In einem vorherigen Artikel haben wir uns auf die Funktion konzentriert, die Large Language Models (LLMs) durch domainspezifische Anpassung von universellen Tools in Forschungsinstrumente verwandelt. Mit optimierten Modellen kodieren Forschungsteams Domain-Fachwissen, institutionelle Forschung und Denkmuster in Systeme, die Entdeckungen beschleunigen und nicht nur unterstützen.
Doch angepasste Modelle sind nur die eine Hälfte der Lösung. Damit diese Modelle auf institutioneller Ebene nützlich werden, benötigen sie eine Plattform, mit der Nutzende sie trainieren, bereitstellen, den Zugriff darauf verwalten und sie in die umfassendere Forschungs-Computing-Umgebung integrieren können. Diese Plattform muss die Welten verbinden, in denen Forschende bereits arbeiten – traditionelle HPC-Cluster (High Performance Computing), auf denen der Slurm-Workload-Manager ausgeführt wird, und das schnell wachsende cloudnative KI-Ökosystem, das auf Kubernetes basiert.
In diesem Artikel untersuchen wir das Zusammenwirken dieser Plattform – die Architektur, mit der Forschungseinrichtungen HPC und cloudnative Workloads konvergieren, angepasste Modelle als Shared Services operationalisieren und generative KI-Funktionen (gen KI) für gesamte Organisationen bereitstellen, ohne Governance, Reproduzierbarkeit oder Kostenkontrolle zu beeinträchtigen.
Die Plattformarchitektur: Wie die Teile zusammenpassen
Nachdem der Use Case für die Anpassung dargelegt wurde, sehen wir uns an, wie die gesamte Plattform zusammenwirkt. Die Architektur ist verallgemeinert und gilt unabhängig davon, ob Sie diese für eine Forschungsuniversität, ein staatlich finanziertes Forschungs- und Entwicklungszentrum, ein Lehrkrankenhaus, ein Energieunternehmen oder eine Forschungsgruppe im Bereich Finanzdienstleistungen entwickeln. Die Komponenten sind identisch, aber die Konfiguration für die einzelnen Domains unterscheidet sich.
Die Basis bildet Red Hat OpenShift, eine Kubernetes-Distribution, die Container-Orchestrierung, Namespace-Governance, role-based Access Control (RBAC), Integration von persistentem Storage und operative Tools bereitstellt, die Platform Engineers für den Betrieb einer gemeinsamen KI-Infrastruktur auf institutioneller Ebene benötigen.
Zusätzlich zu OpenShift bietet Red Hat OpenShift AI KI-spezifische Funktionen, darunter Modellbereitstellung, Modellanpassung, Pipeline-Orchestrierung, Notebook-Umgebungen für Data Scientists und Observability für KI-Workloads. OpenShift AI verwandelt die Kubernetes-Basisplattform in eine Umgebung, in der Forschende Modelle über eine gesteuerte Self Service Schnittstelle trainieren, feinabstimmen, bewerten, bereitstellen und überwachen können – ohne dass jedes Team die eigene ML-Infrastruktur (Machine Learning) verwalten muss.
Die Inferenz-Engine ist vLLM, bereitgestellt über die Modellbereitstellungs-Ebene von OpenShift AI. Das kontinuierliche Batching und die speichereffizienten Attention-Mechanismen von vLLM machen es zur richtigen Wahl für gemeinsam genutzte Inferenzumgebungen, in denen mehrere Forschungsteams Modellendpunkte gleichzeitig nutzen. In einer ressourcenbeschränkten Umgebung – was auf die meisten Forschungseinrichtungen zutrifft – macht der Unterschied zwischen effizienter und ineffizienter Inferenz einen bedeutenden Teil des GPU-Budgets aus.
Auf der Hardware-Ebene von Red Hat AI Factory with NVIDIA wird die Zusammenarbeit von Red Hat und NVIDIA direkt relevant. Red Hat AI Factory with NVIDIA vereint die GPU-Hardware von NVIDIA und das NVIDIA Inference Microservices (NIM) Framework mit den Orchestrierungs- und Governance-Funktionen von OpenShift AI. NIM-Container enthalten optimierte, validierte Modellkonfigurationen, die für die Bereitstellung auf NVIDIA-Hardware bereitstehen. Da sie auf OpenShift ausgeführt werden, übernehmen sie die Namespace-Governance, RBAC und den Observability-Stack der Plattform.
Für Forschungseinrichtungen, die eine NVIDIA GPU-Infrastruktur erwerben – was auf die meisten zutrifft – bietet die Referenzarchitektur von Red Hat AI Factory with NVIDIA einen validierten, unterstützten Weg von der Hardware bis zum Betrieb von Inferenzservices und hilft dabei, monatelange Integrationsarbeit zu vermeiden. Der NIM-Katalog von NVIDIA enthält Basismodelle für die wichtigsten Modellfamilien; die Anpassungs-Pipeline von OpenShift AI erweitert diese Basis-Modelle durch domainspezifisches Fine Tuning. Diese Kombination stellt einen praktischen Weg dar: von „Wir haben GPUs“ hin zu „Wir haben ein feinabgestimmtes klinisches Modell für unsere Forschenden“.
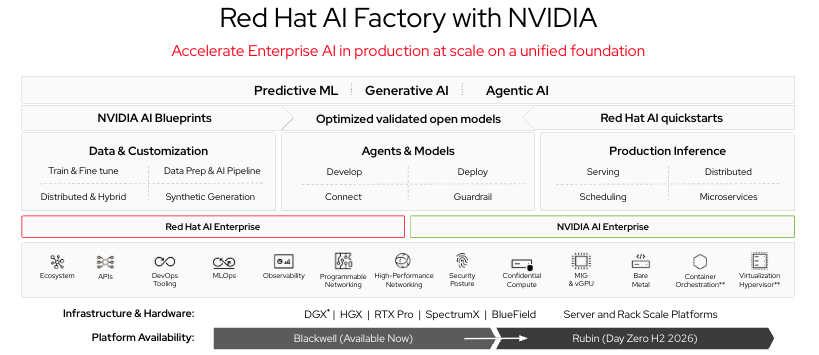
Abbildung 1: Red Hat AI Factory with NVIDIA
Verbindung von HPC und cloudnativer Umgebung: Der Slinky-Operator
Slurm treibt viele der weltweit führenden Supercomputer an und ist die Standardschnittstelle für die Übermittlung von HPC-Jobs in Forschungseinrichtungen. Die Stärken von Slurm sind beachtlich, darunter exklusive GPU-Reservierungen, vorhersagbare Performance, ausgereifte Prioritätswarteschlangen und eine tiefe Integration mit parallelen Dateisystemen sowie MPI-Workloads (Message Passing Interface). Die meisten HPC-Nutzenden in Forschungseinrichtungen kennen Slurm, und ihre Pipelines sind im Allgemeinen für Slurm geschrieben.
Die Herausforderung bestand schon immer in der Lücke zwischen der Slurm-Welt und der Kubernetes-Welt: 2 Scheduler, 2 Systeme für die Ressourcenabrechnung, 2 Möglichkeiten zur Anforderung einer GPU, 2 Operations-Teams. Datenartefakte werden manuell zwischen Umgebungen verschoben, und GPU-Kapazitäten bleiben im HPC-Cluster in Zeitfenstern mit geringer Auslastung häufig ungenutzt, während in der Kubernetes-Umgebung Jobs in der Warteschlange stehen.
Der Slinky-Operator schließt diese Lücke. Wie in diesem Artikel über die Ausführung von Slurm-Workloads auf OpenShift erläutert, ist Slinky ein Kubernetes-Operator, der Slurm-Komponenten – einschließlich slurmctld und slurmd – als containerisierte Workloads in OpenShift bereitstellt und verwaltet. Er automatisiert Deployment, Skalierung und Lifecycle-Management des Slurm-Clusters, sodass dieser mit Kubernetes-nativen Workloads auf derselben Hardware koexistieren kann.
Für Research Platform Engineers bedeutet das in der Praxis:
- Einheitliche Ressourcenplanung: Slurm-Batch-Jobs und Kubernetes-native KI-Workloads teilen sich denselben GPU-Pool. Ungenutzte Kapazitäten zwischen großen Simulationsjobs lassen sich ohne manuelle Eingriffe oder Hardwareneuzuweisungen für Inferenz- oder Fine Tuning-Workloads zuteilen.
- Bewahrte Forschungs-Workflows: HPC-Forschende, die Jobs über sbatch einreichen, müssen ihren Workflow nicht ändern. Die vertraute Slurm-Schnittstelle bleibt bestehen, wird nun aber auch innerhalb von OpenShift ausgeführt – mit der gesamten Observability, dem Lifecycle-Management und der Governance, die Kubernetes bietet.
- Reproduzierbare Umgebungen: Slurm-Jobs werden als Container ausgeführt. Das bedeutet, dass das Container-Image die Umgebung definiert und nicht die jeweilige Installation auf dem Rechenknoten. Dies verbessert die Reproduzierbarkeit erheblich und vereinfacht die Zusammenarbeit zwischen Einrichtungen, die Pipelines gemeinsam nutzen möchten.
- Zentrale operative Oberfläche: Platform Engineers verwalten 1 Cluster, 1 Observability-Stack und 1 RBAC-Modell. Slinky erfordert oder erstellt keine zweite Infrastruktur, sondern integriert die HPC-Planung in die bereits verwendete Plattform.
Die Übernahme von SchedMD, dem Hauptentwickler von Slurm, durch NVIDIA signalisiert, wohin diese Konvergenz auf Branchenebene führt. Die Grenzen zwischen HPC-Planung, Kubernetes-Orchestrierung und KI-Infrastruktur werden gezielt aufgelöst. Slinky ist der Beitrag von Red Hat zu dieser Konvergenz und ist ab sofort für den Produktionseinsatz verfügbar.
Für eine Forschungsuniversität, die sowohl einen HPC-Cluster für Computational Science als auch eine OpenShift-Umgebung für KI-Forschung betreibt, hilft Slinky dabei, diese 2 Investitionen als Einheit zu nutzen.
Models as a Service (MaaS): Das Modell der gemeinsam genutzten KI-Plattform für Forschungseinrichtungen
Die Plattformkonvergenz löst das Infrastrukturproblem, aber es gibt ein weiteres, ebenso wichtiges Problem: Die meisten Forschungsteams verfügen über keine Fachkräfte für Infrastruktur. Ein Team für klinische Informatik, das einen Chatbot für Gleichberechtigung im Gesundheitswesen entwickelt, möchte keine Kubernetes-Namespaces verwalten. Ein Genomik-Labor, das ein feinabgestimmtes Modell für die Variantenannotation benötigt, möchte keine vLLM-Deployments konfigurieren. Eine Abteilung für Sozialinformatik, die LLM-basierte Dokumentenanalysen durchführen möchte, möchte keine Helm-Charts schreiben.
Das Betriebsmodell, das dieses Problem löst, ist Models as a Service (MaaS).
Was ist MaaS?
MaaS ist ein Ansatz, bei dem Platform Engineers KI-Modelle als Shared Services bereitstellen, verwalten und betreiben und sie den Nutzenden über APIs zur Verfügung stellen. Im Kontext einer Forschungseinrichtung bedeutet dies, dass das Team der Research Computing Platform den GPU-Cluster betreibt, den Modell-Lifecycle verwaltet, die Versionierung sowie Updates übernimmt und die Serving-Infrastruktur wartet. Währenddessen nutzen Forschungsteams Modellendpunkte als Service, genau wie sie eine Computing-Zuweisung oder einen Storage-Mount nutzen.
Die Auswirkungen auf die Forschungsproduktivität sind erheblich. Überlegen Sie, wie der Workflow heute im Vergleich zu einem MaaS-Modell aussieht.
Momentan ohne MaaS
Ein Forschungsteam benötigt ein per Fine Tuning optimiertes Modell für sein Projekt. Mitarbeitende verbringen Wochen damit, eine GPU-Umgebung einzurichten, Abhängigkeiten zu installieren, ein Serving-Framework zu konfigurieren und Infrastrukturprobleme zu beheben. Die eigentliche Forschung beginnt erst, wenn die Infrastruktur schließlich funktioniert. Dies kann Monate nach Projektbeginn der Fall sein. Wenn sie fertig sind, verbleibt das Modell auf der Workstation von 1 Person oder einer temporären Cluster-Zuweisung, die zurückgefordert wird.
Mit MaaS auf OpenShift AI
Das Forschungsteam bringt seinen Datensatz und seine Domain-Anforderungen zum Plattformteam. Sie arbeiten mit Platform Engineers zusammen, um einen Fine Tuning-Job über Training Hub auf OpenShift AI zu konfigurieren und auszuführen. Das resultierende Modell wird als versionierter, kontrollierter API-Endpunkt auf dem gemeinsamen Cluster bereitgestellt. Andere Forschungsteams mit ähnlichen Anforderungen können auf denselben Endpunkt zugreifen. Wenn das Modell mit neuen Daten aktualisiert werden muss, wird die Trainingspipeline erneut ausgeführt. Die neue Version wird über denselben kontrollierten Prozess bereitgestellt.
Das Plattformteam kümmert sich um die Infrastruktur, während das Forschungsteam die wissenschaftliche Arbeit leistet. Diese Arbeitsteilung hilft dabei, KI-Funktionen innerhalb einer Einrichtung zu skalieren.

Abbildung 2: Konvergenz von HPC, cloudnativen Anwendungen und Models as a Service für die wissenschaftliche Forschung
Für Platform Engineers bietet MaaS auf OpenShift AI („Research as a Service“, wenn Sie so wollen) die benötigten operativen Funktionen. Dazu gehören Ressourcen-Quotas auf Namespace-Ebene, die verhindern, dass ein einzelnes Forschungsprojekt die GPU-Kapazität monopolisiert, Modellversionierung über eine Registry, RBAC zur Steuerung von Bereitstellung und Nutzung sowie Observability über sämtliche Serving-Workloads über ein einheitliches Dashboard.
Für Forschungseinrichtungen mit mehreren Forschungsgruppen (z. B. eine medizinische Fakultät, eine Abteilung für Computational Biology, ein Fachbereich für Informatik und ein Institut für Data Science), die alle auf derselben Plattform arbeiten, ist MaaS die Lösung. So kann das Plattformteam der Nachfrage voraus sein, ohne die Mitarbeiterzahl linear mit der Anzahl der Forschungsprojekte zu skalieren.
Datengravitation: KI dorthin bringen, wo Forschung stattfindet
In der Forschung gibt es ein Problem mit der Datengravitation. Die wertvollsten Datensätze (klinische Aufzeichnungen, Genomsequenzen, Simulationsergebnisse) sind bereits umfangreich, verteilt und aufgrund von Kosten-, Latenz- oder Governance-Einschränkungen oft nicht zu verschieben. Das Verschieben von Petabytes an Daten an einen Cloud-Endpunkt ist ineffizient und oft unmöglich.
Die Plattform, die wir hier diskutieren, bringt die KI zu den Daten und nicht umgekehrt. Wenn Sie Modelltraining, Fine Tuning und Inferenz dort ausführen, wo sich die Daten bereits befinden (On-Premise, im Labor, in gesicherten Forschungsumgebungen usw.), vermeiden Sie unnötige Datenbewegungen und gewährleisten gleichzeitig Performance und Compliance.
Im Grunde handelt es sich nicht nur um eine Optimierung, sondern um eine architektonische Anforderung. Je näher das Modell an den Daten ist, desto schneller ist die Iterationsschleife, desto niedriger sind die Kosten und desto praktischer wird die Operationalisierung von KI in umfangreichen Forschungs-Workflows.
Anwendungsbereiche dieser Architektur: Sektorübergreifende Forschung
Natürlich ist diese Plattform nicht speziell auf die akademische Forschung ausgerichtet. Die Architektur lässt sich auf die meisten Einrichtungen übertragen, in denen Domain-Fachwissen wichtig ist, Daten-Governance cloudnatives Deployment einschränkt und Forschungs-Workloads das gesamte Spektrum von HPC bis Cloud Native abdecken.
- Forschungsuniversitäten und staatlich finanzierte Forschungs- und Entwicklungszentren (FFRDCs): Universitäten und staatlich finanzierte Forschungs- und Entwicklungszentren wie nationale Laboratorien verfügen in der Regel über die Infrastruktur, die diese Architektur adressiert: HPC-Cluster für simulationsintensive Forschung, eine wachsende Nachfrage nach cloudnativer KI von Data-Science-Gruppen und Platform-Engineering-Teams, die Dutzende von Forschungsgruppen mit unterschiedlichen Computing-Anforderungen bedienen.
- Medizinische Einrichtungen und Lehrkrankenhäuser: Klinische KI ist einer der am schnellsten wachsenden Bereiche für Forschungsinvestitionen und stellt hohe Anforderungen an Modellgenauigkeit, Daten-Governance und Sicherheit. Universelle Cloud-Modelle kommen aufgrund von Datenschutzverpflichtungen für Patientendaten häufig nicht infrage. Diese Organisationen benötigen Fine Tuning-Modelle, die On-Premise mit Audit-Protokollierung und Zugriffskontrollen ausgeführt und über eine verwaltete institutionelle Plattform bereitgestellt werden.
- Verteidigungs- und Nachrichtenforschung: FFRDCs und Verteidigungsunternehmen, die in vertraulichen oder kontrollierten Umgebungen tätig sind, haben die gleichen Anforderungen an die Daten-Governance wie die klinische Forschung, ergänzt durch Klassifizierungsanforderungen, die die Verwendung von Cloud-APIs untersagen. Diese erfordern die On-Premise-Modellbereitstellung, getrennte Abläufe und Fine Tuning-Modelle, die intern vertrauliches Domain-Wissen enthalten.
- Finanzdienstleistungen und quantitative Forschung: Forschungsgruppen in der Finanzdienstleistungsbranche (z. B. Quant Research, Risikomodellierung, regulatorische Analysen) arbeiten mit proprietären Daten und agieren unter regulatorischen Auflagen, die die Übermittlung an externe APIs einschränken. Diese benötigen Fine Tuning-Modelle, die auf interner Forschung trainiert wurden, lokal über MaaS bereitgestellt werden und über verwaltete APIs zugänglich sind, die sich in bestehende Forschungs-Workflows integrieren lassen.
- Energie und industrielle Forschung: Unternehmen in den Bereichen Öl und Gas, Versorgungsunternehmen und industrielle Forschung führen rechenintensive Simulations-Workloads neben wachsenden ML-Pipelines für Materialforschung, prädiktive Wartung und geophysikalische Analysen aus. Slinky ist in diesem Sektor besonders relevant, da Slurm-basierte Simulations-Workflows zum Standard gehören und ML-gesteuerte Analysen nach diesen Simulationen zunehmend erforderlich sind.
In all diesen Kontexten ist das Architekturmuster konsistent: HPC- und cloudnative Planung konvergieren, Modelle für Domain-Spezifität anpassen, sie effizient über eine gemeinsame MaaS-Plattform bereitstellen und den Zugriff auf institutioneller Ebene verwalten.
Zusammengefasst: Was die Plattform ermöglicht
Hier sehen Sie ein Beispiel dafür, was die vollständige Architektur für eine Forschungseinrichtung ermöglicht, die diese implementiert hat:
Ein Mitglied des Forschungsteams im Bereich Computational Genomics reicht einen umfangreichen Variant-Calling-Job über Slurm ein, auf dieselbe Weise, wie HPC-Jobs seit Jahren eingereicht werden. Der Slinky-Operator plant diesen als containerisierten Workload auf OpenShift auf denselben GPU-Knoten, die auch Fine Tuning-Inferenzendpunkte bereitstellen. Wenn der Job abgeschlossen ist, werden die Ausgaben in einem freigegebenen Objektspeicher gespeichert, auf den sowohl die HPC- als auch die Kubernetes-Umgebungen zugreifen können.
Ein klinisch Forschender im Bereich NLP an einer medizinischen Fakultät benötigt ein Modell, das für eine Aufgabe zur Erkennung benannter Entitäten anhand anonymisierter klinischer Notizen optimiert wurde. In Zusammenarbeit mit dem Plattformteam führen sie einen Fine Tuning-Job für eine Low-Rank-Anpassung (LoRA) über Training Hub auf OpenShift AI unter Verwendung eines Basismodells aus dem NVIDIA NIM-Katalog durch. Das resultierende Modell wird versioniert und als MaaS-Endpunkt bereitgestellt. Zwei andere Forschungsteams mit angrenzenden NLP-Aufgaben beginnen sofort mit der Nutzung desselben Endpunkts. Dadurch verteilen sich die Fine Tuning-Kosten auf die gesamte Einrichtung.
Eine Forschungsgruppe im Bereich Cybersicherheit an einem FFRDC muss Threat Intelligence-Berichte in großem Umfang mit einem LLM analysieren. Da ihre Daten Sensibilitätsbeschränkungen unterliegen, die eine Nutzung der Cloud-API verhindern, wird das Modell vollständig lokal auf ihrem OpenShift-Cluster ausgeführt. Das Modell wurde anhand ihres vertraulichen Datensatzes mithilfe der synthetischen Datengenerierung mit InstructLab optimiert, um den kleinen gekennzeichneten Datensatz zu erweitern. Der Zugriff auf den Endpunkt ist nur für Namespaces mit den entsprechenden RBAC-Bindungen möglich.
Ein Platform Engineer, der diese Workloads auf demselben Cluster verwaltet, sieht ein einzelnes Beobachtbarkeits-Dashboard mit der GPU-Auslastung für Slurm- und Kubernetes-Workloads, der Latenz der Modellbereitstellung nach Endpunkt, der Warteschlange für Trainingsjobs und der Nutzung von Ressourcenkontingenten nach Namespace. Ressourcenkonflikte zwischen Workloads löst der einheitliche Scheduler auf, nicht ein manueller Eingriff.
Jede dieser Funktionen ist ab sofort in Red Hat AI und OpenShift AI verfügbar. Sie sind über die Red Hat AI Factory with NVIDIA-Referenzarchitektur in NVIDIA-Hardware integriert und werden durch den Slinky-Operator auf HPC-Workflows ausgeweitet.
Schlussgedanken
Die Forschenden, die die nächste Generation der Forschung vorantreiben, werden LLMs als primäres Tool nutzen. Sie setzen diese als zentralen Bestandteil ihres Forschungs-Workflows ein, nicht als Ergänzung zu bestehenden Methoden.
Sie benötigen von der Plattform Funktionen, die sie nutzen können, ohne zu Infrastruktur-Engineers werden zu müssen. Sie benötigen feinabgestimmte Modelle, die ihre Domäne tatsächlich kennen, sowie eine schnelle und zuverlässige Inferenz. Zudem sind HPC-Workflows ohne Kontextwechsel zu einem anderen Cluster und ein gemeinsamer Zugriff über einen kontrollierten Service erforderlich.
Red Hat OpenShift, Red Hat AI, NVIDIA und der Slinky-Operator können diese Plattform gemeinsam bereitstellen.
Ressource
Erste Schritte mit KI für Unternehmen: Ein Guide für den Einstieger
Über die Autoren

I build real-world GenAI solutions for organizations that can’t afford to get it wrong.
My career spans national security, enterprise software, and next-generation AI platforms, with more than a decade focused on solving complex problems at the intersection of data, intelligence, and technology. I began in the intelligence community, serving eight years with the NSA and across the IC in intrusion defense, intelligence analysis, and mission-critical cyber operations. That experience in high-stakes security, pattern recognition, and adversarial thinking continues to shape how I approach GenAI strategy and deployment today.
Since then, I’ve led product and platform initiatives in digital ecosystems, advised startups, and worked across the data science landscape helping organizations move from experimentation to production. Much of my work focuses on making generative AI models more knowledgeable and reliable by grounding them in domain-specific data, mission context, and real operational constraints across national security, research, and healthcare.
Today, as an AI Solutions Advisor at Red Hat and IBM, I partner with government agencies, research institutions, and enterprises across North America to design scalable GenAI systems that work in the real world. The goal is never novelty — it’s better decisions, faster execution, and durable advantage.

O'Neill Joseph is a Sr AI Solutions Architect in Red Hat focused on specialized AI deployments, has over 20 experience in IT Infrastructure, from telecommunications to cloud native infrastructure with a Degree in Cybersecurity and IT Networking from University of Maryland.

Working with customers to build IT solutions for over 25 years, Wes has experience integrating various technologies and approaches to produce outcomes and achieve mission objectives. Serving highly regulated industries such as healthcare and defense, Wes understands how to approach IT challenges with a secure, compliant end state in mind.
At Red Hat, Wes focuses on helping customers build cloud-native platforms where they can run AI/ML workloads, integrate heterogeneous data and facilitate outcomes anywhere in the world.
Prior to joining Red Hat, Wes was the CTO at a small technology company in DC helping build solutions for a variety of government customers.
Wes has managed global engineering teams, built services to help customers scale their missions, and designed software solutions to meet the needs of growing organizations.
Ähnliche Einträge
IT-Stack vereinheitlichen: VMs, Cloud und KI vereint
Den MCP-Katalog ist da: Auf Red Hat OpenShift AI entdecken, bereitstellen und verbinden
Technically Speaking | Build a production-ready AI toolbox
Technically Speaking | Platform engineering for AI agents
Nach Thema durchsuchen

Automatisierung
Das Neueste zum Thema IT-Automatisierung für Technologien, Teams und Umgebungen

Künstliche Intelligenz
Erfahren Sie das Neueste von den Plattformen, die es Kunden ermöglichen, KI-Workloads beliebig auszuführen

Open Hybrid Cloud
Erfahren Sie, wie wir eine flexiblere Zukunft mit Hybrid Clouds schaffen.

Sicherheit
Erfahren Sie, wie wir Risiken in verschiedenen Umgebungen und Technologien reduzieren

Edge Computing
Erfahren Sie das Neueste von den Plattformen, die die Operations am Edge vereinfachen

Infrastruktur
Erfahren Sie das Neueste von der weltweit führenden Linux-Plattform für Unternehmen

Anwendungen
Entdecken Sie unsere Lösungen für komplexe Herausforderungen bei Anwendungen
Virtualisierung
Erfahren Sie das Neueste über die Virtualisierung von Workloads in Cloud- oder On-Premise-Umgebungen