
Motivos por los que no todas las GPU pueden alojarse en el centro de datos
Hasta ahora, se prefería aplicar un enfoque centrado en la arquitectura de TI para abordar los problemas de capacidad de ajuste, gestión y entorno, y sin duda hay ciertos casos prácticos para ello:
- Los centros de datos que contienen el hardware son amplios y funcionales.
- Casi siempre hay más espacio para agregar nodos o hardware adicionales, los cuales pueden gestionarse de manera local y, en ocasiones, en la misma subred.
- El suministro eléctrico, el enfriamiento y la conectividad de la red son permanentes y redundantes.
¿Por qué conviene corregir una solución que no presenta fallos? No se trata de que haya que corregirla, sino de que las soluciones únicas no suelen adaptarse a todas. Veamos un ejemplo: el control de calidad en la fabricación.
Control de calidad en la fabricación
Una fábrica o cadena de montaje puede tener cientos y, a veces, miles de áreas en las que se realizan tareas específicas. El uso de un modelo tradicional implicaría que cada paso del proceso digital o herramienta física no solo realizara su tarea, sino que también enviara el resultado a una aplicación central en una nube remota. Esta situación puede plantear una serie de interrogantes, como por ejemplo:
- Velocidad: ¿cuánto se tarda en tomar una foto, subirla a la nube, analizarla en la aplicación central, enviar una respuesta y actuar? ¿Prefiere trabajar despacio y reducir los ingresos, o hacerlo rápido y arriesgarse a que se produzcan varios errores o accidentes? ¿Las decisiones son inmediatas o prácticamente inmediatas?
- Cantidad: ¿cuánto ancho de banda de red se necesita para que cada sensor cargue o descargue un flujo permanente de datos sin procesar? ¿Es posible? ¿Resulta muy costoso?
- Confiabilidad: ¿qué ocurre si se produce una interrupción en la conectividad de la red? ¿Se paraliza toda la fábrica?
- Capacidad de ajuste: en el supuesto de que la actividad comercial se desarrolle favorablemente, ¿puede un centro de datos principal adaptarse para gestionar los datos sin procesar de todos los dispositivos y en cualquier lugar? En tal caso, ¿a qué costo?
- Seguridad: ¿algunos de los datos sin procesar son de carácter confidencial? ¿Pueden trasladarse a otra área? ¿Pueden almacenarse en otro sitio? ¿Es necesario cifrarlos antes de transmitirlos y analizarlos?
Migración al extremo de la red
Si alguna de las respuestas anteriores lo hizo dudar, entonces vale la pena plantearse el uso del edge computing. En pocas palabras, este tipo de tecnología traslada las funciones de las aplicaciones privadas, más pequeñas y que responden con rapidez ante eventos específicos fuera del centro de datos y las sitúa cerca de donde se llevan a cabo los procesos reales. El edge computing ya es moneda corriente: está presente en los vehículos que conducimos y en nuestros teléfonos móviles. Gracias a ella, la capacidad de ajuste deja de ser un problema para convertirse en una ventaja.
Volvamos al ejemplo de la fabricación. Si cada cadena de montaje tuviera un pequeño clúster cerca, se podrían reducir todos los problemas mencionados.
- Velocidad: las fotos de las tareas completadas se revisan en el lugar, con hardware local que puede funcionar sin tanto retraso.
- Cantidad: el ancho de banda a sitios externos se reduce de manera significativa, lo cual permite ahorrar en gastos fijos.
- Confiabilidad: aunque se produzca una interrupción en la conectividad de la red de área amplia, las tareas pueden realizarse de manera local y volver a sincronizarse en una nube central cuando se restablezca el servicio.
- Capacidad de ajuste: ya sea que operen dos o 200 fábricas, los recursos necesarios se encuentran en cada ubicación, lo cual reduce la necesidad de crear demasiados centros de datos principales solo para operar durante las horas de mayor actividad.
- Seguridad: ningún dato sin procesar sale de las instalaciones, lo cual disminuye la posibilidad de que se produzcan ataques.
Combinación del edge computing con la nube pública
Red Hat OpenShift es la plataforma de Kubernetes empresarial líder en el sector y ofrece un entorno flexible que permite ubicar las aplicaciones (y la infraestructura) donde más se necesitan. En este caso, no solo puede ejecutarse en una nube pública concentrada, sino que esas mismas aplicaciones pueden trasladarse a las propias cadenas de montaje. De este modo, pueden incorporar, procesar y manipular los datos directamente desde su ubicación. Es el machine learning (aprendizaje automático) en el extremo de la red. Veamos tres ejemplos que combinan el edge computing con nubes privadas y públicas. En el primero se utilizan el edge computing y una nube pública.

- La adquisición de datos tiene lugar en las instalaciones y es donde se recopilan los datos sin procesar. Los sensores y los dispositivos del Internet de las cosas (IoT) que toman medidas o ejecutan tareas pueden conectarse a servidores del extremo de la red localizados a través de Red Hat AMQ Streams o del componente AMQ Broker. En función de los requisitos de la aplicación, estos pueden ser desde pequeños nodos individuales hasta clústeres más grandes de alta disponibilidad y, lo más importante, pueden combinarse entre sí: con nodos pequeños en ubicaciones remotas y clústeres más grandes donde haya más espacio.
- En la preparación de datos, la creación de modelos, el desarrollo y la distribución de aplicaciones es donde tienen lugar los verdaderos procesos. Los datos se incorporan, almacenan y analizan. Si utilizamos el ejemplo de la cadena de montaje, las imágenes de los widgets se analizan en busca de patrones (como fallos en los materiales o los procesos). En este punto comienza el aprendizaje. A partir de la información obtenida, este conocimiento se aplica a las aplicaciones desarrolladas en la nube que se encuentran en el extremo de la red. Sin embargo, esta operación no se lleva a cabo en el extremo, ya que la ejecución de unidades de procesamiento central y gráfico (CPU y GPU) intensivas en clústeres concentrados y complejos acelera el proceso durante días o semanas en comparación con la que se realiza en dispositivos ligeros situados en el extremo de la red.
- Gracias a Red Hat OpenShift Pipelines y GitOps, los desarrolladores pueden mejorar sus aplicaciones de manera constante mediante la integración y la distribución continuas (CI/CD) para que el proceso se realice lo más rápido posible. Si los conocimientos adquiridos se aplican con mayor rapidez, el tiempo y los recursos empleados en la generación de ingresos serán mucho más eficientes. Esto nos remite de nuevo al extremo, en el que las aplicaciones nuevas (o actualizadas) que funcionan con inteligencia artificial utilizan la información obtenida para analizar e incorporar los datos antes de compararlos con los últimos modelos. De este modo, el ciclo se repite como parte del proceso de mejora constante.
Combinación del edge computing con la nube privada
Si observamos el segundo ejemplo, todo el proceso es idéntico a excepción del segundo paso, el cual se realiza en las instalaciones de la empresa y en una nube privada.

Las empresas pueden elegir una nube privada por los siguientes motivos:
- Ya poseen el hardware y pueden utilizar el capital disponible.
- Tienen que cumplir normas estrictas sobre ubicación y seguridad de los datos. La información confidencial no puede almacenarse en una nube pública ni transferirse a través de ella.
- Necesitan hardware personalizado, como matrices de puertas programables en campo, GPU o una configuración que no se puede obtener de un proveedor de nube pública.
- Tienen cargas de trabajo específicas cuya ejecución en una nube pública es más costosa que en hardware local.
Estos son solo algunos ejemplos de la flexibilidad que ofrece OpenShift. Puede ser tan sencillo como ejecutar la plataforma en una nube privada de Red Hat OpenStack Platform.
Combinación del edge computing con la nube híbrida
En el último ejemplo se utiliza una nube híbrida formada por entornos de nube pública y privada.
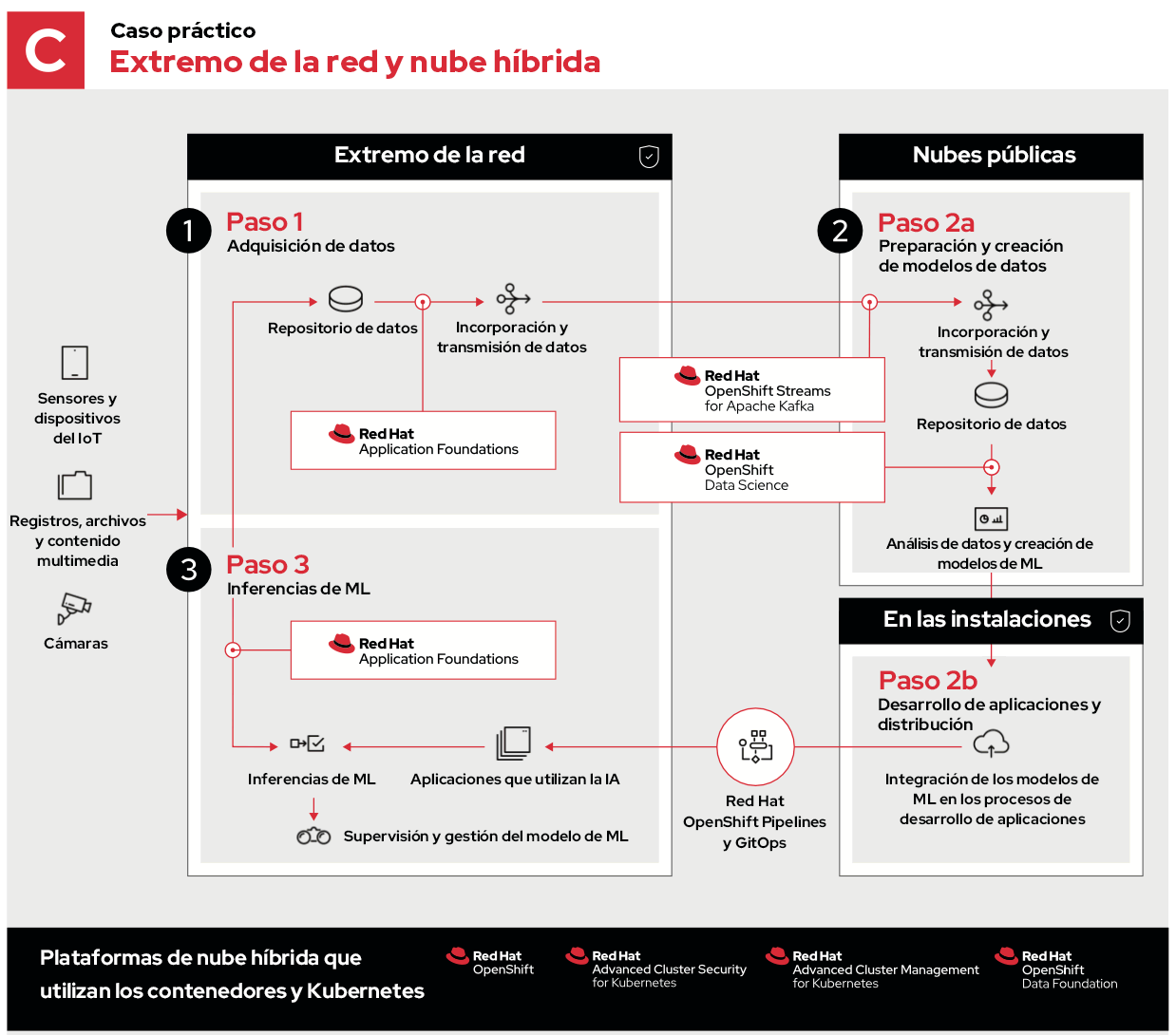
En este caso, el primer y el tercer paso son iguales, e incluso el segundo tiene los mismos procesos; sin embargo, están distribuidos para ejecutarse en entornos óptimos.
- El paso 2a consiste en incorporar, almacenar y analizar los datos desde el extremo de la red, para lo cual aprovecha la capacidad de las nubes públicas en cuanto a los recursos, la diversidad geográfica y la conectividad para recopilarlos y descifrarlos.
- El paso 2b permite el diseño de aplicaciones en las instalaciones, lo cual puede acelerar, proteger o personalizar de algún otro modo los flujos de trabajo de desarrollo específicos antes de aplicar las actualizaciones en el extremo.
Beneficios de Red Hat
Dada la cantidad de variables y aspectos que deben tenerse en cuenta, un entorno de edge computing eficaz debe ser flexible. Red Hat ofrece a sus clientes las herramientas que necesitan para diseñar soluciones flexibles que permitan ejecutar las aplicaciones adecuadas en los lugares correctos, ya sea que se trate de gestionar una conectividad de red lenta, poco confiable o nula, garantizar el cumplimiento de las normas o cumplir con requisitos de rendimiento rigurosos.
Independientemente de que la información se obtenga en el extremo de la red, en una nube pública conocida o en las instalaciones de una nube privada (o en todas partes a la vez), los desarrolladores pueden utilizar las herramientas habituales y seguir innovando sus aplicaciones en la nube (que se ejecutan en OpenShift) y utilizarlas de la manera y en el lugar que les resulte más conveniente.
Sobre el autor
Ben has been at Red Hat since 2019, where he has focused on edge computing with Red Hat OpenShift as well as private clouds based on Red Hat OpenStack Platform. Before this he spent a decade doing a mix of sales and product marking across telecommunications, enterprise storage and hyperconverged infrastructure.
Más como éste
Acelerando el tiempo hacia el descubrimiento científico para los CDC y los NIH
Del costo a la ventaja competitiva con la IA soberana
Technically Speaking | Defining sovereign AI with open source
Infrastructure At The Edge | Compiler
Navegar por canal

Automatización
Las últimas novedades en la automatización de la TI para los equipos, la tecnología y los entornos

Inteligencia artificial
Descubra las actualizaciones en las plataformas que permiten a los clientes ejecutar cargas de trabajo de inteligecia artificial en cualquier lugar

Nube híbrida abierta
Vea como construimos un futuro flexible con la nube híbrida

Seguridad
Vea las últimas novedades sobre cómo reducimos los riesgos en entornos y tecnologías

Edge computing
Conozca las actualizaciones en las plataformas que simplifican las operaciones en el edge

Infraestructura
Vea las últimas novedades sobre la plataforma Linux empresarial líder en el mundo

Aplicaciones
Conozca nuestras soluciones para abordar los desafíos más complejos de las aplicaciones
Virtualización
El futuro de la virtualización empresarial para tus cargas de trabajo locales o en la nube