


In our first blog post, we highlighted the peer-pods solution and its ability to bring the benefits of Red Hat OpenShift sandboxed containers to any environment including the cloud and third-party hypervisors. In this post, we will delve deeper into the various components that make up the peer-pods solution, including the controller, networking model, resource model, etc. We will also cover the communication between the different components and how everything comes together.
Overall, the peer-pods solution provides a powerful way to bring the benefits of OpenShift sandboxed containers to any public cloud environment and is a key enabler for future capabilities such as confidential containers.
Peer-pods overall architecture
The peer-pods project enhances the Kata Containers project so we need to start by explaining what this project is about.
A crash course on Kata Containers
Kata Containers is an open source project working to build a more secure container runtime with lightweight virtual machines (VMs) that are exposed as pods and can run regular container workloads. This approach aims to provide stronger workload isolation using hardware virtualization technology.
OpenShift sandboxed containers, based on Kata Containers, provide an Open Container Initiative (OCI)-compliant container runtime using lightweight VMs running your workloads in their own isolated kernel. This contributes an additional layer of isolation to Red Hat’s defense-in-depth strategy.
The peer-pods project enhances the Kata Containers project and is also a critical building block for Red Hat’s OpenShift sandboxed containers solution for targeting non bare-metal deployments such as public cloud providers and third-party hypervisors.
The following diagram shows the major components involved in a Kata solution:

For a technical deep dive into Kata please refer to the Kata Containers Architecture document.
Let’s go over the main components used in the Kata Containers (and OpenShift sandboxed containers) solution.
- cri-o/containerd: cri-o implements the Kubelet Container Runtime Interface and provides an integration path between OCI runtimes and the Kubelet. CRI-O is the default in OpenShift.
- containerd-shim-kata-v2: This is the Kata containers runtime which creates a VM for each Kubernetes pod, and dispatches containers to this virtual machine. The containers are therefore “sandboxed” inside the VM. For historical reasons the name of the Kata containers runtime binary is coupled with containerd, however the same binary works for both containerd and cri-o. The communication between cri-o/containerd and the Kata containers runtime is based on ttrpc.
- Qemu/KVM: The Kata Containers supports a variety of hypervisors. In the case of OpenShift sandboxed containers, we use Qemu, a highly-trusted, versatile and high-performance hypervisor.
- Kata agent: The kata-agent is a process running inside the guest as a supervisor for managing containers and processes running within those containers. The kata-agent execution unit is the sandbox. A kata-agent sandbox is a container sandbox defined by a set of namespaces (NS, UTS, IPC and PID). kata-runtime can run several containers per VM to support container workloads that require multiple containers running inside the same pod. The kata-agent communicates Kata Containers runtime (containerd-shim-kata-v2) using ttrpc over vsock.
Extending Kata Containers with peer-pods
As pointed out, the peer-pods solution enhances a number of components in the Kata architecture to provide the ability to create VMs running on a different host machine or cloud environment.
The following diagram shows the major components involved in the peer-pods solution (extending the Kata architecture):

Let’s go over the different components mentioned in this diagram (on top of the ones previously mentioned in the Kata architecture section):
- Remote hypervisor support: Enhancing the shim layer to interact with the the cloud-api-adapter instead of directly calling a hypervisor as previously done.
- cloud-api-adaptor: Enables the use of the OpenShift sandboxed containers in a cloud environment and on third-party hypervisors by invoking the relevant APIs.
- agent-protocol-forwarder: Enables kata-agent to communicate with the worker node over TCP.
The following diagram zooms into the cloud-api-adaptor showing the different platforms supported:

As shown, the cloud-api-adapter is capable of supporting multiple platforms while maintaining the same end-to-end flow.
Communication between the Kata containers runtime (shim) and Kata agent
Let’s zoom into how the shim and kata-agent communicate.
Kata pod communication with a local hypervisor (eg. Qemu/KVM)
Starting with classical Kata containers solution we have the following:
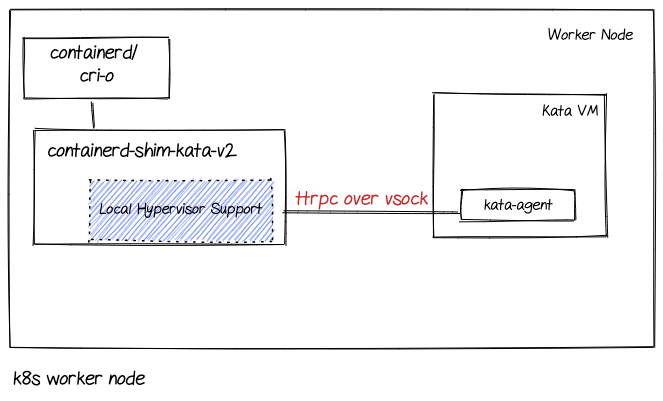
The Kata containers runtime (containerd-shim-kata-v2) communicates with the kata-agent running on the Kata VM using ttrpc over vsock interface. The Kata VM runs on the worker node running the Kata containers runtime. This is the reason we depict the component inside containerd-shim-kata-v2 as local hypervisor support.
The vsock address family however will facilitate communication between virtual machines and the host they are running on, meaning that this can’t work for VMs running on separate host machines (a cloud environment as one example).
Kata pod communication with a remote hypervisor
The remote hypervisor uses TCP instead of vsock to handle communication across different machines:

The Kata shim (containerd-shim-kata-v2) communicates with the kata-agent running on the Kata VM via cloud-api-adaptor using ttrpc over a TCP connection.
The Kata shim communicates with cloud-api-adaptor using ttrpc over Unix socket. The cloud-api-adaptor communicates with the agent-protocol-forwarder running on the Kata VM over TCP. The agent-protocol-forwarder communicates with the kata-agent using ttrpc over a Unix socket.
Peer-pods networking model
Let’s talk about the way networking is done in Kata today and how it changes with peer-pods.
Kata Containers pod networking with a local hypervisor
The Kubernetes network plugin places the device, eth0, in the container's network namespace. This is one end of the veth device. The other end is in the host's network namespace (init namespace). Kata Containers create a tap device for the virtual machine, tap0_kata, sets up a Traffic Control (TC) redirection filter to mirror traffic from eth0's ingress to tap0_kata's egress, and a second to mirror traffic from tap0_kata's ingress to eth0's egress.
These components are shown in the following diagram:

Kata Containers pod networking with a remote hypervisor
With remote hypervisor, a VXLAN tunnel connects the worker node to the external virtual machine as shown in the diagram below:

The Kubernetes network plugin flows to create eth0 and the veth device is the same as with the local hypervisor implementation. However Kata Containers remote hypervisor implementation (cloud-api-adaptor) creates a VXLAN device for the virtual machine (instead of a tap device), vxlan1, sets up a traffic control (TC) redirection filter to mirror traffic from eth0's ingress to vxlan1's egress, and a second one to mirror traffic from vxlan1's ingress to eth0's egress. The other end of the VXLAN tunnel inside the virtual machine is set up by agent-protocol-forwarder.
This solution is described in the following sections for Openshift SDN and OVN-Kubernetes CNIs.
Using OpenShift SDN
The following diagram shows the network topology with OpenShift SDN.

A few points regarding the flow:
- OpenShift SDN creates a veth pair and assigns IP addresses to the pod interface in the pod namespace. This is shown as the 3:eth0@if1081 interface in the diagram above. cloud-api-adaptor creates the VXLAN interface (shown as 4: vxlan1@if4) using the pod virtual machine’s address as the remote VXLAN endpoint.
- cloud-api-adaptor also sets up a TC redirection filter between eth0 and vxlan1 in the pod network namespace.
- In the pod virtual machine, agent-protocol-forwarder creates the VXLAN interface (shown as 3:vxlan0@if3) and assigns it the pod IP address. Note that the same pod IP address (10.132.2.73/23) and MAC address is assigned to eth0 on the worker node and to vxlan0 on the pod virtual machine. The remote endpoint for the VXLAN tunnel is set to the worker node IP address.
- agent-protocol-forwarder creates the vxlan0 endpoint in the init namespace and then moves it to the pod namespace (podns).This allows switching the network namespace when the packet is encapsulated or decapsulated.
Using OVN Kubernetes
This network topology diagram outlines the operation with OVN (Open Virtual Network) Kubernetes.
 Kubernetes.")
A few points regarding the flow:
- From the point of view of peer-pods, the OVN-Kubernetes flow is similar to the OpenShift SDN one
- The main differences reside in flow rules and bridge ports belonging to Open vSwitch. For further details about OpenShift SDN and OVN-Kubernetes please refer to their respective documentations
Peer-pod controller and custom resource
The peer-pod-controller is a Kubernetes controller that manages the lifecycle of peer-pods configuration in a Kubernetes cluster. It does this by watching for changes to the PeerPodConfig CustomResourceDefinition (CRD), which is used to define the configuration for a peer-pods deployment. When a change to a PeerPodConfig is detected, the controller will create, update or delete the corresponding peer-pods deployment to ensure that it is in the desired state. This allows users to dynamically manage the peer-pods configuration in their deployment.
When a KataConfig CR (Custom Resource) has the field “enablePeerPods” set to “true”, the KataConfig controller will create a PeerPodConfig CR. This creation will trigger the peer-pods controller to run its reconcile loop. For a newly created PeerPodConfig CR it will:
- Set the extended resources in the “Resources” and “Limit” fields on the nodes
- Create a daemonset that runs the cloud-api-adaptor software on the same nodes
- Create the peer-pods webhook
apiVersion: kataconfiguration.openshift.io/v1 kind: KataConfig metadata: name: example-kataconfig spec: enablePeerPods: true
The following diagram describes the flow being triggered by a users request:

Peer-pods resource management
A peer-pod uses resources in two locations:
- Kubernetes worker node: This is for metadata, Kata shim resources, remote-hypervisor (cloud-api-adaptor) resources, tunnel setup between worker node and the peer-pod VM, etc.
- Cloud instance: The actual peer-pod VM running in the cloud (e.g. AWS/Azure/IBMcloud/VMware instances).
Since the resources used by peer-pods are external to the Kubernetes cluster and consumed from the cloud provider, there are two main issues that can arise:
- Peer-pods scheduling can fail due to unavailability of required resources on the worker node, even though the peer-pods will not consume those resources
- Cluster administrators have no way to manage the capacity and resource consumption of the peer-pods cloud instances
To address these problems, the capacity of peer-pods is advertised as Kubernetes Node extended resources to let the Kubernetes scheduler handle capacity tracking and accounting. The extended resource is named "kata.peerpods.io/vm" and defines the maximum number of peer-pods that can be created in the cluster.
Additionally, the overhead of a peer-pod in terms of the actual CPU and memory resource requirements on the worker node is specified as pod overhead and is included in the RuntimeClass definition that is used for creating peer-pods.
We use a mutating webhook to remove any resource-specific entries from the pod specification and add the peer-pods extended resources. This allows the Kubernetes scheduler to take these extended resources into account when scheduling the peer-pod, and helps to ensure that the peer-pod is only scheduled when resources are available.
In the following picture we can see the actions taken when a user creates a peer-pod:

The mutating webhook modifies a Kubernetes pod object in the following way:
- It checks if the pod has the expected RuntimeClassName value, which is specified in the TARGET_RUNTIME_CLASS environment variable. If the RuntimeClassName value in the pod's specification does not match the value in TARGET_RUNTIME_CLASS, the webhook exits and the pod is not modified.
- If the RuntimeClassName values match, the webhook makes the following changes to the pod spec:
- The webhook removes all resource specifications (if present) from the resources field of all containers and init containers in the pod.
- The webhook adds the extended resource ("kata.peerpods.io/vm") to the spec by modifying the resources field of the first container in the pod. The extended resource "kata.peerpods.io/vm" is used by the Kubernetes scheduler for accounting purposes.
- The webhook adds an annotation to the pod that specifies the instance type that is used when the VM is created in the cloud environment.
Please note that the mutating webhook excludes specific system namespaces in OpenShift from mutation. If a peer-pod is created in those system namespaces, then resource accounting using Kubernetes extended resources will not work unless the pod spec includes the extended resource. As a best practice, a cluster-wide policy should be in place to allow peer-pods creation only in specific namespaces.
Summary
In this blog post, we reviewed the technical implementation of a few of the key components in the peer-pods solution.
We looked at the overall architecture and how it was built on top of the Kata Containers architecture. We looked at the cloud-api-adapter implementation, how the different components communicate with each other and how the peer-pods networking is implemented (using tunnels) both for OpenShift SDN and OVN-Kubernetes CNIs.
We talked about the peer-pods controller and the CRDs working together to enable managing peer-pods on a cloud environment. To address the issue of resource management, the peer-pods solution allows for the advertisement of peer-pods capacity as Kubernetes extended resources and the use of pod overhead to account for actual resource requirements on the worker node. Overall, the peer-pods solution offers a powerful way to bring the benefits of OpenShift sandboxed containers to public cloud and third-party hypervisor environments.
There are a number of additional topics the community is currently working on, such as supporting persistent storage, dealing with orphaned cloud resources in the case of failures, logging capabilities, debugging capabilities and more.
The next blog post will provide hands-on instructions for deploying and running the peer-pods solution for AWS and VMware deployments.
Über die Autoren
Pradipta is working in the area of confidential containers to enhance the privacy and security of container workloads running in the public cloud. He is one of the project maintainers of the CNCF confidential containers project.
Jens Freimann is a Software Engineering Manager at Red Hat with a focus on OpenShift sandboxed containers and Confidential Containers. He has been with Red Hat for more than six years, during which he has made contributions to low-level virtualization features in QEMU, KVM and virtio(-net). Freimann is passionate about Confidential Computing and has a keen interest in helping organizations implement the technology. Freimann has over 15 years of experience in the tech industry and has held various technical roles throughout his career.
Ähnliche Einträge
Gehärtet, einsatzbereit und kostenlos: Die Container-Sicherheit entwickelt sich weiter
MCP-Sicherheit: Containerisierung und Integration von Red Hat OpenShift
Collaboration In Product Security | Compiler
Keeping Track Of Vulnerabilities With CVEs | Compiler
Nach Thema durchsuchen

Automatisierung
Das Neueste zum Thema IT-Automatisierung für Technologien, Teams und Umgebungen

Künstliche Intelligenz
Erfahren Sie das Neueste von den Plattformen, die es Kunden ermöglichen, KI-Workloads beliebig auszuführen

Open Hybrid Cloud
Erfahren Sie, wie wir eine flexiblere Zukunft mit Hybrid Clouds schaffen.

Sicherheit
Erfahren Sie, wie wir Risiken in verschiedenen Umgebungen und Technologien reduzieren

Edge Computing
Erfahren Sie das Neueste von den Plattformen, die die Operations am Edge vereinfachen

Infrastruktur
Erfahren Sie das Neueste von der weltweit führenden Linux-Plattform für Unternehmen

Anwendungen
Entdecken Sie unsere Lösungen für komplexe Herausforderungen bei Anwendungen
Virtualisierung
Erfahren Sie das Neueste über die Virtualisierung von Workloads in Cloud- oder On-Premise-Umgebungen