

Intel hat kürzlich die 5. Generation der skalierbaren Intel® Xeon® Prozessoren (Intel Xeon SP) mit dem Codenamen Edge Rapids auf den Markt gebracht; eine Familie von unternehmensorientierten, leistungsstarken Prozessoren für verschiedene Workloads. Um herauszufinden, wie die neuen Chips von Intel abschneiden, haben wir mit Intel und anderen Unternehmen zusammengearbeitet, um Benchmarks mit Red Hat Enterprise Linux 8.8 / 9.2 und höher durchzuführen.
Die skalierbaren Xeon Prozessoren der 5. Generation von Intel sind Drop-in-kompatibel mit vorhandenen skalierbaren Xeon Motherboards der 4. Generation. Es unterstützt jetzt bis zu 64 Kerne pro Socket (gegenüber zu 60 Kernen) und kann Speichergeschwindigkeiten von DDR5-5600 gegenüber DDR5-4800 der vorherigen Generation, bis zu das 3-fache der LLC und bis zu 20 GB/s UPI 2.0-Geschwindigkeiten verarbeiten. Das Red Hat Performance Engineering Team hat für beide Modelle ein Prototypsystem von Intel konfiguriert, um Performance-Messungen durchzuführen.
SAP-Performance
RHEL 8.8 SAP HANA Leadership auf dem skalierbaren Intel Xeon Prozessor der 5. Generation
Red Hat und Intel blicken auf eine lange gemeinsame Geschichte zurück und haben erneut zusammengearbeitet, um erstklassige Performance in den Rechenzentren von Unternehmen und darüber hinaus zu liefern. Die Teams von Red Hat im Entwicklungs- und Performance Engineering arbeiten seit mehr als einem Jahr an der Hardware-Aktivierung und Validierung dieser neuen skalierbaren Prozessoren und haben im Vorfeld des GA-Releases von Red Hat Enterprise Linux verschiedene Benchmarks durchgeführt.
Höhere Performance pro Kern, größerer Last-Level-Cache, schnellerer Arbeitsspeicher und Storage in Kombination mit workload-optimierten Kernen wirken sich auf die gesamte System-Performance aus. Um die Performance zu demonstrieren und zusätzliche Informationen zur Skalierbarkeit und Umfangsbestimmung für SAP HANA-Anwendungen und -Workloads bereitzustellen, hat SAP die Business Warehouse (BWH) Edition der SAP HANA Standard Application Benchmark [1] eingeführt. Derzeit in Version 3 simuliert dieser Benchmark eine Vielzahl von Nutzern mit unterschiedlichen analytischen Anforderungen und misst den KPI (Key Performance Indicator), der für jede der drei im Folgenden definierten Benchmark-Phasen relevant ist:
- Datenladephase, Testen der Datenlatenz und der Lade-Performance (niedriger ist besser)
- Phase des Abfragedurchsatzes, Testen des Abfragedurchsatzes mit mäßig komplexen Abfragen (je höher, desto besser)
- Laufzeitphase für Abfragen, in der die Leistung der Ausführung sehr komplexer Abfragen getestet wird (niedriger ist besser)
Red Hat Enterprise Linux (RHEL) wurde in mehreren aktuellen Veröffentlichungen der oben genannten Benchmark verwendet. Insbesondere zeigten zwei separate anfängliche Datensatzgrößen (1,3 bzw. 2,6 Milliarden Datensätze) bei Verwendung eines Dell PowerEdge R760 Servers mit skalierbaren Intel Xeon Prozessoren der 5. Generation, dass die Ausführung des Workloads auf Red Hat Enterprise Linux zu einer deutlichen Leistungssteigerung im Vergleich zur vorherigen Intel-Generation führen kann. (siehe Tabelle 1).
Tabelle 1.Ergebnisse in der Kategorie „scale-up“ mit SAP BW Edition for SAP HANA Standard Application Benchmark, Version 3 auf SAP NetWeaver 7.50 und SAP HANA 2.0
Anfänglich Datensätze (Milliarden) | Phase 1 (niedriger ist besser) | Phase 2 (höher ist besser) | Phase 3 (niedriger ist besser) | |
Red Hat Enterprise Linux 8.8 [2] | 2,6 | 7.083 Sekunden | 13.410 | 68 Sekunden |
SUSE Linux Enterprise Server 15 [3] | 2,6 | 10.404 Sekunden | 9.917 | 76 Sekunden |
Vorteil von Red Hat Enterprise Linux und Intel Xeon der 5. Generation | 31,9 % | 35,2 % | 10,5 % |
[1] SAP-Ergebnisse vom 1. März 2023. SAP und SAP HANA sind eingetragene Marken der SAP AG in Deutschland und mehreren anderen Ländern. Weitere Informationen finden Sie unter www.sap.com/benchmark
2] Dell PowerEdge R760 (2 Prozessoren / 128 Kerne / 256 Threads, Intel Xeon
Platinum 8592+ Prozessor, 1,9 GHz, 80 KB L1 Cache und 2048 KB L2 Cache pro Kern, 320 MB L3 Cache pro Prozessor, 1536 GB Hauptspeicher). Zertifizierungsnummer #2023076
[3] Atos PoolSequana SH20 (2 Prozessoren / 120 Kerne / 240 Threads, Intel Xeon
Platinum 8490H Prozessor, 1,9 Prozessor, 80 KB L1 Cache und 2048 KB L2 Cache pro Kern, 112,5 MB L3 Cache pro Prozessor, 1024 GB Hauptspeicher). Zertifizierungsnummer #2023028
Darüber hinaus verbesserte ein Dell EMC PowerEdge R760 Server mit Red Hat Enterprise Linux bei einer Datensatzgröße von 1,3 Milliarden anfänglichen Datensätzen die Punktzahl eines ähnlich konfigurierten Servers bei zwei von drei Benchmark-KPIs und demonstriert somit bessere Ladezeiten für Datensätze und komplexe Abfragelaufzeiten (siehe Tabelle 2).
Tabelle 2. Ergebnisse in der Kategorie „scale-up“ mit SAP BW Edition for SAP HANA Standard Application Benchmark, Version 3 auf SAP NetWeaver 7.50 und SAP HANA 2.0
Anfängliche Datensätze (Milliarden) | Phase 1 (niedriger ist besser) | Phase 2 (höher ist besser) | Phase 3 (niedriger ist besser) | |
Red Hat Enterprise Linux 8.8 [4] | 1,3 | 6.069 Sekunden | 17.846 | 65 Sekunden |
SUSE Linux Enterprise Server 15 [5] | 1,3 | 8.041 Sekunden | 14.288 | 61 Sekunden |
Vorteil von Red Hat Enterprise Linux und Intel Xeon der 5. Generatio | 24,5 % | 24,9 % | -6,6 % |
[4] Dell PowerEdge R760 (2 Prozessoren / 128 Kerne / 256 Threads, Intel
Xeon Platinum 8592+ Prozessor, 1,9 GHz, 80 KB L1 Cache und 2048 KB L2 Cache pro Kern, 320 MB L3 Cache pro Prozessor, 1536 GB Hauptspeicher). Zertifizierungsnummer #2023075
[5] Atos BullSequana SH20 (2 Prozessoren / 120 Kerne / 240 Threads, Intel Xeon
Platinum 8490H Prozessor, 1,9 GHz, 80 KB L1 Cache und 2048 KB L2 Cache pro Kern, 112,5 MB L3 Cache pro Prozessor, 1024 GB Hauptspeicher). Zertifizierungsnummer #2023026
Diese Ergebnisse bestätigen die Bemühungen von Red Hat, OEM-Partner und ISVs bei der Bereitstellung leistungsstarker Lösungen für gemeinsame Kunden zu unterstützen. Sie demonstrieren die enge Verbindung zwischen Red Hat und Dell, die zusammen mit SAP zur Entwicklung von zertifizierten Lösungen für SAP HANA aus einer Hand beigetragen haben. Die Lösung von Dell wurde für Red Hat Enterprise Linux for SAP Solutions optimiert und ist sowohl als Einzelserver- als auch als größere Scale-Out-Konfiguration verfügbar.
TPC-H @ SF =10000
Eine weitere Branchenstandard-Benchmark ist der TPC-H-Benchmark vom Transaction Processing Council (TPC).
Die Ergebnisse zeigen eine starke Leistung der Rechner der HPE ProLiant DL380 Klasse im TPC-H Benchmark @ SF= 10000 mit einer Verbesserung der Leistung von 17,9 % bei Queries/Hour (QphH) und einem Gewinn von 31,4 % beim Preis-Leistungs-Verhältnis (Price/QphH). Die geprüften TPC-H-Ergebnisse wurden von HPE mit Microsoft SQLServer 2022 64 Bit auf einer Intel Xeon SP der 5. Generation mit RHEL 9.3 ermittelt, im Vergleich zu den Ergebnissen von Intel Xeon SP der 4. Generation mit demselben SQLServer 2022 auf Microsoft Windows Server 2022 Standard Edition Systeme.Die Kombination von RHEL 9.3 und Intel Xeon SP-Designs der 5. Generation verdeutlicht den Wert eines Upgrades des Servers und des Betriebssystems auf eine Lösung, die das beste nicht geclusterte TPC-H-Performance-Ergebnis mit 10.000 GB[6]
TPC-H mit HPE DB @ 10 TB SF = 10000 | |||||||
Sponsor | System | Performance (QphH) | Preis/KQphH | Systemverfügbarkeit | Absendedatum | DB-Softwarename | Betriebssystemsoftware |
Vorher Intel Xeon Prozessoren der 4. Generation | 2.028.444 | 821,80 USD | 1.5.2023 | 8.2.2023 | Microsoft SQL Server 2022 Enterprise Edition 64 Bit | Microsoft Windows Server 2022 Standard Edition | |
NEU Intel Xeon Prozessor der 5. Generation | 2.391.511 | 625,77 USD | 30.6.2024 | 25.1.2024 | Microsoft SQL Server 2022 Enterprise Edition 64 Bit | Red Hat Enterprise Linux Server Release 9.3 | |
Verbesserung Gen5/Gen4 | 17,9 % | 31,4 % |
RHEL 9.4 (Beta) KI/ML und Rechenleistung mit Intel® AMX
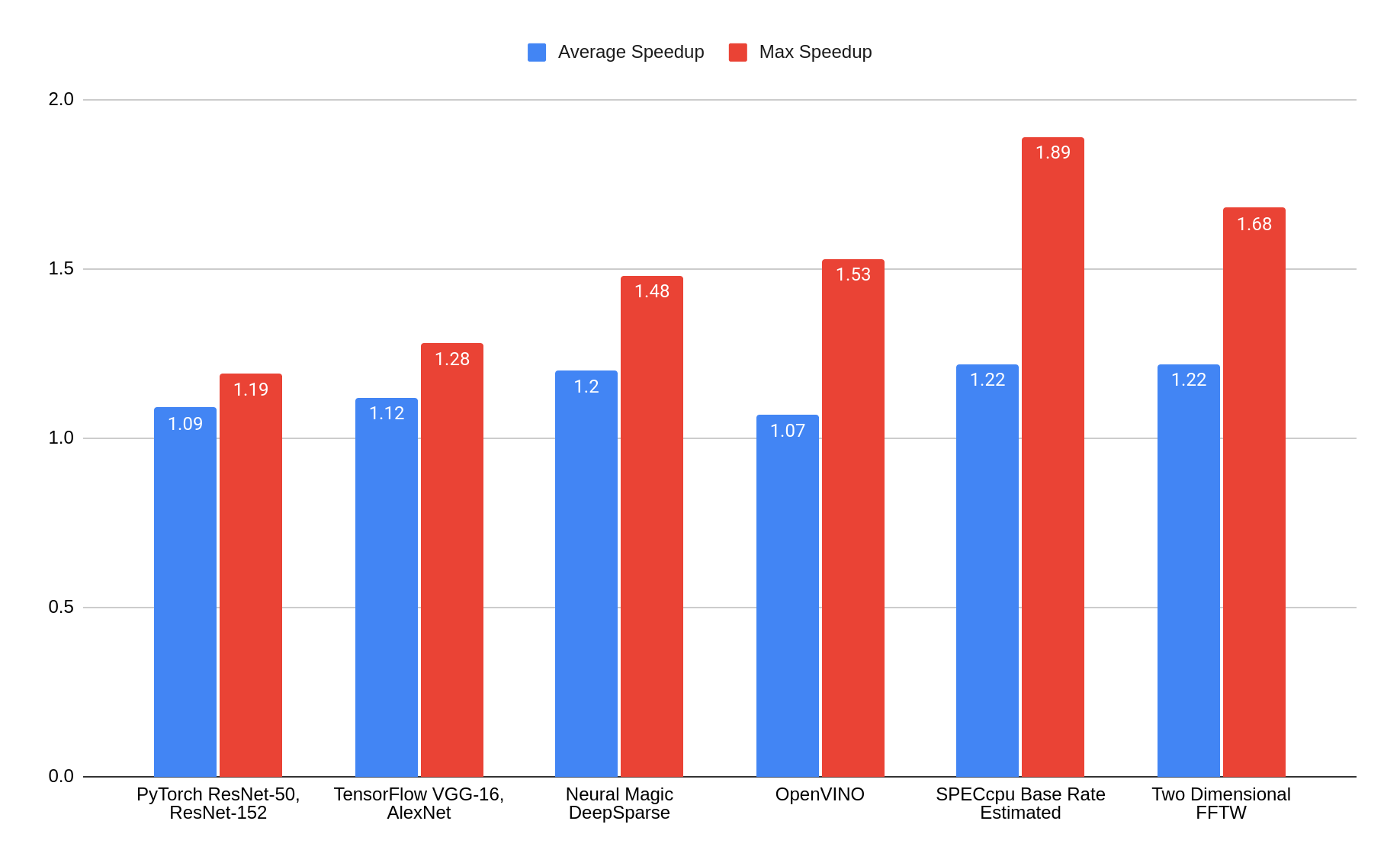
Im Folgenden untersuchen wir die Leistung des Intel Xeon-Prozessors der 5. Generation [7] bei der Ausführung von KI/ML-Funktionen, indem wir die Performance mit dem vorherigen Intel Xeon-Prozessor der 4. Generation [8] anhand einiger der Benchmarks der PTS (Phoronix Test Suite) für PyTorch und TensorFlow vergleichen, sowie die Neural Magic DeepSparse- und Intel® OpenVINO™ Testsuiten. Diese vier Benchmark-Suites umfassen zusammen mehr als 100 Untertests. Informationen zu diesen Ergebnissen finden Sie in [9].
Wir haben auch allgemeine CPU-Computing-Benchmarks wie SPEC CPU Base Rate (geschätzt) und einige zweidimensionale FFTW in unseren Lab-Systemen durchgeführt, um einen direkten Vergleich auf RHEL 9.4-Betasystemen zu ermöglichen.
(Unsere SPEC CPU Base Rate-Ergebnisse sind keine offiziellen Ergebnisse.Wir haben Intel-Binärdateien mit der Konfiguration ic2024.0.2-lin-sapphirapids-rate-20231213.cfg verwendet.)
Die Ergebnisse spiegeln die sofort einsatzbereiten Performance-Gewinne wider. Keiner der Benchmarks enthält spezielle Tunings oder Optimierungen, die über das hinausgehen, was der Compiler automatisch erkennen kann.Unsere Ergebnisse zeigen, dass die durchschnittlichen Beschleunigungsfaktoren für Intel Xeon SP der 5. Generation zwischen 1,07 und 1,22 und die maximalen Beschleunigungsfaktoren zwischen 1,19 und 1,89 im Vergleich zu Intel Xeon SP der 4. Generation liegen.
Zusammenfassung
Das Red Hat Performance Engineering Team arbeitet mit Intel zusammen, um sicherzustellen, dass die Performancefunktionen von Red Hat Enterprise Linux auf Systemen gewährleistet werden, bevor Hardwareanbieter diese in die Produktion liefern.In diesem Blog werden eine Reihe von Funktionen der 5. Generation von Intel vorgestellt, darunter eine höhere Anzahl von CPUs, ein schnellerer DDR5-Speicher, größere 3rd-Level-Caches und eine verbesserte Interprozessor-Bandbreite. Alle diese Features werden in den Versionen von RHEL 8.8 und RHEL 9.2 unterstützt.Wir berichteten, wie OEMs mit diesen Features herausragende Ergebnisse bei SAP [1]-Branchenstandard-Benchmarks und TPC [6] erzielen konnten. Wir haben auch Tests mit RHEL 9.4 Beta durchgeführt, die signifikante Beschleunigungen für CPU-Workloads und KI/ML-Benchmarks beim Vergleich von Intel Xeon SP der 5. Generation mit Intel Xeon SP der 4. Generation zeigten.
Durch die Zusammenarbeit zwischen Intel und Red Hat können wir unsere Fähigkeiten erweitern und werden in zukünftigen Versionen von RHEL weiterhin innovative Funktionen bereitstellen, um für Kunden und Partner weiterhin das bewährte Betriebssystem zu sein.
Mehr erfahren
- Lösungen von Red Hat und Dell Technologies
- Red Hat Enterprise Linux for SAP Solutions
[6] TPC und TPC-H sind Marken des Transaction Processing Performance Council. Alle Drittanbietermarken sind Eigentum ihrer jeweiligen Inhaber: siehe:https://www.tpc.org/tpch/results. Stand aller Vergleiche und Angaben vom 15. März 2024. Gefiltert nach Ergebnissen von 10.000 GB: https://www.tpc.org/tpch/results/tpch_perf_results5.asp?resulttype=noncluster&version=3
[7] Intel Xeon SP der 5. Generation: Hardwarekonfiguration
Processor: 2 x Intel Xeon Platinum 8592+ @ 3.90GHz (128 Cores / 256 Threads)
Motherboard: Intel D50DNP1SBB (SE5C7411.86B.9533.D01.2310110651 BIOS)
Memory: 1008 GB @ 5800 MT/s
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Address sizes: 52 bits physical, 57 bits virtual
Byte Order: Little Endian
CPU(s): 256
On-line CPU(s) list: 0-255
Vendor ID: GenuineIntel
BIOS Vendor ID: Intel(R) Corporation
Model name: INTEL(R) XEON(R) PLATINUM 8592+
BIOS Model name: INTEL(R) XEON(R) PLATINUM 8592+
CPU family: 6
Model: 207
Thread(s) per core: 2
Core(s) per socket: 64
Socket(s): 2
Stepping: 2
CPU(s) scaling MHz: 100%
CPU max MHz: 3900.0000
CPU min MHz: 800.0000
BogoMIPS: 3800.00
Flags:
fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush dts acpi mmx fxsr sse sse2 ss ht
tm pbe syscall nx pdpe1gb rdtscp lm constant_tsc art arch_perfmon pebs bts rep_good nopl xtopology nonstop_tsc
cpuid aperfmperf tsc_known_freq pni pclmulqdq dtes64 monitor ds_cpl vmx smx est tm2 ssse3 sdbg fma cx16 xtpr pdcm
pcid dca sse4_1 sse4_2 x2apic movbe popcnt tsc_deadline_timer aes xsave avx f16c rdrand lahf_lm abm 3dnowprefetch
cpuid_fault epb cat_l3 cat_l2 cdp_l3 cdp_l2 ssbd mba ibrs ibpb stibp ibrs_enhanced tpr_shadow flexpriority ept vpid
ept_ad fsgsbase tsc_adjust bmi1 avx2 smep bmi2 erms invpcid cqm rdt_a avx512f avx512dq rdseed adx smap avx512ifma
clflushopt clwb intel_pt avx512cd sha_ni avx512bw avx512vl xsaveopt xsavec xgetbv1 xsaves cqm_llc cqm_occup_llc
cqm_mbm_total cqm_mbm_local split_lock_detect avx_vnni avx512_bf16 wbnoinvd dtherm ida arat pln pts hwp hwp_act_window
hwp_epp hwp_pkg_req vnmi avx512vbmi umip pku ospke waitpkg avx512_vbmi2 gfni vaes vpclmulqdq avx512_vnni avx512_bitalg
tme avx512_vpopcntdq la57 rdpid bus_lock_detect cldemote movdiri movdir64b enqcmd fsrm md_clear serialize tsxldtrk
pconfig arch_lbr ibt amx_bf16 avx512_fp16 amx_tile amx_int8 flush_l1d arch_capabilities
Virtualization features:
Virtualization: VT-x
Caches (sum of all):
L1d: 6 MiB (128 instances)
L1i: 4 MiB (128 instances)
L2: 256 MiB (128 instances)
L3: 640 MiB (2 instances)
NUMA:
NUMA node(s): 4
NUMA node0 CPU(s): 0-31,128-159
NUMA node1 CPU(s): 32-63,160-191
NUMA node2 CPU(s): 64-95,192-223
NUMA node3 CPU(s): 96-127,224-255
Vulnerabilities:
Gather data sampling: Not affected
Itlb multihit: Not affected
L1tf: Not affected
Mds: Not affected
Meltdown: Not affected
Mmio stale data: Not affected
Retbleed: Not affected
Spec rstack overflow: Not affected
Spec store bypass: Mitigation; Speculative Store Bypass disabled via prctl
Spectre v1: Mitigation; usercopy/swapgs barriers and __user pointer sanitization
Spectre v2: Mitigation; Enhanced / Automatic IBRS, IBPB conditional, RSB filling, PBRSB-eIBRS SW sequence
Srbds: Not affected
Tsx async abort: Not affected[8] Intel Xeon SP der 4. Generation: Hardwarekonfiguration
Processor: 2 x Intel Xeon Platinum 8480+ @ 3.80GHz (112 Cores / 224 Threads)
Motherboard: Dell 0VRV9X (1.3.2 BIOS)
Memory: 2016 GB @ 4800 MT/s
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Address sizes: 46 bits physical, 57 bits virtual
Byte Order: Little Endian
CPU(s): 224
On-line CPU(s) list: 0-223
Vendor ID: GenuineIntel
BIOS Vendor ID: Intel
Model name: Intel(R) Xeon(R) Platinum 8480+
BIOS Model name: Intel(R) Xeon(R) Platinum 8480+
CPU family: 6
Model: 143
Thread(s) per core: 2
Core(s) per socket: 56
Socket(s): 2
Stepping: 8
CPU(s) scaling MHz: 98%
CPU max MHz: 3800.0000
CPU min MHz: 800.0000
BogoMIPS: 4000.00
Flags:
fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush dts acpi mmx fxsr sse sse2 ss ht
tm pbe syscall nx pdpe1gb rdtscp lm constant_tsc art arch_perfmon pebs bts rep_good nopl xtopology nonstop_tsc
cpuid aperfmperf tsc_known_freq pni pclmulqdq dtes64 monitor ds_cpl vmx smx est tm2 ssse3 sdbg fma cx16 xtpr pdcm
pcid dca sse4_1 sse4_2 x2apic movbe popcnt tsc_deadline_timer aes xsave avx f16c rdrand lahf_lm abm 3dnowprefetch
cpuid_fault epb cat_l3 cat_l2 cdp_l3 cdp_l2 ssbd mba ibrs ibpb stibp ibrs_enhanced tpr_shadow flexpriority ept vpid
ept_ad fsgsbase tsc_adjust bmi1 avx2 smep bmi2 erms invpcid cqm rdt_a avx512f avx512dq rdseed adx smap avx512ifma
clflushopt clwb intel_pt avx512cd sha_ni avx512bw avx512vl xsaveopt xsavec xgetbv1 xsaves cqm_llc cqm_occup_llc
cqm_mbm_total cqm_mbm_local split_lock_detect avx_vnni avx512_bf16 wbnoinvd dtherm ida arat pln pts hwp hwp_act_window
hwp_epp hwp_pkg_req vnmi avx512vbmi umip pku ospke waitpkg avx512_vbmi2 gfni vaes vpclmulqdq avx512_vnni avx512_bitalg
tme avx512_vpopcntdq la57 rdpid bus_lock_detect cldemote movdiri movdir64b enqcmd fsrm md_clear serialize tsxldtrk
pconfig arch_lbr ibt amx_bf16 avx512_fp16 amx_tile amx_int8 flush_l1d arch_capabilities
Virtualization features:
Virtualization: VT-x
Caches (sum of all):
L1d: 5.3 MiB (112 instances)
L1i: 3.5 MiB (112 instances)
L2: 224 MiB (112 instances)
L3: 210 MiB (2 instances)
NUMA:
NUMA node(s): 2
NUMA node0 CPU(s): 0,2,4,6,8, . . .
NUMA node1 CPU(s): 1,3,5,7,9, . . .
Vulnerabilities:
Gather data sampling: Not affected
Itlb multihit: Not affected
L1tf: Not affected
Mds: Not affected
Meltdown: Not affected
Mmio stale data: Not affected
Retbleed: Not affected
Spec rstack overflow: Not affected
Spec store bypass: Mitigation; Speculative Store Bypass disabled via prctl
Spectre v1: Mitigation; usercopy/swapgs barriers and __user pointer sanitization
Spectre v2: Mitigation; Enhanced / Automatic IBRS, IBPB conditional, RSB filling, PBRSB-eIBRS SW sequence
Srbds: Not affected
Tsx async abort: Not affected[9] Verwenden von Phoronix-Test-Suites in Containern
Das PTS-Framework ist eine äußerst praktische Möglichkeit, Leistungstests durchzuführen, und es verfügt über ein großes IT-Ökosystem mit vielen erfassten Ergebnissen, die zum Vergleich zur Verfügung stehen. Offizielle Informationen, einschließlich offizieller Anweisungen zum Ausführen von PTS-Tests, finden Sie unter Phoronix Test Suite und OpenBenchmarking.org.
Wir haben die KI/ML-bezogenen Tests in Centos Stream 9-Containern (auf RHEL 9.4 Beta-Hosts) durchgeführt, um versehentliche Änderungen an der Host-Systemumgebung zu vermeiden und für wiederholte Tests eine Neuzustandsliste zu erzwingen.
Schritte zur Replikation der KI/ML-bezogenen Testergebnisse auf Ihrem System:
podman run -it --rm --net=host --privileged centos:stream9 /bin/bashsed -i "/\[crb\]/,+9s/enabled=0/enabled=1/" /etc/yum.repos.d/centos.repodnf -y install https://dl.fedoraproject.org/pub/epel/epel-release-latest-9.noarch.rpmdnf -y install atlas-devel autoconf automake binutils blas blas-devel boost-devel boost-thread bzip2 cmake expat-devel findutils gcc gcc-c++ gcc-gfortran gflags-devel git glog-devel gmock-devel gzip hdf5-devel iputils leveldb-devel libquadmath-devel libusb-devel libusbx-devel lmdb-devel make meson nfs-utils ninja-build openblas-devel opencv opencv-devel openssl-devel patch pciutils php-cli php-json php-xml procps-ng protobuf-compiler protobuf-devel python3 python3-devel python3-pip python3-yaml snappy-devel tar unzip vim-enhanced wget xz zipAt this point you might mount a shared volume with phoronix-test-suite already installed, or you can just download and unpack it in the container with steps like these:wget https://phoronix-test-suite.com/releases/phoronix-test-suite-10.8.4.tar.gztar xvzf phoronix-test-suite-10.8.4.tar.gzcd phoronix-test-suite
./phoronix-test-suite install deepsparse openvino pytorch tensorflow./phoronix-test-suite benchmark deepsparse openvino pytorch tensorflow
Über die Autoren
Michey is a member of the Red Hat Performance Engineering team, and works on bare metal/virtualization performance and machine learning performance.. His areas of expertise include storage performance, Linux kernel performance, and performance tooling.
Ähnliche Einträge
KI-Bedrohungen abwehren: Agile Security für Unternehmen
Der KI-Wendepunkt: Warum Souveränität nicht optional ist
Untangling Networks | Compiler
Technically Speaking | Defining sovereign AI with open source
Nach Thema durchsuchen

Automatisierung
Das Neueste zum Thema IT-Automatisierung für Technologien, Teams und Umgebungen

Künstliche Intelligenz
Erfahren Sie das Neueste von den Plattformen, die es Kunden ermöglichen, KI-Workloads beliebig auszuführen

Open Hybrid Cloud
Erfahren Sie, wie wir eine flexiblere Zukunft mit Hybrid Clouds schaffen.

Sicherheit
Erfahren Sie, wie wir Risiken in verschiedenen Umgebungen und Technologien reduzieren

Edge Computing
Erfahren Sie das Neueste von den Plattformen, die die Operations am Edge vereinfachen

Infrastruktur
Erfahren Sie das Neueste von der weltweit führenden Linux-Plattform für Unternehmen

Anwendungen
Entdecken Sie unsere Lösungen für komplexe Herausforderungen bei Anwendungen
Virtualisierung
Erfahren Sie das Neueste über die Virtualisierung von Workloads in Cloud- oder On-Premise-Umgebungen