There is an increasing demand for running and managing cloud native applications on a platform that is able to handle the surge in traffic in a scalable and performant manner.
OpenShift is the go-to platform. There are a number of features being added in each release to meet the ever-changing needs in various domains, including the most recent edge computing. In the previous blog post, we looked at the highlights of the OpenShift 4.3 scale test run at 2000 node scale. In this blog post, we will look at how we, the Performance and Scalability team at Red Hat, pushed the limits of OpenShift 4.5 at scale.
What’s New in OpenShift 4.5?
OpenShift 4.5 is based on Kubernetes 1.18 and it supports installation on vSphere with full stack automation experience, in addition to other cloud providers. The most awaited API Priority and Fairness feature, which prioritizes system requests over application requests to improve the stability and scalability of OpenShift clusters, is enabled by default. This release includes many other features, bug fixes, and enhancements for various components, including Install, Upgrades, Machine API, Cluster Monitoring, Scale, Cluster Operators, and Disaster Recovery as discussed in the release notes. A single blog post will not be enough to walk through all the features in OpenShift 4.5. Let’s jump straight into the scale test run, where the goal was to see if there was a regression in terms of Performance and Scalability when compared to the previous releases, this time with OpenShift SDN and OVNKube as the network plugins. Based on these tests, we provided recommendations to help with running thousands of objects on large-scale clusters.
OpenShift 4.5 Scale Test Run
We started gearing up for the mission after the stable builds with the 4.5 bits were ready. This time, Cerberus acted as the guardian by monitoring the cluster health, alerting us on the Slack channel, and stopping the workload from generating invalid data, which could drive the cluster into an unrecoverable state. With this automation, we did not have to manually monitor the cluster's health status regularly. We added a bunch of features to Cerberus to improve the health checks coverage as well as code changes to reduce the number of API calls to the server and multithreading to speed up the process. The great blog post by Yashashree Suresh and Paige Rubendall covers all the enhancements in detail. The preparation also included making sure the dashboards are graphing all the metrics of interest similarly to what we did for the previous scale test runs. A couple of the metrics include critical alerts, ApiServer Queries/Requests per second, Inflight API requests, Etcd backend DB size, Etcd leader changes (they are quite disruptive when the count is high), resource usage, and fsync (critical for Etcd read and write operations to be fast enough). We also have a new dashboard that tracks the metrics related to API Priority and Fairness.
We started the runs with base clusters consisting of three Masters/Etcds, three Infrastructure nodes to host the Ingress, Registry and Monitoring stack, and three worker nodes and went on to scale up the cluster to 500 nodes. One cluster was using OpenShift SDN as the network plugin while the other was using OVNKube as one of the goals this time was to compare them and find out the bottlenecks. The Performance and Scale tests were run at various node scales (25/100/250/500) as shown below:

Faster Installs
The first stop is at the install. With the introduction of Cluster Etcd Operator, the installs are much faster due to improvements in the bootstrapping process when compared to the OpenShift 4.3 and prior releases. Let’s get into the details as to what changed:
OpenShift 4.3 and Prior Releases
Bootstrap node boots up master nodes on which it installs and waits for a production three node Etcd cluster to form a temporary control plane on bootstrap node before rolling out the production control plane including API server, cluster operators etc. on master nodes.
OpenShift 4.4 and Later Releases
Etcd is started at an early stage on bootstrap node and is used to create a temporary control plane which is then used to roll out the production control plane including API server, operators, and Etcd much earlier. Also, the Cluster Etcd Operator keeps scaling the production Etcd replicas in parallel during the process leading to faster installs.

Infrastructure Node Sizing
Infrastructure components include Monitoring (Prometheus), Router, Registry and Logging (Elasticsearch). It’s very important to have enough resources for them to run with getting OOM killed, especially on large and dense clusters. Worker nodes in a typical cluster might not be big enough to host the infrastructure components, but we can overcome it by creating Infrastructure nodes using custom MachineSets, and the components can be steered onto them as documented.
This all sounds good, but what instance types or how much resources are needed, one might ask? Prometheus is more memory-intensive than CPU-intensive, and it is the highest resources consumer on the Infrastructure nodes. It is expected to use more than 130GB of memory on a large and dense cluster: 500 nodes, 10k namespaces, 60k pods, 190k secrets, etc.
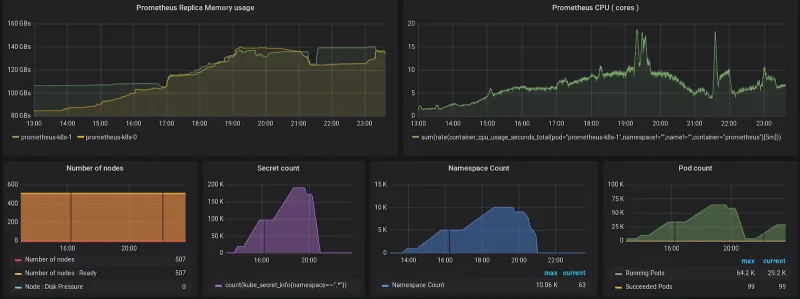
Taking all the data from performance and scalability tests into consideration, here are the sizing recommendations at various node counts. It is recommended to use machines with 32 CPU cores and 192GB memory to host infrastructure components. Note that the cores and memory are mapped to closest instance types that are typically available to be used in public clouds.

Logging stack: Elasticsearch and Fluentd can be installed as part of day two operation, and it’s recommended to steer Elasticsearch onto the infrastructure nodes as well. Note that the recommendations above do not take the Logging stack into account for sizing.
It is recommended to use memory-optimized instances than general or cpu-optimized to save on costs in cases of public clouds as the infrastructure components are more memory intensive than CPU intensive.
Scale Up and Scale Down
Once we had the base cluster ready, we started scaling up the cluster and ran the Performance and Scalability tests at the appropriate node counts. We scaled down the cluster to lower node counts whenever possible to avoid burning down the cash and observed that it might take large amounts of time when scaling down a cluster with nodes hosting a large number of applications. Nodes are drained to relocate the applications before terminating them, and this process might generate a high number of requests since it’s done in parallel and client’s’ default QPS/Burst rates (5/10) might cause throttling leading to increase in the time. We are working on making it configurable.
Cluster Maximums
Cluster maximums are an important measure of knowing when the cluster will start experiencing performance and scalability issues and in the worst case become unstable. It is the point where the user and customer should stop pushing the cluster. We have tested and validated the cluster maximums including number of nodes, pods per node, pods per namespace, services per namespace, number of namespaces etc. to help users and customers plan their environments accordingly. Note that these maximums can be achieved, provided the environment is similar in terms of cloud platform, node type, disk size, disk type, and IOPS, especially for Masters/Etcd nodes since Etcd is I/O intensive and latency sensitive. The tested cluster maximums as well as the environment details are documented as part of the Scalability and Performance Guide.
We observed that 99 percentile of the requests to the API took less than 1 second when the cluster is loaded with around 10k namespaces, 60k pods, 190k secrets, 10k deployments, and hundreds of ConfigMaps and Secrets to hit the maximums. The API server and Etcd were stable all the time due to appropriate defaults including the QPS/Burst rates on the server side and backend quota in case of Etcd. Alerts are a good way to understand if there is something wrong with the cluster. There were no critical alerts observed with the cluster in this state.

Can we push beyond the documented services, one might ask? Users and customers might have a need to run more than 5000 services per namespace. It’s not possible to do it when using environment variables for service discovery: default in Kubernetes and OpenShift today. For each active service in the cluster, the kubelet injects environment variables into the pods, and after 5000 services, the argument length gets too long, leading to pod/deployment failures. Is there any other way for the pods to discover the services? The answer is yes, and the solution is using a cluster-aware DNS. The service links can be disabled when using DNS in the pod/deployment spec file to avoid using environment variables for service discovery which will allow us to go beyond 5000 services per namespace as documented.

The documented cluster limits for the major releases are as documented below:

Upgrades
Over-the-air upgrades are one of the most looked at features that come with the switch to OpenShift 4.x from 3.x. OpenShift 4.x uses immutables OS, and ssh to the nodes is disabled to avoid altering any files or configuration at both cluster as well at node level.
We were able to successfully upgrade a loaded cluster running OpenShift 4.4.13 bits to OpenShift 4.5.4 at 250 node scale using the stable channel. Note that upgrading to 4.4.13 is a prerequisite/recommended to get a stable upgrade to OpenShift 4.5.x.
The DaemonSets are rolled out in serial with maximum unavailability set to one by default, causing the upgrades to take long amounts of time on a large-scale cluster since there a replica runs on each of the nodes. Work is in progress to upgrade 10% of the replicas in parallel for all the DaemonSets, which do not impact the cluster/applications when multiple replicase like node-exporter, node-tuning, and machine-config daemons are being upgraded at once. This should significantly improve the timing of the cluster operators upgrades on a large-scale cluster.
The builds part of the stable-4.5 channel can be found here. During the upgrades, the Cluster Version Operator (CVO) in the cluster checks with the OpenShift Container Platform update service to see the valid updates and update paths based on current component versions. During the upgrade process, the Machine Config Operator (MCO) applies the new configuration to the cluster machines. It cordons the number of nodes that are specified by the maxUnavailable field on the machine configuration pool, so they are drained. Once the drain is finished, it applies the new configuration and reboots them. This operation is applied on a serial basis, and the number of nodes that can be unavailable at a given time is one by default, meaning it is going to take a long time when there are hundreds or thousands of nodes. That is because upgrading each node would need to drain and reboot each node after applying the latest ostree layer. Tuning the maxUnavailable parameter of the worker’s MachineConfigPool should speed up node upgrade time. We need to make sure to set it to a value that avoids causing disruption to any services.
Other Findings
We ran a number of tests to look at the Performance and Scalability of various components of OpenShift, including Networking, Kubelet, Router, Control Plane, Logging, Monitoring, Storage, concurrent builds, and Cluster Maximums. Here are some of the findings from the cluster with OpenShift SDN as the network plugin, which is the default unless compared with OVNKube:
- In OpenShift 4.5, the HAProxy used for Ingress has been upgraded to 2.0.14 and it provides a router reload performance improvement beneficial for clusters with thousands of routes. It provides connection pooling and threading improvements thus allowing faster concurrent I/O operations. We observed that the throughput in terms of requests per second is better in case of clusters with OpenShift SDN than OVNKube which led us to create the bug. We are actively working on fixing it.
- No major regression in terms of networking with OpenShift SDN and OVNKube as the network plugin (default) when compared with OpenShift 4.4.
- OpenShift Container Storage v4.5 is stable and scales well. With OCS v4.5, we can achieve higher density of pods with persistent volume claims (PVCs) per node than for cases when cloud provider storage classes are used as storage providers for applications. Also, deleting PVC (and backend storage) is fast and reliable.
- Cluster logging in OpenShift Container Platform 4.5 now uses Elasticsearch 6.8.1 as the default log store.
- The control plane, or rather API server and Etcd, is stable with thousands of objects and nodes running in the cluster. It is important to use the disks with low fync timings for Masters and Etcds nodes as it’s critical for Etcd’s performance. Etcd has been bumped to 3.4 and it comes with features including non-blocking concurrent read as well as lease lookup operations, improved raft voting process, and new client balancer. https://kubernetes.io/blog/2019/08/30/announcing-etcd-3-4/ is a great source for knowing various enhancements committed in Etcd 3.4 version.
- The pod creation rate is seen to be better in case of clusters with OpenShift SDN as the network plugin when compared with OVNKube.
- Builds build and push operation are stable, and there is not much regression when compared to the previous releases.
We are actively working on improving the performance and scalability of clusters with OVNKube as the networking solution in addition to OpenShift SDN.
Refer to the Scalability and Performance Guide for more information on how to plan the OpenShift environments to be more scalable and performant.
What’s Next?
Stay tuned for the upcoming blog posts on more tooling and automation enhancements, including introducing chaos experiments into the test suite to ensure the reliability of OpenShift during turbulent conditions, as well as highlights from the next large-scale test runs on clusters ranging from 250 to 2000 nodes. As always, feel free to reach us out on Github: https://github.com/cloud-bulldozer, https://github.com/openshift-scale or sig-scalability channel on Kubernetes Slack.
Try OpenShift 4 for free저자 소개

Naga Ravi Chaitanya Elluri leads the Chaos Engineering efforts at Red Hat with a focus on improving the resilience, performance and scalability of Kubernetes and making sure the platform and the applications running on it perform well under turbulent conditions. His interest lies in the cloud and distributed computing space and he has contributed to various open source projects.
채널별 검색

오토메이션
기술, 팀, 인프라를 위한 IT 자동화 최신 동향

인공지능
고객이 어디서나 AI 워크로드를 실행할 수 있도록 지원하는 플랫폼 업데이트

오픈 하이브리드 클라우드
하이브리드 클라우드로 더욱 유연한 미래를 구축하는 방법을 알아보세요

보안
환경과 기술 전반에 걸쳐 리스크를 감소하는 방법에 대한 최신 정보

엣지 컴퓨팅
엣지에서의 운영을 단순화하는 플랫폼 업데이트

인프라
세계적으로 인정받은 기업용 Linux 플랫폼에 대한 최신 정보

애플리케이션
복잡한 애플리케이션에 대한 솔루션 더 보기
가상화
온프레미스와 클라우드 환경에서 워크로드를 유연하게 운영하기 위한 엔터프라이즈 가상화의 미래