
Introduction
A couple years ago, a few big companies began to run Spark and Hadoop analytics clusters using shared Ceph object storage to augment and/or replace HDFS.
We set out to find out why they were doing it and how it performs.
Specifically, we wanted to know first-hand answers to the following three questions:
- Why would companies do this? (see “Why Spark on Ceph? (Part 1 of 3)”)
- Will mainstream analytics jobs run directly against a Ceph object store? (this blog post)
- How much slower will it run than natively on HDFS? (see "Why Spark on Ceph (Part 3 of 3)")
For those wanting more depth, we’ll cross-link to a separate architect-level blog series providing detailed descriptions, test data, and configuration scenarios, and we recorded this podcast with Intel, in which we talk about our focus on making Spark, Hadoop, and Ceph work better on Intel hardware and helping enterprises scale efficiently.
Basic analytics pipeline using a Ceph object store
Our early adopter customers are ingesting, querying, and transforming data directly to and from a shared Ceph object store. In other words, target data locations for their analytics jobs are something like “s3://bucket-name/path-to-file-in-bucket” within Ceph, instead of something like “hdfs:///path-to-file”. Direct access to S3-compatible object stores via analytics tools like Spark, Hive, and Impala is made possible via the Hadoop S3A client.
Jointly with several customers, we successfully ran 1000s of analytics jobs directly against a Ceph object store using the following analytics tools:
 Figure 1: Analytics tools tested with shared Ceph object store
Figure 1: Analytics tools tested with shared Ceph object store
In addition to running simplistic tests like TestDFSIO, we wanted to run analytics jobs which were representative of real-world workloads. To do that, we based our tests on the TPC-DS benchmark for ingest, transformation, and query jobs. TPC-DS generates synthetic data sets and provides a set of sample queries intended to model the analytics environment of a large retail company with sales operations from stores, catalogs, and the web. Its schema has 10s of tables, with billions of records in some tables. It defines 99 pre-configured queries, from which we selected the 54 most IO-intensive for out tests. With partners in industry, we also supplemented the TPC-DS data set with simulated click-stream logs, 10x larger than the TPC-DS data set size, and added SparkSQL jobs to join these logs with TPC-DS web sales data.
In summary, we ran the following directly against a Ceph object store:
- Bulk Ingest (bulk load jobs - simulating high volume streaming ingest at 1PB+/day)
- Ingest (MapReduce jobs)
- Transformation (Hive or SparkSQL jobs which convert plain text data into Parquet or ORC columnar, compressed formats)
- Query (Hive or SparkSQL jobs - frequently run in batch/non-interactive mode, as these tools automatically restart failed jobs)
- Interactive Query (Impala or Presto jobs)
- Merge/join (Hive or SparkSQL jobs joining semi-structured click-stream data with structured web sales data)
Architecture overview
We ran variations of the tests outlined above with 4 large customers over the past year. Generally speaking, our architecture looked something like this:
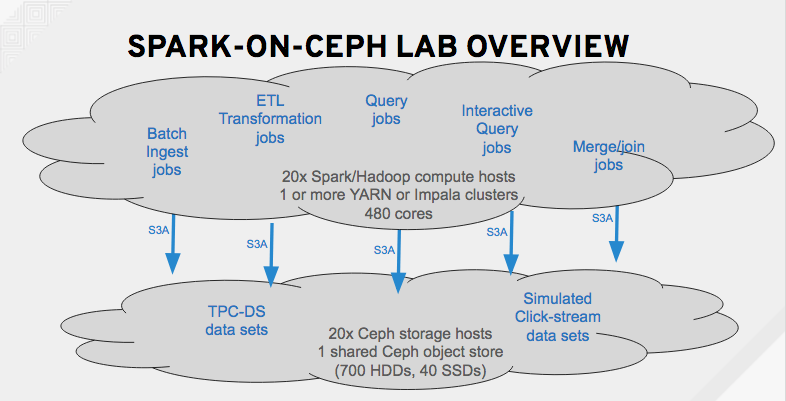 Figure 2: High-level lab architecture
Figure 2: High-level lab architecture
Did it work?
Yes. 1000s of analytics jobs described above completed successfully. SparkSQL, Hive, MapReduce, and Impala jobs all using the S3A client to read and write data directly to a shared Ceph object store. The related architect-level blog series will document detailed lessons learned and configuration techniques.
In the final episode of this blog series, we’ll get to the punch line - what was the performance compared to traditional HDFS? For the answer, continue to Part 3 of this series....
Sull'autore
Altri risultati simili a questo
Le minacce dell'IA si muovono rapidamente. Anche le tue difese dovrebbero farlo.
Il punto di svolta per l’IA: perché la sovranità non è più facoltativa
Container Roundup | Compiler
Untangling Networks | Compiler
Ricerca per canale

Automazione
Novità sull'automazione IT di tecnologie, team e ambienti

Intelligenza artificiale
Aggiornamenti sulle piattaforme che consentono alle aziende di eseguire carichi di lavoro IA ovunque

Hybrid cloud open source
Scopri come affrontare il futuro in modo più agile grazie al cloud ibrido

Sicurezza
Le ultime novità sulle nostre soluzioni per ridurre i rischi nelle tecnologie e negli ambienti

Edge computing
Aggiornamenti sulle piattaforme che semplificano l'operatività edge

Infrastruttura
Le ultime novità sulla piattaforma Linux aziendale leader a livello mondiale

Applicazioni
Approfondimenti sulle nostre soluzioni alle sfide applicative più difficili
Virtualizzazione
Il futuro della virtualizzazione negli ambienti aziendali per i carichi di lavoro on premise o nel cloud