
Docker containers are used to package software applications into portable, isolated stores. Developing software with containers helps developers create applications that will run the same way on every platform. However modern microservice deployments typically use a scheduler such as Kubernetes to run in production. In order to fully simulate the production environment, developers require a local version of production tools. In the Red Hat stack, this is supplied by the Red Hat Container Development Kit (CDK).
The Red Hat CDK is a customized virtual machine that makes it easy to run complex deployments resembling production. This means complex applications can be developed using production grade tools from the very start
, meaning developers are unlikely to experience problems stemming from differences in the development and production environments.
This blog post walks through installation and configuration of the Red Hat CDK. We will create a containerized multi-tier application on the CDK’s OpenShift instance and go through the entire workflow. By the end of this blog post you will know how to run an application on top of OpenShift and will be familiar with the core features of the CDK and OpenShift.
Let’s get started...
Installing the CDK
The prerequisites for running the CDK are Vagrant and a virtualization client (VirtualBox, VMware Fusion, libvirt). Make sure that both are up and running on your machine.
We wrote this example using VirtualBox on a MacOS laptop, but it should run identically on other set-ups.
Start by going to Red Hat Product Downloads (note that you will need a Red Hat subscription to access this). Select ‘Red Hat Container Development Kit’ under Product Variant, and the appropriate version and architecture. You should download two packages:
- Red Hat Container Tools
- RHEL Vagrant Box (for your preferred virtualization client)
The Container Tools package is a set of plugins and templates that will help you start the Vagrant box. In the components subfolder you will find Vagrant files that will configure the virtual machine for you. The plugins folder contains the Vagrant add-ons that will be used to register the new virtual machine with the Red Hat subscription and to configure networking.
Unzip the container tools archive into the root of your user folder and install the Vagrant add-ons.
$ cd $HOME/cdk/plugins
$ vagrant plugin install vagrant-registration vagrant-adbinfo landrush
You can check if the plugins were actually installed with this command:
$ vagrant plugin list
Add the box you downloaded into Vagrant. The path and the name may vary depending on your download folder and the box version:
$ vagrant box add --name cdkv2 \
~/Downloads/rhel-cdk-kubernetes-7.2-13.x86_64.vagrant-virtualbox.box
Check that the vagrant box was properly added with the box list command:
$ vagrant box list
We will use the Vagrantfile that comes shipped with the CDK and has support for OpenShift.
$ cd $HOME/cdk/components/rhel/rhel-ose/
$ ls
README.rst Vagrantfile
In order to use the landrush plugin to configure the DNS we need to add the following two lines to the Vagrantfile:
config.landrush.enabled = true
config.landrush.host_ip_address = "#{PUBLIC_ADDRESS}"This will allow us to access our application from outside the virtual machine based on the hostname we configure. Without this plugin, your applications will be reachable only by IP address from within the VM.
Save the changes and start the virtual machine :
$ vagrant up
During initialization you will be prompted to register your Vagrant box with your RHEL subscription credentials.
Let's review what just happened here. On your local machine you have now a working instance of the OpenShift PaaS running inside a virtual machine. This instance can talk to the Red Hat Registry to download images for the most common application stacks. You also get a private Docker registry for storing images. Docker, Kubernetes, OpenShift and Atomic App CLIs are also installed.
Now that we have our Vagrant box up and running, it’s time to create and deploy a sample application to OpenShift, and create a continuous deployment workflow for it.
The OpenShift console should be accessible at https://10.1.2.2:8443 from a browser on your host (this IP is defined in the Vagrantfile). By default the login credentials will be test-user/test-user. You can also use your Red Hat credentials to login.
In the console, we create a new project:

Next we create a new application using one of the built-in ‘Instant Apps’. Instant Apps are pre-defined application templates that pull specific images. These are an easy way to quickly get an app up and running. From the list of Instant Apps, select “nodejs-mongodb-example” which will start a database (mongodb) and a web server (Node.js).
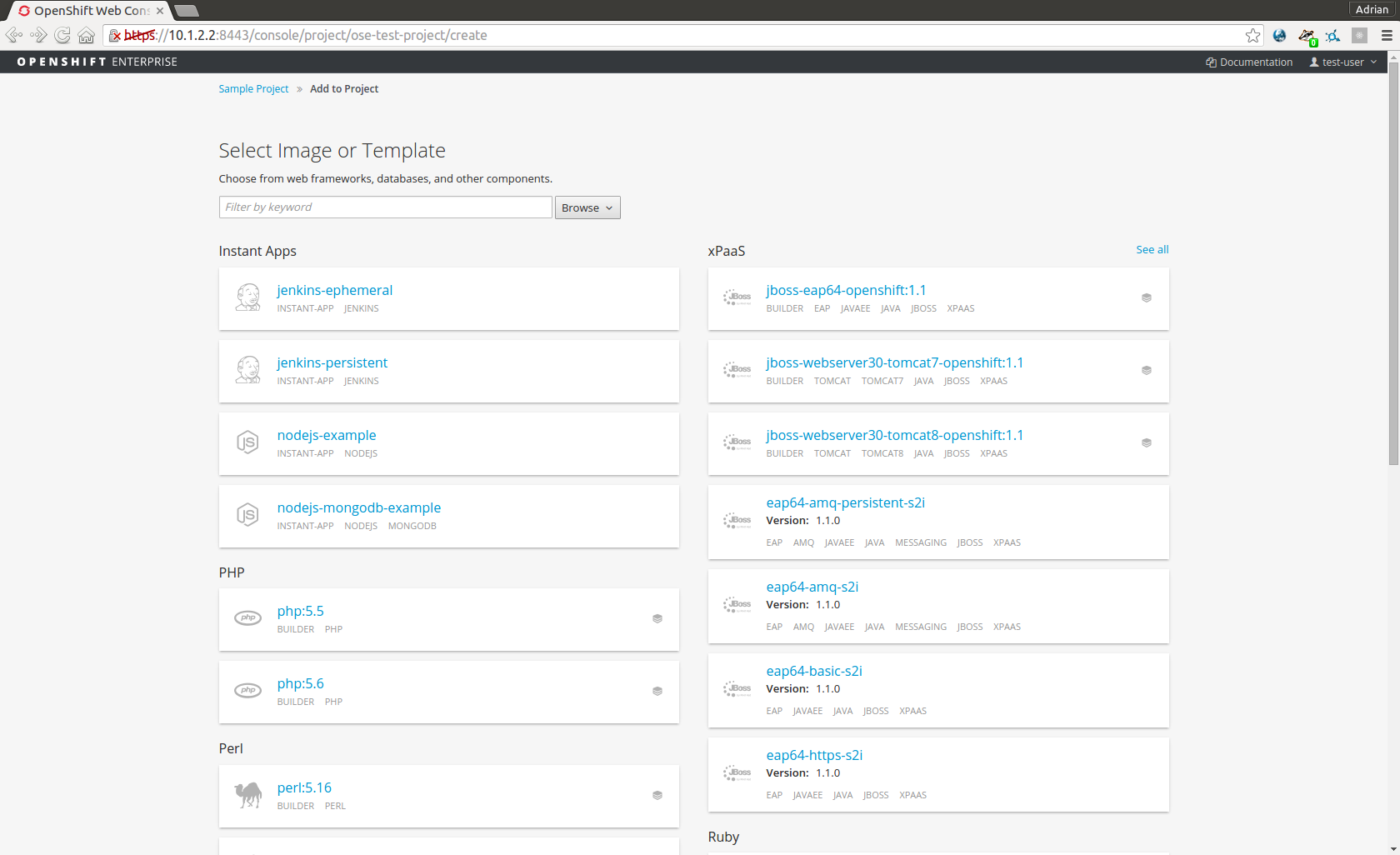
For this application we will use the source code from the OpenShift GitHub repository located here: https://github.com/openshift/nodejs-ex. If you want to follow along with the webhook steps later, you’ll need to fork this repository into your own. Once you’re ready, enter the URL of your repo into the SOURCE_REPOSITORY_URL field:
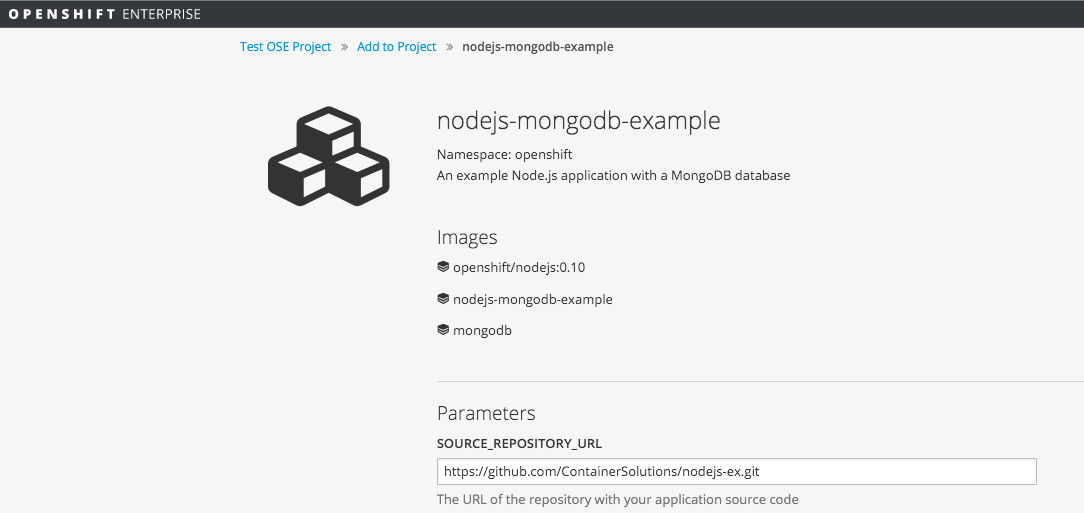
There are two other parameters that are important to us - GITHUB_WEBHOOK_SECRET and APPLICATION_DOMAIN:
- GITHUB_WEBHOOK_SECRET: this field allows us to create a secret to use with the GitHub webhook for automatic builds. You don’t need to specify this, but you’ll need to remember the value later if you do.
- APPLICATION_DOMAIN: this field will determine where we can access our application. This value must include the Top Level Domain for the VM, by default this value is rhel-ose.vagrant.dev. You can check this by running vagrant landrush ls.
Once these values are configured, we can ‘Create’ our application. This brings us to an information page which gives us some helpful CLI commands as well as our webhook URL. Copy this URL as we will use it later on.
OpenShift will then pull the code from GitHub, find the appropriate Docker image in the Red Hat repository, and also create the build configuration, deployment configuration, and service definitions. It will then kick off an initial build. You can view this process and the various steps within the web console. Once completed it should look like this:

If you’re running on MacOS, the application will be available on the host via the domain we specified in the creation step. If you’re running on top of Linux, you will need to do some extra work to get the VM name to resolve via DNS.

Great! Our application has now been built and deployed on our local OpenShift environment. To complete the Continuous Deployment pipeline we just need to add a webhook into our GitHub repository we specified above, which will automatically update the running application.
To set up the webhook in GitHub, we need a way of routing from the public internet to the vagrant machine running on your host. An easy way to achieve this is to use a third party forwarding service such as ultrahook or ngrok. We need to set up a URL in the service that forwards traffic through a tunnel to the webhook URL we copied earlier.
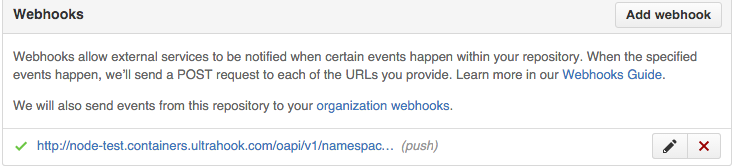
Once this is done, open the GitHub repo and go to Settings -> Webhooks & services -> Add webhook. Under Payload URL enter the URL that the forwarding service gave you, plus the secret (if you specified one when setting up the OpenShift project). If your webhook is configured correctly you should see something like this:
To test out the pipeline, we need to make a change to our project and push a commit to the repo. Any easy way to do this is to edit the views/index.html file, e.g:

(Note that you can also do this through the GitHub web interface if you’re feeling lazy). Commit and push this change to the GitHub repo, and we can see a new build is triggered automatically within the web console. Once the build completes, if we again open our application we should see the updated front page.

We now have Continuous Deployment configured for our application.
Throughout this blog-post we’ve used the OpenShift web interface. However, we could have performed the same actions using the OpenShift console (oc) at the command-line. The easiest way to experiment with this interface is to ssh into the CDK VM via the vagrant ssh command.
Before wrapping up, it’s helpful to understand some of the concepts used in Kubernetes, which is the underlying orchestration layer in OpenShift.
Pods
Our OpenShift applications run in docker containers inside pods. Pods are the smallest unit that you can control in OpenShift (and in Kubernetes in general). For our example application we have now one Pod running one mongodb container and another Pod running one Node.js application. Pods can be scaled up/down from the OpenShift interface.
Replication controllers manage the lifecycle of Pods.They ensure that the correct number of Pods are always running by monitoring the application and stopping or creating Pods as appropriate.
Services
Pods are grouped into services. Our architecture has now two services: the database (mongo) and the web server (nodejs).
Deployments
With every new code commit (assuming you set-up the GitHub webhooks) OpenShift will update your application. New pods will be started with the help of replication controllers running your new application version. The old pods will be deleted. OpenShift deployments can perform rollbacks and provide various deploy strategies.
Conclusion
It’s hard to overstate the advantages of being able to run a production environment in development and the efficiencies gained from the fast feedback cycle of a Continuous Deployment pipeline.
In this post we have shown how to use the Red Hat CDK to achieve both of these goals within a short-time frame. By the end of the post, we had a Node.js and mongodb application running in containers, deployed using the OpenShift PaaS. This is a great way to quickly get up and running with containers and microservices and to experiment with OpenShift and other elements of the Red Hat container ecosystem.
Über den Autor
Ähnliche Einträge
KI-Bedrohungen abwehren: Agile Security für Unternehmen
Der KI-Wendepunkt: Warum Souveränität nicht optional ist
Container Roundup | Compiler
Untangling Networks | Compiler
Nach Thema durchsuchen

Automatisierung
Das Neueste zum Thema IT-Automatisierung für Technologien, Teams und Umgebungen

Künstliche Intelligenz
Erfahren Sie das Neueste von den Plattformen, die es Kunden ermöglichen, KI-Workloads beliebig auszuführen

Open Hybrid Cloud
Erfahren Sie, wie wir eine flexiblere Zukunft mit Hybrid Clouds schaffen.

Sicherheit
Erfahren Sie, wie wir Risiken in verschiedenen Umgebungen und Technologien reduzieren

Edge Computing
Erfahren Sie das Neueste von den Plattformen, die die Operations am Edge vereinfachen

Infrastruktur
Erfahren Sie das Neueste von der weltweit führenden Linux-Plattform für Unternehmen

Anwendungen
Entdecken Sie unsere Lösungen für komplexe Herausforderungen bei Anwendungen
Virtualisierung
Erfahren Sie das Neueste über die Virtualisierung von Workloads in Cloud- oder On-Premise-Umgebungen