Red Hat OpenShift Virtualization 4.19 verbessert die Performance und Geschwindigkeit für I/O-intensive Workloads wie Datenbanken erheblich. Multiple IO Threads für Red Hat OpenShift Virtualization ist ein neues Feature, mit dem Disk-I/Os von virtuellen Maschinen (VMs) auf mehrere Worker-Threads auf dem Host verteilt werden können, die wiederum Disk-Warteschlangen innerhalb der VM zugeordnet sind. So kann eine VM sowohl die vCPU als auch die Host-CPU effizient für Multi-Stream-I/O nutzen und so die Performance verbessern.
Dieser Artikel ergänzt die Vorstellung der Funktionen meiner Kollegin Jenifer Abrams. Im Anschluss stelle ich Performanceergebnisse zur Verfügung, damit Sie Ihre VM optimieren und einen besseren I/O-Durchsatz erzielen können.
Zum Testen habe ich fio mit Linux-VMs als synthetische I/O-Workload verwendet. Es sind weitere Tests mit Anwendungen auch unter Microsoft Windows vorgesehen.
Weitere Hintergrundinformationen zur Implementierung dieses Features in KVM finden Sie in diesem Artikel über IOThread Virtqueue Mapping sowie in diesem Begleitartikel, in dem Performanceverbesserungen für Datenbank-Workloads in VMs demonstriert werden, die in einer Red Hat Enterprise Linux (RHEL) Umgebung ausgeführt werden.
Beschreibung des Tests
Ich habe den I/O-Durchsatz für 2 Konfigurationen getestet:
- Ein Cluster mit lokalem Storage unter Verwendung des Logical Volume Managers, der vom Local Storage Operator (LSO) bereitgestellt wird.
- Ein separater Cluster, der OpenShift Data Foundation (ODF) verwendet.
Die Konfigurationen sind sehr unterschiedlich und können nicht verglichen werden.
Wir haben den Test mit Pods (als Baseline) und VMs durchgeführt. Den VMs wurden 16 Kerne und 8 GB RAM zugewiesen. Ich habe Testdateien mit 512 GB mit 1 VM und 256 GB mit 2 VMs verwendet. Ich habe in allen Tests direkten I/O verwendet. Ich habe Persistent Volume Claims (PVC) im Blockmodus und der ext4-Formatierung für VMs und PVCs im Dateisystemmodus, ebenfalls als ext4 formatiert, für Pods verwendet. Alle Tests wurden mit der I/O-Engine „libaio“ durchgeführt.
Ich habe die folgende Matrix getestet:
Parameter | Einstellungen |
Storage Volume-Typ | Lokal (LSO), ODF |
Anzahl der Pods/VMs | 1, 2 |
Anzahl der I/O-Threads (nur VMs) | Keine (Baseline), 1, 2, 3, 4, 6, 8, 12, 16 |
I/O-Operationen | Sequenzielles und zufälliges Lesen (read) und Schreiben (write) |
I/O-Blockgrößen (Byte) | 2K, 4K, 32K, 1M |
Gleichzeitige Jobs | 1, 4, 16 |
I/O-iodepth (iodepth) | 1, 4, 16 |
Zur Orchestrierung der Tests habe ich ClusterBuster verwendet. Die VMs verwendeten CentOS Stream 9, und die Pods verwendeten ebenfalls CentOS Stream als Container Image-Basis.
Lokaler Storage
Der lokale Storage-Cluster war ein Cluster mit 5 Knoten (3 Master + 2 Worker), bestehend aus Dell R740xd-Knoten mit 2 Intel Xeon Gold 6130 CPUs mit jeweils 16 Kernen und 2 Threads (32 CPUs) für insgesamt 32 Kerne und 64 CPUs. Jeder Knoten enthielt 192 GB RAM. Das I/O-Subsystem bestand aus 4 Kioxia CM6 MU 1,6 TB NVMe-Laufwerken von Dell, die als RAID0 Striped Multiple Device (MD) mit Standardeinstellungen konfiguriert waren. Persistent Volume Claims wurden mit dem lvmcluster-Operator aus dieser MD herausgearbeitet. Leider war diese eher unkomplizierte Konfiguration alles, was mir zur Verfügung stand. Es ist gut möglich, dass ein schnelleres I/O-System zu noch mehr Verbesserung durch mehrere I/O-Threads führen würde.
OpenShift Data Foundation
Der ODF-Cluster (OpenShift Data Foundation) war ein Cluster mit 6 Knoten (3 Master + 3 Worker), der aus Dell PowerEdge R7625-Knoten mit 2 AMD EPYC 9534-CPUs mit jeweils 64 Kernen und 2 Threads (128 CPUs) für 128 Kerne und 256 CPUs insgesamt bestand. Jeder Knoten enthält 512 GB RAM. Das I/O-Subsystem bestand aus 2 NVMe-Laufwerken mit 5,8 TB pro Knoten mit 3-Wege-Replikation über ein standardmäßiges Pod-Netzwerk mit 25 GbE. Ich hatte für diesen Test keinen Zugang zu einem schnelleren Netzwerk, aber neuere Netzwerkhardware hätte wahrscheinlich für einen besseren Uplift gesorgt.
Zusammenfassung der Ergebnisse
Bei diesem Test werden mehrere I/O-Threads mit spezifischen I/O-Backends bewertet, die möglicherweise nicht repräsentativ für Ihren Use Case sind. Unterschiede in den Storage-Eigenschaften können einen großen Einfluss auf die Auswahl der Anzahl von I/O-Threads haben.
Nun mehr zu den Ergebnissen meiner Tests.
- Maximaler I/O-Durchsatz: Für lokalen Storage betrug der maximale Durchsatz etwa 7,3 GB/s (Lesen) und 6,7 GB/s (Schreiben) für Pods und VMs, und zwar unabhängig von iodepth oder der Anzahl der Jobs auf dem lokalen Storage. Das ist erheblich weniger, als von der Hardware erwartet werden würde. Die Geräte (mit jeweils 4 PCIe gen4) sind für 6,9 GB/s (Lesen) und 4,2 MB/s (Schreiben) ausgelegt. Den Grund dafür habe ich nicht untersucht, aber ich habe das System auf veralteter Hardware ausgeführt. Die Top-Performance ist deutlich besser als die Performance mit einem einzelnen Laufwerk, was darauf hindeutet, dass Striping funktionierte. Bei ODF lag der Bestwert, den wir erreicht haben, bei etwa 5 GB/s (Lesen) und 2 GB/s (Schreiben).
- Bei dem I/O für große Blöcke (1 MB) kam es kaum zu einer Verbesserung, da die Performance bereits durch das System begrenzt war.
- Die optimale Wahl für die Anzahl der I/O-Threads hängt von den Workload- und Storage-Eigenschaften ab. Wie erwartet zeigten Workloads ohne signifikante I/O-Nebenläufigkeit kaum Vorteile.
- Lokaler Storage: Für VMs mit erheblicher I/O-Nebenläufigkeit sind 4–8 im Allgemeinen ein guter Ausgangspunkt. Insbesondere für Workloads mit geringer I/O-Größe und großer Nebenläufigkeit können mehr Threads von Vorteil sein.
- ODF: Mehr als 1 I/O-Thread brachte selten einen signifikanten Vorteil, und in vielen Fällen wurde gar keiner benötigt. Dies ist wahrscheinlich auf das vergleichsweise langsame Pod-Netzwerk zurückzuführen. Ein schnelleres Networking führt wahrscheinlich zu anderen Ergebnissen.
- Mehrere I/O-Threads waren bei mehreren gleichzeitigen Jobs effektiver bei der Verbesserung als mit tiefem asynchronem I/O, zumindest bei diesem Test.
- Es gab kaum Unterschiede im Verhalten zwischen 1 und 2 gleichzeitigen VMs, bis der zugrundeliegende aggregierte maximale I/O-Durchsatz (siehe oben) erreicht wurde.
- Mehrere I/O-Threads konnten die Lücke zu Pods mit einer geringeren Jobanzahl oder I/O-iodepth nicht vollständig schließen. Bei einer hohen I/O-iodepth und kleinen Vorgängen zeigten VMs eine bessere Performance als Pods bei Schreibvorgängen.
In Zahlen
Hier ist der I/O-Gesamtdurchsatz, der bei Verwendung mehrerer I/O-Threads auf meinem lokalen Storage-basierten System erreicht werden kann. Wie Sie sehen, können Workloads mit kleineren I/O-Größen und viel Parallelverarbeitung zu einem schnellen I/O-System große Vorteile bieten. Im Folgenden präsentiere ich weitere meiner Ergebnisse in Bezug auf die Vorteile, die ich mit der unterschiedlichen Anzahl von I/O-Threads erhalten habe. Bei einer Blockgröße von 1 MB konnte ich nur eine geringfügige Verbesserung feststellen, da die Performance bereits sehr nahe am zugrunde liegenden Systemlimit war. Mit noch schnellerer Hardware ist es möglich, dass zusätzliche I/O-Threads selbst bei großen Blockgrößen zu Verbesserungen führen.
Beste Verbesserung gegenüber der VM-Baseline mit zusätzlichen I/O-Threads | ||||||||||
(Lokaler Storage) | Jobs | iodepth | ||||||||
1 | 4 | 16 | ||||||||
Größe | Op | 1 | 4 | 16 | 1 | 4 | 16 | 1 | 4 | 16 |
2048 | randread | 18 % | 31 % | 30 % | 30 % | 103 % | 192 % | 151 % | 432 % | 494 % |
randwrite | 81 % | 59 % | 24 % | 153 % | 199 % | 187 % | 458 % | 433 % | 353 % | |
read | 67 % | 58 % | 25 % | 64 % | 71 % | 103 % | 252 % | 241 % | 287 % | |
write | 103 % | 64 % | 0 % | 143 % | 99 % | 84 % | 410 % | 250 % | 203 % | |
2048 Insgesamt | 67 % | 53 % | 20 % | 97 % | 118 % | 141 % | 318 % | 339 % | 334 % | |
4096 | randread | 18 % | 34 % | 28 % | 33 % | 101 % | 208 % | 156 % | 432 % | 492 % |
randwrite | 95 % | 69 % | 20 % | 149 % | 200 % | 187 % | 471 % | 543 % | 481 % | |
read | 26 % | 53 % | 27 % | 24 % | 46 % | 66 % | 142 % | 155 % | 165 % | |
write | 103 % | 69 % | 0 % | 144 % | 86 % | 48 % | 438 % | 256 % | 161 % | |
4096 Insgesamt | 60 % | 56 % | 19 % | 87 % | 108 % | 127 % | 302 % | 346 % | 325 % | |
32768 | randread | 16 % | 23 % | 26 % | 23 % | 71 % | 124 % | 99 % | 160 % | 129 % |
randwrite | 75 % | 71 % | 28 % | 108 % | 132 % | 116 % | 203 % | 123 % | 115 % | |
read | 21 % | 57 % | 25 % | 21 % | 42 % | 32 % | 77 % | 54 % | 32 % | |
write | 79 % | 64 % | 26 % | 104 % | 59 % | 24 % | 195 % | 45 % | 27 % | |
32768 Insgesamt | 48 % | 53 % | 26 % | 64 % | 76 % | 74 % | 143 % | 96 % | 76 % | |
1048576 | randread | 5 % | 2 % | 0 % | 9 % | 0 % | 0 % | 17 % | 0 % | 0 % |
randwrite | 10 % | 0 % | 1 % | 6 % | 0 % | 2 % | 9 % | 0 % | 2 % | |
read | 12 % | 18 % | 0 % | 9 % | 0 % | 0 % | 16 % | 0 % | 0 % | |
write | 19 % | 0 % | 0 % | 7 % | 0 % | 0 % | 9 % | 0 % | 0 % | |
1048576 Insgesamt | 11 % | 5 % | 0 % | 8 % | 0 % | 1 % | 13 % | 0 % | 0 % | |
Hier ist die Anzahl an I/O-Threads, die erforderlich sind, um 90 % des besten Ergebnisses zu erreichen, das mit bis zu 16 I/O-Threads erreichbar ist. Wenn beispielsweise das beste Ergebnis, das in meinem Test mit einer bestimmten Kombination aus Vorgang, Blockgröße, Jobs und iodepth erzielt wurde, 1 GB/s war, dann wäre die hier gemanagte Metrik die geringsten Threads, die benötigt werden, um 900 MB/s zu erreichen. Dies ermöglicht das Festlegen einer konservativen Anzahl von Threads bei gleichzeitig guter Performance.
Minimale Anzahl von I/O-Threads, um 90 % der besten Performance zu erreichen | ||||||||||
(Lokaler Storage) | Jobs | iodepth | ||||||||
1 | 4 | 16 | ||||||||
Größe | Op | 1 | 4 | 16 | 1 | 4 | 16 | 1 | 4 | 16 |
2048 | randread | 1 | 1 | 1 | 1 | 4 | 8 | 3 | 12 | 12 |
randwrite | 1 | 1 | 1 | 3 | 16 | 12 | 8 | 12 | 12 | |
read | 1 | 1 | 1 | 1 | 4 | 4 | 4 | 6 | 8 | |
write | 1 | 1 | 0 | 2 | 12 | 6 | 8 | 6 | 6 | |
2048 Insgesamt | 1 | 1 | 1 | 2 | 9 | 8 | 6 | 9 | 10 | |
4096 | randread | 1 | 1 | 1 | 1 | 4 | 8 | 3 | 12 | 12 |
randwrite | 1 | 1 | 1 | 3 | 16 | 12 | 8 | 12 | 12 | |
read | 1 | 1 | 1 | 1 | 2 | 3 | 3 | 6 | 8 | |
write | 1 | 1 | 0 | 3 | 12 | 4 | 8 | 6 | 4 | |
4096 Insgesamt | 1 | 1 | 1 | 2 | 9 | 7 | 6 | 9 | 9 | |
32768 | randread | 1 | 1 | 1 | 1 | 3 | 6 | 2 | 4 | 3 |
randwrite | 1 | 1 | 1 | 2 | 12 | 6 | 4 | 3 | 3 | |
read | 1 | 1 | 1 | 1 | 2 | 2 | 2 | 2 | 2 | |
write | 1 | 1 | 1 | 2 | 6 | 2 | 4 | 2 | 1 | |
32768 Insgesamt | 1 | 1 | 1 | 2 | 6 | 4 | 3 | 3 | 2 | |
1048576 | randread | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 |
randwrite | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | |
read | 1 | 1 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | |
write | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | |
1048576 Insgesamt | 1 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | |
Detaillierte Ergebnisse
Für jeden gemessenen Testfall habe ich die folgenden Leistungszahlen berechnet:
- Messung des I/O-Durchsatzes
- Beste VM-Performance (nicht direkt angegeben)
- Minimale Anzahl an I/O-Threads, um 90 % der besten VM-Performance zu erreichen
- Verhältnis zwischen bester VM-Performance und Pod-Performance
- Verbesserung der besten VM-Performance im Vergleich zur Baseline-VM-Performance
Ich gebe NICHT die Anzahl der Threads für die beste Performance an, da die Unterschiede in vielen Fällen sehr klein waren, also geringer als die normale Abweichung bei der Angabe der I/O-Performance.
Da die Eigenschaften so unterschiedlich sind, stelle ich separate Zusammenfassungen der Ergebnisse für lokalen Storage und ODF bereit.
Alle folgenden Performancediagramme zeigen Ergebnisse für Pods (pod), eine Baseline-VM ohne I/O-Threads (0) und die angegebene Anzahl von I/O-Threads auf der X-Achse.
Lokaler Storage
Wenn wir die reine Performance betrachten, sehen wir, dass die Verwendung mehrerer I/O-Threads zumindest in einigen Fällen von großem Vorteil ist. Beispiel: Bei 16 Jobs kann asynchroner I/O mit iodepth 1 auf lokalem Storage durch die Verwendung zusätzlicher I/O-Threads zu einem Vorteil in etwa in dieser Größenordnung führen:
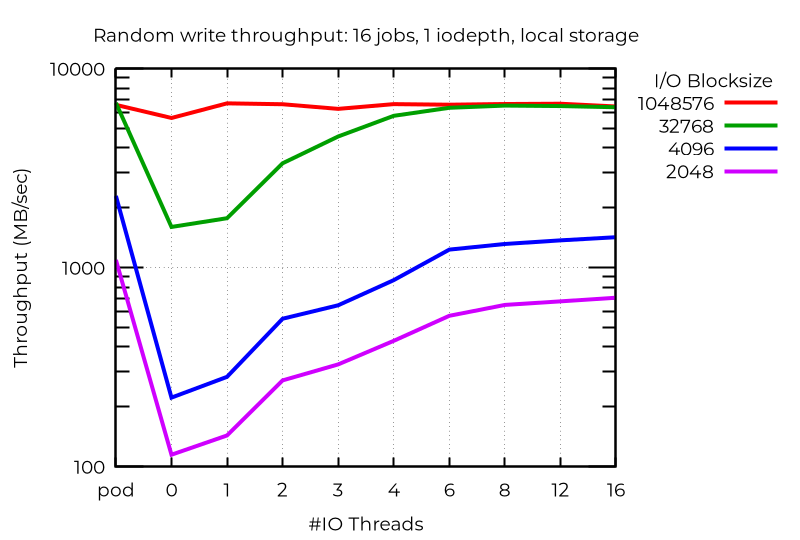
Selbst bei einem einzelnen Stream-I/O kann die Verwendung eines zusätzlichen I/O-Threads von Vorteil sein. Es überrascht nicht, dass mehr als eine nicht hilft:

Es gibt abweichende Fälle, in denen zusätzliche I/O-Threads tatsächlich die Performance beeinträchtigen. In einem solchen Fall wird bei Verwendung von tiefem asynchronem I/O mit kleinen Blöcken die beste Performance (sogar besser als Pods) mit VMs erreicht, die keine dedizierten I/O-Threads verwenden. Ich habe nicht herausgefunden, warum das so ist.
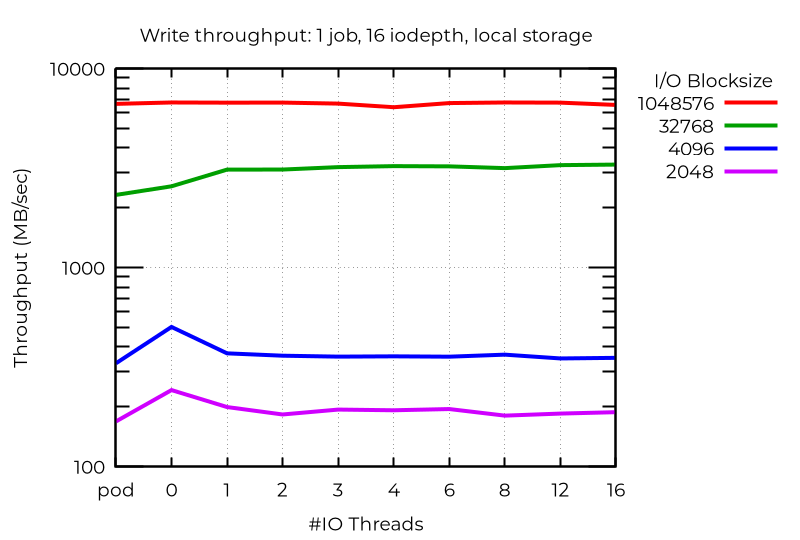
Dies zeigt, dass Sie mit Ihren jeweiligen Workloads experimentieren müssen, um die optimale Performance aus mehreren I/O-Threads herauszuholen.
ODF-Cluster-Ergebnisse
Im Gegensatz zum lokalen Storage, bei dem das zufällige Schreiben kleiner Blöcke mit mehreren I/O-Threads eine erhebliche Verbesserung zeigte, konnte ich mit ODF selbst bei einer hohen Anzahl von Jobs nur minimale Verbesserungen beobachten. Es ist wahrscheinlich, dass schnellere Netzwerke oder niedrigere Latenz größere Vorteile mit sich bringen. Lesevorgänge (read), insbesondere zufälliges Lesen (random read), zeigten einen kleinen Vorteil, aber Schreibvorgänge (write) und eine geringere Jobanzahl zeigten unwesentliche bis keine Vorteile.
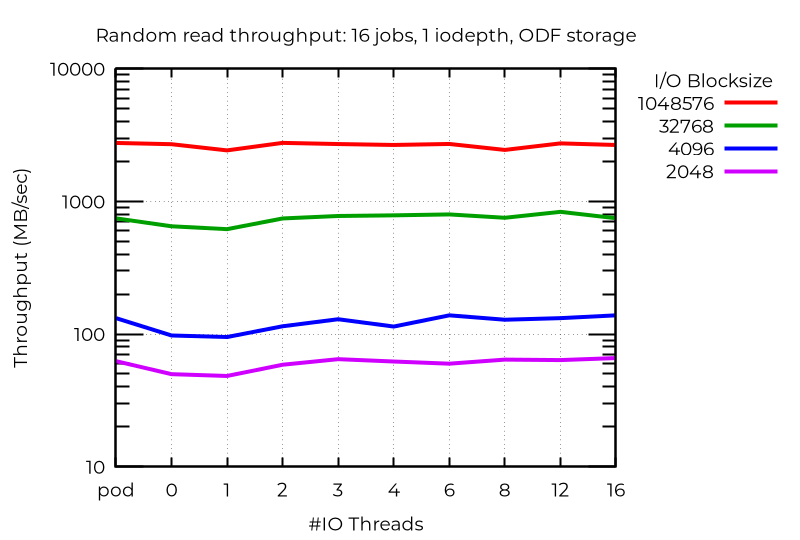
Schlussfolgerungen
Multiple I/O-Threads für OpenShift Virtualization sind eine spannende neue Funktion in OpenShift 4.19, die das Potenzial erheblicher Verbesserungen der I/O-Performance für Workloads mit gleichzeitigem I/O bietet, insbesondere bei schnellen I/O-Systemen wie dem in meinen Tests verwendeten lokalen NVMe-Storage. Schnellere I/O-Subsysteme werden voraussichtlich am meisten von mehreren I/O-Threads profitieren, da mehr CPUs benötigt werden, um den zugrunde liegende Bare Metal-I/O vollständig zu steuern. Wie immer bei I/O können Unterschiede in den I/O-Systemen und den allgemeinen Workloads die Performance stark beeinflussen. Ich empfehle daher, Ihre eigenen Workloads zu testen, um diese neue Funktion optimal zu nutzen. Ich hoffe, dass meine Testergebnisse Ihnen dabei helfen, eine gute Wahl für I/O-Threads zu treffen.
Produkttest
Red Hat OpenShift Virtualization Engine | Testversion
Über den Autor

Ähnliche Einträge
Modernize virtual machines on Google Cloud with Red Hat OpenShift Virtualization
Generate a no-cost VMware migration-readiness report with the OpenShift migration advisor
Nach Thema durchsuchen

Automatisierung
Das Neueste zum Thema IT-Automatisierung für Technologien, Teams und Umgebungen

Künstliche Intelligenz
Erfahren Sie das Neueste von den Plattformen, die es Kunden ermöglichen, KI-Workloads beliebig auszuführen

Open Hybrid Cloud
Erfahren Sie, wie wir eine flexiblere Zukunft mit Hybrid Clouds schaffen.

Sicherheit
Erfahren Sie, wie wir Risiken in verschiedenen Umgebungen und Technologien reduzieren

Edge Computing
Erfahren Sie das Neueste von den Plattformen, die die Operations am Edge vereinfachen

Infrastruktur
Erfahren Sie das Neueste von der weltweit führenden Linux-Plattform für Unternehmen

Anwendungen
Entdecken Sie unsere Lösungen für komplexe Herausforderungen bei Anwendungen
Virtualisierung
Erfahren Sie das Neueste über die Virtualisierung von Workloads in Cloud- oder On-Premise-Umgebungen