
In today’s Storage Tutorial, Brian chats with Red Hat’s Paul Cuzner of the storage business unit. Paul has been focused on finding new ideas and strategies where Red Hat Storage can make a difference for customers and, most recently, has spent time working with Splunk. Watch the video below to find out just how Paul and Red Hat work with customers to make the most of Splunk and their storage, but we’ve broken down one salient bit for you right here…keep reading!
Understanding Splunk data flows
Data arriving within a Splunk indexer, as it’s being parsed, is placed into a structure named a bucket – a directory in a file structure. This bucket is considered “hot” because its index is being actively built, or files are constantly being added or removed from it. When it reaches a certain size, or age, it moves to “warm” storage, meaning the index is built and closed, so no further information is added and it becomes a point of record.
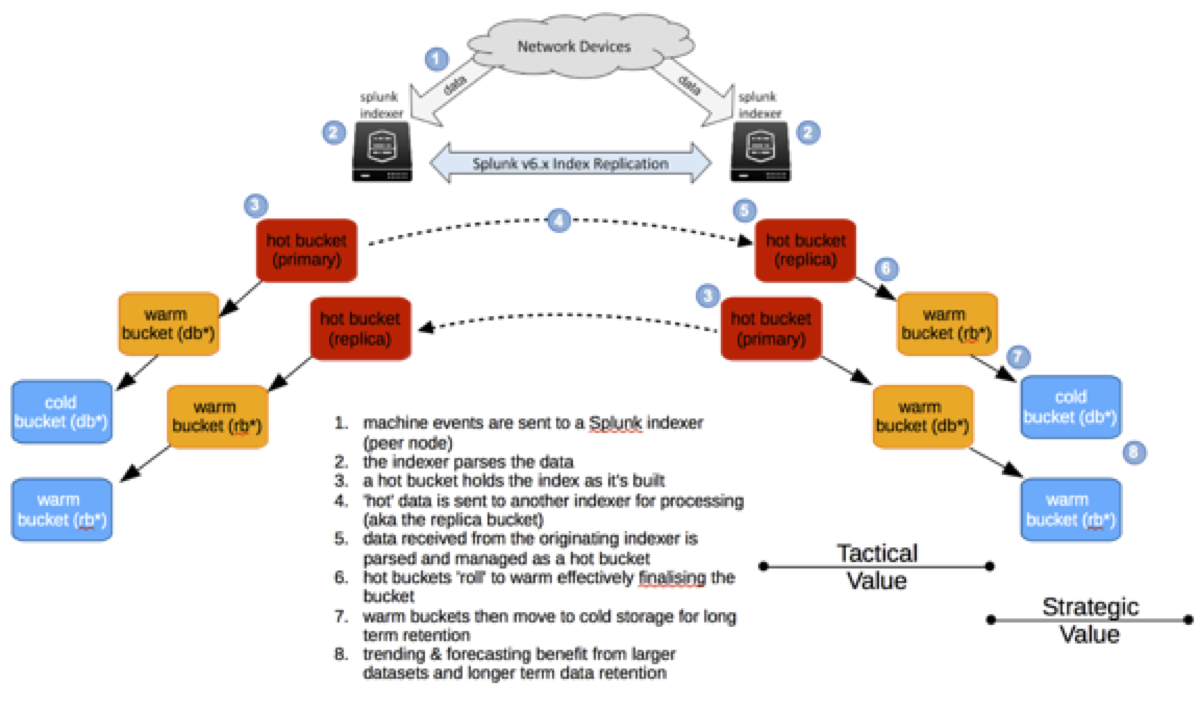 The Splunk data migration flow, illustrated!
The Splunk data migration flow, illustrated!
Hot and warm buckets, because they are considered to be in use or readily available, are typically placed on very fast storage – 10,000 or 15,000 RPM hard disks or flash storage, for example.
Eventually warm buckets are rolled into “cold” buckets. These are also not written to and are available for search. This storage, because it isn’t accessed quite as often, is typically placed on slower storage with very high capacity…and this is where customers struggle to choose a platform.
Be sure to check out the video, next:
Über den Autor
Ähnliche Einträge
KI-Bedrohungen abwehren: Agile Security für Unternehmen
Agentische KI: Open Source-Ansatz für Ihr Unternehmen
Container Roundup | Compiler
Untangling Networks | Compiler
Nach Thema durchsuchen

Automatisierung
Das Neueste zum Thema IT-Automatisierung für Technologien, Teams und Umgebungen

Künstliche Intelligenz
Erfahren Sie das Neueste von den Plattformen, die es Kunden ermöglichen, KI-Workloads beliebig auszuführen

Open Hybrid Cloud
Erfahren Sie, wie wir eine flexiblere Zukunft mit Hybrid Clouds schaffen.

Sicherheit
Erfahren Sie, wie wir Risiken in verschiedenen Umgebungen und Technologien reduzieren

Edge Computing
Erfahren Sie das Neueste von den Plattformen, die die Operations am Edge vereinfachen

Infrastruktur
Erfahren Sie das Neueste von der weltweit führenden Linux-Plattform für Unternehmen

Anwendungen
Entdecken Sie unsere Lösungen für komplexe Herausforderungen bei Anwendungen
Virtualisierung
Erfahren Sie das Neueste über die Virtualisierung von Workloads in Cloud- oder On-Premise-Umgebungen