

Unternehmensteams haben bei der Entwicklung von Anwendungen mit generativer KI (gen KI) wie Retrieval-Augmented Generation (RAG) häufig mit dem „Datenengpass“ zu kämpfen, da herkömmliche Tools zur Dokumentenverarbeitung Tausende komplexe Dokumente nicht effizient verarbeiten können. Dieser Blogbeitrag zeigt, wie eine einheitliche Infrastruktur, die Ray Data für High-Speed-Streaming und Docling für präzises Parsen von Dokumenten kombiniert, diese Hürden überwinden kann. Durch das Skalieren dieser Tools auf Plattformen wie Red Hat OpenShift AI oder Anyscale können Unternehmen ungeordnete, unstrukturierte Daten in nur wenigen Stunden statt in Tagen in verwertbare Erkenntnisse umwandeln. Dies legt den Grundstein für Vertrauen und Zuverlässigkeit für die nächste Welle der KI-Innovation.
Anyscale ist das Unternehmen hinter Ray, einem Framework für verteiltes Computing, das jetzt Teil der PyTorch Foundation ist. Anyscale bietet zudem eine KI-Plattform an.
Red Hat OpenShift AI bietet Unternehmen eine skalierbare Plattform, um KI zu entwickeln und bereitzustellen. Es nutzt KubeRay, um Ray-Cluster auf Kubernetes auszuführen, was die Zuverlässigkeit verbessert und eine automatische Skalierung ermöglicht. Durch die Integration von Docling zum Parsen von Dokumenten ermöglicht OpenShift AI es Teams, CPU- und GPU-Aufgaben auf einem System zu verwalten. Dies verringert den Overhead und beschleunigt die Bereitstellung von KI-Anwendungen.
Die Realität des RAG-Datenengpasses
Demos lassen das Erstellen generativer KI einfach erscheinen, doch die Realität der Datenvorbereitung und -verarbeitung ist weitaus komplexer. Stellen Sie sich vor, Ihr Team hat gerade Zehntausende von Legacy-PDFs übernommen und der CEO möchte diese schnellstmöglich durchsuchbar machen. Das Verarbeiten so vieler komplexer Dokumente – oft mit Tabellen und Bildern – kann schnell zu einem Engpass werden, dessen Behebung Wochen dauert. Die ernüchternde Realität ist, dass die meisten KI-Projekte einen Großteil der Zeit mit der Datenvorbereitung verbringen, anstatt Modelle zu trainieren und zu optimieren.
In vielen Fällen ist die Ineffizienz veralteter Daten-Pipelines die größte Hürde bei der RAG-Entwicklung. RAG verbessert die Antworten von Large Language Models (LLMs), indem es relevanten Kontext aus einer Wissensdatenbank abruft. Dabei werden Dokumente verarbeitet (geparst, in Blöcke aufgeteilt und eingebettet) und in einer Vektordatenbank gespeichert. Bei der Abfrage ruft das System relevante Blöcke ab und stellt sie dem LLM als Kontext bereit. Dies verbessert die Antwortgenauigkeit, da diese nun auf den Daten Ihres Unternehmens basieren, wie hier gezeigt:
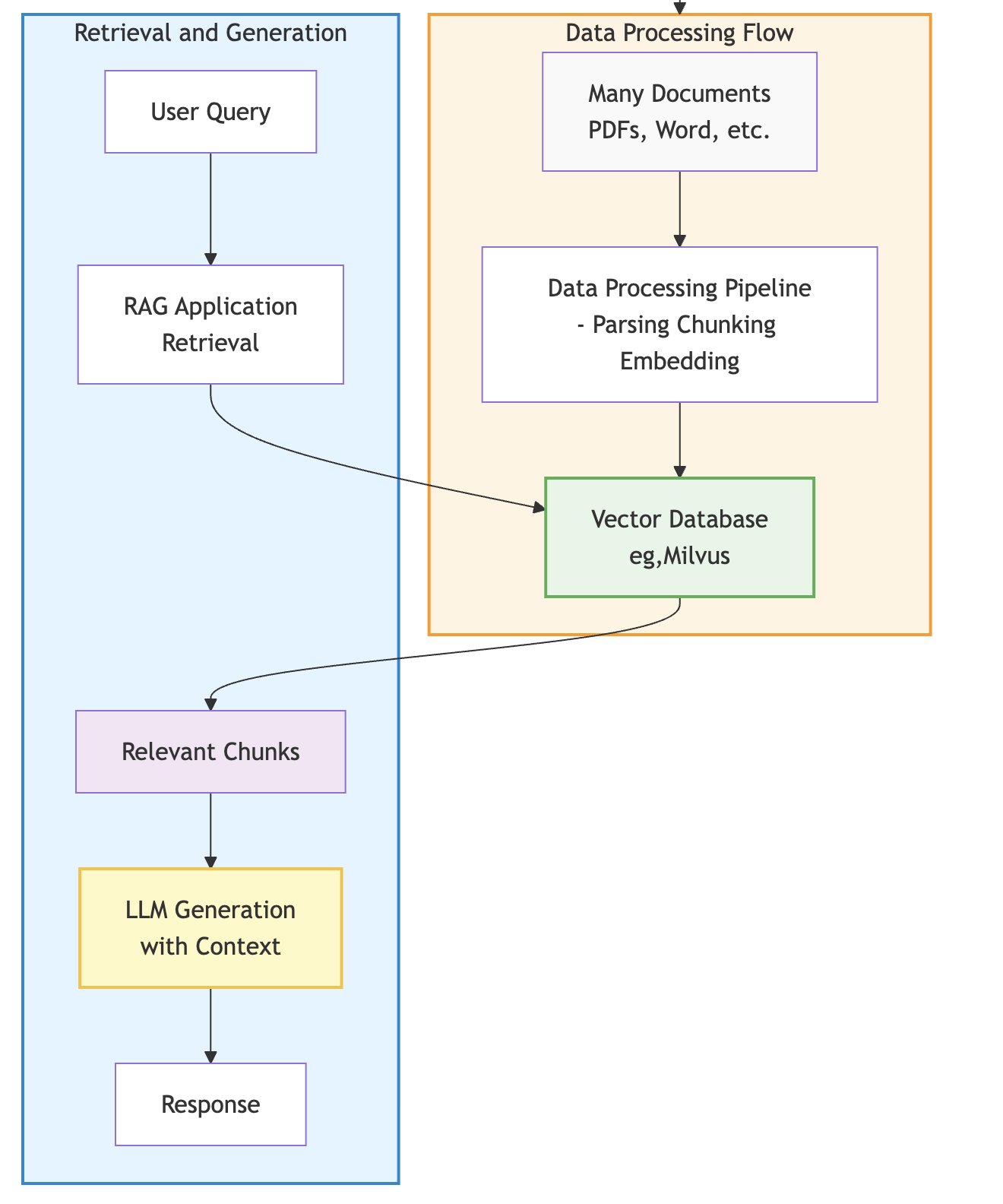
Herkömmliche Frameworks zur Datenverarbeitung werden den Anforderungen von KI oft nicht gerecht, da sie die unterschiedlichen Rechenanforderungen des Datenflusses nicht effektiv mit dem Parsen und Einbetten von Dokumenten koordinieren können. Um KI zu skalieren, müssen Teams in Unternehmen auf eine einheitliche Infrastruktur umsteigen, die sowohl das CPU-intensive Parsen als auch das GPU-intensive Einbetten in einem einzigen, optimierten Prozess bewältigt.
Skalieren mit Ray Data und Docling
Ray Data ist eine Bibliothek für verteilte Verarbeitung, die speziell für KI- und ML-Workloads (Machine Learning) entwickelt wurde. Die Streaming Execution Engine von Ray Data leitet Daten per Pipeline durch CPU- und GPU-Aufgaben und verbessert so die GPU-Auslastung bei gleichbleibender Speichernutzung. Da Ray Data Python-nativ ist, entfällt der Serialisierungs-Overhead beim Übersetzen von Daten zwischen verschiedenen Sprachumgebungen. Dies ermöglicht schnellere Iterationszyklen für RAG-Pipelines.
Docling bewältigt das komplexe Parsen, bei dem herkömmliche Tools oft scheitern. Dies stellt sicher, dass Ihre KI den richtigen Kontext erhält, um nützliche Antworten zu liefern. Durch das präzise Parsen von Tabellen und Layouts in PDFs hilft Docling dabei, die semantische Struktur zu bewahren, wodurch der RAG-Abruf noch nützlicher wird. Bei der Integration in Ray Data führt jeder Node eine Docling-Instanz mit im Arbeitsspeicher eingebetteten Experten-KI-Modellen aus (beispielsweise zur Verarbeitung von Layouts und Tabellen). Dies ermöglicht eine leistungsstarke verteilte Dokumentenverarbeitung.
Ray Data optimiert die Verarbeitung großer Datenmengen, indem es Datensätze in Blöcke partitioniert. Diese werden durch einen Cluster gestreamt, was eine enorme Parallelisierung ermöglicht. In dieser Architektur verwaltet ein Ray Data-Treiber den Ausführungsplan und serialisiert den Aufgabencode (wie die Docling-Verarbeitung) für die Verteilung, während die Ray-Worker die eigentliche Rechenleistung übernehmen. Diese Worker lesen Datenblöcke direkt aus dem Storage und schreiben die resultierenden JSON-Dateien parallel in das Ziel, sodass der Treiber nie zu einem Engpass wird, wie in dieser Architektur dargestellt:
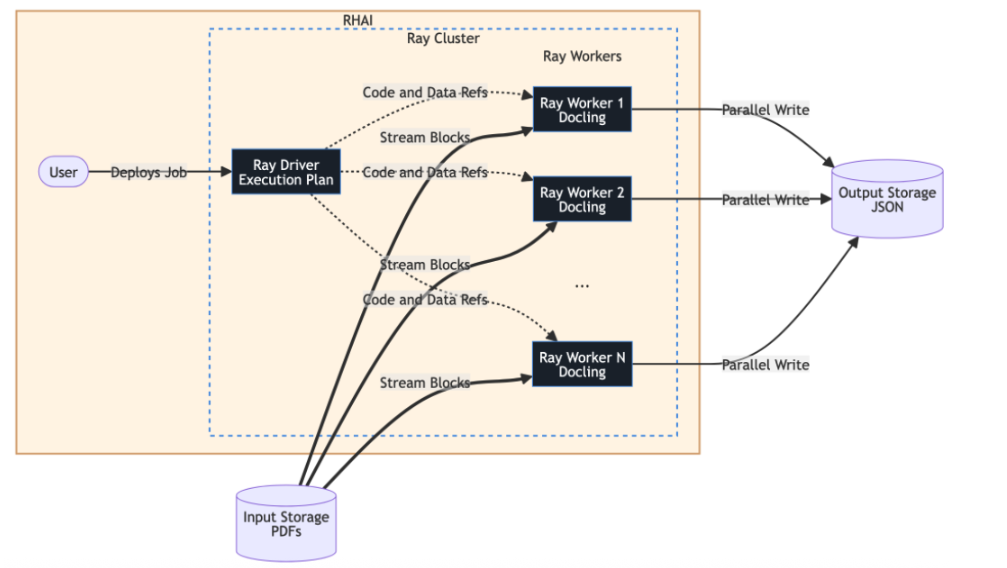
Architektur zur KI-Datenverarbeitung
- Ray-Treiber: Verwaltet die ObjectRefs und den Ausführungsplan und serialisiert den Docling-Code für die Worker.
- Streaming-Blöcke: Die Ray-Worker rufen Daten parallel direkt aus dem Eingabe-Storage ab.
- Paralleles Schreiben: Jeder Worker schreibt seine verarbeitete JSON-Ausgabe direkt in den Storage, sodass der Datendurchsatz den Ray-Treiber nicht überlastet.
Die Integration bewältigt die gesamte verteilte Komplexität, einschließlich Scheduling, Ausfallwiederherstellung und Speicherverwaltung, automatisch. Der Einsatz von heterogenem Computing ermöglicht es CPUs, Daten zu analysieren, während GPUs diese gleichzeitig einbetten, was dazu beiträgt, teure GPU-Ressourcen während des gesamten Prozesses effizienter zu nutzen.
Unternehmensgerechte Zuverlässigkeit mit Red Hat OpenShift AI
OpenShift AI stellt mit KubeRay die Unternehmensbasis bereit und orchestriert Ray-Cluster auf Kubernetes mit integrierten Zuverlässigkeits- und Sicherheitsfunktionen. KubeRay bewältigt operative Komplexitäten wie die dynamische Cluster-Autoskalierung, Fehlertoleranz und die automatische Wiederherstellung beim Ausfall von Workerknoten. Dies ermöglicht eine transparente Skalierung von 10 auf 100 Knoten, um den Anforderungen großer Ingestion-Jobs gerecht zu werden.
Der End-to-End-Ablauf ist unkompliziert, wie hier dargestellt:
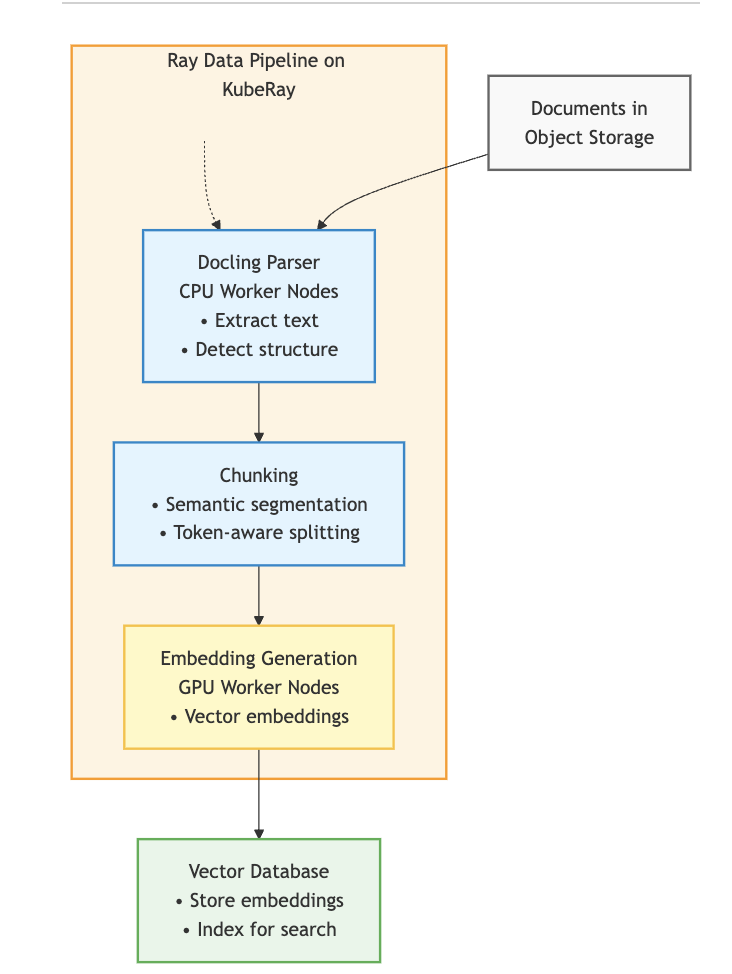
Der Prozess läuft ungefähr so ab:
- Dokumente (z. B. PDFs) landen im Object-Storage (wie S3, PVC).
- Die Ray Data-Pipeline auf OpenShift AI liest diese Dokumente und verteilt sie auf die Workerknoten.
- Docling parst die Dokumente auf den Workerknoten, woraufhin das Chunking für das Einbettungsmodell erfolgt.
- Auf GPU-Knoten werden Einbettungen generiert und in eine Vektordatenbank wie Milvus geschrieben.
- Eine RAG-Anwendung fragt die Datenbank ab und liefert einem LLM Kontext, damit dieses präzise Antworten generiert.
Die Ausführung auf OpenShift AI hält die Datenverarbeitung innerhalb des Kubernetes-Clusters. Dies erleichtert die Einhaltung von Anforderungen an die Datenresidenz und ermöglicht das Deployment in virtuellen Private Clouds oder On-Premises-Umgebungen. Diese einheitliche Infrastruktur reduziert den Betriebsaufwand, da Sie die Datenvorbereitung und die Modellbereitstellung auf derselben Plattform ausführen können.
Ausblick: Auf dem Weg zu agentenbasierten Lösungen
Die Zukunft von Unternehmens-KI hängt davon ab, über die einfache Suche hinauszugehen und hochentwickelte agentische Lösungen einzusetzen. Unternehmen müssen ihre Datenpipelines stärken und weiter verbessern, um mehrstufige agentische Workflows zu unterstützen, in denen autonome Agenten RAG und Retrieval-Augmented Fine Tuning (RAFT) nutzen, um komplexe Probleme zu lösen. Durch die Kombination des Echtzeitkontexts von RAG mit der Fähigkeit von RAFT, ein Modell darauf zu „trainieren“, irrelevantes Rauschen besser zu ignorieren, können Teams wesentlich präzisere und zuverlässigere Agenten entwickeln.
Wer heute in skalierbare Architekturen investiert, ist besser aufgestellt, um diese hochentwickelten Inferenzketten zu implementieren, bei denen mehrere LLM-Aufrufe nacheinander mit optimaler Ressourcenzuweisung erfolgen. Die Umstellung auf agentische KI bedeutet, dass die Qualität Ihrer verarbeiteten Daten kritischer ist als je zuvor, da Agenten auf eine präzise Dokumentation angewiesen sind, um Aufgaben im Namen der Nutzenden auszuführen. Eine robuste Basis sorgt dafür, dass diese kreativen KI-Implementierungen die Unternehmensstandards für Konsistenz und Sicherheit erfüllen.
Letztendlich ist es das Ziel, Informationen für diese KI-Agenten leicht erfassbar und umsetzbar zu machen. Wir sind überzeugt, dass der Erfolg bei generativer KI damit beginnt, komplexe Informationen über eine Open Source-Basis mit einer unternehmensgerechten Governance zugänglich zu machen. Durch den Aufbau einer robusten, einheitlichen Plattform können Unternehmen jetzt dazu beitragen, dass ihre agentischen Initiativen einen langfristigen Mehrwert liefern und das Vertrauen ihrer Nutzenden stärken.
Fazit
Red Hat OpenShift AI und Anyscale bieten die erforderlichen Tools, um komplexe Dokumente in direkt umsetzbare Erkenntnisse umzuwandeln. Indem wir den Engpass bei der Datenverarbeitung mit Ray Data und Docling beseitigen, helfen wir Unternehmen, sich auf das zu konzentrieren, was am wichtigsten ist – die Lösung realer Probleme.
Registrieren Sie sich für den Red Hat Summit 2026, um Kontakt mit unserem Team aufzunehmen und die Zukunft der produktionsreifen KI zu erkunden. Sie können OpenShift AI auch über Red Hat Developer Sandbox ausprobieren und erhalten einen 30-tägigen kostenlosen Zugriff auf eine vollständig verwaltete Umgebung, um diese Tools zu testen.
Produkt
Red Hat AI
Über die Autoren
Ana Biazetti is a senior architect at Red Hat Openshift AI product organization, focusing on Model Customization, Fine Tuning and Distributed Training.
Ähnliche Einträge
Agentische KI erfordert einen neuen Infrastruktur-Stack: AMD und Red Hat bieten eine Lösung
IT-Stack vereinheitlichen: VMs, Cloud und KI vereint
Technically Speaking | Defining sovereign AI with open source
Technically Speaking | Inside open source AI strategy
Nach Thema durchsuchen

Automatisierung
Das Neueste zum Thema IT-Automatisierung für Technologien, Teams und Umgebungen

Künstliche Intelligenz
Erfahren Sie das Neueste von den Plattformen, die es Kunden ermöglichen, KI-Workloads beliebig auszuführen

Open Hybrid Cloud
Erfahren Sie, wie wir eine flexiblere Zukunft mit Hybrid Clouds schaffen.

Sicherheit
Erfahren Sie, wie wir Risiken in verschiedenen Umgebungen und Technologien reduzieren

Edge Computing
Erfahren Sie das Neueste von den Plattformen, die die Operations am Edge vereinfachen

Infrastruktur
Erfahren Sie das Neueste von der weltweit führenden Linux-Plattform für Unternehmen

Anwendungen
Entdecken Sie unsere Lösungen für komplexe Herausforderungen bei Anwendungen
Virtualisierung
Erfahren Sie das Neueste über die Virtualisierung von Workloads in Cloud- oder On-Premise-Umgebungen