


Generative AI products such as OpenAI’s ChatGPT and DALL-E have generated excitement around large foundation models that train on massive amounts of broad data to create impressive textual, visual, and audio content. The buzz around generative AI has been so great because its benefits are easily understood.
The movement towards open sourcing foundation models is increasing in popularity because of the potential ethical issues associated with AI. However, building foundation models is not a cheap or easy endeavor, and a lot of energy and resources have been invested in training open source foundation models like Google’s BERT or Dolly. The initial training phase of foundation models requires vast amounts of generic data, consumes tens of thousands of state-of-the-art GPUs, and often requires a group of machine learning engineers and scientists.
For a foundation model to become an expert in a specific domain, it can be adapted by customization techniques, such as fine-tuning and prompt tuning. These often require additional domain- or customer-specific data.
What is Red Hat’s role in foundation models?
Rather than creating the actual foundation model, Red Hat’s focus is to provide the underlying foundation model workload infrastructure, including the environment to enable training, prompt tuning, fine-tuning, and serving of these models.
Recent announcements from IBM describe how their next-gen AI platform, IBM watsonx.ai, will run on an open source technology stack based on Red Hat OpenShift, an application platform based on Kubernetes. This stack is being built into Open Data Hub (ODH), an open source platform for building, deploying, and managing data-intensive applications on Kubernetes. Technologies matured in Open Data Hub feed into Red Hat OpenShift AI, Red Hat’s AI-focused portfolio, and specifically the commercial product, Red Hat OpenShift Data Science.
Why hybrid cloud?
There are many reasons to consider an open hybrid cloud AI foundation to do this fine-tuning—both legal and data-related issues. Data scientists need to consider legal questions such as whether the pretrained model is available under a suitable license and whether it was trained from suitable sources. Data challenges include understanding what data was used to train the model and whether, for compliance, government restrictions or sheer data volume may restrict where you can run the model. For these reasons, many organizations may want to consider on-site options for their fine-tuning foundation model infrastructure.
Red Hat is building a scalable environment to optimize the large compute footprint and handle distributed workload management and orchestration. The environment will be based on Red Hat OpenShift Data Science, which will be extended to better handle foundation models.
Because it is built on Red Hat OpenShift, which can run on-premise or in all major public clouds, Red Hat OpenShift Data Science gives data scientists and developers a powerful AI/ML platform for gathering insights from data and building intelligent applications. It is part of Red Hat OpenShift AI, an AI-focused portfolio that provides tools across the full lifecycle of AI/ML experiments and models.
The architecture jointly developed by IBM Research and Red Hat
For large model training and fine-tuning, we have recently started the incubation of Project CodeFlare in the open source Open Data Hub community, which will make its way into Red Hat OpenShift Data Science later this year. The CodeFlare Project provides a distributed training stack with batch processing and on-demand resource scaling capabilities. With CodeFlare, customers will be able to easily deploy and manage hundreds of distributed AI/ML workloads, all while minimizing the computational costs to their organization. It is composed of three components: CodeFlare SDK, Multi-Cluster Application Dispatcher (MCAD), and InstaScale. CodeFlare SDK provides an easy-to-use interface and can be easily accessed from a Jupyter Notebook. Here is a link to the quick start guide for CodeFlare.
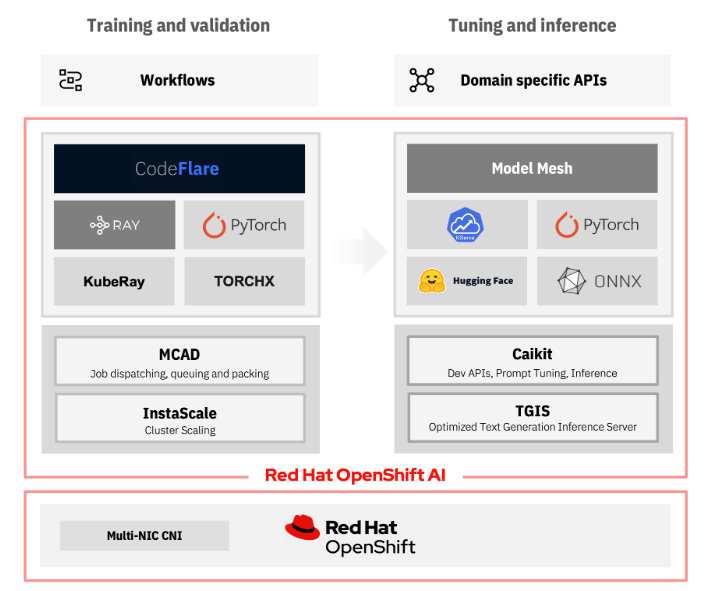
Figure 1: open source foundation model training and inferencing stack
To support prompt tuning and inferencing of foundation models, we recently introduced Caikit. Caikit provides the APIs to perform multi-task prompt tuning and text generation inferencing (TGIS).
Another important component in the architecture is the model serving framework. The serving engine within Open Data Hub is based on KServe technology, a popular model inferencing technology on Kubernetes, and is included in OpenShift Data Science as its model serving component.
Where can you see this in action?
One early example of how we are building this technology to solve real-life customer problems is Red Hat Ansible Lightspeed with IBM Watson Code Assistant. Ansible Lightspeed is a generative AI service accessed via an Ansible VSCode extension, allowing users to accept and run recommended code directly in their code-editing environment while creating Ansible Playbooks.
Red Hat plans to extend the environment for other foundation models built by open source communities such as HuggingFace or commercial companies both in the upstream Open Data Hub project as well as in its commercial product, Red Hat OpenShift Data Science.
This approach to providing the underlying infrastructure to fine-tune and serve models across the hybrid cloud capitalizes on the innovation happening in the open source community while providing the flexibility to work with both foundation models and standard machine learning models. Creating a collaborative environment based on OpenShift that can run consistently, whether on-site or in the public cloud, can really help accelerate and scale an organization’s AI initiatives across the model lifecycle. We are eager to see how organizations leverage foundation models to drive new, compelling use cases.
For more information on Red Hat OpenShift Data Science, visit red.ht/datascience
Über die Autoren
Selbi Nuryyeva is a software engineer at Red Hat in the OpenShift AI team focusing on the Open Data Hub and Red Hat OpenShift Data Science products. In her current role, she is responsible for enabling and integrating the model serving capabilities. She previously worked on the Distributed Workloads with CodeFlare, MCAD and InstaScale and integration of the partner AI/ML services ecosystem. Selbi is originally from Turkmenistan and prior to Red Hat she graduated with a Computational Chemistry PhD degree from UCLA, where she simulated chemistry in solar panels.
Will McGrath is a Senior Principal Product Marketing Manager at Red Hat. He is responsible for marketing strategy, developing content, and driving marketing initiatives for Red Hat OpenShift AI. He has more than 30 years of experience in the IT industry. Before Red Hat, Will worked for 12 years as strategic alliances manager for media and entertainment technology partners.
Ähnliche Einträge
Agentische KI erfordert einen neuen Infrastruktur-Stack: AMD und Red Hat bieten eine Lösung
IT-Stack vereinheitlichen: VMs, Cloud und KI vereint
Technically Speaking | Inside open source AI strategy
Technically Speaking | Build a production-ready AI toolbox
Nach Thema durchsuchen

Automatisierung
Das Neueste zum Thema IT-Automatisierung für Technologien, Teams und Umgebungen

Künstliche Intelligenz
Erfahren Sie das Neueste von den Plattformen, die es Kunden ermöglichen, KI-Workloads beliebig auszuführen

Open Hybrid Cloud
Erfahren Sie, wie wir eine flexiblere Zukunft mit Hybrid Clouds schaffen.

Sicherheit
Erfahren Sie, wie wir Risiken in verschiedenen Umgebungen und Technologien reduzieren

Edge Computing
Erfahren Sie das Neueste von den Plattformen, die die Operations am Edge vereinfachen

Infrastruktur
Erfahren Sie das Neueste von der weltweit führenden Linux-Plattform für Unternehmen

Anwendungen
Entdecken Sie unsere Lösungen für komplexe Herausforderungen bei Anwendungen
Virtualisierung
Erfahren Sie das Neueste über die Virtualisierung von Workloads in Cloud- oder On-Premise-Umgebungen