
Introduction
As OpenShift consultants, we are often asked whether it is possible to deploy an application to multiple OpenShift clusters distributed across several datacenters.
There can be multiple reasons behind this question, but it's usually because the customer wants to implement a highly-available architecture that leverages existing datacenter investments using an active/active strategy.
Such architecture provides both an implicit Disaster Recovery (DR) strategy and often a better use of resources (when compared to an active/passive scenario). Not needing a disaster recovery strategy, because disasters are implicitly prevented by the resiliency of the architecture, is also referred to as Disaster Avoidance.
It is possible to deploy an application to multiple OpenShift datacenters, but getting the design right and compliant with the specific company's requirements may take time.
I have gathered here some best practices and reference designs to accelerate that process.
In the remainder of the post, we will assume that we are building an architecture for two datacenters (A and B) in which two separated OpenShift clusters are deployed. The generalization to n datacenters and m clusters should relatively straightforward.
We will assume also that these datacenters are geographically dispersed and, therefore, it will not be possible to count on being on the same network or having relatively low latency between them. OpenShift depends on a low latency network across its control plane to synchronously replicate state (so we need to have multiple separate OpenShift clusters), and high-latency networks complicate data replication for applications like databases deployed as containers. In other words, we are trying to solve for the worst case scenario, simpler scenarios may have simpler and more elegant solutions.
At a high-level this will be our architecture:

What about Kubernetes Federation?
Kubernetes Federation's objective is to provide a control plane to manage multiple Kubernetes clusters and automate all of what is described in this document. So why can't we just use it? First, the current Federation implementation is not quite stable enough for General Availability release in the OpenShift product, and we advise clients to wait for it to be fleshed out more in the community project (Kubernetes). Moreover, currently federation only works in cloud environments. As far as I am aware, there are no definitive designs for how Federation would operate in premise implementations.
That said, we will draw inspiration from the Federation design every time we can for two reasons:
- We don't want to reinvent the wheel for problems that have already been solved.
- By having a design that is similar to Federation, we hope to make the eventual transition to Federation as easy as possible.
Networking
For networking we are going to assume the following requirements:
- Each application will have a unique vanity URL. From the perspective of the application consumer this is the only URL they will ever see, regardless of the cluster the requests are being redirected to.
- Applications should also have well-known cluster-specific URLs. It is ok if these URLs are available only internally (that is, they are not exposed to the internet).
- We are willing to sacrifice a bit of flexibility in the URL naming, in favor of automation.
- HTTPS must be supported.
- Each application must be able to failover individually. Many customers ask for this property, although it is not strictly needed to make the applications work. The reason is that it is often convenient to be able to manually shut down an individual application in a datacenter and direct all the traffic to other datacenters, while a local issue is addressed.
Some terminology:
A GSLB (Global Server Load Balancing) or GTM (Global Traffic Manager) is a feature-rich DNS server that given a FQDN may return different IPs based on some logic. Often the logic is based on the geographic location of the datacenter and tries to return the IP of the datacenter that is "closer" to the IP of the caller, but the logic could be something different such as a simple round-robin load balancing. Note that data traffic does not flow through this component.
A SLB (Server Load Balancer) or LTM (Local Traffic Manager) is a feature rich load balancer. In the case of HTTP and HTTPS protocols, the LTM can often act as a proxy and is, therefore, able to apply header transformations or other types of content manipulations if necessary.
Some of the major vendors in this space are F5, Cisco and Citrix. PowerDNS is an open source DNS software with enough capabilities to act as a GTM. HAProxy and Nginx are two open source project that can be used as LTM.
The networking reference architecture is depicted in the following diagram:
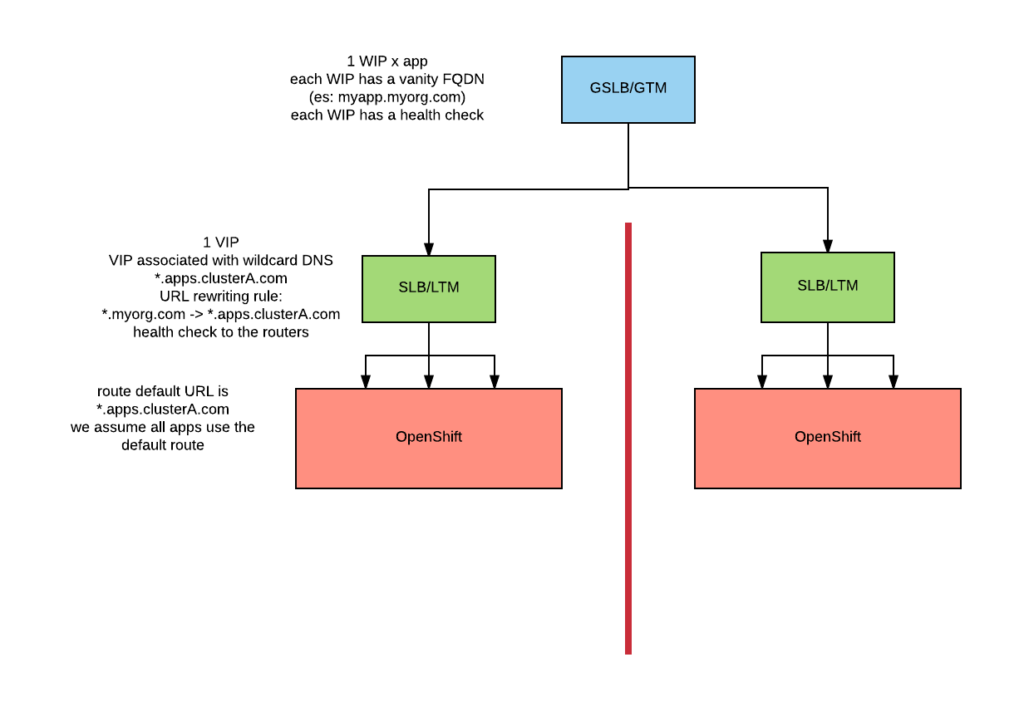
The GTM defines one Wide IP (WIP) per application. All WIPs have the same backend definitions, in this case, the two LTM VIPs. Each WIP also defines a health check. The health checks should check more than one time before declaring a backend unavailable. The reason is that application pods can unexpectedly die, but it is very unlikely that the GTM health check will be served by a dying pod more than one time in a row, so if that happens, we have good indication that the application as a whole is unavailable. The pods' readiness check should use the same endpoint that is used by the GTM. This will make sure that dying pods are promptly removed from the routable pool.
The LTM defines one Virtual IP (VIP). A wildcard DNS record will be associated with this VIP (for example *.apps.clusterA.com) in the corporate DNS. This allows us to direct requests specifically to a selected cluster from within the internal network. A URL rewrite rule is defined on the VIP such that all requests directed to *.myorg.com will be turned into *.apps.clusterA.com. The VIP defines the OpenShift routers as its backend. A health check should be defined to make sure that the routers are available.
The routers always receive a request of the form *.app.clusterA.com, if we assume that the default route has that form and that all applications use the default route then no additional configuration is required.
HTTPS Connections
HTTPS connections will follow the same flow as HTTP connections, with the difference being that the LTM needs to terminate the SSL connection with a wildcard certificate with the following DN: *.myorg.com. And then (if necessary) re-encrypt trusting the wildcard certificate presented by the routers.
Automating the Creation of the WIPs
If it is possible to configure the GTM via APIs, then it should be relatively straightforward to automate the creation of the WIPs. One way to do this is to annotate the Route object in OpenShift that will serve the app with enough information to create the WIP. Then it is possible to write some simple logic that watches the routes and creates the necessary configuration at the GTM level.
There are a few assumptions in this approach that may not work for all companies:
- Having all the URLs follow the same format, both at the WIP and at the router level.
- Exposing a wildcard certificate to external consumers (it is gaining acceptance to do this internally).
- Terminating the TLS connection at the LTM may be an issue for some applications.
Here is an architecture that addresses some of the above shortcomings by compromising on automation:
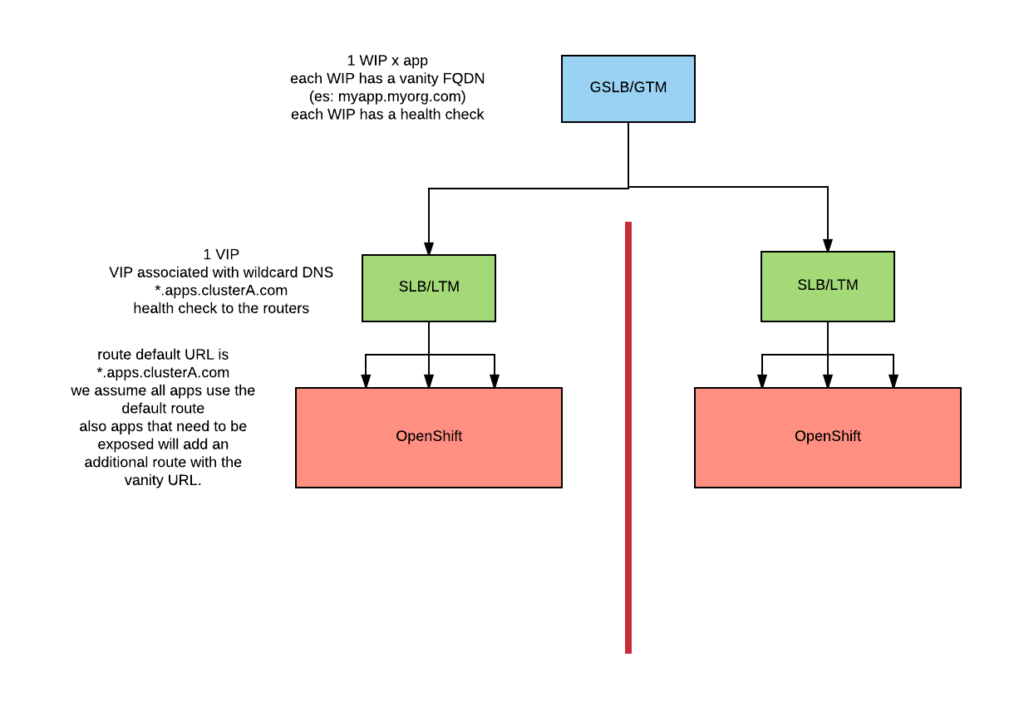
As in the previous case, the GTM defines a WIP for each app. The app can be referenced by any FQDN. Each WIP will have health checks (same caveats as before).
The LTM will have a VIP with a wildcard DNS record associated with it in the corporate DNS (as before). The VIP does not do any URL rewrites and defines a health check as in the previous scenario. The VIP also does not terminate SSL connections but acts always as a passthrough.
The cluster routers define a default route pattern conformant with the wildcard DNS record and all applications define such a route. Applications that need to be accessible externally also define a route with the vanity URL defined in the WIP. If the connection is over SSL, then it will need to be terminated at the router and an appropriate certificate will need to be associated to the route.
Automating the Certificate Creation
We can follow the above suggestion to automatically generate WIPs. In this scenario, though, we also need to generate valid SSL certificates. There a few proof of concepts ( here and here) that show how to integrate OpenShift with an external CA using an additional controller.
Variations on the above architectural approaches can be designed to satisfy additional requirements.
Crossing Datacenters' Boundaries
If a request cannot be fully processed locally (in the datacenter to which it was initially directed) and calls must be made to services in other datacenters, we have to make that request using the vanity URL of that service which will be resolved by the GTM.
Federation handles this use case in a more elegant way, abstracting whether the calls to dependencies are local or to different datacenters and then failing over automatically. The way Federation achieves this is by manipulating entries in SkyDNS (the OpenShift internal DNS service). We cannot manipulate SkyDNS directly and, therefore, we have to fallback to explicitly distinguishing between internal service calls and calls that go through the GTM and that may potentially be routed to a different datacenter.
Compute & Configurations
We assume that we have an OpenShift template that creates our solution and necessary configuration for each environment. We also assume that we have a Continuous Delivery (CD) pipeline process that is capable to deploy to an OpenShift cluster.
When we deploy to multiple clusters we need to analyze what should happen to each of the possible API objects.
Here is what happens in the case of Federation:
| API Object | Federation Behaviour | Notes |
|---|---|---|
| Namespaces | When a federated namespace is created, a namespace with the same name is created in all the federated clusters. | The CD process can be configured to do the same, this behaviour can be extended to OpenShift projects. |
| ConfigMap, Secrets | All the config type of objects have the same behaviour in Federation: They are replicated in each of the federated cluster. | The CD process can be configured to do the same. |
| DaemonSets, Deployment, Jobs, ReplicaSets | All the compute type of objects have the same behaviour in Federation: The object is replicated in all clusters, but the number of replicas assigned to each cluster is divided by the number of clusters. | The CD process can be configured to do the same, including emulating the replica split across the various clusters. |
| Ingress | Federated ingress is still an alpha feature at the time of writing. It sets up the GTM/LTM infrastructure that we have seen in the previous section. | We cannot replicate the behaviour of federated ingress and we should simply create a copy of the ingress in each of the clusters. The same concept can be extended to OpenShift routes. |
| Services | Federated services creates corresponding services in each of the federated cluster, and also enable pods to discover services and pods in other clusters by manipulating a global DNS (GTM). | We cannot easily recreate this behavior with our CD process, so, as mentioned above, if a pod needs to communicate with a pod in another cluster it will have to use an ingress or route. |
| Horizontal Pod Autoscalers (HPA) | Federated HPA (in alpha at the time of writing) has the objective of moving pods to the cluster where they are needed the most. See here for more details. | We cannot emulate this behaviour with our CD process, so we will fall back to deploying statically configured HPA to each individual cluster. |
As we can see, for the most part, Federation just replicates objects in the various target clusters. We can mimic Federation's behaviour by having our CD process deploy API objects to all the involved clusters. The general idea is captured in the following diagram:
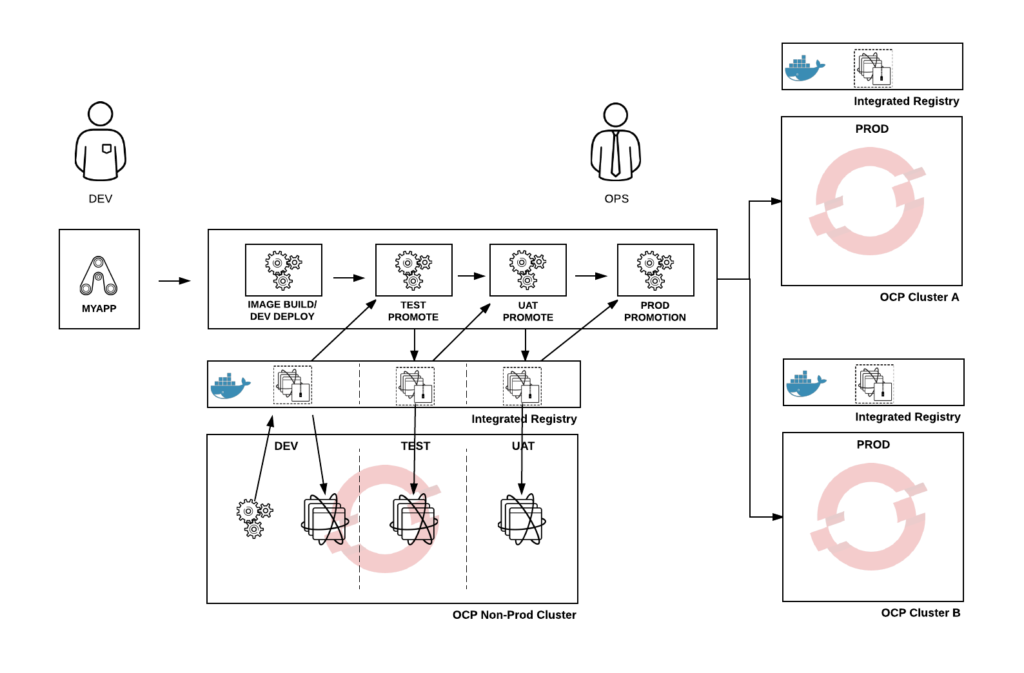
If we are using Jenkins pipelines to define the CD process, our deploy stage will look similar to the following:
pipeline {stages {
...
stage('Deploy') {
parallel {
stage('Deploy in cluster A') {
...
}
stage('Deploy in cluster B') {
...
}
}
}
}
}
There are some objects such as ingresses, services, and HPAs for which we can only approximate the federation behaviour.
Storage
Storage is a notoriously hard problem to solve for geographically distributed deployments. In fact, it's so hard that even the major cloud providers (such as Amazon, Google, Azure) haven't solved it. The heart of the issue is that if two datacenters are significantly apart, the number of network appliances the requests have to go through and the distance itself make the communication latency unacceptable for general storage use cases. The way this issue surfaces with the cloud providers is that volumes are not available across different zones, let alone geographies.
I don't see any near-future solution to this problem and OpenShift will not change that. It is interesting to note that the Federation effort does not tackle storage at this point either.
In my opinion, the best way to approach this issue is to understand the storage use case at hand and design a solution that works for the geographically distributed architecture that we are using.
I have gathered here a list of common geographically distributed storage patterns that can be the base for our design and address broad classes of use cases.
No Replication
This scenario is displayed in the below diagram:
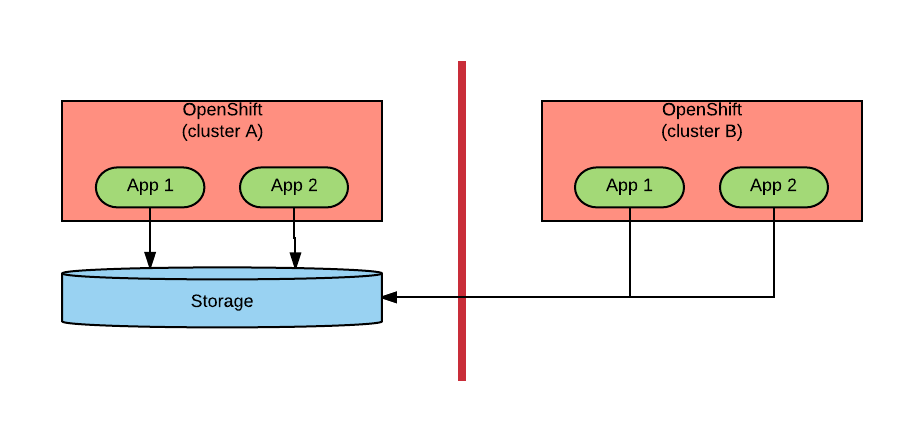
In this scenario, we are basically accepting the long latency for some (half?) of our transactions. This may be an acceptable approach if the two or more datacenters are not too far apart. We also see customers adopting this scenario when there are some constraints by which the storage (or database or mainframe) must exist in only one datacenter (the reasons for that choice are usually not technical).
If the datacenter in which the storage resides is lost in a disaster, then the application becomes unavailable. For this reason, we need a Disaster Recovery (DR) process. Our DR process will involve backing up the storage in the other datacenter and its characteristics are the following:
- Recovery Time Objective (RTO): Time to restore the storage, restart databases or mainframes, reconfigure our OpenShift application to point to the new storage endpoint.
- Recovery Point Objective (RPO): Interval between two backups.
Infrastructure-based Asynchronous Replication
In this scenario, we set up the storage infrastructure to asynchronously replicate volumes across datacenters (we assume that synchronous replication would not work because of the latency).
The below diagram tries to capture this architecture:

Somewhere in our datacenters there are one or more content creators. Once content is created and stored, the storage infrastructure takes care of replicating it to one or more destinations.
The general use case that fits this scenario is when our data is read-only content. When storage is set up this way it will behave like a Content Delivery Network (CDN). Use cases that fit this approach are: Static web content, images, video, and notably, in the container world, container images.
In case one of the datacenters is lost, no DR process is necessary.
Most storage software support this mode of operation, including Container Native Storage (CNS) with its geo replication feature.
Note that this approach can be used to backup data for the No Replication scenario.
Application-based Asynchronous Replication
In this scenario, replication across datacenters is managed by an application. Again we assume that the replication needs to be asynchronous because synchronous replication would involve too long wait times. We also want the database to be highly available and tolerant to network partitions. The relationship between consistency (which requires transactional replication), availability, and tolerance to network partitions has been studied in the CAP theorem, and thanks to it, we know that it is impossible to have all of them.
Applications written to operate in this scenario give up consistency. This means that there could be a period of time in which different instances of that application see a different state. The application synchronization protocol must ensure that eventually, all instances see the same state (eventual consistency).
Many NoSQL databases can operate this way and this is one of the reasons why NoSQL databases tend to be so successful in very large and geographically distributed deployments. The below picture tries to capture this concept:

In case of a disaster, no DR process is necessary in this scenario, but some of the data may not be recovered until the instances in the lost datacenter are recovered. Mongodb, Kafka and Cassandra are just some examples of software that can work in this mode.
An interesting case in this space is Google Spanner. Spanner is a geographically-distributed transactional database, so it apparently violates the CAP theorem. Strictly speaking, Spanner gives up availability and is a CP (consistent during network partitions). Spanner uses the 2 phase commit protocol across geographies and the the paxos leader election protocol for clusters within a region. The reason Google claims that Spanner is also highly available is because they are banking on their network being very available as described in this document.
Application-based Data Partitioning
In this scenario, data is not replicated across datacenters, but is partitioned between them.
The assumption is that we have a way of splitting the traffic that makes sure that once requests enter a datacenter, they can be completely fulfilled there. Applications must be designed to work that way.
Under this assumption, we can organize our storage as shown in the below diagram:

Notice that the way we have set up our ingress networking, based on GTM and LTM, does not allow us to select a datacenter based on some piece of information contained in the request (content based routing). Some additional mechanism must be added at that level.
In case of a disaster, we are in a similar situation as we are for the No Replication scenario. In this case, in order to recover we also need to change the content-based router rules to allow for content that would have gone to the lost datacenter to be directed to one of the healthy datacenters.
Conclusions
This post explains a set of concerns that should be considered when planning to deploy an application in geographically distributed OpenShift clusters. I hope I have provided enough ideas and best practices to enable teams to quickly come up with implementable designs.
Über den Autor
Raffaele is a full-stack enterprise architect with 20+ years of experience. Raffaele started his career in Italy as a Java Architect then gradually moved to Integration Architect and then Enterprise Architect. Later he moved to the United States to eventually become an OpenShift Architect for Red Hat consulting services, acquiring, in the process, knowledge of the infrastructure side of IT.
Currently Raffaele covers a consulting position of cross-portfolio application architect with a focus on OpenShift. Most of his career Raffaele worked with large financial institutions allowing him to acquire an understanding of enterprise processes and security and compliance requirements of large enterprise customers.
Raffaele has become part of the CNCF TAG Storage and contributed to the Cloud Native Disaster Recovery whitepaper.
Recently Raffaele has been focusing on how to improve the developer experience by implementing internal development platforms (IDP).
Ähnliche Einträge
KI-Bedrohungen abwehren: Agile Security für Unternehmen
Der KI-Wendepunkt: Warum Souveränität nicht optional ist
Container Roundup | Compiler
Untangling Networks | Compiler
Nach Thema durchsuchen

Automatisierung
Das Neueste zum Thema IT-Automatisierung für Technologien, Teams und Umgebungen

Künstliche Intelligenz
Erfahren Sie das Neueste von den Plattformen, die es Kunden ermöglichen, KI-Workloads beliebig auszuführen

Open Hybrid Cloud
Erfahren Sie, wie wir eine flexiblere Zukunft mit Hybrid Clouds schaffen.

Sicherheit
Erfahren Sie, wie wir Risiken in verschiedenen Umgebungen und Technologien reduzieren

Edge Computing
Erfahren Sie das Neueste von den Plattformen, die die Operations am Edge vereinfachen

Infrastruktur
Erfahren Sie das Neueste von der weltweit führenden Linux-Plattform für Unternehmen

Anwendungen
Entdecken Sie unsere Lösungen für komplexe Herausforderungen bei Anwendungen
Virtualisierung
Erfahren Sie das Neueste über die Virtualisierung von Workloads in Cloud- oder On-Premise-Umgebungen