
The image garbage collector is one of two mechanisms present in every kubernetes cluster node trying to maintain enough available space in the local disks for normal operations to continue. The other mechanism is the container garbage collector which is not covered in detail in this article.
The image garbage collector is part of the kubelet and automatically removes unused images from the node when a configured disk usage percentage is reached.
This article describes how the image garbage collector works and how to modify its configuration to improve performance and availability in an Openshift cluster.
Images and Filesystem Storage
Every pod deployed in an Openshift cluster is made up of one or more containers, each of these containers is based on an image that must be pulled down into the node the first time it is used. Because this is a costly operation in terms of time and network bandwidth, images are kept in the local disk creating a cache to speed up the creation of future containers based on recently used images.
Every image is basically a collection of regular files stored in the directory specified by the parameter graphroot in the configuration file /etc/containers/storage.conf. The default value in an Openshift cluster node is:
graphroot = "/var/lib/containers/storage"Caching images locally in the nodes can save time and network traffic, but can also consume a large amount of disk space.
Images are kept indefinitely in the local cache, in particular an image is not deleted when there are no more containers using it in the node. Local cache and registry are also completely independent, pruning the internal registry does not have the effect of removing the pruned images from the node's local cache.
Over time and due to the normal use of the Openshift cluster, images will pile up in the node's local cache consuming an ever increasing amount of disk space. To minimize the risk of running out of disk space there is an automatic mechanism that removes unused images from the local cache: The image garbage collector.
The image garbage collector constantly watches over the filesystem containing the image cache, if it detects that its usage percentage goes over a configured high threshold, some images are removed without the need of user intervention. The number of images removed is the minimum required to reach a configured low threshold, the goal here is to prevent the disk from filling up while maximizing the number of images in the cache. Only images that are not being used by any container can be removed.
The image garbage collector may not succeed in releasing the space required, there may not be enough unused images to remove, the filesystem space could be consumed by other files: temporary files, log messages created by running containers or the operating system, etc.
If the image garbage collector is unable to reduce the disk usage percentage, the container garbage collector will take additional measures.
How Does the Image Garbage Collector Work
The image garbage collector is part of the kubelet and runs independently on each node. It wakes up every 5 minutes and checks the usage percentage in the filesystem containing the images, there is no synchronization between nodes so the starting time will be different for each one of them.
An image garbage collector run follows these steps:
The usage percentage in the filesystem holding the container images is computed.
If the usage percentage is at the configured high threshold or above, the amount of bytes that need to be removed to reach the configured low threshold is computed. Otherwise if the high threshold has not been exceeded, this run ends and the next steps are not executed.
A list of all the unused images existing in the local cache is created, only images that don't have a container using them are added to the list.
The list of unused images is sorted according to the last time they were used by a container.
The list is traversed from "oldest" to "newest" and for every image visited:
- The image is checked to determine whether it has been in the node longer than a configured minimum age, if that is the case it is deleted, otherwise go to the next image in the list.
- If an image was deleted in the previous step, the number of bytes released is added to a counter of all bytes deleted in this image garbage collector run.
- If the total amount of bytes deleted so far is larger than the amount required to reduce the usage percentage of the filesystem below the configured low threshold, this run ends and no more images are deleted, otherwise go to the next image in the list.
If all images in the list have been visited but not enough disk space has been released, an error message is sent to the log and this image garbage collection run ends.
If enough disk space has been released to go below the high threshold but not below the low threshold, the next time the image garbage collector runs it does not try to remove additional unused images, only when the high threshold is reached again a new run will start.
All the previous steps are taken without affecting the normal operations in the node, in particular new pods can be deployed while the image garbage collector is running even if that means new images need to be pulled into the node.
Working Example
The following example illustrates a typical image garbage collector run:
- The filesystem containing the images has a capacity of 120 GB.
- The high threshold is set to 74% (88.8 GB).
- The low threshold is set to 69% (82.8 GB).
- The minimum image age is set to 5 minutes and 30 seconds.
The filesystem usage has grown to 90.9 GB since the last image garbage collector run, above 76%. The additional consumed space doesn't necessarily have to come from new images pulled into the node, it could be temporary files, log files, etc.
Next time the image garbage collector wakes up, it detects that the usage percentage is above the high threshold of 74% so it computes the amount of bytes it needs to delete to go down to the low threshold of 69%. The following message appears in the node's log:
Disk usage on image filesystem is at 77% which is over the high threshold (74%). Trying to free 9123558236 bytes down to the low threshold (69%).The usage percentage is rounded up to 77%. The space to free is around 8.5 GB.
The node contains:
- 45 containers, using 30 different images.
- 168 total images, 138 of which are not being used by any container
The image garbage collector creates a list of unused images and sorts it out according to the last time they were used, then deletes as many images as required to release the amount of bytes computed in the first step. Some of the images included in the list may be in use by a container, however this is a minor error since these images will not be deleted.
The following extract from the log shows the images being removed, all of them are older than the minimum 5 minutes 30 seconds.
Removing image "b88df34d660a1e83fdb351d076f07bb0dea66cd47e4aeb72a026f3e2d4f532cf" to free 648163659 bytes
Removing image "f04243cec82b99516491ff8c4c0087c4f6644d61d130c74f1d44f72ab65fae1f" to free 918015854 bytes
Removing image "b08aef8ffcdd9dfe6d2582db7c637a058627ab00e9890344642d03cff78a3f26" to free 844269695 bytes
Removing image "84cb9cf0503a209c5731e4a61732d7663b1bebd78b0152567d3a75f180268841" to free 674198872 bytes
Removing image "3e7316459b8e9009968f52dff2a9071e9871c29d758b394efcda84878b6e8807" to free 646500683 bytes
Removing image "a66c3f307cdb21c84f93b62db6f4c7e74cf9f6970e58dfcf144ea53f45f2de02" to free 323363999 bytes
Removing image "7a19c9b3fb2ffa85d73732e5278e7ad314353618eeef0a8c8f07bb04ca6b023d" to free 267674800 bytes
Removing image "211cf05bb9a70e244ab6af0c6ddb53e914f1f8d2760767e4b5c13dd74458de69" to free 511012751 bytes
Removing image "868449820f31f3112477b8f61a06c832cfe76dc99afbd75fa8007a0e0ec137ff" to free 298767731 bytes
Removing image "22133b02a85f517b08d44ebf048439dfd69ba0576d29c0bf28051b40f3c18e80" to free 1219368157 bytes
RemoveImage "22133b02a85f517b08d44ebf048439dfd69ba0576d29c0bf28051b40f3c18e80" from image service failed: rpc error: code = Unknown desc = Image used by 2b435f6b905ac531894c1631902b3fe2717c6554fd52bc90d803ec9e4da1c08d: image is in use by a container
Remove image "22133b02a85f517b08d44ebf048439dfd69ba0576d29c0bf28051b40f3c18e80" failed: rpc error: code = Unknown desc = Image used by 2b435f6b905ac531894c1631902b3fe2717c6554fd52bc90d803ec9e4da1c08d: image is in use by a container
Removing image "4411bfe8d2f1426ba61c600610cd67cf22a2b9a7f718b46a195489780c95c989" to free 674198873 bytes
Removing image "0561497623f838518bacd45d480f8868cca3f05d4c7586e9e300b13e38da35f1" to free 660754312 bytes
Removing image "7491f5f484164674f3d1610e58dab752dae275fabd5fe68fd8a13f9f52814217" to free 236515650 bytes
Removing image "3faaab80cd610654276b199994986568feb6376cdf72832a3595bc8b0b26497e" to free 321482743 bytes
Removing image "ede24212466429bd94b7c7a01892c39e7564de594a87c22770cb548d245825b5" to free 324947033 bytes
Removing image "6e07543c6b6e12c27bcf94ea93df93a491f623355b0cb06a2233a0d3e308cc11" to free 281203361 bytes
Removing image "15686194eddbc83851cacab4ffbd97938750a8fe57f2c5022edd8aedf396eeb9" to free 263075986 bytes
Removing image "f660c39eb19f065d7f10c9f0aa17cacf51f0df3054f00cce19bacce99146f065" to free 521937062 bytes
Removing image "87efd68a920f1fd8dc45111ed4578ff85c81c3959caed49a60f89687b1ea432f" to free 461642966 bytes
Removing image "fbaf322a7e2aaeb28af4b4b3ae021b4f71ed6cbcc5201f025a363e62579b6c2b" to free 302723450 bytes
Image garbage collection failed once. Stats initialization may not have completed yet: wanted to free 9123558236 bytes, but freed 9180449480 bytes space with errors in image deletion: rpc error: code = Unknown desc = Image used by 2b435f6b905ac531894c1631902b3fe2717c6554fd52bc90d803ec9e4da1c08d: image is in use by a containerThe final message reports a failed result because one of the images could not be removed, however this was expected because the image is being used by a container, therefore the final result can be considered a success since the number of bytes deleted is larger than the objective defined at the beginning of the run: wanted to free 9123558236 bytes, but freed 9180449480 bytes
The usage percentage in the filesystem after the image garbage collector has finished may not be what is expected. The following picture shows a graph with data collected by prometheus, the vertical axis represents usage percentage, the horizontal axis represents time of day.
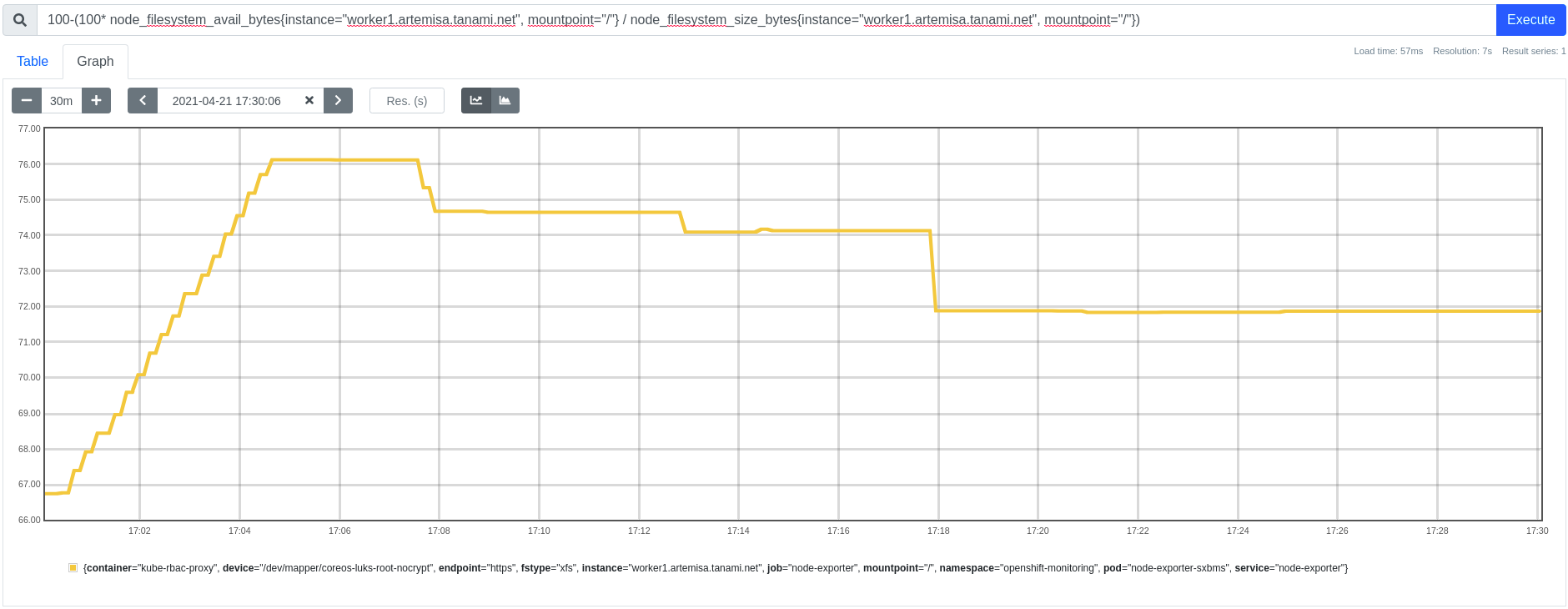
In the first part the usage percentage grows from around 67% to just above 76% in about 3 minutes, then the filesystem stays stable for another 3 minutes until the image garbage collector wakes up at exactly 17:07:36 and removes the images shown earlier in the log excerpt. However instead of going down to the low threshold of 69%, the filesystem usage percentage stays just under 75% which in fact is above the high threshold, there are two main reasons for this:
- The filesystem usage percentage is not recalculated during the image deletion loop.- Because of this the image garbage collector doesn't know the actual usage percentage after the images have been removed.
- Images are made of immutable layers that can be shared between them.- This is a design feature in container images, thanks to layers being immutable it is common that they share one or more of the lower layers resulting in a significant space saving, but when these images are removed only a portion of the total size is released.
In the above picture, after the first image garbage collector run, the filesystem stays stable for five minutes until the next run at 17:12:39 when another batch of images is removed, this time the amount of bytes to delete is 6.7 GB, but again the images deleted share a large part of the space they take so the usage percentage is barely reduced and stays above the 74% high threshold mark.
Disk usage on image filesystem is at 75% which is over the high threshold (74%). Trying to free 7240807260 bytes down to the low threshold (69%).
...
Image garbage collection failed multiple times in a row: wanted to free 7240807260 bytes, but freed 7546615567 bytes space with errors in image deletion: ...The error message is again because some images were included in the list of unused images by mistake and could not be deleted.
Finally five minutes later at 17:17:40 the image garbage collector wakes up and detects that the usage percentage is above the high threshold so another batch of images is deleted. This time the reduction is enough to take the usage percentage under 72% which is below the high threshold but still above the expected low threshold of 69%. The error message has the same cause as in the previous runs.
Disk usage on image filesystem is at 75% which is over the high threshold (74%). Trying to free 6577705820 bytes down to the low threshold (69%).
...
Image garbage collection failed multiple times in a row: wanted to free 6577705820 bytes, but freed 7226991725 bytes space with errors in image deletion: ...The image garbage collector will not take any further actions until the usage percentage goes above the 74% high threshold mark again.
It took the image garbage collector 3 consecutive runs to go below the 74% high threshold and yet the usage percentage did not go down to the expected 69%. 52 images out of the total 138 unused images were deleted. On a positive note, the normal operations in the node were not affected during the time the garbage collector was doing its job.
Configuring the Image Garbage Collector
The image garbage collector configuration is embedded in the kubelet configuration and has 3 parameters that can be modified by the cluster administrator:
- imageMinimumGCAge.- The minimum age since the image was pulled into the node before it can be removed by the image garbage collector. It is expressed as a number and a time suffix (s for seconds, m for minutes, h for hours):
5m;300s;1h5m20s - imageGCHighThresholdPercent.- The maximum usage percentage allowed in the filesystem before the image garbage collector starts the process of removing unused images. It is expressed as an integer representing a percentage without the % simbol:
80 - imageGCLowThresholdPercent.- The target usage percentage that the image garbage collector will try to go down to by deleting unused images. It is expressed as an integer representing a percentage without the % simbol:
75
The frequency at which the image garbage collector checks the status of the filesystem is set to once every 5 minutes and cannot be modified in the configuration.
To inspect the current kubelet's configuration for a particular node in an Openshift cluster, the following command can be used. In this example the node's name is worker1.artemisa.example.com. The jq utility is used to pretty print the output.
Only the relevant information for the image garbage collector is shown:
$ oc get --raw /api/v1/nodes/worker1.artemisa.example.com/proxy/configz | jq
...
"imageMinimumGCAge": "2m0s",
"imageGCHighThresholdPercent": 85,
"imageGCLowThresholdPercent": 80,
...In this case the image garbage collector will trigger when the filesystem usage percentage reaches 85%, and will try to delete just enough images to go down to 80%. Images that have been pulled into the node less than two minutes ago cannot be deleted by the image garbage collector, even if they are not being used by any containers. This prevents deleting images that have just been pulled into the node but don't have a corresponding container created yet.
To modify the kubelet configuration, an object of type KubeletConfig needs to be created in the cluster with the new configuration values. This KubeletConfig object is associated with one or more machine config pools which results in the new configuration to be applied to the nodes in those pools.
Different KubeletConfig objects can be applied to different machine config pools so the nodes in those pools can get the configuration that best fit their characteristics.
One important point to notice is that applying configuration changes through machineconfig and machineconfigpools causes the reboot of all the nodes in the affected pools.
The following example shows how to modify the kubelet configuration in all worker nodes to have the image garbage collector trigger when the filesystem usage reaches 75%, then try to remove enough images to go down to 70%. The minimum age for an image to be eligible for deletion is set to 5 minutes 30 seconds.
The yaml definition for the KubeletConfig object with the above configuration values is:
apiVersion: machineconfiguration.openshift.io/v1
kind: KubeletConfig
metadata:
name: imgc-kubeconfig
spec:
kubeletConfig:
imageGCHighThresholdPercent: 75
imageGCLowThresholdPercent: 70
imageMinimumGCAge: "5m30s"
machineConfigPoolSelector:
matchLabels:
pools.operator.machineconfiguration.openshift.io/worker: ""The section machineConfigPoolSelector links this KubeletConfig object to one or more machine config pools. A matchLabels or matchExpressions subsection must contain at least one label that is present in the machine config pool's metadata.labels section.
The label used in this example is found in the worker machine config pool so the kubelet configuration will be applied to all worker nodes:
$ oc get machineconfigpool worker -o yaml|grep -A 2 labels
labels:
machineconfiguration.openshift.io/mco-built-in: ""
pools.operator.machineconfiguration.openshift.io/worker: ""To apply the KubeletConfig object to more than one machine config pool, a common label can be added to those pools and then used in the machineConfigPoolSelector section.
The next example adds the label imgc=optimized to the master and worker machine config pools:
$ oc label machineconfigpool master worker imgc=optimized The new label can then be used in KubeletConfig object definition:
apiVersion: machineconfiguration.openshift.io/v1
kind: KubeletConfig
...
machineConfigPoolSelector:
matchLabels:
imgc: optimizedOnce the KubeletConfig yaml definition is ready, the next step is to create the object in the Openshift cluster. If the yaml definition is saved in the file kubeletconf-workers.yaml:
$ oc create -f kubeletconf-workers.yaml
kubeletconfig.machineconfiguration.openshift.io/imgc-kubeconfig createdAfter a few seconds the machine config pool shows up with status UPDATED=False, UPDATING=True, READYMACHINECOUNT=0, UPDATEDMACHINECOUNT=0. This means that the KubeletConfig object has been accepted and the process to apply the new configuration to the nodes is in progress:
$ oc get machineconfigpools
NAME CONFIG UPDATED UPDATING DEGRADED MACHINECOUNT READYMACHINECOUNT UPDATEDMACHINECOUNT DEGRADEDMACHINECOUNT AGE
master rendered-master-50f40899cc607585ec6bd6edd8c99164 True False False 3 3 3 0 88d
worker rendered-worker-08ef6581d005ba7463bc1bb9fa6ceaca False True False 2 0 0 0 88dThe whole process will take several minutes while every node in the pool is marked unschedulable and its pods are drained, then rebooted with the new configuration. Only one node is handled at any given time to minimize disruption in the cluster.
# oc get nodes
NAME STATUS ROLES AGE VERSION
master1.artemisa.example.com Ready master 88d v1.20.0+551f7b2
master2.artemisa.example.com Ready master 88d v1.20.0+551f7b2
master3.artemisa.example.com Ready master 88d v1.20.0+551f7b2
worker1.artemisa.example.com Ready,SchedulingDisabled worker 88d v1.20.0+551f7b2
worker2.artemisa.example.com Ready worker 88d v1.20.0+551f7b2After a node is completely updated, the machine config pool output shows an increment of 1 in the READYMACHINECOUNT and UPDATEDMACHINECOUNT columns:
# oc get machineconfigpools
NAME CONFIG UPDATED UPDATING DEGRADED MACHINECOUNT READYMACHINECOUNT UPDATEDMACHINECOUNT DEGRADEDMACHINECOUNT AGE
master rendered-master-50f40899cc607585ec6bd6edd8c99164 True False False 3 3 3 0 88d
worker rendered-worker-08ef6581d005ba7463bc1bb9fa6ceaca False True False 2 1 1 0 88dThe process of making the node unschedulable, drain its pods, and reboot it, repeats for every node in the machine config pool until all have the new configuration in place, then the status is changed to UPDATED=True, UPDATING=False:
# oc get machineconfigpools
NAME CONFIG UPDATED UPDATING DEGRADED MACHINECOUNT READYMACHINECOUNT UPDATEDMACHINECOUNT DEGRADEDMACHINECOUNT AGE
master rendered-master-50f40899cc607585ec6bd6edd8c99164 True False False 3 3 3 0 88d
worker rendered-worker-8099cb059b905294f6deee4b03085295 True False False 2 2 2 0 88dImproving the Default Configuration
The image garbage collector tries to prevent the node's local disk from filling up by removing unused images without the need of user intervention and without affecting the cluster normal operation. However the default kubelet configuration could produce unexpected results and may not be ideal in many situations.
The following command shows the default node's configuration in an Openshift 4.7 cluster:
$ oc get --raw /api/v1/nodes/worker1.artemisa.example.com/proxy/configz | jq
...
"imageMinimumGCAge": "2m0s",
"imageGCHighThresholdPercent": 85,
"imageGCLowThresholdPercent": 80,
...
"evictionHard": {
"imagefs.available": "15%",
...The evictionHard section (there is no evictinSoft in the default configuration) represents the minimum percentage of free space in the images filesystem at which the container garbage collector will trigger: 15% free = 85% usage. With this configuration both image and container garbage collectors will react at the same time.
When the container garbage collector triggers, it takes a series of steps to increase the free space available in the disk and go back above the 15% limit.
- It enables the DiskPressure condition in the node until the situation has been resolved.
- It deletes non running pods along with their containers. This removes all temporary files created by the container.
- If the free percentage is still below 15%, all unused images are deleted.
- If it is still below 15%, user deployed pods in running state are evicted from the node until the disk free percentage goes above the 15% mark.
The container garbage collector causes disruption, by applying the previous steps, in the following ways:
- By enabling the DiskPressure condition, which blocks the deployment of new pods in the node. The minimum time this condition is active is 5 minutes even if the disk space shortage has been recovered sooner.
- By completely clearing out the local image cache, which delays the start of new containers based on previously cached images.
- By evicting running pods from the node, which forces the pod to be deployed on a different node if a suitable one is available.
The default kubelet configuration can be improved by setting the image garbage collector to trigger earlier than the container garbage collector, reducing the disruption caused by the latter because it will only run when the image garbage collector fails to resolve the situation.
The following example shows such a configuration in which the image garbage collector will trigger at 75% usage while the container garbage collector will trigger at 15% free or 85% usage.
$ oc get --raw /api/v1/nodes/worker1.artemisa.example.com/proxy/configz | jq
...
"imageMinimumGCAge": "2m0s",
"imageGCHighThresholdPercent": 75,
"imageGCLowThresholdPercent": 70,
...
"evictionHard": {
"imagefs.available": "15%",
...Always make sure that the high threshold level at which the image garbage collector is activated is defined at a lower level than that of the container garbage collector, otherwise the effect of the configuration is to disable the image garbage collector. For example if the high threshold for the image garbage collector is set to 88% usage while the container garbage collector activates at 15% free (85% usage), the container garbage collector will always activate before the image garbage collector, taking all the disruptive steps shown before.
Another possible improvement to the configuration consists on reducing the low threshold imageGCLowThresholdPercent below the actual threshold that is expected to reach. As explained in the example section earlier, it is common that the usage percentage stays above the defined low threshold by a significant margin after the image garbage collector deletes the images. So "aiming low" in the configuration may give more accurate results. In the following example, the low threshold expected is 70%, but the configuration uses 65% for better results:
$ oc get --raw /api/v1/nodes/worker1.artemisa.example.com/proxy/configz | jq
...
"imageMinimumGCAge": "2m0s",
"imageGCHighThresholdPercent": 75,
"imageGCLowThresholdPercent": 65,
...
"evictionHard": {
"imagefs.available": "15%",
...Über den Autor
Ähnliche Einträge
KI-Bedrohungen abwehren: Agile Security für Unternehmen
IT-Orchestrierung: Catalyst und Ansible Automation Platform
Container Roundup | Compiler
Untangling Networks | Compiler
Nach Thema durchsuchen

Automatisierung
Das Neueste zum Thema IT-Automatisierung für Technologien, Teams und Umgebungen

Künstliche Intelligenz
Erfahren Sie das Neueste von den Plattformen, die es Kunden ermöglichen, KI-Workloads beliebig auszuführen

Open Hybrid Cloud
Erfahren Sie, wie wir eine flexiblere Zukunft mit Hybrid Clouds schaffen.

Sicherheit
Erfahren Sie, wie wir Risiken in verschiedenen Umgebungen und Technologien reduzieren

Edge Computing
Erfahren Sie das Neueste von den Plattformen, die die Operations am Edge vereinfachen

Infrastruktur
Erfahren Sie das Neueste von der weltweit führenden Linux-Plattform für Unternehmen

Anwendungen
Entdecken Sie unsere Lösungen für komplexe Herausforderungen bei Anwendungen
Virtualisierung
Erfahren Sie das Neueste über die Virtualisierung von Workloads in Cloud- oder On-Premise-Umgebungen