
The requirements associated with data science and AI/ML applications have pushed organizations toward using highly parallel and scalable hardware that often resemble high performance computing (HPC) infrastructure. HPC has been around for a while and has evolved to include ultra large supercomputers that run massively parallel tasks and operate at exascale (able to perform a billion billion operations per second). Nowadays these large systems need to run machine learning (ML) and other similar jobs that often require use of multiple containerized applications, effectively blurring the line between traditional enterprise technologies and supercomputing applications.
Additionally, the sprawl of data has affected both scientific and commercial applications, necessitating the use of a robust distributed file system for data storage, a technology that became a standard part of operating environments at many HPC sites and enterprises.
To manage the complexity of running multiple jobs in parallel the HPC community has traditionally used Message Passing Interface (MPI) with their preferred workload manager or scheduler such as SLURM, Univa Grid Engine, and others. To run and orchestrate multiple containers, enterprises have adopted Kubernetes. While containers and Kubernetes have become a norm for enterprise software development, they are not yet widely adopted in HPC.
There are benefits of using containers and Kubernetes for running HPC applications. Like other workload managers, Kubernetes allows for sharing a compute resource pool and getting access to it on-demand. For complex HPC workloads, containerization is helpful for managing and packaging complex dependencies together with applications in a portable way. Deploying containerized HPC workloads on Red Hat OpenShift Container Platform also has several security benefits that may be of interest to HPC sites.
In this blog, we will demonstrate how a typical scientific application, the molecular dynamics package called GROMACS, can run in parallel across multiple nodes on OpenShift, using MPI, while accessing data via distributed Lustre filesystem.
Lustre is one of the most popular filesystems used at large HPC sites. To use the Lustre filesystem in Linux, client systems need a kernel module. We are able to deploy the lustre client kernel module on the worker nodes in the OpenShift cluster by using the Special Resource Operator (SRO) to build and deploy driver containers for the lustre client. More information about SRO internals can be found in the blog posts “How to Enable Hardware Accelerators on OpenShift” part 1 and part 2.
The OpenShift cluster for this demo is running on AWS, so that we can use Lustre filesystems created with the Amazon FSx for Lustre service, which allows us to link the filesystem with an S3 bucket.
Once the worker nodes have the lustre client kernel module loaded by the driver container, we are able to mount lustre filesystems in pods running on those nodes. This enables us to run the aws-fsx-csi-driver for lustre on our OpenShift cluster, which can be deployed by SRO. Container Storage Interface (CSI) is a standard for exposing storage systems to containers in Kubernetes or other container orchestration systems. The aws-fsx-csi-driver is specifically designed for use with Amazon FSx for Lustre filesystems on AWS, however a similar CSI driver could be created for an on-premise Lustre instance.
GROMACS is a parallel application that can be run across multiple machines using MPI, which is the de facto standard for writing parallel message-passing applications and is prevalent in the HPC community. The MPI Operator makes it easy to deploy containerized MPI applications on OpenShift.
Now let's take a deeper look into how we can run highly parallel scientific workloads on OpenShift.
Setting up the cluster:
After the OpenShift installation, the following configuration steps need to be done before setting up the lustre client and lustre CSI driver and running the containerized GROMACS with MPI:
- Set up cluster-wide entitlements to enable the driver container builds
- Install the Node Feature Discovery Operator from Operator Hub to manage detection and labelling of features of the worker nodes, including kernel version information
- Install the MPI Operator, which creates the MPIJob CustomResourceDefinition, which allows for the creation of MPIJob objects to launch an MPI application on the OpenShift cluster.
Deploying the driver container and CSI driver for the Lustre Client with SRO:
After the cluster is set up with NFD and the MPI Operator, the next step is to deploy the Lustre client driver container and the aws-fsx-csi-driver using SRO. The following steps should be completed on the machine with oc / kubectl. You also will need golang installed to deploy SRO from source.
First, clone the git repository for the special-resource-operator, on the branch with the lustre-client recipe.
$ git clone --branch simple-kmod-v2 https://github.com/openshift-psap/special-resource-operator.git
The following command will deploy SRO in the openshift-sro namespace. It will wait for a CR to be instantiated.
$ cd special-resource-operator
$ make deploy
The aws-fsx-csi-driver requires some AWS IAM permissions to communicate with the FSx for Lustre service. Before creating the lustre-client SpecialResource, insert your credentials into spec.environment field in config/recipes/lustre-client/0000-lustre-client-cr.yaml:
environment:
- key: "key_id"
value: "XXXXXXXXXXX”
- key: "access_key"
value: "XXXXXXXXXXXXXXXXXXXX”
Then you can deploy the Lustre driver container and the CSI driver using the recipe we’ve created for SRO:
$ SPECIALRESOURCE=lustre-client make
The Lustre client driver container depends on a base driver container image which needs to be built on the entitled cluster nodes. You can watch the driver-container-base image build progress in the driver-container-base namespace:
$ oc get pods -n driver-container-base -w
Once the driver-container base is built the lustre-client driver container build will start:
$ oc get pods -n lustre-client -w
Once the container is built, the driver-container daemonset pods will start running on all worker nodes.
$ oc get pods -n lustre-client
NAME READY STATUS RESTARTS AGE
lustre-client-driver-container-rhel8-7s68x 1/1 Running 0 5m
You can also verify that the Lustre kernel modules are loaded:
$ oc exec lustre-client-driver-container-rhel8-7s68x -n lustre-client -- lsmod | grep lustre
lustre 856064 0
lmv 229376 1 lustre
mdc 204800 1 lustre
lov 323584 1 lustre
ptlrpc 1409024 8 fld,osc,fid,mgc,lov,mdc,lmv,lustre
obdclass 2220032 9 fld,osc,fid,ptlrpc,mgc,lov,mdc,lmv,lustre
lnet 491520 7 osc,obdclass,ptlrpc,mgc,ksocklnd,lustre
libcfs 495616 12 fld,lnet,osc,fid,obdclass,ptlrpc,mgc,ksocklnd,lov,mdc,lmv,lustre
The lustre-client recipe will also deploy the aws-fsx-csi-driver. To verify that the necessary pods are running, run:
$ oc get pods -n lustre-client
NAME READY STATUS RESTARTS AGE
pod/fsx-csi-controller-7bd6bcdcd-nbqwn 2/2 Running 0 70m
pod/fsx-csi-controller-7bd6bcdcd-nfz7l 2/2 Running 0 70m
pod/fsx-csi-node-nwqvt 3/3 Running 0 70m
pod/fsx-csi-node-prb4t 3/3 Running 0 70m
Once the driver container is running, and we can see that the fsx-csi-controller-* and fsx-csi-node-* pods are running, we can go ahead and use the CSI driver to dynamically create a Lustre instance in AWS, backed by an S3 bucket.
Using the CSI driver:
$ git clone https://github.com/kubernetes-sigs/aws-fsx-csi-driver.git
$ cd aws-fsx-csi-driver/
We can set up the CSI driver with an AWS Lustre for FSx filesystem in a few different ways. For a pre-existing filesystem, you can follow the static provisioning example. We already have an S3 bucket with the data we need for GROMACS, so we can follow the example for dynamically provisioning a Lustre filesystem linked to an S3 bucket.
$ cd examples/kubernetes/dynamic_provisioning_s3/specs
For dynamic provisioning, we need to specify the AWS subnet (any of the subnets in the OpenShift cluster will do), the S3 bucket, and a security group for the Lustre server. Create a security group, and then add the rules specified by AWS in this article to allow the necessary traffic between the Lustre filesystem and the worker nodes. For more troubleshooting information on using FSx for Lustre, see this documentation.
Once storageclass.yaml has been configured for your cluster, you can create the StorageClass, PersistentVolumeClaim, and test pod:
$ oc apply -f storageclass.yaml
$ oc apply -f claim.yaml
$ oc apply -f pod.yaml
The creation of the PersistentVolumeClaim will trigger the CSI driver to create a Lustre FSx filesystem. This can take several minutes. To watch the status of the filesystem, you can check the logs of one of the fsxi-csi-controller pod’s fsx-plugin containers, until you see “filesystem status is: AVAILABLE”.
$ oc logs -n lustre-client pod/fsx-csi-controller-7bd6bcdcd-qw27h fsx-plugin -f
...
I1021 20:05:37.038709 1 cloud.go:219] WaitForFileSystemAvailable filesystem status is: CREATING
I1021 20:05:52.055197 1 cloud.go:219] WaitForFileSystemAvailable filesystem status is: CREATING
I1021 20:06:07.046181 1 cloud.go:219] WaitForFileSystemAvailable filesystem status is: AVAILABLE
Then you will be able to see the contents of the S3 bucket in the fsx-app pod:
$ oc exec -it fsx-app -- ls /data
Now you are ready to run your workload using Lustre.
Running GROMACS with Lustre:
To run GROMACS, we create an MPIJob using the gromacs-mpijob.yaml file.
$ oc create -f gromacs-mpijob.yaml
After a few seconds we will see the worker and launcher pods begin running. We can follow the logs to watch the GROMACS simulation progress.
Note that to scale to different numbers of workers, we change the number of worker pod replicas, as well as the `-np` argument in the mpirun command. By setting the resources each worker pod will use, we can control how many worker pods will be scheduled to a node.
Once the environment was set up, we ran several MPIJobs for GROMACS at different scales. The following graph shows the results of running GROMACS mdrun with the water dataset, which is a common benchmark for GROMACS performance. These results are from running the simulation on m5.2xlarge instances on AWS, which have 4 real cores and 8 vCPUs.
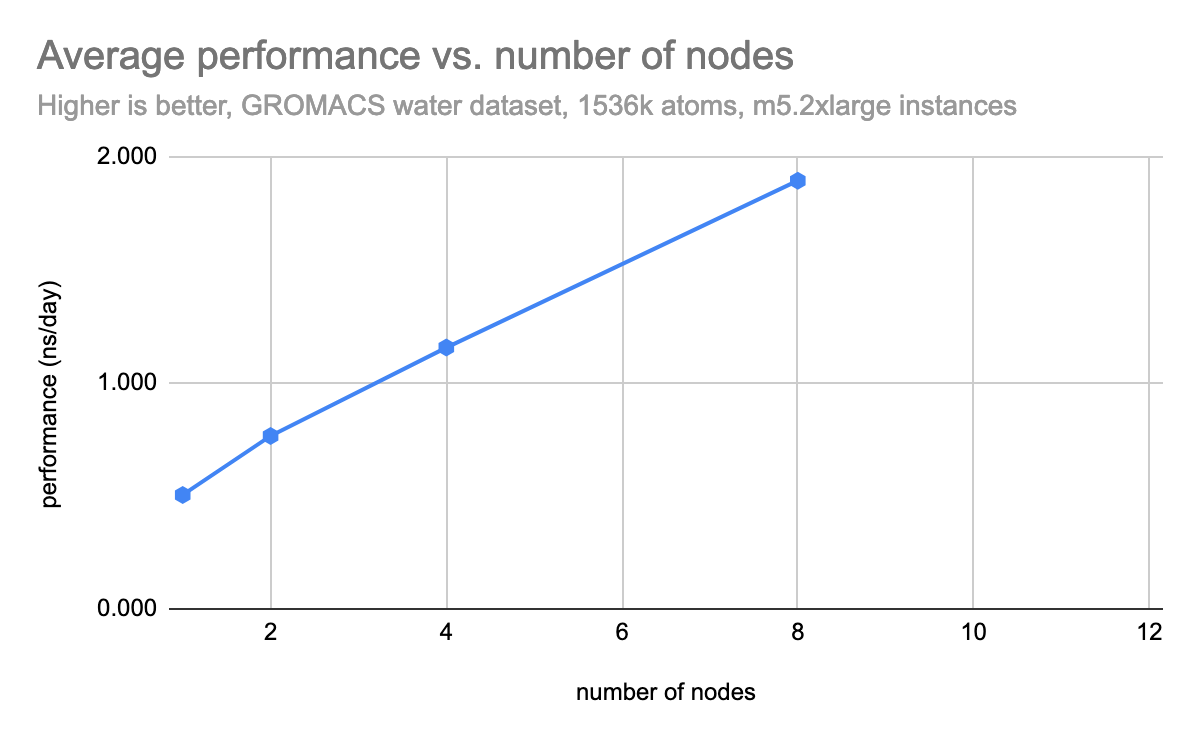
The performance scales fairly well, however it could be improved by bypassing the software-defined networking (SDN) in OpenShift. This can be done by giving the pods access to the hosts network namespace or by using Multus to create a secondary network. Giving pods access to the hosts network namespace is not always recommended because of the security implications, however to give an example of the performance improvement that can be achieved, we tested the same workload with hostNetwork enabled, as seen below.
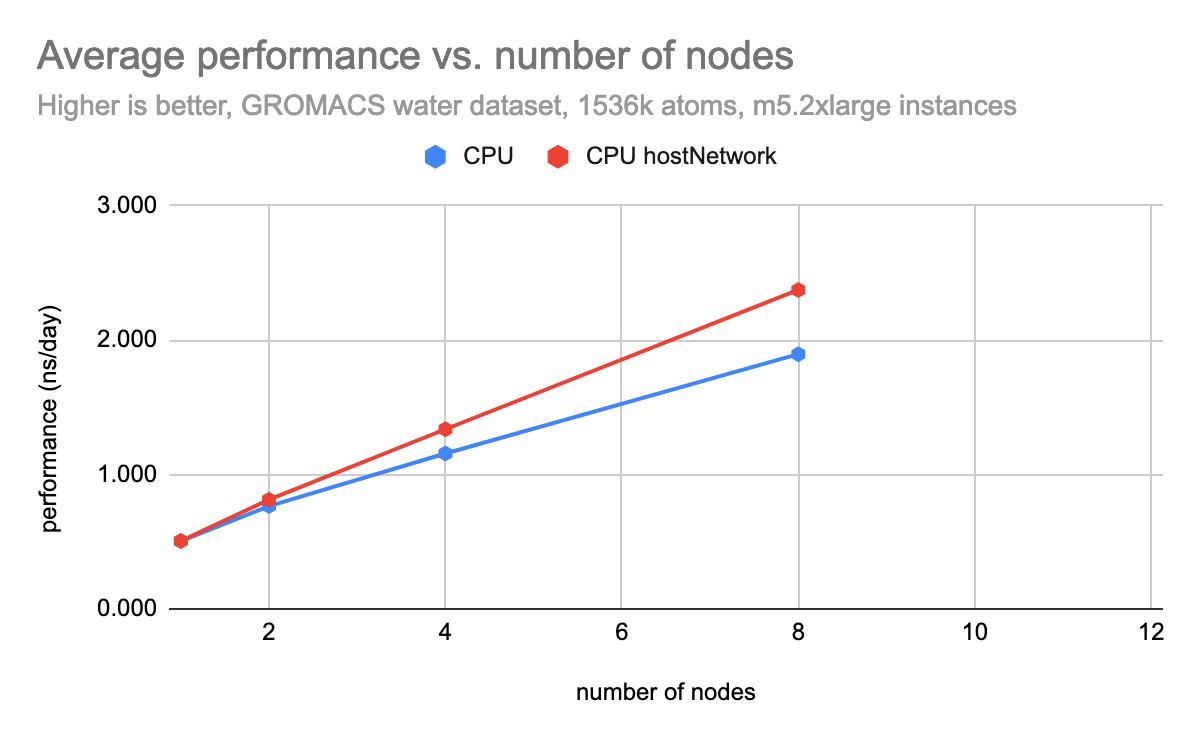
In summary, these results demonstrate how to use Openshift to run a scientific application with the MPI operator and the parallel shared Lustre filesystem. We also highlighted the use of SRO to deploy kernel modules for the Lustre client via driver container, enabling consumption of data stored in S3.
In a future blog post we plan to look at how the performance of GROMACS on OpenShift could be improved. We will evaluate the effects of running the MPI jobs on high-speed networks with Multus, isolating infrastructure pods to certain nodes and accelerating GROMACS codes with NVIDIA GPUs.
Über den Autor
David Gray is a Senior Software Engineer at Red Hat on the Performance and Scale for AI Platforms team. His role involves analyzing and improving AI model inference performance on Red Hat OpenShift and Kubernetes. David is actively engaged in performance experimentation and analysis of running large language models in hybrid cloud environments. His previous work includes the development of Kubernetes operators for kernel tuning and specialized hardware driver enablement on immutable operating systems.
David has presented at conferences such as NVIDIA GTC, OpenShift Commons Gathering and SuperComputing conferences. His professional interests include AI/ML, data science, performance engineering, algorithms and scientific computing.
Ähnliche Einträge
IT-Stack vereinheitlichen: VMs, Cloud und KI vereint
Red Hat AI 3.4: KI im Unternehmen intelligent skalieren
Technically Speaking | Inside open source AI strategy
Technically Speaking | Build a production-ready AI toolbox
Nach Thema durchsuchen

Automatisierung
Das Neueste zum Thema IT-Automatisierung für Technologien, Teams und Umgebungen

Künstliche Intelligenz
Erfahren Sie das Neueste von den Plattformen, die es Kunden ermöglichen, KI-Workloads beliebig auszuführen

Open Hybrid Cloud
Erfahren Sie, wie wir eine flexiblere Zukunft mit Hybrid Clouds schaffen.

Sicherheit
Erfahren Sie, wie wir Risiken in verschiedenen Umgebungen und Technologien reduzieren

Edge Computing
Erfahren Sie das Neueste von den Plattformen, die die Operations am Edge vereinfachen

Infrastruktur
Erfahren Sie das Neueste von der weltweit führenden Linux-Plattform für Unternehmen

Anwendungen
Entdecken Sie unsere Lösungen für komplexe Herausforderungen bei Anwendungen
Virtualisierung
Erfahren Sie das Neueste über die Virtualisierung von Workloads in Cloud- oder On-Premise-Umgebungen