Having OpenShift (or Kubernetes) cluster nodes able to learn routes via BGP is a popular ask.
In simple scenarios where the cluster nodes have one single interface (and default gateway), everything is straightforward because there are no exceptions to the default route.
However, when you have nodes with multiple interfaces (such as multiple VLANs or bonds) or multiple physical interfaces, you might face the following scenarios:
- Dynamic routing: The network fabric around the cluster is complex, and some services are reachable via different interfaces (for example, services of type LoadBalancer announced by other Kubernetes clusters living on different networks).
- Traffic segregation: Different external services are reachable via different node interfaces because of traffic segregation requirements. The traffic directed to a given CIDR must be sent via a specific network interface (typically, a VLAN corresponding to a VRF in the router). Setting static routes simply does not scale.
- Multiple Gateways: The users want to achieve high availability for the egress traffic, having multiple DCGWs in an active-active configuration.
- Asymmetric return path: The nodes do not have a route to reach the client, so the return traffic goes via the default gateway.
The node must know the path to the client to send the return traffic to a given request via the correct interface.
Using MetalLB to receive routes
You can resolve the problems described above by allowing external routers to push routes to the node's host networking space via BGP.
MetalLB leverages the FRR stack to advertise Kubernetes services of type LoadBalancer via BGP.
Despite having an FRR instance running on each node of the cluster, this instance can't be used for purposes beyond the very specific MetalLB use case.
Allowing the FRR instance coming with MetalLB to configure the node routes
MetalLB translates its configuration described with Kubernetes CRDs to a raw FRR configuration. MetalLB provides a raw configuration that can be appended to the one rendered by MetalLB.
The FRR instance running inside MetalLB does not allow incoming routes to be propagated because of a generated rule like:
route-map 192.168.1.5-in deny 20
The rule is named after the IP of the neighbor configured in the BGPPeer instance.
Using a custom config to remove the deny rule
To enable FRR to receive the routes via BGP, a ConfigMap must be configured with one line per configured peer, such as the one below:
apiVersion: v1
kind: ConfigMap
metadata:
namespace: metallb-system
name: bgpextras
data:
extras: |
route-map 192.168.1.5-in permit 20
route-map fc00:f853:ccd:e793::5-in permit 20
This will override the deny rule put in place by MetalLB, and the FRR instance will be able to receive the routes.
Filtering the incoming prefixes
The only extra piece of allowed FRR configuration is:
- Custom prefix-lists not overlapping with the ones generated by MetalLB (with a custom name, for example, `filtered`).
- A route map per router, under the form "route-map xxxx-in permit 20" (with the same 20 index to override the one MetalLB puts in place).
- A match rule for the route map, matching the aforementioned prefix list.
Below is an example of the configuration:
ip prefix-list filtered permit 172.16.1.0/24 le 32
ip prefix-list filtered permit 172.16.2.0/24 le 32
route-map xxxx-in permit 20
match ipv4 address prefix-list filtered
Availability
This particular configuration is available in the upstream version of MetalLB https://metallb.universe.tf/ and in OpenShift 4.12+ as Tech Preview.
Known issues
Because of this FRR bug, the configuration must be in place before MetalLB establishes a session. This means that the ConfigMap must be created before the BGPPeer CRDs are, or that the speaker pods must be restarted if the ConfigMap is created after the session was already established. The bug is not present in 4.14, where a more recent version of FRR is used.
What's next
This first implementation permits you to unblock users where dynamic route learning for the cluster's nodes is required. However, MetalLB's purpose is not really receiving routes. On the other hand, running multiple FRR instances on the same node has other challenges and wastes resources.
Because of this, we are re-architecting MetalLB so that FRR will run as a separate instance with its own API that can be contributed by MetalLB, the user, or other controllers.
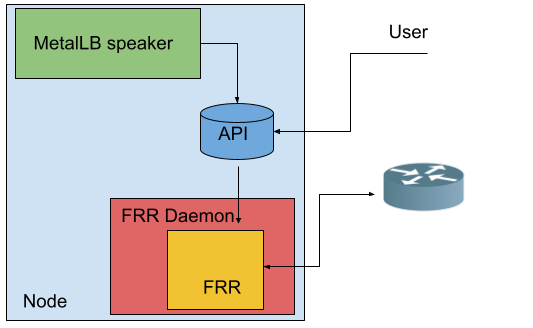
Having a single FRR instance on each node is the best way to optimize both node and router resources, as the various configurations will be able to share the same BGP/BFD session.
For more details, the upstream design proposal is available here and is currently being worked on.
Über den Autor

Ähnliche Einträge
IT-Stack vereinheitlichen: VMs, Cloud und KI vereint
Red Hat Skills Bundle: Der neue Standard für KI-Agenten
Crack the Cloud_Open | Command Line Heroes
Edge computing covered and diced | Technically Speaking
Nach Thema durchsuchen

Automatisierung
Das Neueste zum Thema IT-Automatisierung für Technologien, Teams und Umgebungen

Künstliche Intelligenz
Erfahren Sie das Neueste von den Plattformen, die es Kunden ermöglichen, KI-Workloads beliebig auszuführen

Open Hybrid Cloud
Erfahren Sie, wie wir eine flexiblere Zukunft mit Hybrid Clouds schaffen.

Sicherheit
Erfahren Sie, wie wir Risiken in verschiedenen Umgebungen und Technologien reduzieren

Edge Computing
Erfahren Sie das Neueste von den Plattformen, die die Operations am Edge vereinfachen

Infrastruktur
Erfahren Sie das Neueste von der weltweit führenden Linux-Plattform für Unternehmen

Anwendungen
Entdecken Sie unsere Lösungen für komplexe Herausforderungen bei Anwendungen
Virtualisierung
Erfahren Sie das Neueste über die Virtualisierung von Workloads in Cloud- oder On-Premise-Umgebungen