With the release of Red Hat OpenStack Services on OpenShift, there is a major change in structure and architecture that changes how OpenStack services are deployed and managed. The OpenStack control panel has moved from traditional containers in Red Hat Enterprise Linux to an advanced pod-based architecture. In this blog post, we take a look at how to upgrade from Red Hat OpenStack Platform 17.1 to Red Hat OpenStack Services on OpenShift and how to get the most out of this transformative shift.
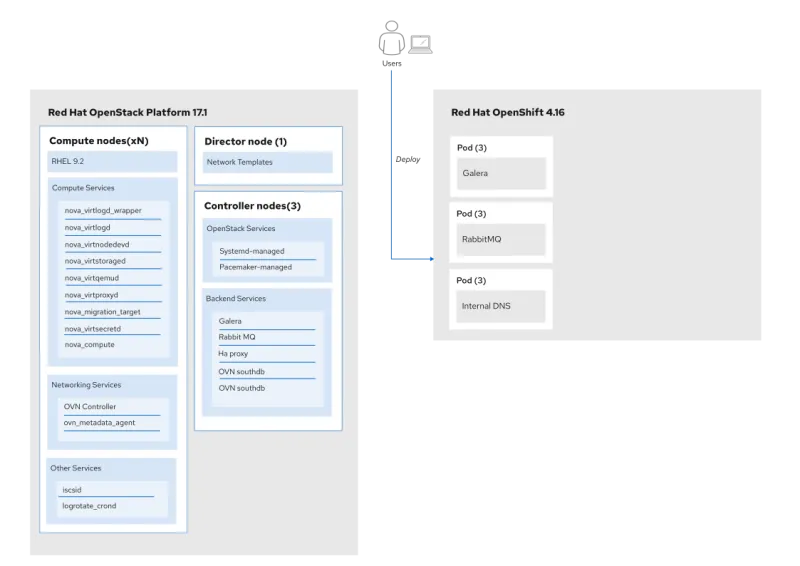
Red Hat OpenStack Services on OpenShift control plane on an OpenShift cluster
In the new architecture, the deployed OpenShift cluster is based on Red Hat CoreOS. Red Hat Openshift provides a powerful foundation for containerized applications and microservices. CoreOS is a lightweight Linux distribution optimized for containerized workloads, and now it serves as the operating system for the OpenShift cluster.
Within this OpenShift cluster, the Red Hat OpenStack Services on OpenShift control plane is deployed as pods, leveraging the flexibility and scalability of Kubernetes orchestration. Each component of the control plane, including services like Nova, Neutron, Cinder, and Keystone, is an individual pod, enabling efficient resource utilization and simple management.
This pod-based deployment model offers several advantages over a traditional containerized deployment. By leveraging Kubernetes primitives (such as deployments, services, and pods), you gain granular control over the lifecycle of OpenStack services. You get built-in capabilities for scaling, rolling updates, and even self-healing.
The data plane on Red Hat Enterprise Linux
While the control plane transforms within the OpenShift cluster, the data plane still uses Red Hat Enterprise Linux (RHEL). The data plane includes the virtualized infrastructure where Red Hat OpenStack Services on OpenShift instances are created and controlled.

Introducing the adoption mechanism
The transition from Red Hat OpenStack Platform 17.1 to Red Hat OpenStack Services on OpenShift demands a nuanced approach. Unlike traditional upgrades performed in place, this evolution necessitates a strategic adoption mechanism that acknowledges the fundamental architectural shift in the control plane.
Control plane transition: Side-by-side deployment
The heart of this migration lies in the control plane, where the shift from running as containers in RHEL to pods in OpenShift signifies a departure from conventional upgrade methodologies. To address the complexities involved, the adoption mechanism opts for a side-by-side deployment strategy. This approach allows for the coexistence of both the existing Red Hat OpenStack Platform 17.1 deployment and the new Red Hat OpenStack Services on OpenShift environment.
One of the significant advantages of maintaining both source and target control planes is the ability to revert to the Red Hat OpenStack Platform 17.1 environment in the event of an unexpected issue during the upgrade. This safety mechanism offers peace of mind to administrators and reduces risk.
Data plane upgrade: In-place migration
While the control plane undergoes a transformative shift through side-by-side deployment, the data plane upgrade takes a more traditional in-place migration approach. This distinction is crucial, as the data plane components encompass critical workloads and services that demand minimal disruption during the upgrade process.
In-place migration of the data plane ensures continuity and stability, allowing your organization to seamlessly transition data and workloads to the new environment without compromising performance or availability. By leveraging established best practices and automation tools, an administrator can streamline the upgrade process, minimize downtime, and maximize operational efficiency.
Key steps in the adoption mechanism
The new OpenShift CP for Red Hat OpenStack Services on OpenShift is based on Red Hat OpenShift 4.16 and the Red Hat OpenStack Services on OpenShift operators come already installed. Including the following: NMstate, MetalLB, Cert-manager, and Baremetal Operator (Metal3).

Adoption preparation
In the preparation state of adoption, operators extract the following information from the existing Red Hat OpenStack Platform 17.1 environment:
- Red Hat OpenStack Platform 17.1 service configuration: Injected into the control plane during each service adoption
- Networking configuration: Addresses allocated in the overcloud and
os-net-confignetworking templates are injected in the dataplane custom resources
Those configurations are injected into the control plane during each service adoption, and during the data plane adoption.

Finally, define a group of shell variables with information about the original database, compute service cell mappings, and hostnames of the compute services. This information is used later for verification purposes during the adoption process.

Migrating databases to the control plane
In its initial state, the operator creates the OpenStackControlPlane custom resource (CR) with basic backend services deployed and all OpenStack services disabled. This is the foundation of the control plane.
Before you start the database migration, you must stop Red Hat OpenStack Services on OpenShift services on the controller nodes. This is a vital step to avoid inconsistencies in the data migrated for the data plane adoption procedure caused by resource changes after the database has been copied to the new deployment.
Some services are easy to stop because they only perform short asynchronous operations, but other services are difficult to stop gracefully because they perform synchronous or continuous operations that you might want to complete instead of aborting them.
Next, the operator moves the databases from the original OpenStack deployment to the MariaDB instances in the OpenShift cluster. The next steps are:
- Deploy the adoption helper pod mariadb-copy-data
- Create a dump of the original databases
- Restore the databases from
.sqlfiles into the control plane MariaDB
Finally the mariadb-copy-data pod needs to be deleted.

OVN database migration follows a similar process with the following steps:
- Deploy the adoption helper
pod ovn-copy-data - Create a back-up of the OVN databases
- Start the control plane OVN database services prior to import, keeping
northd/ovn-controllerstopped - Upgrade database schema for the backup files
- Restore database backup to the control plane OVN database servers
- Finally, you can start
ovn-northdservice that keeps the OVN northbound and southbound databases in sync. Also, enableovn-controller

Adopting Red Hat OpenStack Services on OpenShift control plane services
The next step is to deploy Red Hat OpenStack Services on OpenShift services one by one. In this example, the Identity Service (Keystone adoption) process is:
- Patch
OpenStackControlPlaneto deploy the Identity service - During keystone deployment, the
keystone-db-syncpod is created. This pod detects that the database schema is from a previous version, and performs the fast-forward process through 4 releases: Wallaby → Xena → Yoga → Zed → Antelope

- After
keystone-db-syncexecution, the Keystone Database is using the Antelope DB schema - The Operator uses the
openstackclientpod to executeopenstackcommands to clean up the services and endpoints that still point to the old control plane

All remaining Red Hat OpenStack Services on OpenShift services of the control plane follow a similar process.
Should you encounter a problem during the adoption of the Red Hat OpenStack Services on OpenShift control plane services, you can roll back the control plane adoption. The rollback procedure consists of the following steps:
- Restore the functionality of the source control plane
- Remove the partially or fully deployed destination control plane
Adopting the data plane
The second part of the adoption process is the adoption of the data plane. First, you must stop the remaining backend services in the control plane.

Before the adoption of the compute services, the operator must create an OpenStackDataplaneDeployment resource. This deployment should include the pre-adoption-validation playbook packaged as an OpenStackDataplaneService.
Following the deployment, an Ansible Execution Environment job is automatically triggered. This job executes the following validation checks:
- Hostname validation
- Kernel argument validation
- Tuned profile check

Here are the steps required:
- Configure IP address management (IPAM) NetConfig resources using the network configuration gathered in the first step, and any EDPM (External Dataplane Management) related Custom Resources used in a Greenfield deployment (secrets)
- Create a
nova-compute-extra-configservice wheredisable_compute_service_check_for_ffu=true. This is only to be enabled to facilitate a Fast-Forward upgrade (FFU) where new control services are being started before compute nodes have been able to update their service record. In an FFU, the service records in the database are more than one version old until the compute nodes start up, but control services need to be online first - Deploy the
OpenStackDataPlaneNodeSetandOpenStackDataPlaneDeploymentCustom Resources. Ansible Execution Environment (EE) jobs are launched to execute playbooks for every service: bootstrap, download-cache, configure-network, and so on - The bootstrap service points the RHEL system to RHOSO18 repositories, and installs the minimum required packages like
openstack-selinux OpenStackDataPlaneServicesreplaces the storage, compute and networking OSP 17.1 containers with RHOSO 18 containers
Finally, remove pre-fast-forward upgrade workarounds for the compute control plane services by setting the flag disable_compute_service_check_for_ffu=false, and run the compute database online migrations to complete the fast-forward upgrade.
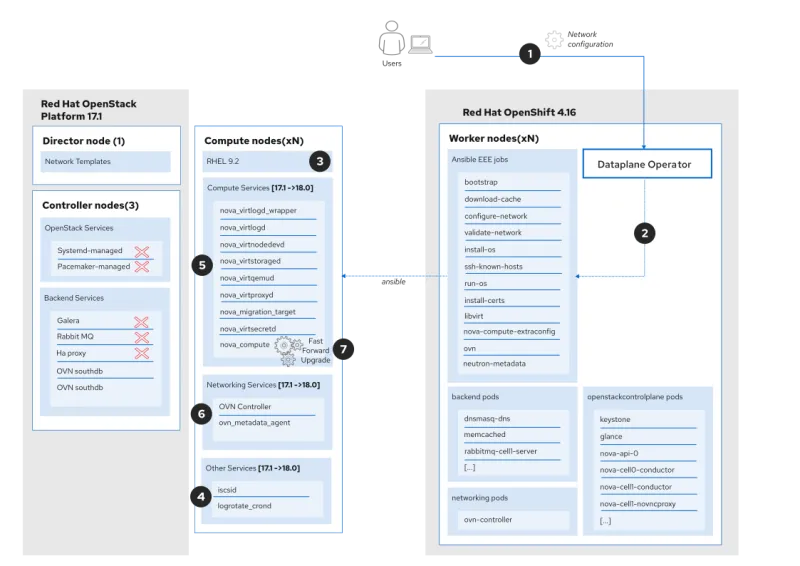
At this stage, all Red Hat OpenStack Platform content in the cluster has been upgraded to Red Hat OpenStack Services on OpenShift. You have a supported environment.
Conclusion
The transition from Red Hat OpenStack Platform 17.1 to Red Hat OpenStack Services on OpenShift represents a pivotal moment in the evolution of cloud infrastructure. By embracing a pod-based control plane within an OpenShift cluster on CoreOS, and maintaining a robust data plane on Red Hat Enterprise Linux, you can unlock unprecedented levels of agility, scalability, and resilience. With Red Hat, you're ready to embark on a journey towards a future where cloud infrastructure is not just a platform, but a catalyst for innovation and transformation.
About the author
More like this
F5 BIG-IP Virtual Edition is now validated for Red Hat OpenShift Virtualization
More than meets the eye: Behind the scenes of Red Hat Enterprise Linux 10 (Part 4)
Can Kubernetes Help People Find Love? | Compiler
Scaling For Complexity With Container Adoption | Code Comments
Browse by channel

Automation
The latest on IT automation that spans tech, teams, and environments

Artificial intelligence
Explore the platforms and partners building a faster path for AI

Cloud services
Get updates on our portfolio of managed cloud services

Security
Explore how we reduce risks across environments and technologies

Edge computing
Updates on the solutions that simplify infrastructure at the edge

Infrastructure
Stay up to date on the world’s leading enterprise Linux platform

Applications
The latest on our solutions to the toughest application challenges

Original shows
Entertaining stories from the makers and leaders in enterprise tech