (GPU) e il livello applicativo (Kubeflow/Feast), consentendo ai data scientist di concentrarsi sulla modellazione anziché sull'infrastruttura.
- Astrazione hardware scalabile: Indipendentemente dal fatto che venga eseguito su rack bare metal o su un cloud privato virtualizzato, Red Hat AI astrae le risorse fisiche. Utilizza operatori per ottimizzare ed esporre automaticamente hardware specializzato, come le GPU di un supercomputer nazionale, consentendo una forte multi-tenancy senza esporre l'utente alla complessità.
Con questa base sicura, ci affidiamo a Red Hat OpenShift AI. In quanto piattaforma di IA distribuita all'interno del portfolio Red Hat AI, OpenShift AI consente alle organizzazioni di creare, ottimizzare, distribuire e gestire modelli e applicazioni di IA. Agisce come il sistema nervoso centrale che orchestra tre funzionalità critiche integrate: un motore di addestramento ad alte prestazioni, un livello di gestione dei dati preciso e un framework ottimizzato per il model serving.
Calcolo integrato: Kubeflow Trainer
Per una factory di IA sovrana, l'utilizzo di un'infrastruttura cloud pubblica spesso non è un'opzione praticabile, a causa dei severi requisiti di controllo e residenza dei dati. Per mantenere una vera sovranità, è necessario possedere e gestire l'hardware. Tuttavia, questa indipendenza comporta la responsabilità di gestirlo efficacemente, compresa la pianificazione di processi distribuiti complessi, la gestione dei guasti dei nodi e l'utilizzo efficiente di risorse di alto valore per il calcolo a prestazioni elevate.
Kubeflow Trainer (un componente di OpenShift AI) risolve questo paradosso operativo. Offre la facilità d'uso del cloud native alla tua infrastruttura privata, fungendo da motore ad alte prestazioni che semplifica l’addestramento distribuito su Kubernetes. Sostituisce i workflow frammentati con l'API TrainJob unificata, consentendo ai data scientist di ridimensionare framework come PyTorch e TensorFlow senza riscrivere codice infrastrutturale complesso.
- Semplificazione: grazie all'astrazione dell'infrastruttura sovrana alla base, fornisce un'unica interfaccia coerente per attività di addestramento distribuite su vasta scala.
- Affidabilità: Basata sull'API JobSet di Kubernetes, garantisce che l'intero gruppo sia gestito correttamente (pianificazione completa) qualora si verifichi un guasto a un nodo in un cluster di addestramento distribuito. Questo contribuisce a ridurre lo spreco di risorse, poiché i processi di addestramento su larga scala vengono eseguiti completamente oppure riavviati in modo netto.
- Integrazione: si integra nativamente con Kueue (parte dello stack di pianificazione di OpenShift AI) per gestire le quote dei processi e l'accodamento, allocando dinamicamente le risorse GPU dal pool di nodi OpenShift sottostante, in modo da utilizzare le risorse di elaborazione nazionali nel modo più efficiente possibile.
Dati sovrani: Feast Feature Store
Sebbene una reale sovranità dei dati richieda una strategia completa, è necessario un componente specializzato per colmare il divario tra i dati non elaborati e l'utilizzo dei modelli. A complemento del motore di elaborazione, Feast funge da "memoria" della soluzione. In esecuzione su OpenShift, Feast disaccoppia il modello dall'infrastruttura dei dati non elaborati per migliorare la conformità e la riproducibilità.
Feast gestisce la correttezza "point-in-time", in modo che il modello venga addestrato esattamente in base ai dati disponibili in un momento storico specifico, prevenendo la perdita di dati e consentendo la piena verificabilità.
- Offline store (ad es. MinIO): si connette in modo sicuro all'object store air-gap compatibile con S3 per gestire i dati storici ad alta velocità destinati all’addestramento.
- Online store (ad es. Redis): gestisce le funzionalità a bassa latenza per l'inferenza, in modo che le decisioni vengano prese in tempo reale all'interno del perimetro sovrano.
- Feature registry: fornisce un'unica fonte di riferimento per le definizioni delle funzionalità, in modo che le metriche critiche (ad esempio, "Patient Age") vengano calcolate in modo identico da ogni data scientist sulla piattaforma, mantenendo l'integrità dell'intelligence sovrana.
Completamento del ciclo di vita: distribuzione di modelli sovrani
La vera sovranità va oltre la formazione e deve comprendere l'intero ciclo di vita di MLOps. Una volta addestrato da Kubeflow, un modello deve essere distribuito per elaborare i dati in tempo reale senza mai uscire dal perimetro di sicurezza.
OpenShift AI chiude questo ciclo con funzionalità di model serving integrate. Sfruttando strumenti come KServe, vLLM e il supporto llm-d per l'inferenza distribuita all'interno della piattaforma, le organizzazioni possono distribuire immediatamente gli artefatti del modello nello stesso cluster sovrano air-gap in cui sono stati addestrati. Ciò significa che:
- l’inferenza avviene internamente: con vLLM e llm-d, le query degli utenti (ad esempio, la richiesta di una diagnosi da parte di un medico) e i flussi di dati in tempo reale vengono elaborati in locale, senza mai passare attraverso un'API pubblica. Queste tecnologie ottimizzano l'utilizzo della memoria GPU tramite PagedAttention e consentono di suddividere modelli fondativi di grandi dimensioni su più GPU più piccole. Questa funzionalità ottimizzata rende economicamente e tecnicamente fattibile per le aziende ospitare l'IA generativa (gen AI) ad alte prestazioni sulla propria infrastruttura esistente, evitando la necessità di noleggiare costose API cloud non sovrane.
- la sovranità è unificata: dall'accelerazione hardware al monitoraggio dei modelli, l'intero flusso, Gather (Feast) → Train (Kubeflow) → Serve (OpenShift AI), viene eseguito su un'infrastruttura sovrana, sotto il tuo controllo.
Questa funzionalità collega direttamente la fase di "sviluppo" alle fasi di "integrazione" e "monitoraggio". In questo modo, un'entità regolamentata può eseguire internamente una factory di IA end-to-end di livello mondiale.
Architettura
Il seguente diagramma illustra in che modo OpenShift AI funge da livello di piattaforma sovrana, incapsulando l'orchestrazione, la sicurezza e la gestione dell'hardware necessarie per eseguire Kubeflow e Feast in un ambiente air-gap.
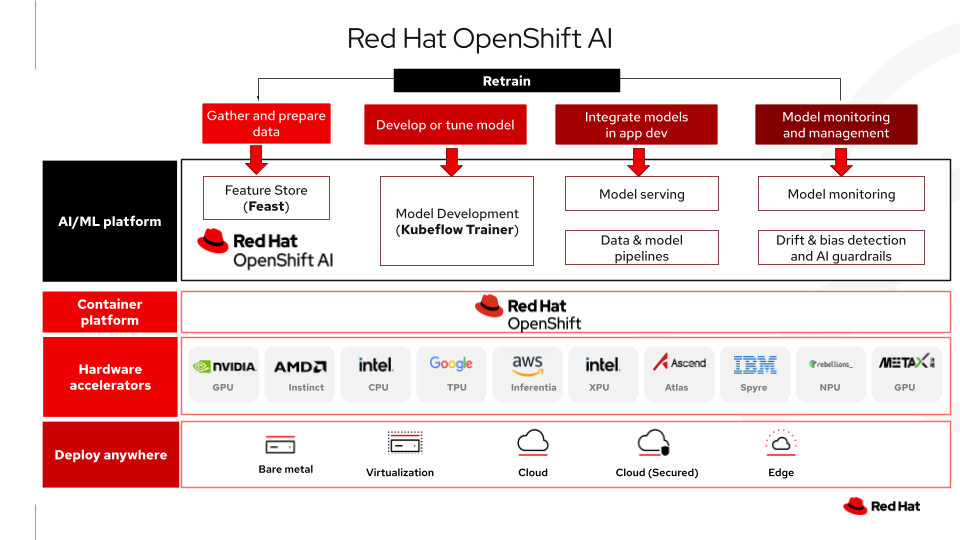
Conclusioni
Per ottenere un'IA sovrana, non è sufficiente disporre di hardware locale, ma è necessaria un'architettura software che rispetti l'importanza dei dati e la complessità dei flussi di lavoro di IA moderni.
Utilizzando tecnologie come Kubeflow Trainer e Feast all'interno di OpenShift AI, le organizzazioni possono creare una factory di IA sovrana con le seguenti caratteristiche.
- Progettata per essere sicura: i dati fluiscono direttamente all'interno del perimetro protetto, dallo storage all'elaborazione, e sono regolati dal controllo degli accessi basato sui ruoli (RBAC) di livello enterprise di Red Hat e dalla conformità facoltativa ai Federal Information Processing Standards (FIPS).
- Scalabile: sfrutta l’efficienza dell’addestramento distribuito su Kubernetes con la gestione automatizzata dell'hardware fornita da OpenShift AI e Kubeflow Trainer.
- Riproducibile: utilizza feature store per supportare il data lineage verificabile.
Questa soluzione consente a nazioni e aziende di sfruttare la potenza dell'IA senza compromettere la propria indipendenza, trasformando la sfida della sovranità in un vantaggio competitivo.
Vuoi creare la tua factory di IA sovrana?
- Aspetti tecnici: vuoi scoprire il codice alla base dell'architettura? Nel blog Red Hat Developer è disponibile un tutorial tecnico dettagliato: Migliora il recupero delle RAG con Feast e Kubeflow Trainer.
- Scopri la piattaforma: se desideri una panoramica a livello generale, visita la pagina di Red Hat OpenShift AI per scoprire come la nostra piattaforma di livello enterprise aiuta le organizzazioni a creare, distribuire e gestire applicazioni di IA sovrane e protette su larga scala.
Risorsa
L'adattabilità enterprise: predisporsi all'IA per essere pronti a un'innovazione radicale
Sull'autore

Umberto Manganiello is a Staff Engineer at Red Hat since 2025. Prior to this, he spent over 15 years as a Principal Architect and Engineer in the Financial and Telecommunications sectors. He specializes in designing high-availability systems that operate at massive scale, leveraging deep expertise in Kubernetes, Kafka, and Cloud modernization. Currently, he applies this architectural discipline to the challenges of MLOps, with a focus on GenAI, OpenShift AI, and Kubeflow, blending cloud-native resilience with AI model training workflows.
Altri risultati simili a questo
Smetti di gestire il passato e inizia a costruire il futuro dell'IT
Dall'inferenza agli agenti: scalabilità dell'IA in azienda con Red Hat AI 3.4
Technically Speaking | Build a production-ready AI toolbox
Technically Speaking | Platform engineering for AI agents
Ricerca per canale

Automazione
Novità sull'automazione IT di tecnologie, team e ambienti

Intelligenza artificiale
Aggiornamenti sulle piattaforme che consentono alle aziende di eseguire carichi di lavoro IA ovunque

Hybrid cloud open source
Scopri come affrontare il futuro in modo più agile grazie al cloud ibrido

Sicurezza
Le ultime novità sulle nostre soluzioni per ridurre i rischi nelle tecnologie e negli ambienti

Edge computing
Aggiornamenti sulle piattaforme che semplificano l'operatività edge

Infrastruttura
Le ultime novità sulla piattaforma Linux aziendale leader a livello mondiale

Applicazioni
Approfondimenti sulle nostre soluzioni alle sfide applicative più difficili
Virtualizzazione
Il futuro della virtualizzazione negli ambienti aziendali per i carichi di lavoro on premise o nel cloud