
Fühlt sich Ihre Private Cloud wie ein Buffet an, an dem sich unkontrolliert bedient werden kann? Sie wissen, dass sie einen Mehrwert bietet. Wenn jedoch die Rechnung fällig wird, lässt sich kaum nachvollziehen, wer was verbraucht.
In den heutigen dynamischen Cloud-Umgebungen wird es immer wichtiger, Kosten den internen Nutzenden korrekt zuzuordnen – insbesondere für Unternehmen, die ihre eigene Cloud-Infrastruktur betreiben. Sie müssen Verantwortlichkeit schaffen, um Kosten gerecht auf Abteilungen zu verteilen oder Teams dazu zu bewegen, ihre Workloads optimal zu dimensionieren. Mehr Transparenz zu schaffen, ist dabei der erste Schritt.
Mit Feature Release 5 (FR5) von Red Hat OpenStack Services on OpenShift 18 liefern wir eine entscheidende Komponente zur Lösung dieses Problems: die Möglichkeit, die Bewertung auf Basis der gemessenen Nutzung Ihrer Mandanten durchzuführen.
Wir führen CloudKitty, den OpenStack-nativen Bewertungsservice, mit FR5 als allgemein verfügbar ein. Dieser Service schließt die Lücke zwischen Ihren technischen Rohdaten und Ihren Finanzprozessen.
Warum ist CloudKitty wichtig?
CloudKitty bietet eine Übersetzungsebene, die Daten zur Servernutzung in nützliche Informationen für die Budgetplanung der Abteilungen umwandelt. Betrachten Sie CloudKitty als Zähler: Die Lösung agiert zwischen Ihren erfassten Metriken und Ihrer FinOps- oder Abrechnungslösung. Die Lösung erfasst technische Rohdaten – beispielsweise die Laufzeit einer virtuellen Maschine (VM) oder die Menge des genutzten Speicherplatzes – und wendet Ihre spezifischen Tarifregeln an, um einen Bericht zu erstellen. Dies hilft Ihnen dabei, 2 Hauptziele zu erreichen:
- Transparente Kostendeckung: Sie erhalten nun eine detaillierte, aufgeschlüsselte Übersicht der Ressourcennutzung pro Mandant. So decken Sie Ihre Betriebsausgaben präzise ab, ohne interne Kunden mit undurchsichtigen Gebühren zu überraschen.
- Vertrauen und Optimierung: Sobald Mandanten sehen, wie sich ihr eigener Verbrauch (aufgeschlüsselt nach Projekt, Flavor und Metrik) auf die Kosten auswirkt, können sie fundierte Entscheidungen treffen. Dazu gehören etwa das Archivieren veralteter Daten oder das Optimieren der VM-Nutzung.
Bitte beachten Sie, dass CloudKitty ausschließlich als Engine für Transparenz und Bewertung fungiert. Sie setzt Budgets nicht aktiv durch und blockiert auch nicht die Erstellung von Ressourcen (wie Nova-Instanzen), wenn ein Mandant eine bestimmte Kostenschwelle überschreitet.
Wie funktioniert CloudKitty?
Obwohl CloudKitty keine vollständige Abrechnungslösung ist, bietet die Anwendung das entscheidende Bindeglied zwischen Nutzung und Kosten. Vereinfacht ausgedrückt sieht der Workflow wie folgt aus:
Tarifregeln festlegen → Metriken sammeln → Bewertungsberichte generieren
Regeln definieren
Wir stellen einen Beispielmandanten aus unserer fiktiven Liste vor: das Datenschutzministerium. In der Vergangenheit hat das Ministerium für seine Analyse-Workloads sehr große VMs gestartet und diese auch lange nach Abschluss der Berechnungen weiterlauflassen.
Um eine transparente Kostendeckung zu erreichen, müssen wir deren Compute-Footprint nachverfolgen. Dazu erfassen wir die Metrik ceilometer_cpu. Diese spezifische Metrik ermöglicht es uns, eine Flavor-basierte Verfügbarkeit bereitzustellen. Das bedeutet, dass CloudKitty für jeden Zeitraum, in dem eine VM-Instanz ausgeführt wird, einen anderen Tarif basierend auf ihrer Größe berechnen kann.
Schritt 1: Erstellen Sie den Service
Zuerst müssen wir einen Top-Level-Container für unsere Metrik erstellen. Der Servicename muss exakt dem Metriknamen oder dem alt_name entsprechen, der in metrics.yaml definiert ist. (Wir gehen später noch genauer auf diese Datei ein.)
openstack rating hashmap service create ceilometer_cpu
+----------+--------------------------------------+
| Name | Service ID |
+----------+--------------------------------------+
| ceilometer_cpu | <uuid> |
+----------+--------------------------------------+Speichern Sie diese Service-ID (UUID) – Sie benötigen sie für die nächsten Befehle.
Indem wir einen Service namens ceilometer_cpu erstellen, stellen wir sicher, dass die CPU-Datenpunkte, die vom Collector stammen, direkt an diese neue Tarifregel weitergeleitet werden.
Schritt 2: Gruppe erstellen (optional)
Wir möchten verhindern, dass sich die Compute-Kosten des Ministeriums mit den Rechnungen für Storage oder Netzwerke vermischen. Gruppen helfen uns dabei, zusammengehörige Mappings zu organisieren und Berechnungen voneinander zu isolieren.
openstack rating hashmap group create cpu_ratingIndem wir diese Zuordnungen gruppieren, trennen wir unterschiedliche Abrechnungsszenarien. Wenn mehrere Zuordnungen in derselben Gruppe übereinstimmen, wendet CloudKitty nur die kostspieligste an.
Schritt 3: Zuordnung erstellen
Mappings are the Kostenregeln. Zuerst schaffen wir eine Ausgangsbasis für das Datenministerium, indem wir feste Kosten pro Element berechnen. Indem Sie <service_id> und <group_id> durch die in den vorherigen Schritten erhaltenen UUIDs ersetzen, können Sie diese neue Regel direkt mit Ihrem ceilometer_cpu-Service und Ihrer cpu_rating-Gruppe verknüpfen.
openstack rating hashmap mapping create 0.02 \
-s <service_id> \
-g <group_id> \
-t flatIn diesem Szenario bedeutet 0,02 eine Gebühr von 0,02 Einheiten pro Erfassungszeitraum (standardmäßig jede Stunde). Für CPU-Instanzen wird eine Pauschale von 0,02 Einheiten berechnet, unabhängig von ihrer Auslastung.
Schritt 4: Feldbasierte Bewertung (die Geheimwaffe)
Das Datenministerium betreibt winzige Webserver neben riesigen, ressourcenintensiven Datenbankknoten. Eine pauschale Abrechnung für alle Services wäre nicht angemessen. Wir möchten für die verschiedenen genutzten VM-Flavors unterschiedliche Preise berechnen.
Zunächst erstellen wir ein Feld, das auf den Metadatenschlüssel verweist:
openstack rating hashmap field create <service_id> flavor_idDanach erstellen wir eine spezifische Zuordnung für diesen Flavor-Wert:
openstack rating hashmap mapping create 0.05 \
--field-id <field_id> \
--value <flavor_uuid> \
-t flatWir wiederholen diesen Zuordnungsschritt für alle in unserer Umgebung verfügbaren Flavors. Für jeden Flavor erstellen wir eine neue Regel, damit der Bewertungsservice bei der Ausführung der jeweiligen VM-Größe den passenden Tarif berechnen kann.
Das Ergebnis: So funktioniert das Zusammenspiel
Wenn das Monatsende erreicht ist und das Datenministerium seine Nutzung einsehen möchte, verarbeitet CloudKitty die oben erstellten Regeln wie folgt:
ceilometer_cpu (metric)
└─> Service: ceilometer_cpu
└─> Field: flavor_id (optional)
└─> Mapping: m1.tiny = 0.01, m1.large = 0.05
└─> Mapping (direct): 0.02 flatWas Sie messen können, können Sie auch bewerten
Wir haben die CPU-Auslastung des Datenministeriums (ceilometer_cpu) als primäres Beispiel verwendet, aber die Rechenleistung ist nur ein Teil des Puzzles. Die wahre Stärke von CloudKitty in Red Hat OpenStack Services on OpenShift liegt in der Integration mit Prometheus.
Denken Sie daran, dass Sie bereits erfasste Metriken für die Bewertung nutzen können. Damit können Sie mit genau denselben Schritten, die wir oben beschrieben haben, ganz einfach Tarifregeln für den verbleibenden Ressourcenverbrauch Ihres Mandanten erstellen. Sie können beispielsweise Kostenzuordnungen für Folgendes erstellen:
- Block-Storage: Erfassung der Kapazität in GB-Monaten mit
ceilometer_disk_device_capacity - Networking: Abrechnung von zugewiesenen öffentlichen IP-Adressen über
ceilometer_ip_floating - Ausgehende Bandbreite: Bewertung des gesamten ausgehenden Datenverkehrs von VMs über
ceilometer_network_outgoing_bytes
Sobald CloudKitty diesen Datenumfang von Prometheus abgerufen hat, wendet der Prozessor Ihre benutzerdefinierten Tarifregeln an und überträgt die endgültigen, bewerteten Metriken direkt an ein Storage-Backend. Es dient als zentrale automatisierte Brücke zwischen Ihren unbearbeiteten technischen Telemetriedaten und Ihrem FinOps-Reporting.
Bewertungsberichte generieren: Der Moment der Wahrheit
Sobald Sie Ihre Regeln erstellt und Metriken von Prometheus erfasst haben, extrahieren Sie im letzten Schritt die bewerteten Daten.
Es ist wichtig zu beachten, dass CloudKitty kein Abrechnungssystem ist. Es versucht nicht, eine ansprechende PDF-Rechnung zu erstellen. Stattdessen ist es als robuste Daten-Engine konzipiert, die bereinigte, analysierbare JSON-Daten über die eigene REST-API oder den OpenStack-Client bereitstellt. Auf diese Weise können Sie die bewerteten Daten noch einfacher direkt in die bestehende FinOps-, Showback- oder Abrechnungs-Middleware Ihres Unternehmens integrieren.
Die Mandantensicht: Das Ministerium prüft seine laufenden Kosten
CloudKitty verfügt über eine integrierte, mandantenbezogene Zugriffskontrolle. Wenn das Datenministerium seine aktuelle Nutzung einsehen möchte, kann es nur auf den Ressourcenverbrauch des eigenen Projekts zugreifen. Die API blockiert oder ignoriert automatisch alle Versuche, die Daten anderer Mandanten anzuzeigen.
Um die monatliche Zusammenfassung abzurufen, kann das Ministerium den OpenStack-Client nutzen:
# Get summary for a specific month
openstack rating summary get --begin 2026-02-01 --end 2026-03-01Die Sicht der Administration: Die Vogelperspektive
Während das Datenministerium nur seine eigene Nutzung einsehen kann, benötigt die Cloud-Administration eine ganzheitliche Sicht auf die gesamte Umgebung, um Kapazitäten zu verwalten und ein globales Chargeback zu ermöglichen.
Mit einem Admin-Token erhalten Operatoren volle Einsicht. Sie können den Befehl erweitern, um einen bestimmten Mandanten über --tenant-id <project_uuid> zu isolieren.
openstack rating summary get \
--begin 2026-02-01 \
--end 2026-03-01 \
--tenant-id <project_uuid>Benötigt das FinOps-Team das Gesamtbild für den Export in sein Abrechnungssystem, kann die Administration alternativ die bewerteten Daten für die gesamte Cloud auf einmal über das Flag --all-tenants abrufen.
Direkte Verbindung zu Ihrer FinOps-Lösung
Wenn Ihre FinOps-Middleware diese Daten programmatisch abruft, kann sie über die REST-API eine detaillierte Aufschlüsselung anfordern, gruppiert nach den spezifischen, zuvor konfigurierten Servicetypen (wie ceilometer_cpu):
curl -X GET \
-H "X-Auth-Token: $TENANT_TOKEN" \
"http://localhost:8888/v1/report/summary?begin=2026-02-01T00:00:00&end=2026-03-01T00:00:00&groupby=res_type"Die resultierende JSON-Ausgabe stellt den Ressourcentyp, den Zeitraum und die Gesamtanzahl der berechneten Einheiten übersichtlich dar:
{
"summary": [
{
"tenant_id": "MoD-project-uuid",
"res_type": "ceilometer_cpu",
"begin": "2026-02-01T00:00:00",
"end": "2026-03-01T00:00:00",
"rate": 125.50
}
]
}Indem Sie diese strukturierten, aggregierten JSON-Daten direkt in die übergeordnete Finanzsoftware Ihres Unternehmens einspeisen, schließen Sie erfolgreich den Kreis zwischen der tatsächlichen Infrastrukturnutzung und der Kostenverantwortung.
Ein Blick hinter den Kulissen
Nachdem wir CloudKitty nun aus der Betreiberperspektive in Aktion gesehen haben, werfen wir einen genaueren Blick auf die darunterliegende Engine. Wenn Sie die Architektur verstehen, können Sie die Skalierbarkeit besser beurteilen, Fehler beheben und nachvollziehen, warum bestimmte Designentscheidungen getroffen wurden.
Architekturübersicht
CloudKitty läuft als 2 unabhängige Prozesse, die jeweils eine eigene Zuständigkeit haben:
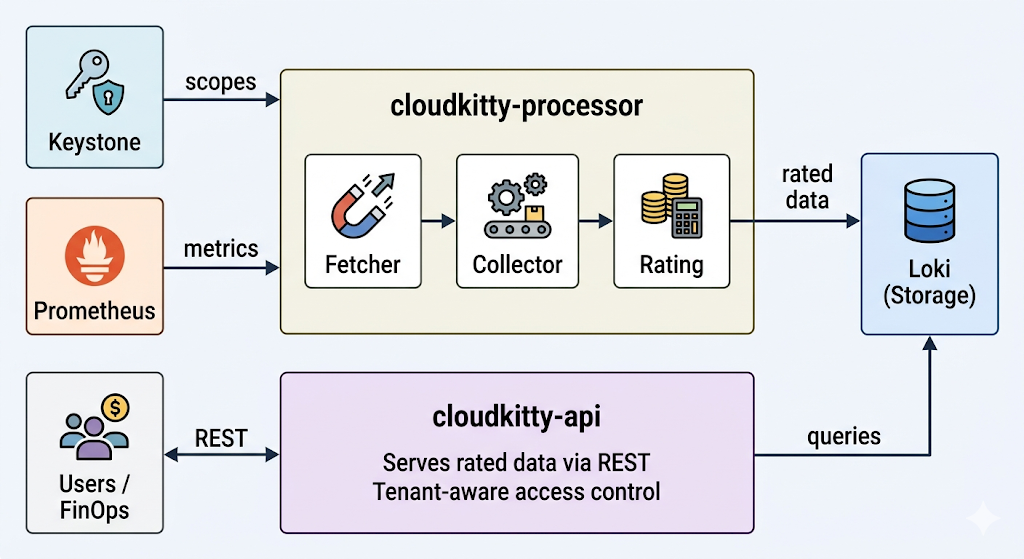
Abbildung 1. Die Architektur von CloudKitty. cloudkitty-processor ruft Scopes von Keystone und Metriken von Prometheus ab, bewertet die Daten und speichert sie in Loki. cloudkitty-api stellt die bewerteten Daten aus Loki über REST für Nutzende und FinOps-Tools bereit.
cloudkitty-processor ist die Bewertungs-Engine. In jedem Erfassungszeitraum (standardmäßig 1 Stunde) führt er eine 4-stufige Pipeline aus:
- Abruf: Fragt Keystone nach der Liste der zu bewertenden OpenStack-Projekte (Scopes).
- Sammeln: Fragt für jeden Scope die in
metrics.yamldefinierten Rohmetrikwerte von Prometheus ab. - Bewerten: Wendet die Hashmap-Regeln (die zuvor konfigurierten Services, Felder und Zuordnungen) an, um den Rohverbrauch in bewertete Daten umzuwandeln.
- Speichern: Überträgt die resultierenden bewerteten DataFrames zur Persistenz an Loki.
cloudkitty-api ist das REST-Frontend. Es verarbeitet alle eingehenden Anfragen von Mandanten, Administrierenden und externen FinOps-Tools. Wenn Nutzende eine Bewertungszusammenfassung anfordern, fragt es Loki ab und gibt die Ergebnisse zurück. Dieser Prozess ist zustandslos und lässt sich horizontal skalieren, um mehr gleichzeitige Anfragen zu verarbeiten.
Da die beiden Prozesse entkoppelt sind, können Sie diese unabhängig voneinander skalieren: Fügen Sie weitere API-Replikate hinzu, um die Abfragelast zu bewältigen, oder optimieren Sie die Parallelisierung des Prozessors, um mehr Scopes gleichzeitig zu bewerten.
Warum Loki?
Die Verwendung von Grafana Loki als Storage-Backend für bewertete Daten scheint eine unkonventionelle Wahl zu sein, da Loki in erster Linie als Log-Aggregationssystem bekannt ist. Tatsächlich ist es jedoch eine hervorragende Lösung:
- Nativ für Zeitreihen: Bewertete Daten sind von Natur aus zeitbezogen: Kosten pro Scope und Erfassungszeitraum. Loki ist speziell für effiziente Zeitbereichsabfragen über strukturierte Streams konzipiert.
- Bereits im Stack: OpenStack Services on OpenShift-Bereitstellungen enthalten bereits einen LokiStack für das Log-Management. CloudKitty nutzt dieselbe vom Operator verwaltete Infrastruktur, sodass Sie keine zusätzliche Datenbank bereitstellen oder warten müssen.
- Basiert auf Object Storage: Loki speichert Daten in S3-kompatiblem Object Storage und hält so den operativen Footprint klein – ohne zusätzliche PVCs oderamp; Datenbank-Cluster, die Sie verwalten müssen.
- Strukturierte Metadaten: In Zukunft wird CloudKitty indizierte Metadaten (Mandant, Metriktyp, Flavor) direkt in jedem Log-Eintrag speichern. Dies wird schnelle gefilterte Abfragen ohne vollständiges JSON-Parsing ermöglichen und die Abfrage-Performance im großen Maßstab erheblich verbessern.
Die Metrikkonfiguration
Das Herzstück der Erfassungsphase bildet metrics.yaml. Diese Datei teilt CloudKitty mit, welche Prometheus-Metriken das Tool erfassen und wie es diese verarbeiten soll. Hier ist ein repräsentativer Auszug aus der mitgelieferten Konfiguration:
metrics:
ceilometer_cpu:
unit: instance
alt_name: instance
groupby:
- resource
- user
- project
- flavor_name
- flavor_id
mutate: NUMBOOL
extra_args:
aggregation_method: max
ceilometer_image_size:
unit: MiB
factor: 1/1048576
groupby:
- resource
- project
metadata:
- container_format
- disk_format
extra_args:
aggregation_method: maxJeder Eintrag steuert, wie CloudKitty eine bestimmte Prometheus-Metrik erfasst und interpretiert:
unit: Die Abrechnungseinheit, die in Bewertungsberichten erscheint (z. B. Instanz, GiB, B, IP).alt_name: Ein alternativer Name für die Metrik. Beim Erstellen von Hashmap-Services können Sie entweder den Prometheus-Metriknamen (ceilometer_cpu) oder denalt_name(instance) verwenden.groupby: Die Prometheus-Labels, die Sie zur Disaggregierung der Metrik verwenden. Für ceilometer_cpu ermöglicht die Gruppierung nach flavor_name and flavor_id die Flavor-basierten Tarifregeln, die wir zuvor konfiguriert haben.mutate: Eine Transformation, die Sie auf den Rohwert anwenden. NUMBOOL konvertiert jeden Wert ungleich null in 1, was sich perfekt für die Semantik „Ist diese Ressource aktiv?“ eignet – uns interessiert nicht der rohe CPU-Zähler, sondern nur, dass die Instanz läuft.factor: Ein Multiplikationsfaktor für die Einheitenumrechnung. Beispielsweise verwendetceilometer_image_size1/1048576, um Rohbytes in MiB umzurechnen.metadata: Zusätzliche Prometheus-Labels, die Sie zu Informationszwecken in die bewerteten Daten übernehmen (z. B.container_format,disk_formatfür Images).extra_args: Backend-spezifische Argumente.aggregation_method: maxweist den Prometheus-Collector an, den Maximalwert innerhalb jedes Erfassungszeitraums zu verwenden.
Da der Collector von CloudKitty direkt mit Prometheus kommuniziert, ist die Bewertung von verfügbaren Metriken unkompliziert: Fügen Sie metrics.yaml einen neuen Eintrag mit den entsprechenden Labels und der passenden Einheit hinzu, und CloudKitty beginnt im nächsten Verarbeitungszyklus mit deren Erfassung und Bewertung.
Rohdaten überprüfen
Während der Befehl openstack rating summary get Ihnen aggregierte Summen liefert, müssen Sie manchmal genauer hinsehen. Ganz gleich, ob Sie die korrekte Anwendung Ihrer Tarifregeln überprüfen, eine fehlende Metrik debuggen oder nachvollziehen möchten, was CloudKitty speichert: Mit dem Befehl openstack rating dataframes get können Sie die einzelnen bewerteten Datenpunkte in Loki untersuchen.
Stellen Sie sich Zusammenfassungen wie eine monatliche Abrechnung und DataFrames wie die einzelnen Posten auf dem Beleg vor.
So rufen Sie die rohen bewerteten DataFrames für ein bestimmtes Zeitfenster ab:
openstack rating dataframes get --begin 2026-03-01T00:00:00Z --end 2026-03-01T01:00:00ZDie Zeilen in der Ausgabe stellen jeweils einen einzelnen bewerteten Datenpunkt für 1 Erfassungszeitraum dar:
| Beginn | Ende | Metriktyp | Einheit | Menge | Preis | Gruppieren nach | Metadaten |
|---|---|---|---|---|---|---|---|
2026-03-01T00:00:00Z |
2026-03-01T01:00:00Z |
ceilometer_cpu |
instance |
1 |
0.05 |
flavor_id=<uuid>, flavor_name=m1.large, project=<project_uuid>, resource=<vm_uuid> |
|
2026-03-01T00:00:00Z |
2026-03-01T01:00:00Z |
ceilometer_cpu |
instance |
1 |
0.01 |
flavor_id=<uuid>, flavor_name=m1.tiny, project=<project_uuid>, resource=<vm_uuid> |
Sehen wir uns an, welche Informationen die einzelnen Spalten enthalten:
- Beginn/Ende: Der Erfassungszeitraum, den dieser Datenpunkt abdeckt. Standardmäßig erfasst CloudKitty die Daten stündlich, sodass Sie 1-Stunden-Fenster sehen.
- Metriktyp: Der Name der Metrik aus
metrics.yaml(z. B.ceilometer_cpu,ceilometer_ip_floating). - Einheit: Die Abrechnungseinheit, wie in
metrics.yamldefiniert. - Menge: Die Rohmenge nach allen Mutate- oder Faktor-Transformationen. Für
ceilometer_cpumitNUMBOOLbeträgt dieser Wert 1, wenn die Instanz lief. - Preis: Der bewertete Wert, nachdem Sie Ihre Hashmap-Regeln angewendet haben. Hier können Sie überprüfen, ob die richtige Zuordnung angewendet wurde. Wenn Sie
m1.largeauf 0,05 festgelegt haben, sollte genau das hier angezeigt werden. - Gruppieren nach: Die Label-Werte aus den Feldern
groupbyinmetrics.yaml. Auf diese Weise disaggregiert CloudKitty die Daten, sodass Sie gezielt Details zu bestimmten Ressourcen, Flavors oder Projekten abrufen können. - Metadaten: Alle zusätzlichen Labels, die über das Metadatenfeld in
metrics.yamlübermittelt werden.
Dies bietet Betreibenden ein konkretes Tool, um den gesamten Weg von der Rohmetrik bis zum Endpreis zurückzuverfolgen. So wird das Verhalten von CloudKitty bei jedem Schritt transparent und debuggbar.
Bereit, Kosten zu erfassen?
Ganz gleich, ob Ihr Ziel eine strikte Kostendeckung durch interne Abteilungen oder eine transparente Übersicht über den Ressourcenverbrauch ist: CloudKitty liefert Ihnen die strukturierten, zuverlässigen Daten, die Sie für die Umsetzung benötigen. Die Lösung schließt die Lücke zwischen Ihrer unformatierten OpenStack-Telemetrie und der FinOps-Middleware Ihres Unternehmens.
Die Zeiten, in denen die Private Cloud wie ein kostenloses Buffet behandelt wurde, sind vorbei. Wir freuen uns, diese native, hochgradig anpassbare Funktion mit Feature Release 5 im Ökosystem von OpenStack Services on OpenShift bereitzustellen. Es ist an der Zeit, mit dem Schätzen aufzuhören und mit der Bewertung zu beginnen.
Erste Schritte
Erfahren Sie in der offiziellen Dokumentation, wie Sie CloudKitty in Ihrer Umgebung konfigurieren und verwalten:
- Aktivieren der Cloud-Bewertung in einer OpenStack Services on OpenShift-Umgebung
- So nutzen Sie den Bewertungsservice
Erleben Sie die Lösung in Aktion
Sehen Sie sich die Video-Demo an, um zu erfahren, wie Administrierende auf einfache Weise Flavor-basierte Tarifregeln konfigurieren und die erste monatliche Aufschlüsselung abrufen können.
Dieses Video ist ein kuratierter Zusammenschnitt aus 2 separaten Terminal-Sitzungen. Wenn Sie sich die im Hintergrund verwendeten Rohbefehle genauer und interaktiv ansehen möchten, finden Sie hier die vollständigen, ungeschnittenen Asciinema-Aufzeichnungen:
- https://asciinema.org/a/ofDLdVKxHfMAsaNM: CloudKitty bereitstellen und die Flavor-basierten Tarifregeln erstellen.
- https://asciinema.org/a/P11NR7CEqfiewF4R: Die Chargeback-DataFrames verifizieren und die monatliche Zusammenfassung extrahieren.
Produkttest
Red Hat OpenShift Container Platform | Testversion
Über die Autoren
Juan Larriba is a software engineer specializing in cloud infrastructure and OpenStack observability. He is a contributor to the OpenStack Kubernetes Operators ecosystem, where he works on the Telemetry Operator — a project that brings together metrics collection, alarming, and rating services like CloudKitty into cloud-native Kubernetes deployments. His work focuses on bridging traditional OpenStack telemetry components with modern container-native architectures, helping operators gain visibility and cost insight into their cloud workloads. Juan is passionate about open source collaboration and has contributed to projects spanning Ceilometer, Aodh, and CloudKitty, with a focus on making rating and chargeback capabilities more accessible in production OpenStack environments.
Ähnliche Einträge
Red Hat OpenShift 4.21: Intelligentere Skalierung, schnellere Migration und KI-gestützte Effizienz
Einführung in Red Hat build of Podman Desktop: Lokale Container-Entwicklungsumgebungen für Unternehmen
Do We Want A World Without Technical Debt? | Compiler
Avoiding Failure In Distributed Databases | Code Comments
Nach Thema durchsuchen

Automatisierung
Das Neueste zum Thema IT-Automatisierung für Technologien, Teams und Umgebungen

Künstliche Intelligenz
Erfahren Sie das Neueste von den Plattformen, die es Kunden ermöglichen, KI-Workloads beliebig auszuführen

Open Hybrid Cloud
Erfahren Sie, wie wir eine flexiblere Zukunft mit Hybrid Clouds schaffen.

Sicherheit
Erfahren Sie, wie wir Risiken in verschiedenen Umgebungen und Technologien reduzieren

Edge Computing
Erfahren Sie das Neueste von den Plattformen, die die Operations am Edge vereinfachen

Infrastruktur
Erfahren Sie das Neueste von der weltweit führenden Linux-Plattform für Unternehmen

Anwendungen
Entdecken Sie unsere Lösungen für komplexe Herausforderungen bei Anwendungen
Virtualisierung
Erfahren Sie das Neueste über die Virtualisierung von Workloads in Cloud- oder On-Premise-Umgebungen