
Red Hat OpenShift Virtualization helps to remove workload barriers by unifying virtual machine (VM) deployment and management alongside containerized applications in a cloud-native manner. As part of the larger Performance and Scale team, we have been deeply involved in the measurement and analysis of VMs running on OpenShift since the early days of the KubeVirt open source project and have helped to drive product maturity through new feature evaluation, workload tuning and scale testing. This article dives into several of our focus areas and shares additional insights into running and tuning VM workloads on OpenShift.
Tuning and scaling guides
Our team contributes to tuning and scaling documentation to help customers get the most out of their VM deployments. First, we have an overall tuning guide, which you can find in this knowledge base article. This guide covers recommendations for optimizing the Virtualization control plane for high VM "burst" creation rates and various tuning options at both the host and VM levels to improve workload performance.
Second, we published an in-depth reference architecture that includes an example OpenShift cluster, Red Hat Ceph Storage (RHCS) cluster and network tuning details. It also examines sample VM deployment and boot storm timings, I/O latency scaling performance, VM migration and parallelism and performing cluster upgrades at scale.
Team focus areas
The following sections provide an overview of some of our major focus areas and details about the testing we do to characterize and improve the performance of VMs running on OpenShift. Figure 1 below illustrates our focus areas.
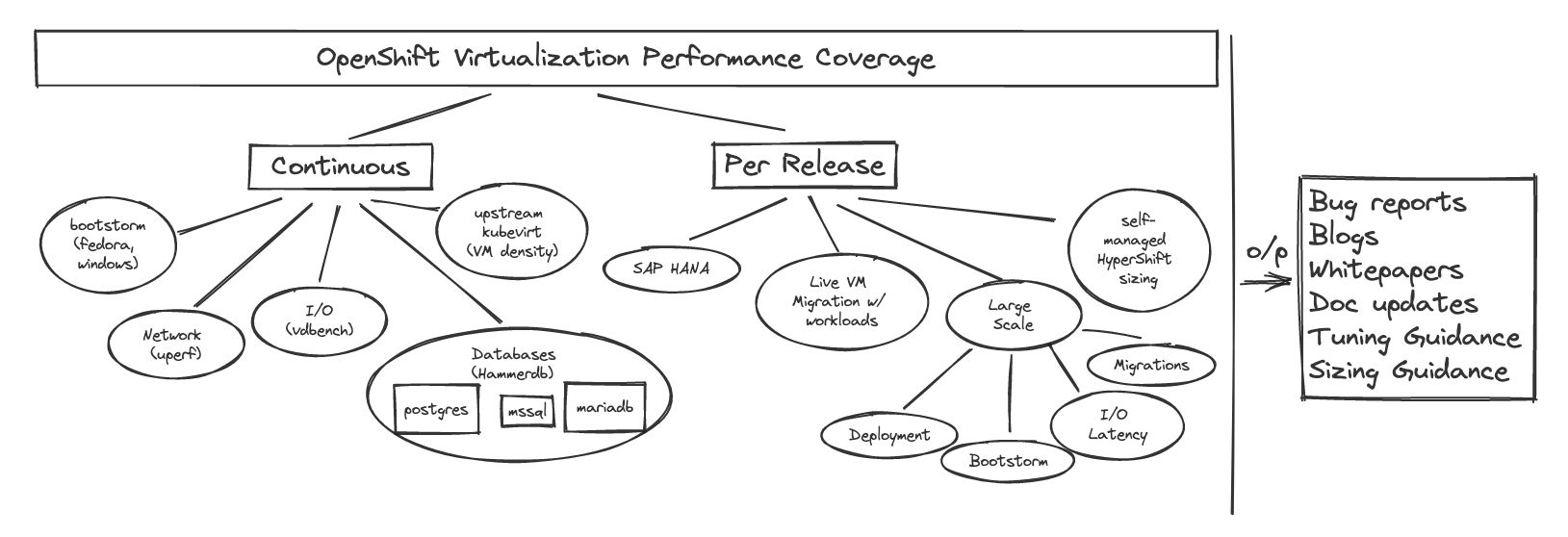
Figure 1: OpenShift Virtualization Performance focus areas
Workload performance
We spend a lot of time focusing on key workloads covering compute, networking and storage components to make sure we have broad coverage. This work includes gathering continuous baselines on different hardware models, updating results as newer releases come out and diving deep into various tuning options to achieve optimal performance.
One key workload focus area is database performance. We typically use HammerDB as the workload driver and focus on multiple database types, including MariaDB, PostgreSQL and MSSQL, so we can understand how databases with different characteristics perform. This template provides an example HammerDB VM definition.
Another major workload focus area is a high throughput in-memory database, SAP HANA, with a goal of performing within 10% of bare metal. We achieve this by applying some isolation-style tuning at both the host and VM layer, including using CPUManager, adjusting process affinity controlled by systemd, backing the VM with hugepages, and using SRIOV network attachments.
To further cover storage performance, we run a set of different I/O application patterns focusing on both IOPs (input/output operations per second) and latency using the Vdbench workload. The application patterns vary the block size, I/O operation type, size and number of files and directories, and adjust the mix of reads and writes. This allows us to cover various I/O behaviors to understand different performance characteristics. We also run another common storage microbenchmark, Fio, to measure various storage profiles. We test multiple persistent storage providers, but our main focus is OpenShift Data Foundation using Block mode RADOS Block Device (RBD) volumes in VMs.
We also focus on different types of microbenchmarks to assess other component performance to round out some of these more complex workloads. For networking, we typically use the uperf workload to measure both Stream and RequestResponse test configurations for various message sizes and thread counts, focusing on both the default podnetwork and other container network interface (CNI) types, such as Linux Bridge and OVN-Kubernetes additional networks. For compute tests, we use a variety of benchmarks, such as stress-ng, blackscholes, SPECjbb2005 and others, depending on the focus area.
Regression testing
Using an automation framework called benchmark-runner, we continuously run workload configurations and compare the results to known baselines to catch and fix any regressions in pre-release versions of OpenShift Virtualization. Since we care about virtualization performance, we run this continuous testing framework on bare metal systems. We compare workloads with similar configurations across pods, VMs and sandboxed containers to help us understand relative performance. This automation allows us to quickly install new pre-release versions of OpenShift and the operators we focus on, including OpenShift Virtualization, OpenShift Data Foundation, Local Storage Operator and OpenShift sandboxed containers. Characterizing the performance of pre-release versions multiple times each week allows us to catch any regressions early before they are released to customers and enables us to compare performance improvements over time as we update to newer releases with improved features.
We are always expanding our continuous automated workload coverage, but the current set of workloads we run regularly includes database benchmarks, compute microbenchmarks, uperf, Vdbench, Fio, and both VM "boot storm" and pod startup latency tests that exercise various areas of the cluster to measure how quickly a bulk number of pods or VMs can be started at once.
Migration performance
One advantage of using a shared storage provider that allows RWX access mode is that VM workloads can more seamlessly live migrate during cluster upgrades. We consistently work to improve the speed at which VMs can migrate without significant workload interruption. This involves testing and recommending migration limits and policies to provide safe default values and testing much higher limits to uncover migration component bottlenecks. We also measure the benefits of creating a dedicated migration network and analyze node-level networking and per-VM migration metrics to characterize migration progress over the network.
Scaling performance
We regularly test high-scale environments to uncover any bottlenecks and evaluate tuning options. Our scale testing involves areas ranging from OpenShift control plane scale to Virtualization control plane scale, workload I/O latency scaling, migration parallelism, DataVolume cloning and VM "burst" creation tuning.
Throughout this testing, we've discovered various scale-related bugs that ultimately led to improvements, allowing us to push the next round of scale tests even higher. Any scale-related best practices we find along the way we document in our general Tuning and Scaling Guide.
Hosted cluster performance
An emerging focus area for us is hosted control plane and hosted cluster performance, specifically examining on-premises bare metal hosted control planes and hosted clusters on OpenShift Virtualization, which uses the KubeVirt cluster provider.
Some of our initial work areas are scale testing multiple instances of etcd (see the storage recommendation in the Important section), hosted control plane scale testing with heavy API workload, and hosted workload performance when managing hosted control plane clusters on OpenShift Virtualization. Check out our hosted cluster sizing guidance to see one of the major outcomes of this recent work.
What's next
Keep an eye out for upcoming posts covering these performance and scale areas in more detail, including a deeper dive into hosted cluster sizing guidance methodology and in-depth VM migration tuning recommendations.
In the meantime, we will keep measuring and analyzing the performance of VMs on OpenShift, pushing new scale boundaries, and focusing on catching and fixing any regressions before releases reach the hands of our customers!
About the author
Jenifer joined Red Hat in 2018 and leads the OpenShift Virtualization Performance team. Previously, she spent a decade working at IBM in the Linux Technology Center focused on Linux Performance.
More like this
Taming existing tech: A strategic approach for insurance modernization
How Red Hat OpenShift 4.22 impacts enterprise AI’s bottom line
Browse by channel

Automation
The latest on IT automation for tech, teams, and environments

Artificial intelligence
Updates on the platforms that free customers to run AI workloads anywhere

Open hybrid cloud
Explore how we build a more flexible future with hybrid cloud

Security
The latest on how we reduce risks across environments and technologies

Edge computing
Updates on the platforms that simplify operations at the edge

Infrastructure
The latest on the world’s leading enterprise Linux platform

Applications
Inside our solutions to the toughest application challenges
Virtualization
The future of enterprise virtualization for your workloads on-premise or across clouds