Bereitstellung eines gemeinsamen Zugriffs auf KI mit zentralisierten Modelloperationen
- Für AI Engineers bietet MaaS einen schnelleren Zugriff auf leistungsstarke Modelle über APIs, wodurch das Herunterladen von Modellen, die Verwaltung von Abhängigkeiten oder die Anforderung von GPU-Zuweisungen über langwierige IT-Tickets entfällt.
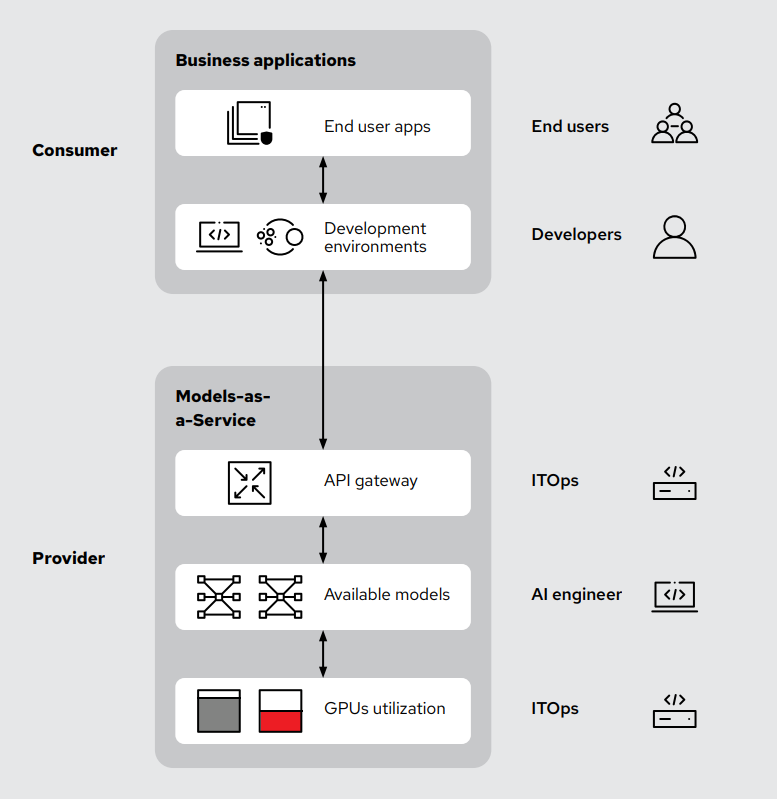
MaaS funktioniert über die Einrichtung eines KI-Operations-Teams als zentraler Eigentümer gemeinsamer KI-Ressourcen. Modelle werden auf einer skalierbaren Plattform (wie Red Hat® OpenShift® AI oder ähnlichen Plattformen) bereitgestellt und dann über ein API-Gateway zugänglich gemacht. So können mehrere Nutzende, Mitglieder des Entwicklungsteams und Geschäftsbereiche einen vereinfachten Zugriff für Endbenutzende bereitstellen und gleichzeitig die Vorgaben zu Sicherheit und Governance von IT- und Finanzteams erfüllen. Diese Priorisierung kann Chargeback-Funktionen umfassen, was die Nutzung von Modellen ohne direkten Hardwarezugang oder tiefgreifendes technisches Fachwissen ermöglicht. Ziel ist es, einen nutzungsfreundlichen Zugriff auf die KI-Modelle und nicht auf die zur Ausführung dieser Modelle erforderlichen Ressourcen wie GPUs und TPUs (Tensor Processing Units) zu ermöglichen. Gleichzeitig müssen Sie die Performance- und Compliance-Anforderungen des Unternehmens erfüllen, ohne den Zugriff für Endbenutzende zu erschweren.
In der Praxis interagieren Nutzende nur mit APIs, die vom Modell generierte Antworten liefern. So wie öffentliche KI-Anbieter die Komplexität der Hardware von den Endbenutzenden abstrahieren, bieten interne MaaS-Deployments dieselbe Einfachheit. Die Nutzenden verwalten nicht direkt die Hardware- oder Softwareinfrastruktur, sie warten auch nicht darauf, dass ein IT-Ticket in ihrem Namen bearbeitet oder dass eine Umgebung für sie konfiguriert wird. Stattdessen verwalten IT-Operations- und KI-Teams zentral den Modell-Lifecycle sowie Sicherheit, Updates und Skalierung der Infrastruktur und bieten Nutzenden einen optimierten und dennoch kontrollierten Zugriff.
Diese Zentralisierung optimiert nicht nur die internen KI-Abläufe, sondern verbessert auch den Sicherheitsfokus und die Governance. Der Zugriff auf KI-Modelle wird durch die Zugangsdatenverwaltung über ein API-Gateway streng kontrolliert. Unternehmen können die Verwendung einfach nachverfolgen, interne Chargeback-Mechanismen einrichten, sicherstellen, dass Compliance-Richtlinien zum Datenschutz eingehalten werden, und klare operative Grenzen festlegen. So wird Unternehmens-KI sowohl überschaubar als auch praktisch. Das Verfolgen der Nutzung auf Token-Ebene (ein- und ausgehend) ist die genaueste und granularste Methode, viel präziser als Metriken auf GPU-Ebene.
Nutzung kontrollieren, Zugang drosseln, Kosten managen
- IT und Platform Engineers profitieren von zentraler Kontrolle, die nicht autorisierte Modellbereitstellungen verhindert, Sicherheits- und Compliance-Standards durchsetzt und das Lifecycle- und Infrastrukturmanagement vereinfacht.
- Für Finanzteams reduzieren zentralisierte Nutzungsverfolgung und interne Chargeback-Mechanismen Verschwendung und machen die GPU-Nutzung vorhersehbarer und nachvollziehbarer. So können Mehrausgaben durch nicht ausreichend genutzte, teamspezifische Hardwarezuweisungen vermieden werden.
Die Kontrolle erfolgt in erster Linie durch die Integration eines API-Gateways in die KI-Infrastruktur, wodurch Teams die KI-Nutzung auf sehr granularer Ebene verwalten und überwachen können.
Herkömmliche KI-Implementierungen werden häufig durch nicht verwaltete oder ineffiziente Nutzung beeinträchtigt, da Einzelpersonen oder Teams unabhängig voneinander Modelle ohne zentrale Kontrolle bereitstellen. Dieser fragmentierte Ansatz kann zu kostspieligen Ineffizienzen führen, da GPU-Ressourcen gar nicht oder nicht ausreichend genutzt werden. Durch die Platzierung eines API-Gateways als Kernstück der KI-Infrastruktur entsteht ein kontrollierter Zugangspunkt zwischen Nutzenden und Modellen.
Dieses Setup erleichtert präzises Nachverfolgen der Nutzung bis auf die Ebene der einzelnen Token. So können Teams eindeutig ermitteln, wie viel die einzelnen Nutzenden, Teams oder Anwendungen verbrauchen, und die Kosten für GPU und Infrastruktur genau zuordnen. Unternehmen können so feststellen, ob bestimmte Nutzende oder Anwendungen übermäßig viele Ressourcen verbrauchen und entsprechende Abhilfemaßnahmen ergreifen, wie etwa die Nutzung drosseln oder Kosten durch interne Chargeback-Mechanismen zuordnen.
Die vom API-Gateway bereitgestellten Drosselfunktionen sorgen für eine konsistente Performance und verhindern eine Überlastung der Ressourcen. Durch das Drosseln können IT-Teams die Intensität der Zugriffe verwalten und verhindern, dass einzelne Nutzende viele GPU-Ressourcen beanspruchen oder die Performance anderer beeinträchtigen.
Darüber hinaus ermöglichen API-Gateways eine fein granulierte Zugangsdatenverwaltung und Zugangskontrolle. Interne Nutzende können Zugangsdaten für den unabhängigen Zugriff auf KI-Modelle generieren, was den Administrationsaufwand optimiert. Außerdem können Zugangsdaten in kürzerer Zeit widerrufen oder geändert werden, um auf sich ändernde Sicherheitsanforderungen oder Nutzungsmuster zu reagieren.
All dies bedeutet, dass das Kostenmanagement transparenter und nachvollziehbarer wird. IT-Teams können GPU- und Infrastrukturausgaben genau den Teams oder Geschäftsbereichen zuordnen, die sie nutzen.
Support für beliebige Modelle, beliebige Beschleuniger, beliebige Clouds
Ein Kerngedanke des MaaS-Ansatzes ist die Kontrolle. So können Unternehmen eine große Bandbreite an KI-Modellen auswählen und bereitstellen, ihre bevorzugten Hardwarebeschleuniger wählen und in ihren bestehenden Cloud- oder On-Premise-Umgebungen arbeiten. Dieser Ansatz gibt Unternehmen die Freiheit, KI genau nach ihren Anforderungen an Technik und Sicherheit sowie gemäß operativen Präferenzen zu implementieren.
- Bei der Einführung von KI sehen sich Unternehmen starren Einschränkungen gegenüber. Dazu gehören oft:
- Einschränkungen durch bestimmte Cloud Services
- Bindung an proprietäre Modell-Ökosysteme
- Einschränkungen durch feste Hardwareinfrastrukturen
- MaaS begegnet diesen Einschränkungen auf verschiedene Weise, darunter:
- Unterstützung von quelloffenen oder proprietären Modellen, individuell trainierten Modellen und gängigen LLMs wie Llama und Mistral
- Erweiterung der textbasierten Modelle mit prädiktiven Analysen, maschinellem Sehen, Tools für die Audiotranskription und weiteren, multimodalen gen KI-Use Cases wie Bild- oder Videogenerierung
- MaaS ist von Hardwarebeschleunigern unabhängig und bietet so folgende Vorteile:
- Unternehmen können GPUs oder andere Beschleuniger wählen, die ihren Workloads, Kostenstrukturen und Performance-Anforderungen entsprechen
- Zentralisierte KI-Teams können wichtige Entscheidungen in Bezug auf Umfangsbestimmung und Deployment treffen, was die Effizienz verbessert und Fehler durch weniger technisch versierte Nutzende reduziert
- Zentralisiertes Management bietet folgende Vorteile:
- Optimale Zuweisung und Nutzung der Infrastruktur
- Reduzierter operativer Aufwand und Vermeidung der Fehlkonfiguration von Ressourcen
- MaaS unterstützt Deployments in vielen verschiedenen Umgebungen, darunter:
- On-Premise, Hybrid Cloud, Air Gap-Umgebungen und Public Clouds, was besonders für stark regulierte Sektoren geeignet ist, die Datensouveränität, Compliance mit Vorschriften oder strenge Sicherheitskontrollen erfordern