-
Produkte und Dokumentation Red Hat AI
Eine Plattform mit Produkten und Services für die Entwicklung und Bereitstellung von KI in der Hybrid Cloud.
Red Hat AI Enterprise
Erstellen, entwickeln und stellen Sie KI-gestützte Anwendungen in der Hybrid Cloud bereit.
Red Hat AI Inference Server
Optimieren Sie die Modell-Performance mit vLLM für schnelle und kosteneffiziente Inferenz in großem Umfang.
Red Hat Enterprise Linux AI
Entwickeln, testen und führen Sie generative KI-Modelle mit optimierten Inferenzfunktionen aus.
Red Hat OpenShift AI
Entwickeln und implementieren Sie KI-gestützte Anwendungen und Modelle in großem Umfang in Hybrid-Umgebungen.
-
Lernen Grundlagen
-
KI-Partner
Warum Sie sich mit KI-Inferenz befassen sollten
Einfach ausgedrückt: Ohne Inferenz gibt es keine KI.
Inferenz ist der Kern generativer KI. Doch wenn große Modelle immer umfangreichere Strategien umsetzen sollen, kann es zu Komplikationen kommen.
Deshalb analysieren wir die Herausforderungen und Chancen, die mit KI-Inferenz verbunden sind – von der Modelloptimierung mit vLLM bis hin zu den aktuellsten verteilten Open Source Frameworks wie llm-d.
Die Bedeutung von Inferenz
Inferenz ist der letzte Schritt in einem langen und komplexen Machine Learning-Prozess, bei dem ein Modell die gewünschte Ausgabe bereitstellt.
Vor allem aber ist sie eine für die erfolgreiche Anwendung von KI notwendige Funktion.
Deshalb können Hardware und Software, die Ihre Inferenzfunktionen unterstützen, über Erfolg oder Misserfolg Ihrer KI-Strategie entscheiden.

Hindernisse bei der Skalierung
Aufgrund der immer größer werdenden Modelle gerät die Inferenz unter erheblichen Druck. Je komplexer die Modelle werden, desto langsamer wird die Inferenz.
Für erfolgreiche Inferenz müssen KI-Modelle viele Berechnungen in kurzer Zeit durchführen. Daher können Faktoren wie Modellgröße, hohes Nutzervolumen und Latenz die Performance einschränken.
Wenn Modelle mehr Daten und Speicher benötigen, können Hardware und Beschleuniger nur schwer mithalten.
66 %
der KI-Rechenressourcen werden voraussichtlich im Jahr 2026 für Inferenzzwecke genutzt werden, ein gestiegener Bedarf im Vergleich zu 33 % im Jahr 2023 und 50 % im Jahr 2025.1
Verbesserte Inferenz
Durch Optimieren der Inferenz können KI-Modelle schneller und intelligenter ausgeführt werden.
Zu den Optimierungsmethoden gehören eine effizientere Nutzung von GPUs, spekulative Dekodierung, Sparsity, die Komprimierung von Modellen mit Quantisierungstechniken und verteilte Inferenz.
Tools wie LLM Compressor nutzen die aktuellsten Erkenntnisse aus der Forschung zur Modellkomprimierung, um LLMs kleiner, energieeffizienter und schneller zu machen. So lassen sich die Hardwareanforderungen reduzieren und die Effizienz steigern – ohne Verlust an Genauigkeit.
Dank solcher Optimierungen bleibt die KI-Inferenz kosteneffizient und kann so mit Ihren Teams nach und nach skaliert werden.
> 99 %
Genauigkeit bei Optimierungen mit LLM Compressor2

2-mal
mehr Rechenleistung durch komprimierte Modelle, ohne Verlust an Genauigkeit3
50 %
Kosteneinsparungen ohne Performance-Einbußen bei der Modelloptimierung mit LLM Compressor4

Inferenzoptimierung durch vLLM
Das Optimieren von Modellen allein reicht nicht aus. Sie benötigen außerdem eine leistungsstarke Inferenz-Engine. Hier kann vLLM weiterhelfen.
Traditionelle LLM-Speicherverwaltungssysteme organisieren den Speicher nicht besonders effizient. Das führt zur Verlangsamung von LLMs. vLLM nutzt PagedAttention, eine Speicherverwaltungstechnik, die sich wiederholende Schlüsselwerte identifiziert, um den LLMs zusätzliche Arbeit zu ersparen.
So kann vLLM den GPU-Speicher besser nutzen und die generative KI-Inferenz beschleunigen. Dadurch lässt sich der Durchsatz (die Anzahl der pro Sekunde verarbeiteten Tokens) maximieren, um viele Nutzende gleichzeitig zu unterstützen.
Durch den effizienteren Einsatz von Beschleunigern können Modelle mehr Berechnungen in kürzerer Zeit durchführen, sodass Teams mehr Nutzende und Agenten schneller unterstützen können.
50 %
Weniger Parameter bei Verwendung einer Sparsity-Struktur5

2,1-fache
Verringerung der Inferenzlatenz durch spekulative Dekodierungstechniken6
24-fach
höhere Durchsatz-Performance mit vLLM im Vergleich zu Mitbewerbern7
Gründe für die zunehmende Verbreitung von vLLM
vLLM hat dazu beigetragen, die Kernprobleme im Zusammenhang mit einer effizienten GPU-Nutzung zu lösen und niedrigere Kosten pro Token sowie eine stabile Latenz in großem Umfang zu erzielen, und zwar mit einem offenen, portierbaren Deployment-Ansatz.
Deshalb ist die vLLM-Community so aktiv und lebendig. Beiträge stammen von engagierten Unternehmen wie Hugging Face, UC Berkeley, NVIDIA, Red Hat und vielen anderen. Die Community testet und verbessert die Software im Open Source-Projekt kontinuierlich.
Mit Day 0-Support für sämtliche wichtigen Modelle und Beschleuniger ist diese Art der Zugänglichkeit sowohl für die Branche als auch für die Wissenschaft attraktiv.
über 10.000
vLLM GitHub Commits* – ein Anstieg von über 200 % – im Jahr 2025
Aktueller Stand der vLLM Community
über 500.000
GPUs rund um die Uhr im Einsatz8
über 200.000
verschiedene Beschleunigertypen9
über 500.000
unterstützte Modellarchitekturen9
über 2.200
Einsatzbereiche verteilter Inferenz
Verteilte Inferenz sorgt dafür, dass KI-Modelle die Inferenzarbeit auf eine Gruppe miteinander verbundener Geräte aufteilen können.
Wenn ein Modell verschiedene Anforderungen gleichzeitig erfüllen kann, reduziert dies den Hardwarebedarf erheblich und erhöht die Inferenzeffizienz.
Verteilte Inferenz nutzt Techniken wie Tensorparallelität, intelligente Inferenzplanung und Disaggregation. Durch die Kombination mit vLLM verwandelt sich Inferenz in eine äußerst effiziente Multitasking-Maschine.
So bleibt Inferenz beobachtbar, skalierbar und konsistent.
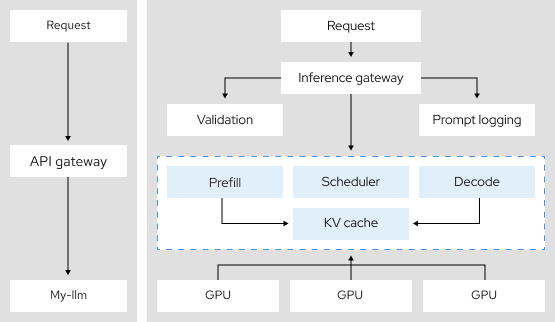
3,9-mal
höherer Token-Durchsatz durch Tensorparallelität, eine verteilte Inferenzarchitektur10
Gibt es dafür eine Open Source Community?
Ja, sie heißt llm-d.
llm-d ist ein Open Source Framework, das Entwicklungsteams einen Blueprint für das Entwickeln verteilter Inferenz in großem Umfang bietet.
Die modulare Architektur unterstützt die komplexen Ressourcenanforderungen anspruchsvoller LLMs und ersetzt manuelle, fragmentierte Prozesse durch integrierte Well-lit Paths, wodurch die Zeit vom Pilotprojekt bis zur Produktion verkürzt wird.
llm-d integriert Inferenz in Kubernetes und bietet ein standardisiertes Toolkit, mit dem Sie verteilte Inferenz auf Ihre individuellen Unternehmensanwendungen anwenden können.
2-fache
QPS (Baseline of Queries Per Second), unterstützt von llm-d11
Weitere KI-Ressourcen
Red Hat AI Inference
Beschleunigen Sie die Umsetzung Ihrer LLMs vom Code zur Produktion.
Unsere auf vLLM basierende Inferenz-Engine für Unternehmen ermöglicht schnellere Inferenz ohne Einbußen bei der Performance.
Skalieren Sie Ihre Hybrid Cloud mit Ihrem bevorzugten und optimierten gen KI-Modell, auf beliebigen KI-Beschleunigern und in beliebigen Cloud-Umgebungen.

Verwendete Quellen
[1] „Why AI’s Next Phase Will Likely Demand More Computing Power—Not Less.“ The Wall Street Journal, 22. Jan. 2026.
[2] Kurtić, Eldar, et al. „Wir haben über eine halbe Million Auswertungen von quantisierten LLMs durchgeführt – hier sind die Ergebnisse.“ Red Hat Developer Blog, 17. Okt. 2024.
[3] Condado, Carlos. „Ein strategischer Ansatz für die Performance von KI-Inferenz.“ Red Hat Blog, 15. Sept. 2025.
[4] Zelenović, Saša. „Das volle Potenzial von LLMs ausschöpfen: Optimieren Sie die Performance mit vLLM“, Red Hat Blog, 27. Feb. 2025
[5] Kurtić, Eldar, et al. „2:4 Sparse Llama: Kleinere Modelle für effiziente GPU-Inferenz.“ Red Hat Developer Blog, 28. Feb. 2025.
[6] Marques, Alexandre, et al. „Fly Eagle(3) fly: Schnellere Inferenz mit vLLM und spekulativer Dekodierung.“Red Hat Developer Blog, 1. Juli 2025.
[7] Kwon, Woosuk, et al. „vLLM: Einfacher, schneller und günstiger LLM-Service mit PagedAttention.“ vLLM Blog, 20. Juni 2023.
[8] Goin, Michael. „[vLLM Office Hours Nr. 38] vLLM 2025 Retrospective & 2026 Roadmap – 18. Dezember 2025.“ YouTube, 8. Dez. 2025.
[9] Kwon, Woosuk. „Today, vLLM supports 500+ model architectures, runs on 200+ accelerator types, and powers inference at global scale.“ X, 26. Jan. 2026.
[10] Goin, Michael. „Verteilte Inferenz mit vLLM.“ Red Hat Developer, 6 Feb. 2025.
[11] Shaw, Robert. „llm-d: Kubernetes-native distributed inferencing.“ Red Hat Developers, 20. Mai 2025.