

Wir beobachten einen deutlichen Trend: Immer mehr Unternehmen bauen ihre LLM-Infrastruktur (Large Language Model) intern auf. Unabhängig davon, ob es um Latenz, Compliance oder Datenschutz geht – durch Self-Hosting mit Open Source-Modellen auf Ihrer Hardware behalten Sie die Kontrolle über Ihre KI-Einführung. Die Skalierung von LLMs von einem experimentellen zu einem produktionsreifen Service ist jedoch mit erheblichen Kosten und Komplexität verbunden.
Das neue Open Source Framework llm-d, das von Mitwirkenden wie Red Hat, IBM und Google unterstützt wird, wurde entwickelt, um diese Herausforderungen zu meistern. Es konzentriert sich auf den Kern des Problems: KI-Inferenz – den Prozess, bei dem Ihr Modell Ergebnisse für Prompts, Agenten, Retrieval-Augmented Generation (RAG) und mehr generiert.
Durch intelligente Planungsentscheidungen (Disaggregation) und KI-spezifische Routing-Muster ermöglicht llm-d eine dynamische, intelligente Workload-Distribution für LLMs. Warum ist das so wichtig? Erfahren Sie, wie llm-d funktioniert und wie es Ihnen helfen kann, KI-Kosten zu sparen und gleichzeitig die Performance zu steigern.
Die Herausforderung bei der Skalierung der LLM-Inferenz
Die Skalierung traditioneller Webservices auf Plattformen wie Kubernetes folgt etablierten Mustern. Standardmäßige HTTP-Anforderungen sind in der Regel schnell, einheitlich und zustandslos. Die Skalierung der LLM-Inferenz ist jedoch ein grundlegend anderes Problem.
Einer der Hauptgründe dafür ist die hohe Varianz bei den Anfragemerkmalen. So kann beispielsweise ein RAG-Muster einen langen Eingabe-Prompt mit Kontext aus einer Vektordatenbank verwenden, um eine kurze, aus einem Satz bestehende Antwort zu generieren. Umgekehrt kann eine Reasoning-Aufgabe mit einem kurzen Prompt beginnen und zu einer langen, aus mehreren Schritten bestehenden Antwort führen. Diese Varianz führt zu Lastungleichheiten, die die Performance beeinträchtigen und zu einer erhöhten Tail-Latenz (ITL) führen können. Die LLM-Inferenz stützt sich auch stark auf den KV-Cache (Key Value), den Kurzzeitspeicher eines LLM, um Zwischenergebnisse zu speichern. Dem traditionellen Load Balancing ist der Zustand dieses Caches nicht bekannt, was zu ineffizientem Anfrage-Routing und nicht ausgelasteten Rechenressourcen führt.

Bei Kubernetes besteht der aktuelle Ansatz darin, LLMs als monolithische Container bereitzustellen – große Black Boxes ohne Transparenz oder Kontrolle. Diese Tatsache sowie das Ignorieren der Prompt-Struktur, der Tokenanzahl, der Latenzziele für Antworten (Service Level Objectives oder SLO), der Cache-Verfügbarkeit und vieler anderer Faktoren erschweren eine effektive Skalierung.
Kurz gesagt, unsere aktuellen Inferenzsysteme sind ineffizient und benötigen mehr Rechenressourcen als nötig.
llm-d macht Inferenz effizienter und kostengünstiger
vLLM bietet zwar eine umfassende Modellunterstützung für zahlreiche Hardwarekomponenten, llm-d geht aber noch einen Schritt weiter. llm-d baut auf bestehenden IT-Infrastrukturen von Unternehmen auf und bietet verteilte und erweiterte Inferenzfunktionen, mit denen Sie Ressourcen einsparen und die Performance verbessern können. Dazu zählen unter anderem eine 3-fache Verbesserung bei der Time to First Token und doppelter Durchsatz unter Latenzeinschränkungen (SLO). Obwohl llm-d
- Disaggregation: Die Disaggregation des Prozesses ermöglicht einen effizienteren Einsatz von Hardwarebeschleunigern während der Inferenz. Dabei wird die Prompt-Verarbeitung (Prefill-Phase) von der Token-Generierung (Decode-Phase) in einzelne Workloads, auch Pods genannt, getrennt. Diese Trennung ermöglicht eine unabhängige Skalierung und Optimierung der einzelnen Phasen, da sie unterschiedliche Rechenanforderungen haben.
- Intelligente Planungsschicht: Sie erweitert die Kubernetes Gateway-API und ermöglicht differenziertere Routing-Entscheidungen für eingehende Anfragen. Sie nutzt Echtzeitdaten wie die KV-Cache-Nutzung und Pod-Last, um Anfragen an die optimale Instanz zu leiten, Cache-Treffer zu maximieren und Workloads im Cluster zu verteilen.

Zusätzlich zu Funktionen wie dem anfrageübergreifenden Caching von KV-Paaren zum Verhindern einer Neuberechnung unterteilt llm-d die LLM-Inferenz in modulare, intelligente Services für eine skalierbare Performance (und baut auf der umfassenden Unterstützung von vLLM selbst auf). Im Folgenden möchten wir die einzelnen Technologien genauer betrachten und anhand einiger praktischer Beispiele erfahren, wie sie von llm-d verwendet werden.
Wie Disaggregation den Durchsatz bei geringerer Latenz erhöht
Der grundlegende Unterschied zwischen den Prefill- und Decode-Phasen der LLM-Inferenz stellt eine Herausforderung für eine einheitliche Ressourcenzuweisung dar. Die Prefill-Phase, in der der Eingabe-Prompt verarbeitet wird, ist in der Regel rechengebunden und erfordert eine hohe Rechenleistung, um die ersten KV-Cache-Einträge zu erstellen. Umgekehrt ist die Decode-Phase, in der Token einzeln generiert werden, häufig an die Speicherbandbreite gebunden, da sie hauptsächlich das Lesen und Schreiben in den KV-Cache mit relativ weniger Rechenleistung umfasst.
Durch die Implementierung der Disaggregation ermöglicht llm-d, dass diese beiden unterschiedlichen Rechenprofile durch separate Kubernetes-Pods bereitgestellt werden. Das bedeutet, dass Sie Prefill-Pods mit Ressourcen bereitstellen können, die für rechenintensive Aufgaben optimiert sind, und Decode-Pods mit Konfigurationen, die auf eine effiziente Nutzung der Speicherbandbreite zugeschnitten sind.
Funktionsweise des LLM-fähigen Inferenz-Gateways
Das Herzstück der Performanceverbesserungen von llm-d ist der intelligente Scheduling-Router, der orchestriert, wo und wie Inferenzanforderungen verarbeitet werden. Wenn eine Inferenzanforderung am llm-d-Gateway (basierend auf kgateway) eingeht, wird sie nicht einfach an den nächsten verfügbaren Pod weitergeleitet. Stattdessen bewertet der Endpoint Picker (EPP), eine Kernkomponente des Schedulers von llm-d, mehrere Echtzeitfaktoren, um das optimale Ziel zu bestimmen:
- KV-Cache-Bewusstsein: Der Scheduler verwaltet einen Index des KV-Cache-Status für alle ausgeführten vLLM-Replikate. Verwendet eine neue Anforderung ein gemeinsames Präfix mit einer bereits zwischengespeicherten Session auf einem bestimmten Pod, priorisiert der Scheduler das Routing zu diesem Pod. Dadurch werden die Cache-Zugriffsraten drastisch erhöht, redundante Berechnungen vorab aufgefüllt und die Latenz direkt reduziert.
- Lastbewusstsein: Neben der einfachen Anzahl von Anfragen bewertet der Scheduler auch die tatsächliche Auslastung jedes vLLM-Pods unter Berücksichtigung der GPU-Speicherauslastung und der Verarbeitungswarteschlangen, um Engpässe zu vermeiden.
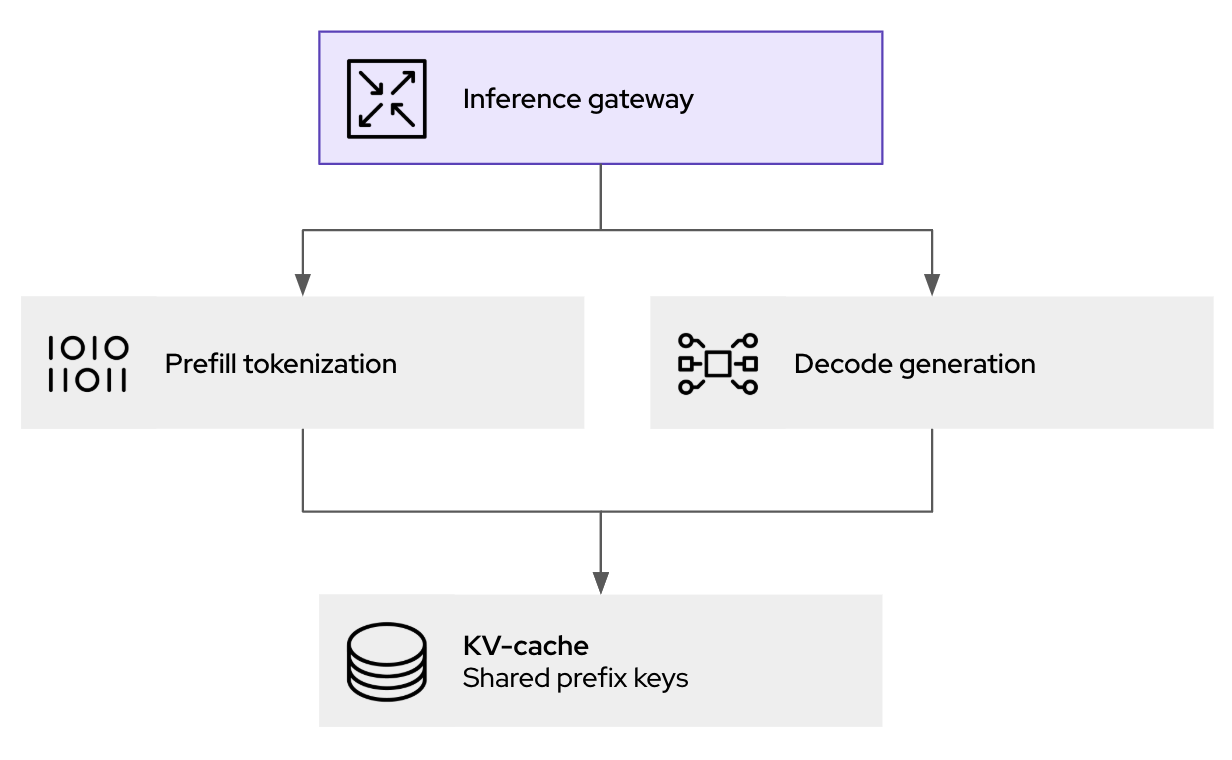
Dieser Kubernetes-native Ansatz liefert die Richtlinien-, Sicherheits- und Beobachtbarkeitsschicht für generative KI-Inferenz. Dies hilft nicht nur bei der Bewältigung des Datenverkehrs, sondern ermöglicht auch Prompt Logging und Auditing (für Governance und Compliance) sowie Richtlinien vor der Weiterleitung zur Inferenz.
Einstieg in llm-d
Hinter dem llm-d-Projekt steckt viel Energie. Während vLLM sich ideal für Einzelserver-Setups eignet, wurde llm-d für Operatoren entwickelt, die einen Cluster verwalten und auf eine leistungsfähige, kostengünstige KI-Inferenz abzielen. Möchten Sie es selbst testen? Sehen Sie sich das llm-d-Repository auf GitHub an, und diskutieren Sie auf Slack mit. Hier können Sie Fragen stellen und sich einbringen.
Die Zukunft der KI beruht auf offenen und von Zusammenarbeit geprägten Prinzipien. Mit Communities wie vLLM und Projekten wie llm-d arbeitet Red Hat daran, KI für Entwicklungsteams auf der ganzen Welt zugänglicher, erschwinglicher und leistungsfähiger zu machen.
Ressource
Erste Schritte mit KI für Unternehmen: Ein Guide für den Einstieger
Über die Autoren
Cedric Clyburn (@cedricclyburn), Senior Developer Advocate at Red Hat, is an enthusiastic software technologist with a background in Kubernetes, DevOps, and container tools. He has experience speaking and organizing conferences including DevNexus, WeAreDevelopers, The Linux Foundation, KCD NYC, and more. Cedric loves all things open-source, and works to make developer's lives easier! Based out of New York.
Christopher Nuland is a Principal Technical Marketing Manager for AI at Red Hat and has been with the company for over six years. Before Red Hat, he focused on machine learning and big data analytics for companies in the finance and agriculture sectors. Once coming to Red Hat, he specialized in cloud native migrations, metrics-driven transformations, and the deployment and management of modern AI platforms as a Senior Architect for Red Hat’s consulting services, working almost exclusively with Fortune 50 companies until recently moving into his current role. Christopher has spoken worldwide on AI at conferences like IBM Think, KubeCon EU/US, and Red Hat’s Summit events.
Ähnliche Einträge
KI-Bedrohungen abwehren: Agile Security für Unternehmen
Die Zukunft der KI erfordert eine hybride Basis
Technically Speaking | Defining sovereign AI with open source
Technically Speaking | Inside open source AI strategy
Nach Thema durchsuchen

Automatisierung
Das Neueste zum Thema IT-Automatisierung für Technologien, Teams und Umgebungen

Künstliche Intelligenz
Erfahren Sie das Neueste von den Plattformen, die es Kunden ermöglichen, KI-Workloads beliebig auszuführen

Open Hybrid Cloud
Erfahren Sie, wie wir eine flexiblere Zukunft mit Hybrid Clouds schaffen.

Sicherheit
Erfahren Sie, wie wir Risiken in verschiedenen Umgebungen und Technologien reduzieren

Edge Computing
Erfahren Sie das Neueste von den Plattformen, die die Operations am Edge vereinfachen

Infrastruktur
Erfahren Sie das Neueste von der weltweit führenden Linux-Plattform für Unternehmen

Anwendungen
Entdecken Sie unsere Lösungen für komplexe Herausforderungen bei Anwendungen
Virtualisierung
Erfahren Sie das Neueste über die Virtualisierung von Workloads in Cloud- oder On-Premise-Umgebungen