
Machine Learning is a tool that is quickly becoming more and more available to enterprises. Although this new tool is very powerful, it is still often not well understood. This blog post intends to demystify the concepts around Machine Learning, define much of the vernacular common to the practice, and inform how Red Hat teams can help today. This post extends the information provided in our whiteboarding video.
Disciplines of Artificial Intelligence
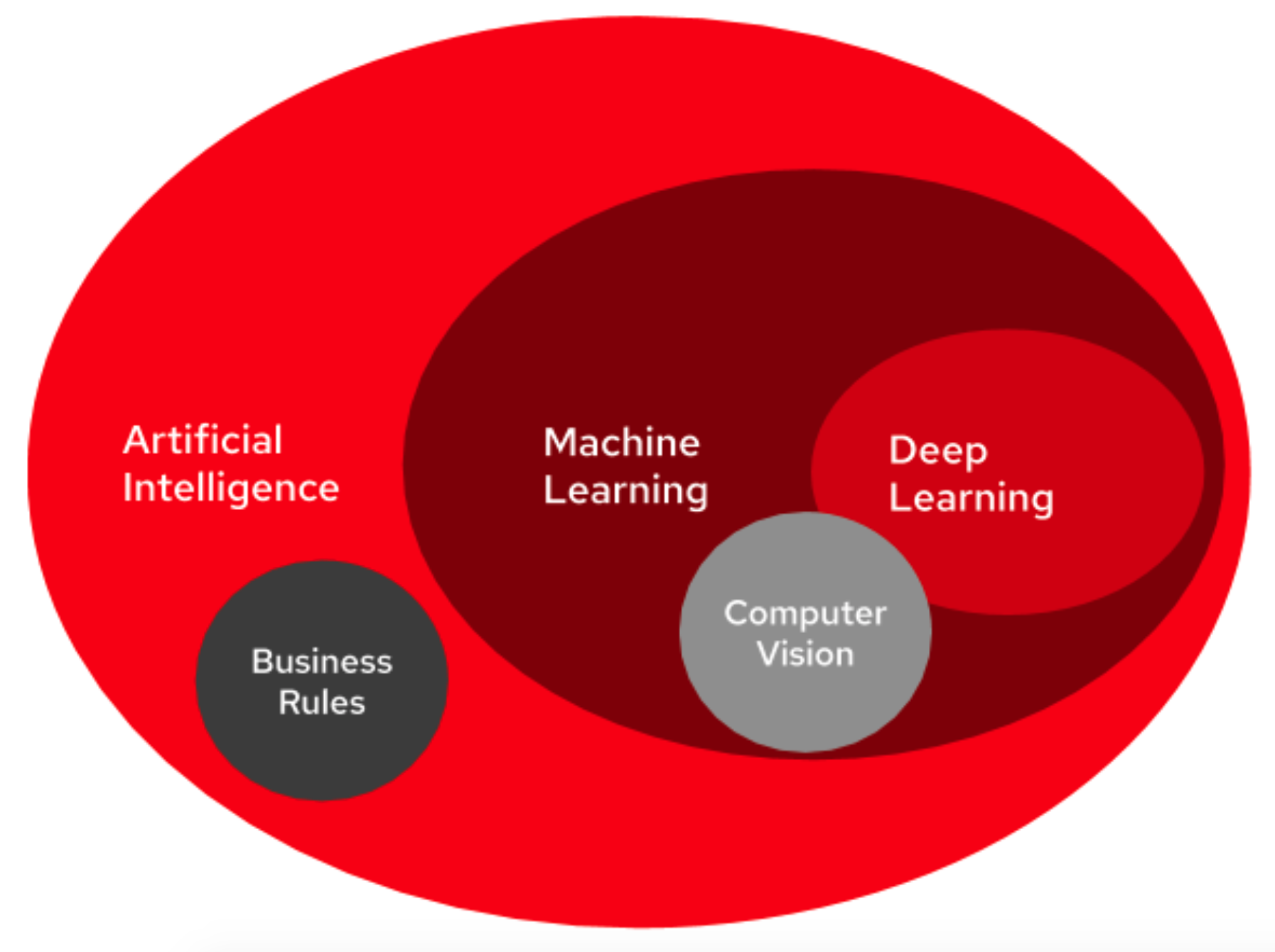
Machine Learning is a general name given to an extensive collection of algorithms that are used to allow a computer to identify patterns in past data and use those patterns to predict future results. Computer Vision and Natural Language Processing both make heavy use of Machine Learning.
The field of Machine Learning is considered to be a subset of a field called Artificial Intelligence. Often, the terms concatenated together as AI/ML, but it is important to understand the difference. Artificial Intelligence describes a computer making decisions just as an educated human might. In Artificial Intelligence, the computer is given instructions on how to make a decision rather than finding the rules from data. Business Rules and Process Automation are great examples of Artificial Intelligence that are not considered to be Machine Learning.
Within the past decade, the industry has seen a boom in the discipline of Deep Learning. This is a subset of Machine Learning that employs the use of large Artificial Neural Networks (ANN) to identify patterns in data. ANNs are algorithms designed to work similarly to the human brain. Deep Learning has the advantage of requiring less data preparation than traditional machine learning algorithms, but it also requires substantially more compute resources in return. Often, Machine Learning is assumed to be primarily Deep Learning. However, many algorithms exist that do not make use of ANNs and are not considered to be Deep Learning. Choosing the best algorithm for the problem at hand is the chief responsibility of the data scientist.
Styles of Machine Learning
Machine learning is typically classified by three learning styles: Supervised Learning, Unsupervised Learning, and Reinforcement Learning.
Supervised Learning is a style of learning where the computer is trained to map known inputs to known outputs based on known examples. For this style of learning to work, there must be good examples to give to the computer for it to learn. For this example set of data, called a training set, the answer must already be known. The process of attaching answers to the learning data set is called labeling the data. This learning can be used to perform two types of analysis: Regression and Classification. A regression problem is one where the output is a continuous number, like a home’s market value. A classification problem is one where the answer is one or many categories, like identifying objects in pictures. Supervised Learning is a fairly well-understood discipline, and many pre-trained algorithms exist. However, Supervised Learning does require clean and labeled data.
Unsupervised Learning is a style of learning where the computer is trained to map known inputs to unknown outputs simply by recognizing patterns in the data. A training set of data is given to the algorithm, but the answers are not already known. Common analyses performed with Unsupervised Learning are Clustering and Anomaly Detection (although others exist). Clustering involves looking for data points that are close to each other and are easily grouped. Anomaly Detection involves recognizing common traits so that rare data points are identified. Unsupervised learning does not require training data to be labeled and does not require the data scientist to have deep domain knowledge in the data. However, these algorithms are more difficult in practice and require additional analysis to ensure the results are meaningful.
Reinforcement Learning is a style of learning where a computer is trained to take a series of actions to maximize a reward. This style of learning is often used when training a computer to play a game such as Chess or Go. With these algorithms, the computer can play the game and recognize which actions lead to a win or a loss. These algorithms provide the benefit that they can produce very finely tuned results. However, data scientists can only use these algorithms when the problem has some notion of a reward, and scientists can simulate the problem space. The computer will need to run through many simulations of the problem to learn realistic outcomes.
Machine Learning at Red Hat
Red Hat has employed data scientists for quite some time. One product of Red Hat’s Data Science Team is Red Hat Insights. This tool monitors Red Hat Enterprise Linux systems and identifies hardware or configuration issues before they manifest as outages. This tool is publicly available now and provided with every RHEL subscription.
Internally, Red Hat’s data scientists work primarily on OpenShift. Data science environments typically depend on a specific permutation of software dependencies and software versions that are easily standardized and versioned with containers. OpenShift is perfectly suited to provide compute resources to data scientists in a flexible and on-demand way that has not previously been possible in compute-intensive environments. Additionally, OpenShift allows data scientists to move their trained models into production with ease. The infrastructure used internally at Red Hat for data science has been open-sourced as the Open Data Hub project. This is publically available as a reference architecture to any enterprise looking to bootstrap their data science platform.
Über den Autor
Ähnliche Einträge
Agentische KI erfordert einen neuen Infrastruktur-Stack: AMD und Red Hat bieten eine Lösung
IT-Stack vereinheitlichen: VMs, Cloud und KI vereint
Operating System Management | Compiler
Technically Speaking | Inside open source AI strategy
Nach Thema durchsuchen

Automatisierung
Das Neueste zum Thema IT-Automatisierung für Technologien, Teams und Umgebungen

Künstliche Intelligenz
Erfahren Sie das Neueste von den Plattformen, die es Kunden ermöglichen, KI-Workloads beliebig auszuführen

Open Hybrid Cloud
Erfahren Sie, wie wir eine flexiblere Zukunft mit Hybrid Clouds schaffen.

Sicherheit
Erfahren Sie, wie wir Risiken in verschiedenen Umgebungen und Technologien reduzieren

Edge Computing
Erfahren Sie das Neueste von den Plattformen, die die Operations am Edge vereinfachen

Infrastruktur
Erfahren Sie das Neueste von der weltweit führenden Linux-Plattform für Unternehmen

Anwendungen
Entdecken Sie unsere Lösungen für komplexe Herausforderungen bei Anwendungen
Virtualisierung
Erfahren Sie das Neueste über die Virtualisierung von Workloads in Cloud- oder On-Premise-Umgebungen