

InstructLab ist ein communitybasiertes Projekt, das darauf abzielt, den Prozess der Mitwirkung an Large Language Models (LLMs) und deren Verbesserung durch Generierung synthetischer Daten zu vereinfachen. Mit dieser Initiative wird auf mehrere Herausforderungen reagiert, mit denen Entwicklungsteams konfrontiert sind. Dazu gehören die Komplexität der Beiträge zu LLMs, das Problem der Modellausuferung, die durch Modellverzweigung verursacht wird, und der Mangel an direkter Community-Governance. InstructLab wird von Red Hat und IBM Research unterstützt und nutzt neuartige, auf synthetischen Daten basierende Methoden zur Ausrichtungsabstimmung, um Performance und Zugänglichkeit der Modelle zu verbessern. Im Folgenden sprechen wir über das aktuelle Problem und die technischen Herausforderungen, die beim traditionellen Fine Tuning von Modellen auftreten, sowie über den Ansatz, den InstructLab zur Lösung dieser Probleme verfolgt.
Die Herausforderung: niedrige Datenqualität und ineffiziente Nutzung der Rechenressourcen
Da der Wettbewerb im LLM-Bereich zunimmt, scheint der Ansatz darin zu bestehen, immer größere Modelle zu entwickeln, die mit riesigen Datenmengen aus dem öffentlichen Internet trainiert werden. Große Teile des Internets enthalten jedoch redundante Informationen oder Daten in nicht natürlicher Sprache, die nicht zur Kernfunktionalität des Modells beitragen.
So stammen beispielsweise 80 % der Token, die zum Trainieren des LLM GPT-3 verwendet werden, auf dem spätere Versionen basieren, von Common Crawl, das eine enorme Anzahl von Webseiten umfasst. Dieser Datensatz enthält bekanntermaßen eine Mischung aus Text von hoher Qualität, Text von geringer Qualität, Skripten und anderen Daten in nicht natürlicher Sprache. Es wird geschätzt, dass es sich bei einem erheblichen Teil der Daten um nicht nutzbare Inhalte oder Inhalte von geringer Qualität handelt. (Common Crawl-Analyse)
Die Folge dieses großen Umfangs an nicht kuratierten Daten ist eine ineffiziente Nutzung der Rechenressourcen, die zu hohen Trainingskosten führt. Dies wiederum erhöht die Kosten für die Nutzenden dieser Modelle und stellt Herausforderungen bei der Implementierung der Modelle in lokalen Umgebungen dar.
Wir sehen eine zunehmende Anzahl von Modellen mit weniger Parametern, bei denen die Qualität und Relevanz der Daten wichtiger sind als die reine Quantität. Modelle mit einer präziseren und gezielteren Datenkuratierung bieten eine bessere Performance, erfordern weniger Rechenressourcen und liefern qualitativ hochwertigere Ergebnisse.
Die Lösung von InstructLab: Verfeinerung der Generierung synthetischer Daten
Das Besondere an InstructLab ist die Fähigkeit, mit nur einem kleinen Seed-Datensatz große Datenmengen für das Training zu generieren. Verwendet wird die LAB-Methode (Large-Scale Alignment for chatBots), die LLMs mit möglichst wenigen, von Menschen generierten Daten, und minimalem Rechenaufwand verbessert. Dies bietet Einzelpersonen eine benutzerfreundliche Möglichkeit, relevante Daten beizusteuern, die dann durch Generieren synthetischer Daten mit einem Modell verbessert werden, das den Generierungsprozess unterstützt.

Hauptmerkmale des Ansatzes von InstructLab:
Taxonomiegesteuerte Datenkuratierung:
Der Prozess beginnt mit der Erstellung einer Taxonomie – einer hierarchischen Struktur, die verschiedene Kompetenzen und Wissensbereiche organisiert. Diese Taxonomie dient als Roadmap für das Kuratieren erster, von Menschen generierter Beispiele, die als Startdaten für den Prozess der Generierung synthetischer Daten fungieren. Diese Daten sind in einer Struktur organisiert, mit der Sie das vorhandene Wissen des Modells einfach untersuchen und Lücken finden können, bei denen Sie dazu beitragen können, redundante, unorganisierte Informationen zu reduzieren. Gleichzeitig wird die spezifische Ausrichtung eines Modells auf einen Use Case oder bestimmte Anforderungen ermöglicht, wobei nur einfach zu formatierende YAML-Dateien im Frage-Antwort-Paar-Format verwendet werden.

Generierung synthetischer Daten
Aus den Basisdaten nutzt InstructLab ein Lehrmodell, um während der Datengenerierung neue Beispiele zu erstellen. Es ist wichtig zu beachten, dass bei diesem Prozess kein vom Lehrmodell gespeichertes Wissen verwendet wird, sondern bestimmte Prompt Templates, die den Datensatz erheblich erweitern und gleichzeitig sicherstellen, dass die neuen Beispiele die Struktur und den Zweck der ursprünglichen, von Menschen kuratierten Daten beibehalten. Bei der LAB-Methodik werden 2 spezifische Generatoren für synthetische Daten verwendet:
- Skills Synthetic Data Generator (Skills-SDG): Verwendet Prompt-Vorlagen für die Anweisungsgenerierung, Bewertung, Antwortgenerierung und abschließende Bewertung.
- Knowledge-SDG: Generiert Anweisungsdaten für Bereiche, die nicht vom Lehrmodell abgedeckt sind, unter Verwendung externer Wissensquellen als Grundlage der generierten Daten.
Auf diese Weise reduziert es den Bedarf an großen, manuell mit Anmerkungen versehenen Datenmengen. Die Verwendung der kleinen, besonderen und von Menschen erstellten Beispiele als Referenz ermöglicht die Kuratierung von Hunderten, Tausenden oder Millionen von Frage-Antwort-Paaren, um die Gewichtungen und Verzerrungen des Modells zu beeinflussen.
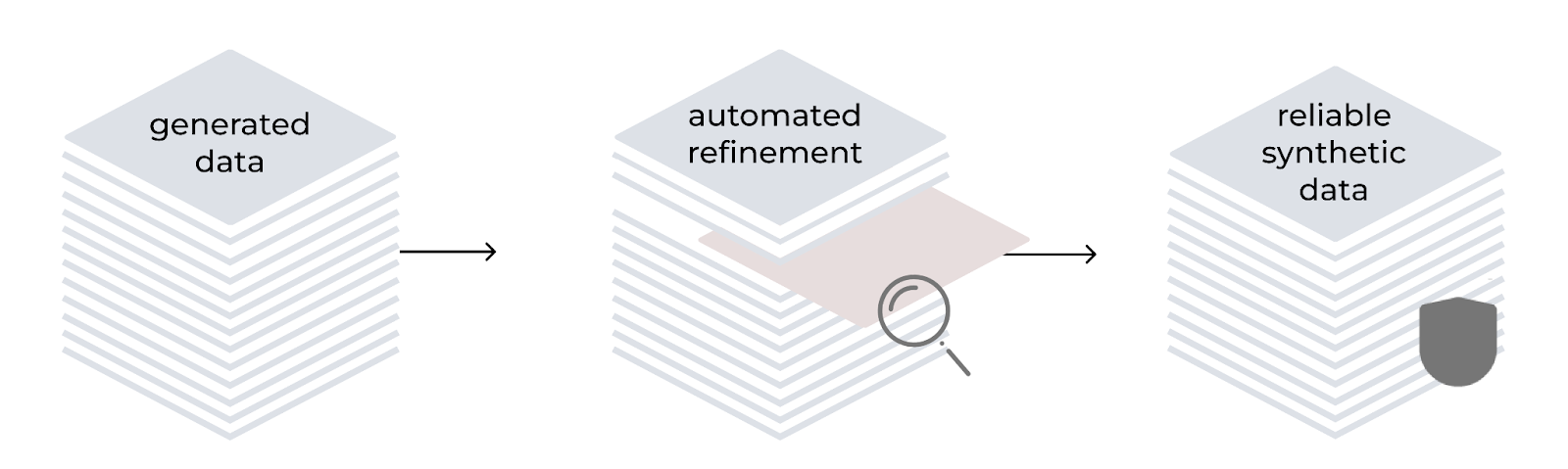
Automatisierte Optimierung
Das LAB-Verfahren beinhaltet einen automatisierten Optimierungsprozess zur Verbesserung der Qualität und Zuverlässigkeit synthetisch generierter Trainingsdaten. Es orientiert sich an einer hierarchischen Taxonomie und verwendet das Modell sowohl als Generator als auch als Evaluator. Der Prozess umfasst das Generieren von Anweisungen, das Filtern von Inhalten, das Generieren von Antworten und die Bewertung mithilfe eines 3-Punkte-Systems. Bei wissensbasierten Aufgaben beruhen die generierten Inhalte auf zuverlässigen Quelldokumenten, wodurch potenzielle Ungenauigkeiten in spezialisierten Domains behoben werden.
Multiphasen Tuning-Framework
InstructLab implementiert einen mehrphasigen Trainingsprozess, um die Performance des Modells schrittweise zu verbessern. Dieser stufenweise Ansatz trägt dazu bei, die Trainingsstabilität zu erhalten, und ein Replay-Buffer der Daten verhindert katastrophales Vergessen. So kann das Modell kontinuierlich lernen und sich verbessern. Die generierten synthetischen Daten werden in einem zweistufigen Tuning-Prozess verwendet:
- Knowledge Tuning: Integriert neue Fakten, unterteilt in ein Training mit kurzen Antworten, gefolgt von langen Antworten und grundlegenden Kompetenzen
- Skills Tuning: Verbessert die Fähigkeit des Modells, Wissen bei verschiedenen Aufgaben und Kontexten anzuwenden, und konzentriert sich dabei auf Kompositionsfähigkeiten

Das Framework verwendet kleine Lernraten, lange Aufwärmzeiten und eine große effektive Batch-Größe, um die Stabilität zu erhöhen.
Iterativer Verbesserungszyklus
Der Prozess zur Generierung synthetischer Daten ist iterativ konzipiert. Sobald neue Beiträge zur Taxonomie geleistet werden, können sie zur Generierung zusätzlicher synthetischer Daten verwendet werden, was das Modell weiter verbessert. Dieser kontinuierliche Verbesserungszyklus trägt dazu bei, das Modell auf dem neuesten Stand und relevant zu halten.
Ergebnisse und Bedeutung von InstructLab
InstructLab ermöglicht es, mit öffentlich verfügbaren Lehrmodellen eine erstklassige Performance zu erreichen, anstatt sich auf proprietäre Modelle zu verlassen. In Benchmarks hat die InstructLab-Methode vielversprechende Ergebnisse gezeigt. Bei der Anwendung auf Llama-2-13b (resultierend in Labradorite-13b) und Mistral-7B (resultierend in Merlinite-7B) übertrafen die mit LAB trainierten Modelle beispielsweise die derzeit besten Modelle, die auf ihre jeweiligen Basismodelle abgestimmt waren, in Bezug auf die MT-Bench-Scores. Auch bei anderen Metriken wie MMLU (Prüfung des Multitasking-Sprachverständnisses), ARC (Bewertung des logischen Denkens) und HellaSwag (Bewertung der Schlussfolgerungen im Bereich Allgemeinwissen) erzielten sie gute Ergebnisse.

Communitybasierte Zusammenarbeit und Zugänglichkeit
Einer der wichtigsten Vorteile von InstructLab ist sein Open Source-Charakter und das Ziel, generative KI so zu demokratisieren, dass alle an der Gestaltung der Zukunft von Modellen mitwirken können. Die Befehlszeilenschnittstelle (CLI) ist so konzipiert, dass sie auf gängiger Hardware wie Laptops ausgeführt werden kann. Dies senkt die Einstiegshürde für Entwicklungsteams und Mitwirkende. Darüber hinaus fördert das InstructLab-Projekt die Beteiligung der Community, indem es den Mitgliedern ermöglicht, neue Kenntnisse oder Kompetenzen in ein Hauptmodell einzubringen, das regelmäßig entwickelt und auf Hugging Face veröffentlicht wird. Das neueste Modell können Sie sich hier ansehen.

Der Prozess zur Generierung synthetischer Daten von InstructLab, der auf der LAB-Methodik basiert, stellt einen bedeutenden Fortschritt auf dem Gebiet der generativen KI dar. Durch die effiziente Erweiterung von LLMs um neue Funktionen und Wissensdomains ebnet InstructLab den Weg für einen gemeinschaftlicheren und effektiveren Ansatz bei der KI-Entwicklung. Wenn Sie mehr über das Projekt erfahren möchten, empfehlen wir Ihnen, instructlab.ai zu besuchen oder diesen Guide für den Einstieg zu lesen, um InstructLab auf Ihrem Rechner zu testen.
Über die Autoren
Cedric Clyburn (@cedricclyburn), Senior Developer Advocate at Red Hat, is an enthusiastic software technologist with a background in Kubernetes, DevOps, and container tools. He has experience speaking and organizing conferences including DevNexus, WeAreDevelopers, The Linux Foundation, KCD NYC, and more. Cedric loves all things open-source, and works to make developer's lives easier! Based out of New York.
Legare Kerrison is a Technical Marketing Manager and Developer Advocate working on Red Hat's Artificial Intelligence offerings. She is passionate about open source AI and making technical knowledge accessible to all. She is based out of Boston, MA.
Ähnliche Einträge
KI-Bedrohungen abwehren: Agile Security für Unternehmen
Flut an KI-generierte Sicherheitsschwachstellen erfordert menschliche IT-Expertise
Untangling Networks | Compiler
Technically Speaking | Defining sovereign AI with open source
Nach Thema durchsuchen

Automatisierung
Das Neueste zum Thema IT-Automatisierung für Technologien, Teams und Umgebungen

Künstliche Intelligenz
Erfahren Sie das Neueste von den Plattformen, die es Kunden ermöglichen, KI-Workloads beliebig auszuführen

Open Hybrid Cloud
Erfahren Sie, wie wir eine flexiblere Zukunft mit Hybrid Clouds schaffen.

Sicherheit
Erfahren Sie, wie wir Risiken in verschiedenen Umgebungen und Technologien reduzieren

Edge Computing
Erfahren Sie das Neueste von den Plattformen, die die Operations am Edge vereinfachen

Infrastruktur
Erfahren Sie das Neueste von der weltweit führenden Linux-Plattform für Unternehmen

Anwendungen
Entdecken Sie unsere Lösungen für komplexe Herausforderungen bei Anwendungen
Virtualisierung
Erfahren Sie das Neueste über die Virtualisierung von Workloads in Cloud- oder On-Premise-Umgebungen