
"Every AI lab is losing money serving your company right now. They know it. And they are doing it on purpose."
That was the opening line of an article that landed in my inbox the same week 3 numbers crystallized to make it clear why open inference is no longer optional.
A developer built a simple notes app over a weekend using an open source coding agent with a direct API key. One page, one feature. Cost: $50. The next day, a $20/month subscription provided 50x more tokens.
One engineer on our inference team consumed 300 million tokens through open-weight models in 2 days, doing the same work that would have cost thousands of dollars through proprietary APIs.
The first 2 numbers reveal the subsidy. The third reveals the way out. And the reason we need that way out is agents.
The pricing model is in transition
The frontier model providers have done something remarkable. They have made world-class AI accessible to millions of developers at price points that would have been unthinkable 2 years ago. That accessibility has driven an explosion of adoption. It has also created an economic structure that may not be sustainable at current rates.
The Is AI profitable yet? website tracks the AI industry's general financial picture. AI companies currently spend roughly 195% of their revenue. One contributor to the discussion calculated that, in 2024 dollar equivalents, the total AI capital expenditure in 10 years has been roughly 3x the cost of the entire U.S. Interstate Highway System. These are the kinds of investments that will eventually be reflected in service pricing.
Signs of that transition are already appearing. Reports circulated that some large enterprises are reconsidering AI coding tool licenses as token-based billing replaces flat-rate subscriptions, with per-engineer costs reaching $500 to $2,000 per month. Newer frontier models deliver modest benchmark improvements while consuming 10-25% more tokens per task. GPU supply is already locked up 3 to 4 years into the future, and several GPU cloud providers are already sold out of capacity.
None of this is a criticism of the providers. They're building the future and pricing aggressively to accelerate adoption. Per-token unit costs will likely continue to fall, and Gartner projects a 90% reduction by 2030. But as the same analysis notes, agentic workloads consume so many more tokens per task that total enterprise inference spend is expected to rise despite cheaper units. Goldman Sachs forecasts a 24-fold increase in token consumption by 2030. Enterprises planning for the next 3 to 5 years should prepare for higher aggregate costs, not lower. Open source models running on self-managed infrastructure are the release valve that will help keep AI accessible as consumption scales.

Figure 1: The agentic inference cost paradox. Per-token costs fall 90% (Gartner) but total consumption rises 24x (Goldman Sachs), resulting in higher aggregate enterprise spend despite cheaper units.
Agents changed the equation
Subscription pricing was designed for humans typing at human speed. Agents generate orders of magnitude more API calls, and no existing pricing model was built for that.
One OpenClaw contributor consumed $1.3 million in OpenAI API tokens in a single month. That's 603 billion tokens across 7.6 million requests from roughly 100 Codex instances operated by 3 people. On a single day, that account logged $19,985.84 in spend.
Jensen Huang stated that agent token consumption has increased by roughly 1,000x compared to traditional model usage. On the Latent Space podcast, Marc Andreessen said his circle spends $1,000 per day on Claude tokens running agents, with latent demand of $5,000 to $10,000 per day per fully deployed personal agent. Even with a 10x price improvement, that is still $100 per day. "Still way beyond what people can pay."
Some providers have already had to restrict third-party agent frameworks from running under flat-rate subscriptions because the compute demands exceeded what the pricing model could sustain. Flat-rate pricing and autonomous agent workloads are structurally mismatched.
Cost is only part of the problem. Agentic workloads have technical requirements that proprietary APIs were never designed to expose.
API fragmentation. The agentic API landscape has multiple competing standards. Chat Completions (OpenAI's original stateless format), Responses API (OpenAI's newer stateful format with built-in tools and Model Context Protocol integration), Messages API (Anthropic's format), and Interactions API (Google's agentic protocol). Each handles tool calling, state management, and reasoning differently. Each harness picks a different one.
Each model family also wraps the same tool call in completely different tags. Sending get_weather(city="Seattle") to 5 models produces 5 different formats: Llama uses Python syntax with <|python_tag|>, Mistral uses [TOOL_CALLS] with JSON arrays, Gemma uses <tool_code>tags, and Hermes uses <tool_call>XML. The inference engine needs a separate parser for every model family.
Tool calling. Behind a proprietary API, you get whatever parser the provider ships. You can't customize it. You can't fix a model that outputs Pythonic syntax instead of its trained format. You're a passenger.
Model routing. A single agent run generates heterogeneous sub-tasks, some require deep reasoning, some require fast classification, and some require code generation. Routing these tasks to different models requires control over the serving layer. Behind a single provider's API, every task goes to the same model at the same price.
Context engineering. Managing what reaches the model across many turns is the highest-leverage optimization available. A well-tuned context pipeline can reduce token usage by 60-80% while improving output quality. But effective context engineering requires access to the model's behavior at the inference level, because you need to measure what the model actually attends to, identify which context tokens contribute to output quality, and tune summarization and retrieval strategies based on real attention patterns rather than guesswork.
Circuit breakers. Without control over the inference layer, you can't implement per-agent budgets, anomaly detection, or automatic shutdown at the model server level. Having been on the receiving end of a runaway loop, I can tell you the provider will not save you.
Economists call this the Jevons Paradox. William Stanley Jevons noticed the pattern in 1865. As coal engines became more efficient, total coal consumption increased. AI tokens are on the same trajectory. Every efficiency gain unlocks new use cases that consume more than the gain saved. The companies that achieve outcome-per-token will use more AI, not less.
Open models are ready for agentic work
As mentioned above, our inference team processed 300 million tokens using open-weight models in 2 days. Nemotron 3 Super, Gemma 4, and Qwen 3.6, all running on the Red Hat AI inference stack. The result was strong enough for pull request reviews, first-pass implementations, and targeted investigations, offloading work that would otherwise go to frontier models and accumulate token costs.
The cost gap isn't marginal. Benchmarks on consumer Blackwell GPUs show that a $500 GPU running open-weight models can process 30 million tokens per day. At that volume, the hardware cost is recovered within 3 months compared to what the same workload would cost through budget-tier API providers at ~$0.20 per million tokens. Against frontier API pricing, the return on investment period drops to days.
A researcher built a coding agent that achieved 87% on benchmarks using a model that activates only 4 billion parameters per token. Agents using 14 billion parameter models scored 75%. The difference wasn't the model, it was compound tools and an error feedback loop. The harness did the heavy lifting, not the model size.
Making open models work well for agentic scenarios requires real engineering, and that engineering is exactly what open source enables. A recent demo of Gemma 4 running with OpenCode and Claude Code shows what this looks like in practice, with custom chat template adjustments, tool call parser tuning for each model family, and prompt formatting across multiple API standards. The 4 billion parameter model needed different handling than the 26 billion parameter quantized version, which needed different handling than the 31 billion parameter model.
This is the kind of work that closes the gap between benchmark performance and real-world agentic performance. It involves translating between chat completion, messages and responses APIs, and parsing model output with fuzzy logic, because models sometimes miss their tool call start tokens or generate unexpected syntax influenced by the harness's system prompts.
This work is happening upstream in vLLM, in model vendor chat templates, and in harness bug reports. And it can only happen in the open. With a proprietary inference server, you can't submit a chat template fix, tune a tool call parser, or even observe why your agent's output is failing. With open source, every fix benefits every user and every parser upgrade is permanent. This upstream integration work, making open-weight models reliable for agentic workloads across the full serving stack, is a core focus of Red Hat AI.
The agentic inference stack
There are 8 layers that must work together for agentic inference at enterprise scale. Every layer interacts with every other layer.
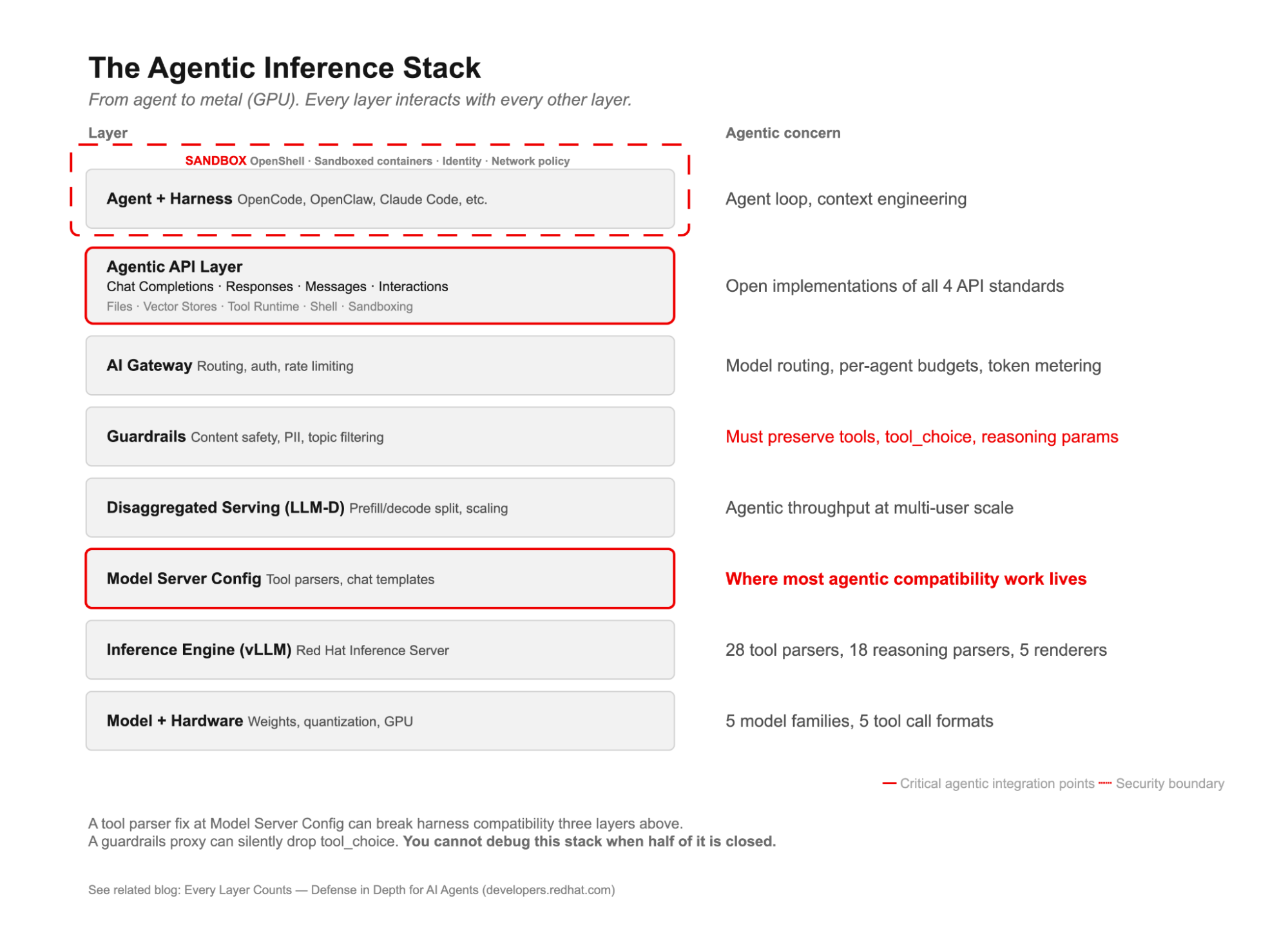
Figure 2: The agentic inference stack, from agent and harness at the top through API translation, gateway, guardrails, disaggregated serving, model server configuration, inference engine, and finally hardware at the bottom. Red borders highlight the 2 layers where most agentic compatibility work lives. The dashed sandbox boundary wraps the agent layer where code execution and security controls are tightest.
Assembling these layers from individual open source projects is possible but operationally expensive. The value of a self-managed inference platform such as Red Hat AI is that they are integrated into a tested, supported stack that runs on your infrastructure, so your data never leaves your security boundary, and you control the upgrade cycle, model selection, and routing policy.
The agentic API layer
The API diversity problem is real. Harnesses speak Chat Completions, Responses, Messages API, or Interactions API, and the model server underneath doesn't necessarily support them all. The agentic API layer sits between the harness and the infrastructure to help bridge this gap. Projects like OGX (formerly Llama Stack) provide open implementations of the agentic APIs themselves: Chat Completions, Responses API, Messages API, and Interactions API, along with supplementary capabilities like vector stores, file management, and tool execution, all on top of whatever model serving layer you run.
No single API standard is slated to win the race at this point, despite the first-mover advantage of some APIs. What matters is having open source implementations of them all, so you can match any harness to any model, whenever you need. When the translation layer is open, it preserves the full tool calling contract, and you can see exactly what happens to your request. When a proprietary provider handles the translation, you'll never know what gets lost.
llm-d: Scaling agentic inference
Single-instance vLLM works for one engineer running agents, but it doesn't work for a hundred engineers hitting the same models simultaneously. llm-d is the disaggregated serving layer that splits inference into separate prefill and decode phases, allowing them to scale independently on different hardware. For agentic workloads, where many short requests interleave with long reasoning chains, this architecture is increasingly essential.
Guardrails and sandboxing
Content safety sits in this stack too, and it has to be agentic-aware. Guardrails frameworks that operate as proxies need to preserve the full agentic API contract, including tool definitions, tool choice, and reasoning parameters, or they risk silently degrading agent behavior.
Effective agentic guardrails also require access to inference-level data that simple input/output text filtering can't provide, such as reasoning traces to evaluate whether the model's chain-of-thought contains unsafe steps before the final output, tool call parameters to validate that invoked tools and arguments are within policy, token-level logarithmic probabilities (logprobs) to detect hallucination risk and low-confidence outputs, and generation metadata for audit trails and compliance logging. This is another reason the inference layer should be open. Guardrails that can only see the text going in and out are insufficient for agentic workloads.
If your guardrails proxy is a black box that strips tool-calling parameters, when your agents fail, you can't diagnose why. Open source guardrails (such as the NVIDIA NeMo Guardrails non-proxying /v1/guardrails/checks endpoint) enforce content safety without breaking the agentic API contract.
Sandboxing is another factor. Agents execute code, write files, and invoke tools. Defense in depth requires layered isolation, including container-level confinement, network policy, file system restrictions, and runtime enforcement. Placing an agent in a container isn't sufficient. The sandbox boundary in the stack diagram wraps the agent and harness because that's where arbitrary code execution can happen, and where security controls must be tightest.
Why open source wins
You can't test an 8-layer stack when you can't see what half the layers are doing. You can't debug failing tool calls when you can't see the parser. You can't enforce safety when the guardrails proxy silently drops the parameters agents need. The stack is too coupled for any single layer to be opaque. Integrating and hardening these layers together, so enterprises don't have to assemble the stack themselves, is the problem Red Hat AI is built to solve.
Beyond the technical argument, open inference is inevitable for structural reasons that go beyond cost.

Figure 3: Open inference vs. proprietary APIs for agentic workloads. Proprietary APIs lead on ease of setup and frontier model quality. Open inference leads on the 7 capabilities agentic workloads depend on in production: model routing, tool call debugging, domain customization, per-agent budgets, data residency, provider independence, and inference-level guardrails.
Education accelerates the entire field. Open source delivers 2 things, free software and free knowledge. DeepSeek R1 showed this clearly. Reasoning capabilities existed in proprietary models for months before the broader community could replicate them. Once DeepSeek published the code and the paper, every major lab had reasoning capabilities within 3 months. The knowledge diffusion effect is more valuable than the model itself. Applied to agentic inference, every tool call parser fix, every chat template improvement, and every harness patch becomes shared infrastructure that compounds across the entire ecosystem.
Trust requires transparency. Not every organization is willing to route all of its data and workflows through a handful of cloud model providers. For some, it is a matter of strict compliance. Industries like healthcare and finance face rigid regulatory requirements around data privacy and residency. For others, it's a strategic choice to avoid vendor lock-in and retain complete ownership over their intellectual property.
Open source gives organizations the option to run models on their own terms, under their own security boundaries, with full visibility into how the system works. For regulated industries, government, and security-sensitive workloads, this is a requirement. Regulation is moving in the same direction: the EU AI Act's transparency obligations, enforceable from August 2026, require technical documentation covering model architecture, training procedures, and performance characteristics. Open source models that already publish this information qualify for exemptions that closed models don't.
Customization requires owned weights. Behind a closed API, every organization runs the same model. When you own the weights on your own infrastructure, you can fine-tune for your domain, your internal tooling, and your codebase conventions without sending proprietary data externally. Healthcare organizations fine-tune for clinical terminology and patient record formats. Legal teams adapt models to jurisdiction-specific language and contract structures. Financial institutions train on their proprietary risk models and compliance frameworks. For agentic workloads, this is the difference between a general-purpose agent and one that already understands how your systems work.
Open source creates ecosystem gravity. When hardware vendors invest in open source inference software, more accessible models drive broader hardware adoption. Investments in vLLM (the inference runtime) optimizations and improvements to the open source serving stack make every GPU more capable of agentic workloads and enable hardware reusability. The result is a virtuous cycle in which open source software improvements compound across the entire ecosystem.
The next phase favors distributed models. The emerging pattern is "shared context-centric," with many models working on shared knowledge graphs and context stores. This inverts the focus from a single massive model to an ecosystem of specialized models coordinated by an intelligent harness. You don't necessarily need one model that can do everything. More often, what you'll need is many specialized models, each doing what it does well, working together as a compound system. That architecture is inherently more open and distributed.
Emerging agent architectures like Pi and OpenClaw, amongst others, are already built this way. Their design is minimal, often including a large language model (LLM), a bash shell, a file system, markdown state files, and a cron loop. State lives in files, not weights, so you can swap the LLM without losing agent memory. These agents work with any model, closed or open. But when the full stack is open, from model weights through serving infrastructure, every structural advantage compounds together: you fine-tune for your domain, route across models you control, observe with tools you own, and swap any layer without disrupting the rest. That is what makes open inference a natural foundation for agentic AI and Red Hat AI as the platform powering it.
How to prepare
3 things to do now, before the pricing changes arrive.

Figure 4: 3 actions to prepare for open agentic inference, each with specific tools from the Red Hat AI stack. The timeline shows a 12-month ramp from API portability to full self-managed agentic infrastructure.
Build harness-agnostic. How you engineer your agentic harness and agents matters as much as which model you run, if not more. If your agents are hardcoded to a single provider's API, you have locked yourself in before the pricing changes arrive. You should build for model and API portability. This is where projects like OGX, available through Red Hat AI, fit in, providing the open translation layer across Chat Completions, Responses, Messages, and Interactions APIs so your agents remain portable regardless of which model or provider sits underneath.
Self-host the volume on managed infrastructure. A single GPU running a quantized Gemma 4 or Qwen model can already handle pull request reviews, documentation, and code summarization. Use API subscriptions for workloads that genuinely need frontier reasoning, or where frontier models still hold a clear quality advantage, and self-host the rest on infrastructure you control. A self-managed inference platform handles the operational complexity of model serving, scaling, routing, and observability so your team can focus on building agents rather than maintaining the serving stack.
As open source models continue to close the gap with frontier capabilities, the workloads you can self-host will only grow. Starting now builds the operational readiness you'll need when open models cover the full stack. Research on model routing shows that directing the majority of requests to smaller or self-hosted models, escalating only complex tasks to frontier APIs, can reduce costs by 60-85% with minimal quality loss.
Test end-to-end across the agentic stack. A model that passes benchmarks can still fail when the harness prompts it incorrectly, the tool parser misreads output, or the gateway routes the wrong tasks. Testing model-harness-configuration triples is the right approach.
Build token budgeting into your process as well. Per-agent limits. Per-feature attribution. Anomaly detection. MLflow Tracing, already part of the Red Hat AI stack, captures prompts, reasoning steps, tool invocations, and token costs with full OpenTelemetry compatibility. You want the budget alerts before you need them.
Build for what comes next
Hardware normally depreciates. GPUs for open inference are doing the opposite. The chips do not change, but the software running on them keeps improving. Better batching and attention kernels in vLLM push more tokens per second through the same silicon. Quantization breakthroughs fit models that once required 80GB into 20GB at comparable quality. Disaggregated serving splits workloads so the same cluster handles more concurrent agents. An enterprise GPU purchased three years ago produces more useful inference today than it did the day it was installed, because the open source stack has improved around it.
That compounding is the thread that runs through this entire argument. Open tool call parsers get better for everyone. Open chat templates fix compatibility once, permanently. Open guardrails that preserve the agentic API contract protect every deployment, not just one vendor's customers. Open disaggregated serving scales on hardware you already own.
This is what an open source AI platform is for. Not just serving models, but owning the full agentic inference stack, on your own infrastructure, from the API layer that translates between harness and model, through the gateway that routes and meters, down to the serving engine and the hardware it runs on, what we call "metal to agents." Your data stays within your security boundary. Your models run where you choose. Your costs are predictable because you control every layer. Every layer is open. Every layer is debuggable. Every improvement is shared.
The models are good enough (and getting better day by day). The stack is taking shape. The economics are clear. The question is not whether open agentic inference will happen (it already has), it's whether you'll be prepared when the bill arrives.
Ressource
Einstieg in die KI-Inferenz
Über den Autor
Adel Zaalouk is a product manager at Red Hat who enjoys blending business and technology to achieve meaningful outcomes. He has experience working in research and industry, and he's passionate about Red Hat OpenShift, cloud, AI and cloud-native technologies. He's interested in how businesses use OpenShift to solve problems, from helping them get started with containerization to scaling their applications to meet demand.
Ähnliche Einträge
Agentische KI erfordert einen neuen Infrastruktur-Stack: AMD und Red Hat bieten eine Lösung
IT-Stack vereinheitlichen: VMs, Cloud und KI vereint
Technically Speaking | Inside open source AI strategy
Technically Speaking | Build a production-ready AI toolbox
Nach Thema durchsuchen

Automatisierung
Das Neueste zum Thema IT-Automatisierung für Technologien, Teams und Umgebungen

Künstliche Intelligenz
Erfahren Sie das Neueste von den Plattformen, die es Kunden ermöglichen, KI-Workloads beliebig auszuführen

Open Hybrid Cloud
Erfahren Sie, wie wir eine flexiblere Zukunft mit Hybrid Clouds schaffen.

Sicherheit
Erfahren Sie, wie wir Risiken in verschiedenen Umgebungen und Technologien reduzieren

Edge Computing
Erfahren Sie das Neueste von den Plattformen, die die Operations am Edge vereinfachen

Infrastruktur
Erfahren Sie das Neueste von der weltweit führenden Linux-Plattform für Unternehmen

Anwendungen
Entdecken Sie unsere Lösungen für komplexe Herausforderungen bei Anwendungen
Virtualisierung
Erfahren Sie das Neueste über die Virtualisierung von Workloads in Cloud- oder On-Premise-Umgebungen