
Since the early days of OpenShift (2010), our focus has been on multi-tenancy. That is, running many applications from potentially different untrusted sources on the same instances (VMs or physical hosts). Today, with the combination of Kubernetes and OpenShift, that focus is still very prevalent.
At its core, the Kubernetes scheduler is built around the concept of managing CPU and memory resources at a container level. Every node (instances to schedule containers to) is assigned an amount of schedulable memory and CPU. Every container has a choice of how much memory and CPU it will request. And the scheduler finds the best fit given the allocated CPU and memory on the nodes.
The Basics
CPU and memory can be specified in a couple of ways:
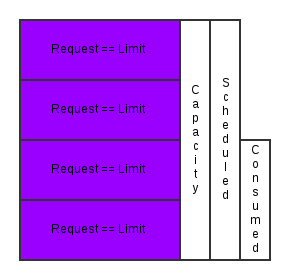
- The request value specifies the min value you will be guaranteed. This corresponds to CPU shares with CGroups and is used to determine which containers should get killed first when a system is running out of memory. The request value is also used by the scheduler to assign pods to nodes. So a node is considered available if it can satisfy the requests of all the containers in a pod (a pod is a group of related containers collocated on a node).
- The limit value specifies the max value you can consume. This corresponds to a CGroup CPU quota and memory limit in bytes. Limit is the value applications should be tuned to use.
QoS Tiers
Kubernetes defines a number of different quality of service (QoS) tiers based on how request and limit are specified.
- Best-Effort: A request value of 0 (unlimited) with no limit set is classified as best effort. Best-Effort containers are the first to get killed when resources are limited.
- Guaranteed: A container with a request value equal to its limit. These containers will never get killed based on resource constraints.
- Burstable: A container with a request value less than its limit. Will be killed after Best-Effort containers when resources are limited if their usage exceeds their request value.
While those are the basic constructs, you can consume this infrastructure in a number of ways that also affect the overall QoS to the end user. Let’s use a few examples to illustrate some common scenarios.
- Mission Critical: Most mission critical use cases are going to run with at or near guaranteed QoS (request ~ limit).
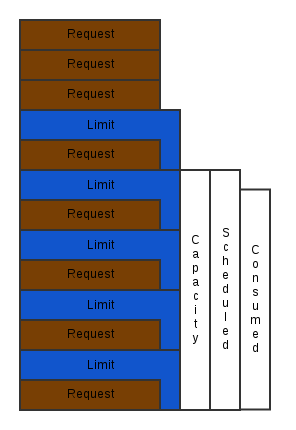
- The Over Committer: Anyone whose goal is squeeze every bit of compute out of their nodes that they can fit into this category. A common scenario that fits into this bucket is anyone executing lots of jobs where uptime isn’t as important as total work accomplished. This may not be implemented as every container being best effort though. Doing so may end up in consuming all your hardware, but could possibly spend the entire time context switching and getting OOM killed. So even in this scenario, the most effective resource constraints would still be to set the request values at the true minimums for CPU and near the expected average value for memory. Leaving the limit unset or set to a very high value is expected in this scenario. While following these rules for the majority of your containers, it can be effective to schedule a few containers as best-effort to fill in any gaps.
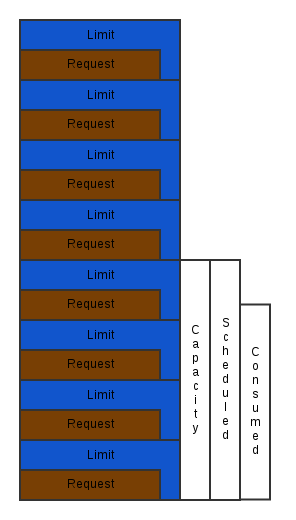
- High Density with High QoS: Let’s face it, most hardware in the world is not consumed to its fullest potential. But it’s very possible to use the burstable QoS while maintaining both high density and a high QoS. Let’s take a simple example of a single 8GB node with 8 containers running on it each with a limit set to 1GB. If under normal usage, the instance is still only consuming a small portion of its available memory. There can be a benefit in setting the limits higher than the requests without much risk of all of the containers using all their excess memory at once. You can generally tune the request to limit ratio to the point at which your consumed node resources are at a level you can feel comfortable with.
Writing Applications
As an application author, you may need to make some changes to your application to have it properly adjust to the size of the container it’s in. Essentially, any application component that by default adjusts itself to the size of the node will need to adjust itself to its CGroup limit instead. This can be accomplished by reading directly from the cgroup config or by using the downward API. A java application, for example, might want to set its max heap size to 70% of:
<span>CONTAINER_MEMORY_IN_BYTES=`cat /sys/fs/cgroup/memory/memory.limit_in_bytes`</span>
or using the downward API to set an environment variable:
env:
- name: MEM_LIMIT
valueFrom:
resourceFieldRef:
resource: limits.memoryIdeally this value would be what’s returned from free and other system commands and hopefully the usability will be improved in the future. It’s one of the few remaining cases that containers don’t provide perfect encapsulation. Or at least knowledge of the encapsulation.
Quota
To manage the overall usage, every OpenShift project can have a limit on how much memory and CPU it can consume. This limit can be specified in both request and limit values. You can also specify the min request and max limit of a given container as well as the max ratio between request and limit. See https://docs.openshift.org/latest/admin_guide/quota.html for more details.
What's Changing
As of 1.3, Kubernetes now supports eviction/rescheduling pods from memory constrained nodes. This goes beyond basic OOM killing and constantly attempts to find the best fit for pods running on the cluster. Another great feature, being delivered in 1.4, is the ability to manage resource usage at a pod level. This means you can have a shared pool of resources from which all containers in the pod can consume. In the majority of cases, these values are best set at a container level where the tuning is tied to the one process that’s running. What's interesting about this for everyone is the entire pod will now share the most restrictive eviction policy. So if one container in a pod is guaranteed, then effectively all containers in a pod are guaranteed. This provides a better lifecycle guarantees/management for a pod because you don't want a pod to be rescheduled if any containers within the pod are guaranteed.
Future
Beyond 1.4, I think the most interesting thing that can happen around quota and resource consumption is to have scheduling based on actual usage in addition to the request values. This would take the guesswork out of the operator’s hands about how much overcommit to estimate with the request to limit ratio. Instead the operator could focus entirely on the limit values and let the request be auto tuned by the system to make as much use of the hardware as desired. It will even be possible in some cases to have the limit value auto tuned but this would only be effective for non greedy applications (i.e. not most java apps).
Other Useful Resources
- http://kubernetes.io/docs/user-guide/compute-resources/
- https://docs.openshift.org/latest/admin_guide/allocating_node_resources.html
- https://docs.openshift.org/latest/admin_guide/overcommit.html
- https://docs.openshift.org/latest/admin_guide/limits.html
- https://docs.openshift.org/latest/dev_guide/compute_resources.html
I want to give a big shout out to Derek Carr who has been the leading contributor to most of this work in Kubernetes.
Über den Autor
Ähnliche Einträge
Das agentische Paradoxon und die hybride KI-Strategie
IT-Stack vereinheitlichen: VMs, Cloud und KI vereint
Diving for Perl | Command Line Heroes
The Web Developer And The Presence | Compiler: Re:Role
Nach Thema durchsuchen

Automatisierung
Das Neueste zum Thema IT-Automatisierung für Technologien, Teams und Umgebungen

Künstliche Intelligenz
Erfahren Sie das Neueste von den Plattformen, die es Kunden ermöglichen, KI-Workloads beliebig auszuführen

Open Hybrid Cloud
Erfahren Sie, wie wir eine flexiblere Zukunft mit Hybrid Clouds schaffen.

Sicherheit
Erfahren Sie, wie wir Risiken in verschiedenen Umgebungen und Technologien reduzieren

Edge Computing
Erfahren Sie das Neueste von den Plattformen, die die Operations am Edge vereinfachen

Infrastruktur
Erfahren Sie das Neueste von der weltweit führenden Linux-Plattform für Unternehmen

Anwendungen
Entdecken Sie unsere Lösungen für komplexe Herausforderungen bei Anwendungen
Virtualisierung
Erfahren Sie das Neueste über die Virtualisierung von Workloads in Cloud- oder On-Premise-Umgebungen