
Con Red Hat OpenShift Virtualization, podrá unificar la implementación y la gestión de las máquinas virtuales (VM) junto con las aplicaciones en contenedores en la nube para eliminar los obstáculos relacionados con las cargas de trabajo. Dado que formamos parte del equipo de rendimiento y ampliación en general, nos dedicamos de lleno a la medición y el análisis de las máquinas virtuales que se ejecutan en OpenShift desde el inicio del proyecto open source de KubeVirt y contribuimos a impulsar la consolidación del producto mediante la evaluación de las funciones nuevas, el ajuste de las cargas de trabajo y las pruebas de ampliación. En este artículo, nos centramos en varias de nuestras áreas de interés y compartimos información adicional sobre la ejecución y el ajuste de las cargas de trabajo de las máquinas virtuales en OpenShift.
Guías de ajuste y ampliación
Nuestro equipo se encarga de elaborar documentación sobre el ajuste y la ampliación con el fin de que los clientes puedan aprovechar al máximo sus implementaciones de máquinas virtuales. En primer lugar, disponemos de una guía de ajuste general, la cual se encuentra en este artículo de la base de conocimientos e incluye recomendaciones para optimizar el plano de control de la solución a fin de lograr altos índices de creación de ráfagas de máquinas virtuales y diversas opciones de ajuste, tanto a nivel del host como de las máquinas virtuales, que permiten mejorar el rendimiento de las cargas de trabajo.
En segundo lugar, publicamos una arquitectura de referencia detallada que incluye un ejemplo de un clúster de OpenShift, un clúster de Red Hat Ceph Storage (RHCS) e información específica sobre el ajuste de la red. También analizamos ejemplos de los tiempos de arranques simultáneos y de implementaciones de máquinas virtuales, el rendimiento del ajuste de la latencia de E/S, la migración y la simultaneidad de las máquinas virtuales, y la ejecución de las actualizaciones de los clústeres según sea necesario.
Áreas de interés del equipo
En las siguientes secciones, se ofrece una descripción general de algunas de nuestras principales áreas de interés y detalles sobre las pruebas que llevamos a cabo para describir y mejorar el rendimiento de las máquinas virtuales que se ejecutan en OpenShift. En la figura 1, se muestran nuestras áreas de interés.
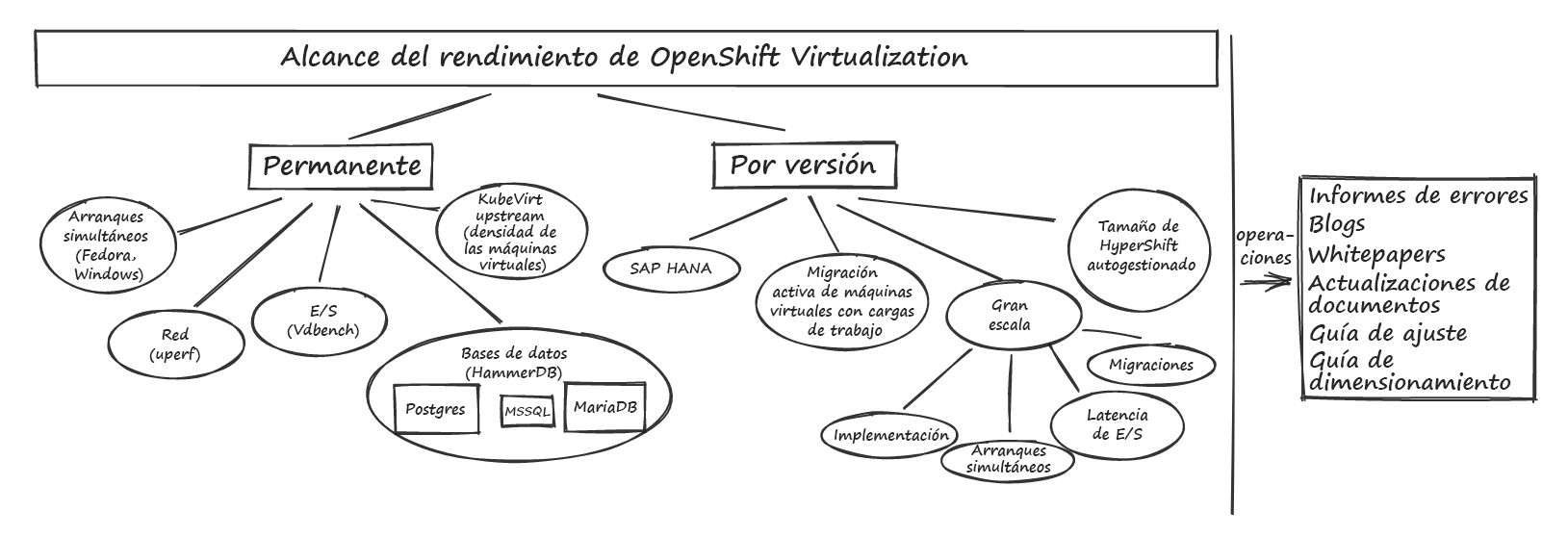
Figura 1: Áreas de interés del rendimiento de OpenShift Virtualization
Rendimiento de las cargas de trabajo
Dedicamos mucho tiempo a centrarnos en cargas de trabajo fundamentales que abarcan elementos informáticos, de redes y de almacenamiento para garantizar un amplio alcance. Para ello, recopilamos estándares permanentes en diferentes modelos de hardware, actualizamos los resultados a medida que aparecen versiones nuevas y estudiamos a fondo las distintas opciones de ajuste para lograr un rendimiento óptimo.
Un área de interés importante de las cargas de trabajo tiene que ver con el rendimiento de las bases de datos. Por lo general, utilizamos HammerDB como controlador de las cargas de trabajo y nos centramos en varios tipos de bases de datos (como MariaDB, PostgreSQL y MSSQL), de modo que podamos comprender mejor su rendimiento en función de sus distintas características. En esta plantilla, se ofrece un ejemplo de definición de una máquina virtual de HammerDB.
Otra de las principales áreas es una base de datos en memoria de alto rendimiento, SAP HANA, con el objetivo de obtener resultados por debajo del 10 % de los de un servidor dedicado (bare metal). Para lograrlo, aplicamos algunos ajustes de aislamiento en el host y en la máquina virtual, como el uso de CPUManager, el ajuste de la afinidad de procesos controlada por systemd, el respaldo de la máquina virtual con hugepages y el empleo de conexiones de red con SRIOV.
Para analizar más a fondo el rendimiento del almacenamiento, usamos cargas de trabajo de Vdbench para ejecutar un conjunto de patrones de aplicaciones de E/S diferentes que se centran en las IOP (operaciones de entrada/salida por segundo) y la latencia. Estos patrones cambian el tamaño del bloque, el tipo de operación de E/S y el tamaño y la cantidad de archivos y directorios, y ajustan la combinación de las operaciones de lectura y escritura. De este modo, podemos abordar los diversos comportamientos de E/S y comprender así las diferentes características del rendimiento. También ejecutamos otra evaluación comparativa común, Fio, para medir varios perfiles de almacenamiento. Probamos diversos proveedores de almacenamiento permanente, pero nos centramos principalmente en OpenShift Data Foundation con los volúmenes de los dispositivos de RADOS (RBD) en modo bloque en las máquinas virtuales.
Asimismo, utilizamos diferentes tipos de evaluaciones comparativas para determinar el rendimiento de otros elementos y completar algunas de las cargas de trabajo más complejas. En cuanto a las conexiones de redes, solemos utilizar la carga de trabajo de uperf para medir las configuraciones de prueba Stream y RequestResponse en función del tamaño de los mensajes y el recuento de los subprocesos, y nos centramos en las redes de pods predeterminadas y en otros tipos de interfaces de red de contenedores (CNI), como las redes adicionales Linux Bridge y OVN-Kubernetes. Para las pruebas informáticas, utilizamos una variedad de evaluaciones comparativas convencionales, como stress-ng, blackscholes, SPECjbb2005 y similares, según el área de interés.
Pruebas de regresiones
Al utilizar un marco de automatización denominado benchmark-runner, ejecutamos configuraciones de cargas de trabajo de manera permanente y comparamos los resultados con los estándares básicos conocidos para detectar y corregir las posibles regresiones en las versiones previas al lanzamiento de OpenShift Virtualization. Dado que el rendimiento de la virtualización es un aspecto fundamental, ejecutamos este marco de pruebas permanentes en sistemas con servidores dedicados (bare metal). Se comparan las cargas de trabajo con configuraciones similares en pods, máquinas virtuales y contenedores en entornos de pruebas (sandbox) para comprender mejor el rendimiento relativo. Esta automatización nos permite instalar rápidamente las nuevas versiones preliminares de OpenShift y los operadores en los que nos centramos, como OpenShift Virtualization, OpenShift Data Foundation, el operador de almacenamiento local y los contenedores en entornos de prueba (sandbox) de OpenShift. Si analizamos el rendimiento de las versiones preliminares varias veces a la semana, es posible detectar las regresiones antes de que se pongan a disposición de los clientes y comparar las mejoras de rendimiento a lo largo del tiempo a medida que actualizamos a las versiones más recientes que incorporan funciones más avanzadas.
Aunque seguimos ampliando las cargas de trabajo automatizadas de manera permanente, el conjunto actual que ejecutamos con regularidad incluye evaluaciones comparativas de bases de datos, microevaluaciones comparativas informáticas, uperf, Vdbench, Fio y pruebas de arranque simultáneo de máquinas virtuales y latencia de arranque de pods que utilizan diversas áreas del clúster para medir la rapidez con la que un gran número de pods o máquinas virtuales pueden arrancar a la vez.
Rendimiento de la migración
Una de las ventajas de usar un proveedor de almacenamiento compartido que permite el modo de acceso RWX es la posibilidad de que las cargas de trabajo de las máquinas virtuales puedan migrar de manera activa y sin problemas durante las actualizaciones del clúster. Por ello, siempre estamos buscando la forma de mejorar la velocidad de migración de las máquinas virtuales sin que se produzcan interrupciones significativas de la carga de trabajo. Esto implica probar y proponer límites y políticas al respecto que proporcionen valores predeterminados seguros, así como poner a prueba límites mucho más elevados que permitan detectar posibles obstáculos en la migración de elementos. También evaluamos las ventajas que ofrece la creación de una red de migración exclusiva y analizamos la red a nivel de nodo y los indicadores por máquina virtual para describir el avance de este proceso en la red.
Ampliación del rendimiento
Realizamos pruebas periódicas de los entornos a gran escala para detectar los posibles obstáculos y evaluar las opciones de ajuste. Nuestras pruebas de ampliación abarcan diversas áreas, entre las que se encuentran: la ampliación del plano de control de OpenShift y de virtualización, el ajuste de la latencia de E/S de la carga de trabajo, la simultaneidad de las migraciones, la clonación de DataVolume y el ajuste de la creación de ráfagas de las máquinas virtuales.
Durante las pruebas, detectamos varios errores relacionados con la ampliación que, en última instancia, se tradujeron en mejoras, lo cual nos permitió llevar a cabo la siguiente fase de pruebas a una escala aún mayor. Todas las prácticas recomendadas relacionadas con la ampliación que identificamos durante el proceso se documentan en nuestra Guía general de ajuste y ampliación.
Rendimiento de los clústeres alojados
Un área de interés que comienza a adquirir relevancia para nosotros es el plano de control y el rendimiento de los clústeres alojados, en concreto el análisis de los planos de control alojados de los servidores dedicados (bare metal) locales y los clústeres alojados en OpenShift Virtualization, cuyo proveedor es KubeVirt.
Algunas de nuestras áreas de trabajo iniciales son las pruebas de ampliación de varias instancias de etcd (consulte la recomendación sobre almacenamiento en la sección Aspectos importantes), las pruebas de ampliación del plano de control alojado con una gran carga de trabajo de las API y el rendimiento de la carga de trabajo alojada cuando se gestionan los clústeres del plano de control en OpenShift Virtualization. Para obtener más información sobre uno de los principales resultados de este trabajo reciente, consulte nuestra guía de dimensionamiento de clústeres alojados.
Próximos pasos
Preste atención a las próximas publicaciones en las que se tratarán estas áreas de rendimiento y ampliación con más detalle, entre las que se incluirán un análisis más exhaustivo de la metodología orientativa para el dimensionamiento de clústeres alojados y recomendaciones detalladas para el ajuste de la migración de las máquinas virtuales.
Mientras tanto, seguiremos evaluando y analizando el rendimiento de las máquinas virtuales en OpenShift, superando nuevos límites de ampliación y centrándonos en detectar y corregir las regresiones antes de que las versiones lleguen a nuestros clientes.
Sobre el autor
Jenifer joined Red Hat in 2018 and leads the OpenShift Virtualization Performance team. Previously, she spent a decade working at IBM in the Linux Technology Center focused on Linux Performance.
Más como éste
Deja de administrar el pasado y comienza a forjar el futuro de TI
OpenShift: Integración consistente para la empresa híbrida
Navegar por canal

Automatización
Las últimas novedades en la automatización de la TI para los equipos, la tecnología y los entornos

Inteligencia artificial
Descubra las actualizaciones en las plataformas que permiten a los clientes ejecutar cargas de trabajo de inteligecia artificial en cualquier lugar

Nube híbrida abierta
Vea como construimos un futuro flexible con la nube híbrida

Seguridad
Vea las últimas novedades sobre cómo reducimos los riesgos en entornos y tecnologías

Edge computing
Conozca las actualizaciones en las plataformas que simplifican las operaciones en el edge

Infraestructura
Vea las últimas novedades sobre la plataforma Linux empresarial líder en el mundo

Aplicaciones
Conozca nuestras soluciones para abordar los desafíos más complejos de las aplicaciones
Virtualización
El futuro de la virtualización empresarial para tus cargas de trabajo locales o en la nube