
Por que nem todas as GPUs podem residir no data center?
Tradicionalmente, a arquitetura de TI centralizada é a principal forma de resolver problemas com a escala, gerenciamento e ambiente. E essa abordagem é útil nestas condições:
- Os data centers que abrigam o hardware são eficazes e grandes
- Quase sempre há espaço para adicionar mais nós ou hardware, que podem ser gerenciados localmente, às vezes até na mesma sub-rede
- A alimentação, o resfriamento e a conectividade são constantes e redundantes
Mas por que consertar algo que não está quebrado? A questão é que raramente uma solução padronizada serve para todos os cenários. Vejamos um exemplo de uso do controle de qualidade no setor de manufatura.
Controle de qualidade no setor de manufatura
Uma fábrica ou linha de montagem pode ter centenas, e às vezes milhares de áreas onde são realizadas tarefas específicas. Com o modelo tradicional, cada etapa digital ou ferramenta física precisaria, além de executar sua função, transmitir o resultado do trabalho a uma aplicação central em uma nuvem à distância. Isso leva a questões como:
- Velocidade: quanto tempo leva para capturar uma foto, enviá-la à nuvem para ser analisada pela aplicação central, receber uma resposta e executar uma ação? As operações são lentas, reduzindo a receita, ou rápidas, estando propensas a vários erros ou acidentes? As decisões são tomadas em tempo real ou praticamente em tempo real?
- Quantidade: quanta largura de banda a rede precisa ter para cada sensor fazer upload ou download de um fluxo constante de dados brutos? Isso é possível? O custo é proibitivo?
- Confiabilidade: o que acontece quando há uma queda na conectividade da rede? A fábrica inteira simplesmente para?
- Escala: considerando que os negócios vão bem, é possível escalar o data center central para processar todos os dados brutos de todos os dispositivos e locais? Em caso afirmativo, qual é o custo disso?
- Segurança: alguma parte dos dados brutos é considerada confidencial? Eles podem sair do local? Podem ser armazenados em qualquer lugar? Devem ser criptografados antes de serem transmitidos e analisados?
Migração para a edge
Se alguma dessas respostas gerou reflexão, considere a edge computing. Em poucas palavras, a edge computing transfere as funções de aplicações menores, sensíveis à latência ou privadas para fora do data center, posicionando-as perto de onde as tarefas são executadas. A edge computing já é comum. Ela está nos carros que dirigimos e nos celulares em nossos bolsos. Com a edge computing, a escala deixa de ser um problema e vira uma vantagem.
Vamos voltar ao exemplo da manufatura. Se cada linha de montagem tivesse um pequeno cluster por perto, todos os problemas acima seriam resolvidos.
- Velocidade: as fotos das tarefas concluídas são revisadas no local, e o hardware opera com menos atraso.
- Quantidade: a largura de banda para locais externos é bastante reduzida, economizando custos recorrentes.
- Confiabilidade: mesmo com uma queda na conectividade da rede de longa distância, o trabalho continua sendo realizado no local e é sincronizado com a nuvem central quando a conectividade é restabelecida.
- Escala: não importa se são duas ou 200 fábricas, ter os recursos necessários em cada local reduz a necessidade de criar grandes data centers centrais para operar apenas durante os horários de pico.
- Segurança: os dados brutos não saem do local, reduzindo a possível superfície de ataque.
Como a edge e a nuvem pública funcionam juntas?
O Red Hat OpenShift, a plataforma empresarial de Kubernetes líder do setor, oferece um ambiente flexível que posiciona as aplicações (e a infraestrutura) onde são mais necessárias. Nesse caso, além de serem executadas em uma nuvem pública centralizada, as aplicações podem ser movidas para as linhas de montagem. Isso permite ingerir os dados, processá-los e tomar medidas rapidamente no local. É o machine learning (aprendizado de máquina, ML) atuando na edge. Vejamos três exemplos que combinam a edge computing com nuvens públicas e privadas. O primeiro combina a edge computing e a nuvem pública.

- A aquisição de dados acontece no local, com a coleta dos dados brutos. Os sensores e dispositivos de Internet das Coisas (IoT) que fazem medições ou executam tarefas podem se conectar a servidores de edge locais usando fluxos do Red Hat AMQ ou o componente de broker do AMQ. Eles podem variar de nós únicos a clusters maiores de alta disponibilidade, dependendo dos requisitos da aplicação. O melhor de tudo é que eles podem ser combinados, usando pequenos nós em áreas remotas e clusters maiores onde há mais espaço.
- O trabalho em si é feito na preparação, modelagem, desenvolvimento e entrega das aplicações. Os dados são ingeridos, armazenados e analisados. Usando a linha de montagem como exemplo, as imagens de widgets são analisadas em busca de padrões, como falhas nos materiais ou processos. É assim que o aprendizado acontece. O novo conhecimento obtido é reintegrado às aplicações nativas em nuvem que estão na edge. Nem tudo é feito na edge porque, em comparação com dispositivos de edge lightweight, executar as unidades de processamento central e gráfico (CPU/GPU) intensivas em clusters densos e centralizados acelera o processo em dias ou semanas.
- Com o Red Hat OpenShift Pipelines e o GitOps, os desenvolvedores podem aprimorar continuamente suas aplicações usando integração e entrega contínuas (CI/CD) para tornar o processo o mais rápido possível. Quanto mais rápido o conhecimento adquirido for usado, mais tempo e recursos poderão ser direcionados à geração de receita. Isso nos traz de volta à edge, onde as apps novas e recém-atualizadas com inteligência artificial usam novos conhecimentos para observar e ingerir dados antes de compará-los com modelos recentes. O ciclo se repete como parte da melhoria contínua.
Como a edge e a nuvem privada funcionam juntas?
No segundo exemplo, todo o processo é igual, com exceção da etapa 2, que agora reside on-premise em uma nuvem privada.
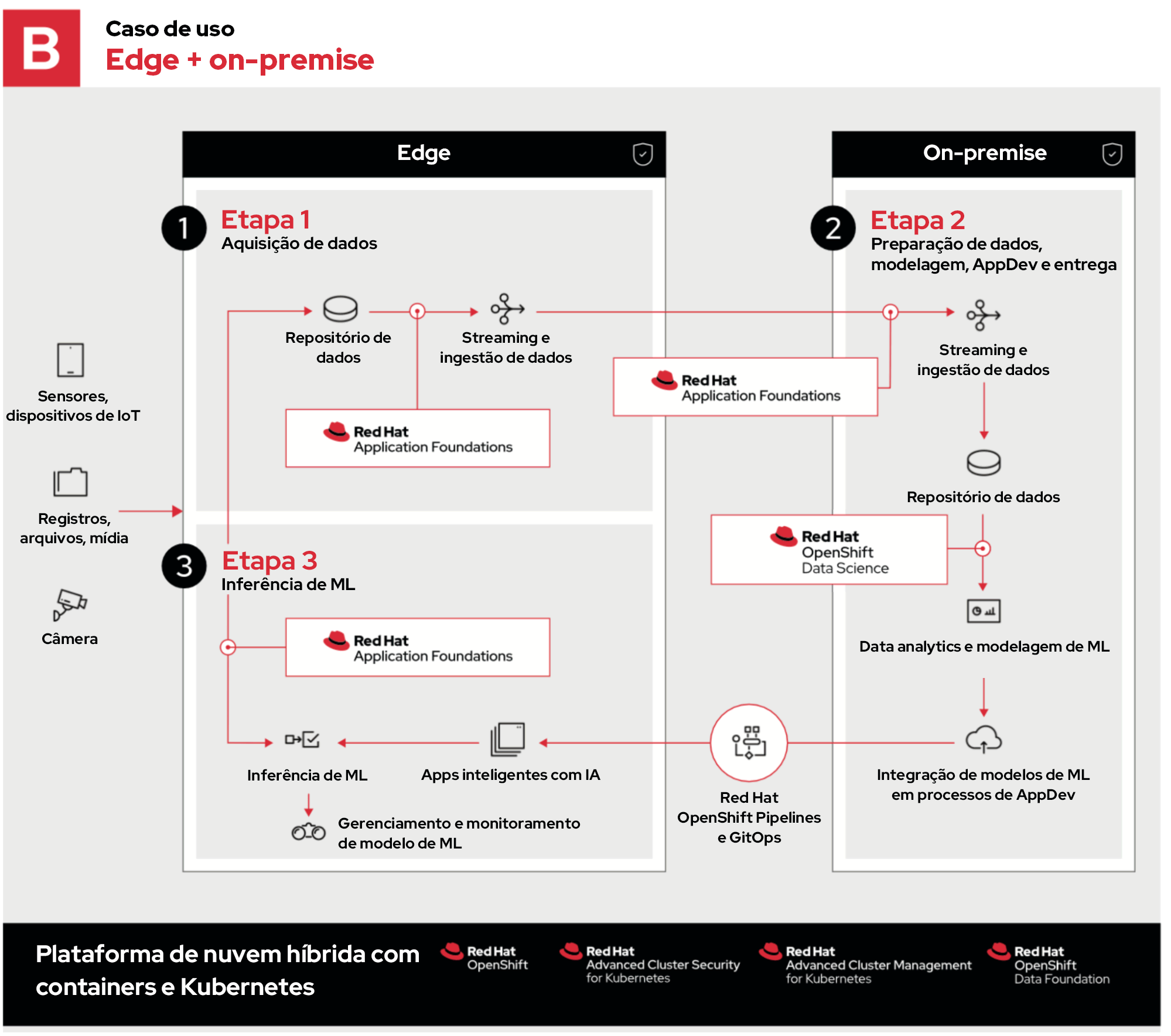
As empresas podem escolher a nuvem privada porque:
- Já possuem o hardware e podem usar o capital existente.
- Têm que aderir a regulamentações rígidas sobre localização e segurança de dados. Os dados confidenciais não podem ser armazenados ou transmitidos usando uma nuvem pública.
- É necessário hardware personalizado, como matrizes de portas programáveis em campo, GPUs ou uma configuração indisponível para locação em um provedor de nuvem pública.
- É mais caro executar as cargas de trabalho específicas em uma nuvem pública do que em um hardware local.
Esses são apenas alguns exemplos da flexibilidade que o OpenShift oferece. E, para isso, basta executar o OpenShift em uma nuvem privada do Red Hat OpenStack Platform.
Como a edge e a nuvem híbrida funcionam juntas?
O exemplo final usa uma nuvem híbrida, que consiste em nuvens públicas e privadas.
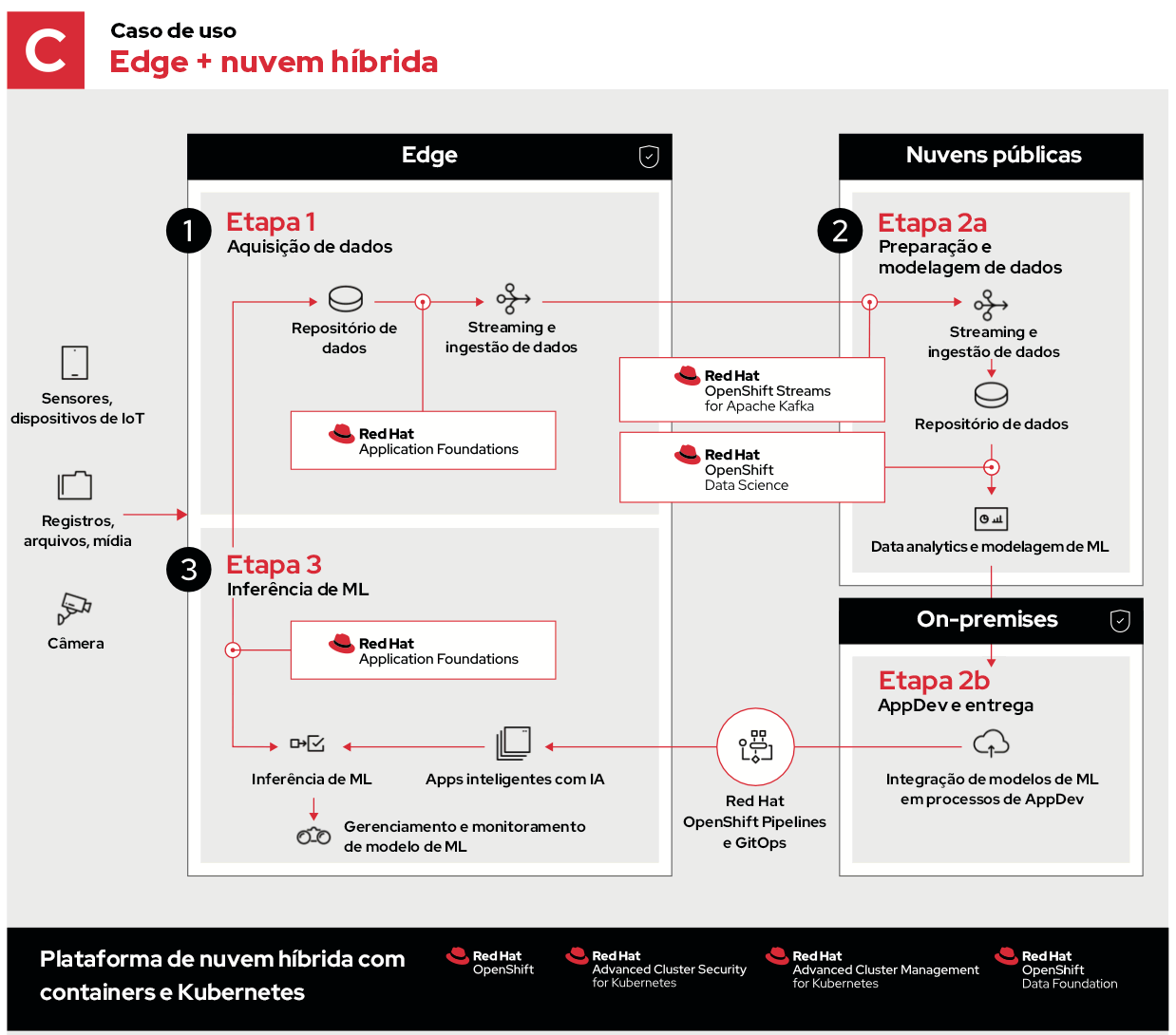
Nesse caso, as etapas 1 e 3 são iguais. A etapa 2 segue os mesmos processos, mas eles são distribuídos para serem executados nos ambientes ideais.
- A etapa 2a envolve a ingestão, o armazenamento e a análise dos dados na edge, aproveitando a escala de recursos, a diversidade geográfica e a conectividade das nuvens públicas para coletar e decifrar dados.
- A etapa 2b permite desenvolver aplicações on-premise, o que pode acelerar, proteger ou personalizar fluxos de trabalho de desenvolvimento específicos antes de enviar essas atualizações de volta para a edge.
O que a Red Hat oferece?
Devido à quantidade de variáveis e considerações envolvidas, o ambiente de edge computing precisa ser flexível para ter sucesso. A Red Hat oferece aos clientes as ferramentas para criar soluções flexíveis, que podem ser ajustadas para executar as aplicações certas nos lugares certos. Isso permite resolver a conectividade de rede lenta, não confiável, nula ou atender à conformidade rígida e requisitos de desempenho extremos.
Não importa se os insights vêm da edge, de uma nuvem pública conhecida, on-premise em uma nuvem privada ou de todos os lugares ao mesmo tempo: os desenvolvedores podem usar ferramentas conhecidas para inovar continuamente as aplicações nativas em nuvem no OpenShift e executá-las como e onde for melhor.
Sobre o autor
Ben has been at Red Hat since 2019, where he has focused on edge computing with Red Hat OpenShift as well as private clouds based on Red Hat OpenStack Platform. Before this he spent a decade doing a mix of sales and product marking across telecommunications, enterprise storage and hyperconverged infrastructure.
Mais como este
Por que agentes de IA são a evolução das aplicações
O paradoxo agêntico e o argumento a favor da IA híbrida
Technically Speaking | Defining sovereign AI with open source
Infrastructure At The Edge | Compiler
Navegue por canal

Automação
Últimas novidades em automação de TI para empresas de tecnologia, equipes e ambientes

Inteligência artificial
Descubra as atualizações nas plataformas que proporcionam aos clientes executar suas cargas de trabalho de IA em qualquer ambiente

Nuvem híbrida aberta
Veja como construímos um futuro mais flexível com a nuvem híbrida

Segurança
Veja as últimas novidades sobre como reduzimos riscos em ambientes e tecnologias

Edge computing
Saiba quais são as atualizações nas plataformas que simplificam as operações na borda

Infraestrutura
Saiba o que há de mais recente na plataforma Linux empresarial líder mundial

Aplicações
Conheça nossas soluções desenvolvidas para ajudar você a superar os desafios mais complexos de aplicações
Virtualização
O futuro da virtualização empresarial para suas cargas de trabalho on-premise ou na nuvem