

Einleitung
DR-Strategien für virtuelle Maschinen (VMs) auf Red Hat OpenShift sind unerlässlich, um die Business Continuity auch bei ungeplanten Ausfallzeiten aufrechtzuerhalten. Wenn Unternehmen kritische Workloads zu Kubernetes-Plattformen migrieren, wird die Fähigkeit, diese Workloads schnell und zuverlässig wiederherzustellen, zu einer wichtigen operativen Anforderung.
Während kurzlebige, zustandslose VMs in cloudnativen Umgebungen mittlerweile üblich sind, bleiben die meisten VM-Workloads in Unternehmen zustandsbehaftet. Diese VMs erfordern persistenten Block-Storage, der bei Neustarts oder Migrationen wieder zugeordnet werden kann. Daher bringt Disaster Recovery für zustandsbehaftete VMs Herausforderungen mit sich, die sich erheblich von denen unterscheiden, die sich mit früheren Kubernetes-DR-Patterns (Spazzoli, 2024) lösen lassen. Diese konzentrierten sich in der Regel auf zustandslose, containerbasierte Anwendungen.
In diesem Blog-Beitrag werden verschiedene Anforderungen für zustandsbehaftete VMs behandelt. Zunächst wird untersucht, wie sich die Wahl der Cluster- und Storage-Architektur auf die Durchführbarkeit von Failover, das Replikationsverhalten und die RPO/RTO-Ziele auswirken. Anschließend wird die Orchestrierungsschicht untersucht und gezeigt, wie Kubernetes-native Tools wie Red Hat Advanced Cluster Management, Helm, Kustomize und GitOps-Pipelines die Platzierung und Wiederherstellung der Workloads steuern. Abschließend wird in diesem Blog-Beitrag der Frage nachgegangen, wie moderne Storage-Plattformen, die sowohl Block-Storage als auch Kubernetes-Manifeste replizieren, den Wiederherstellungsprozess optimieren und die Infrastruktur mit Automatisierung auf Anwendungsebene verbinden können.
Unsere Terminologie
Zunächst sollten wir einige wichtige Begriffe definieren:
Disaster:
Im hier erwähnten Kontext bezieht sich der Begriff „Disaster“ auf „Standortverlust“. Bei Disaster Recovery (DR) geht es immer darum, die Unterbrechungszeit eines Unternehmensservices zu minimieren. Wenn Sie also einen Standort verlieren, müssen Sie Ihre Disaster Recovery-Pläne so schnell und effizient wie möglich am alternativen Standort umsetzen.
Hinweis: Die Inkraftsetzung eines Disaster Recovery-Plans erfolgt nicht nur, wenn ein Standort verloren geht. Bei Ausfall einer wichtigen Komponente – was die Verlagerung einzelner Unternehmensdienste auf den Ausweichstandort während der Wiederherstellung der ausgefallenen Komponente erfordert – ist es üblich, DR-Pläne für einzelne Unternehmensdienste umzusetzen.
Komponentenausfall:
Ein Komponentenausfall ist ein Ausfall in einem oder mehreren Subsystemen, der sich auf einen Teil der Geschäftsanwendungen in Ihrem Unternehmen auswirkt. Dieser Fehlermodus erfordert, dass Sie die Verarbeitung entweder auf ein anderes System am primären Standort übertragen oder aber individuelle Disaster Recovery-Pläne umsetzen, um die Verarbeitung der Geschäftsanwendung an einen sekundären Standort zu verlagern.
Recovery Point Objective (RPO):
RPO ist definiert als die maximale Datenmenge (gemessen an der Zeit), die nach der Wiederherstellung eines Disaster- oder Ausfall-Events verloren gehen kann, bevor der Datenverlust das für ein Unternehmen akzeptable Maß überschreitet.
Recovery Time Objective (RTO):
RTO ist definiert als die maximale Zeitspanne, für die ein Unternehmen die Nichtverfügbarkeit eines Dienstes tolerieren kann. Obwohl sich die Wahl der verschiedenen Architekturen auf die RTO auswirkt, werden diese Überlegungen in diesem Blog-Beitrag nicht im Detail behandelt.
Metro-DR im Vergleich zu Regional-DR:
Es gibt 2 Arten von DR: Metro-DR und Regional-DR.
- Metro-DR eignet sich für Situationen, in denen Ihre Rechenzentren nah genug beieinander sind und die Netzwerk-Performance eine synchrone Datenreplikation ermöglicht. Die synchrone Replikation hat den Vorteil, dass Sie einen RPO von null erreichen können.
- Regional-DR eignet sich für Situationen, in denen Sie gezwungen sind, die asynchrone Replikation zu verwenden, da die Rechenzentren zu weit voneinander entfernt sind, um die synchrone Replikation zu unterstützen. Bei der asynchronen Replikation entsteht mit Sicherheit ein gewisser Datenverlust. Das Ausmaß dieses Datenverlusts spielt für diesen Blog-Beitrag keine Rolle.
Hinweis: Wenn Ihre Storage-Infrastruktur keine synchrone Replikation unterstützt, dann würde eine Regional-DR-Architektur für Ihr Metro-DR verwendet.
Restart Storm:
Ein Restart Storm ist ein Event, das auftritt, wenn die Anzahl der VMs, die Sie gleichzeitig neu starten möchten, so groß ist, dass der Hypervisor und die unterstützende Infrastruktur dies nicht mehr bewältigen können. Das führt dazu, dass entweder keine VMs neu gestartet werden können oder die VM-Neustarts um einiges länger dauern, als vertretbar ist. Dies ist mit einem nicht böswilligen Denial of Service-Angriff vergleichbar.
Architekturansätze für Business Continuity
Es gibt verschiedene Ansätze für Business Continuity und Disaster Recovery. Eine allgemeine Diskussion zu diesem Thema finden Sie im Whitepaper Cloud Native Disaster Recovery for Stateful Workloads (Spazzoli, 2024) der Cloud Native Computing Foundation (CNCF). Im Allgemeinen gibt es 4 archetypische Ansätze für die DR, die im folgenden Diagramm dargestellt sind (eine ausführliche Erläuterung für jeden dieser Ansätze ist im Whitepaper enthalten):
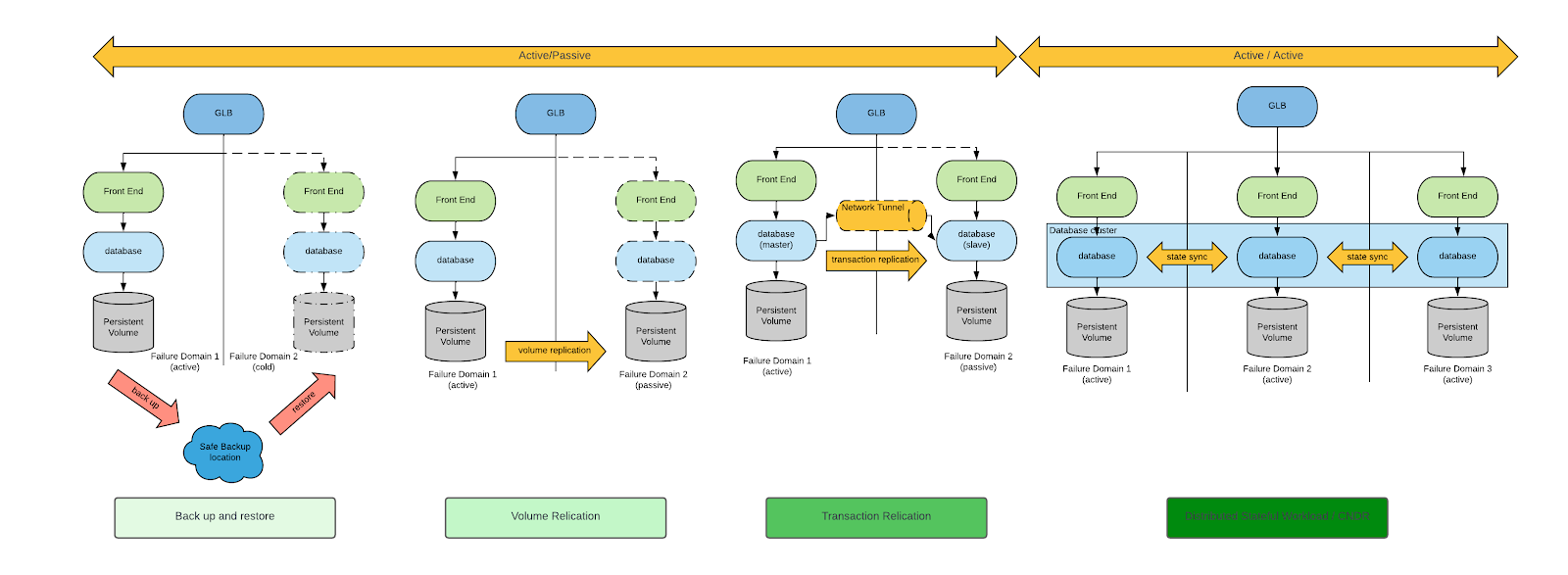
In Bezug auf die Disaster Recovery-Anforderungen für VMs sind Backup und Wiederherstellung sowie Volume-Replikation die einzigen geeigneten DR-Patterns.
Sowohl Backup und Wiederherstellung als auch Volume-Replikation sind praktikable Ansätze, jedoch minimieren DR-Ansätze auf Basis von Volume-Replikation RPO und RTO. Aus diesem Grund konzentrieren wir uns nur auf DR-Ansätze, die auf Volume-Replikation basieren.
Nachdem wir unseren Analysebereich eingegrenzt haben, erläutern wir 2 Architekturansätze für Disaster Recovery, die sich architektonisch durch die Art der Volume-Replikation unterscheiden:
- Unidirektionale Replikation
- Symmetrische Replikation oder bidirektionale Replikation
Unidirektionale Replikation
Bei der unidirektionalen Replikation werden Volumes von einem Rechenzentrum in ein anderes repliziert, nicht aber umgekehrt. Die Replikationsrichtung wird über das Storage-Array gesteuert, und die Volume-Replikation kann entweder synchron oder asynchron sein. Die Auswahl hängt von der Kapazität des Storage-Arrays und der Latenz zwischen den beiden Rechenzentren ab. Die asynchrone Replikation eignet sich für Rechenzentren mit einer hohen Latenz untereinander und befindet sich sehr wahrscheinlich in derselben geografischen Weltregion, aber nicht im selben Metropolraum.
Aus der Perspektive der Architektur ähnelt die unidirektionale Replikation der folgenden Abbildung:
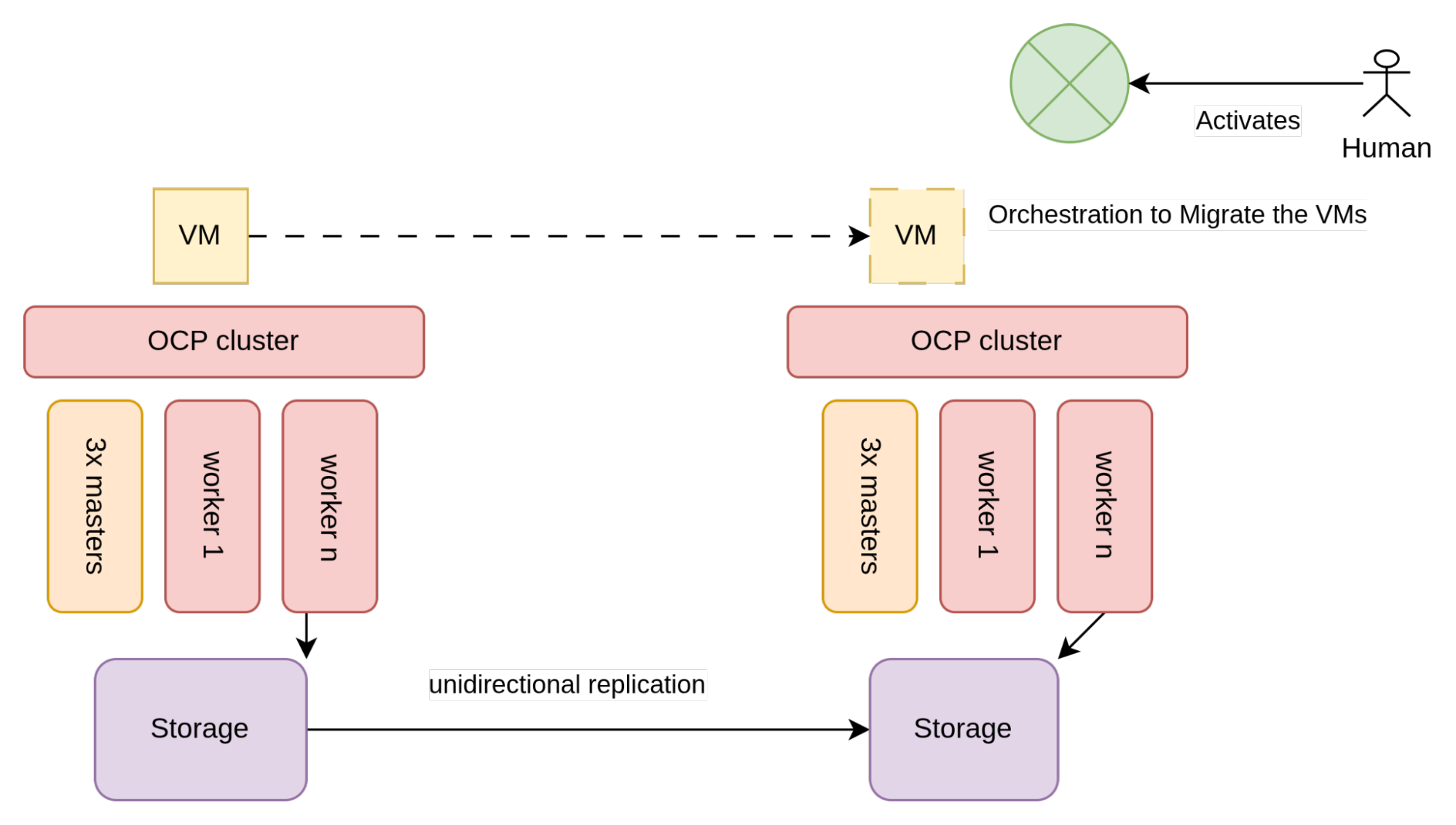
Wie in Abbildung 2 dargestellt, ist der von den VMs (in der Regel SAN-Arrays) verwendete Storage so konfiguriert, dass er eine unidirektionale Replikation ermöglicht.
In jedem Rechenzentrum sind 2 verschiedene OpenShift Cluster vorhanden, die jeweils mit dem lokalen Storage-Array verbunden sind. Die Cluster sind sich gegenseitig nicht bekannt, sodass die einzigen Einschränkungen für die Implementierung dieser Architektur vom Storage-Anbieter vorgegeben werden, insbesondere durch die Anforderungen, die für eine unidirektionale Replikation erfüllt sein müssen.
Überlegungen zur unidirektionalen Volume-Replikation
Die Volume-Replikation ist in der Kubernetes-CSI-Spezifikation nicht standardisiert. Aus diesem Grund haben Storage-Anbieter proprietäre Custom Resource Definitions (CRDs) erstellt, um diese Funktion zu ermöglichen. Wir erleben aktuell Anbieter mit 3 Entwicklungsstufen, die über diese Funktion verfügen:
- Die Volume-Replikationsfunktion ist auf der CSI-Ebene nicht verfügbar, oder sie ist in einer Weise verfügbar, die die Erstellung einer ordnungsgemäßen Disaster Recovery-Orchestrierung nicht ermöglicht, ohne die Storage Array-API direkt aufzurufen.
- Die Funktion zur Volume-Replikation ist auf CSI-Ebene verfügbar
- Die Funktion zur Replikation von Volumes ist verfügbar, und der Anbieter managt auch die Wiederherstellung der Namespace-Metadaten (d. h. der VMs und anderer im Namespace vorhandener Manifeste).
Angesichts dieser Fragmentierung ist es nicht einfach, einen anbieterunabhängigen Disaster Recovery-Prozess für eine regionale Disaster Recovery zu schreiben. Wie viel für eine ordnungsgemäße Disaster Recovery-Orchestrierung geschrieben werden muss, hängt vom jeweiligen Storage-Anbieter ab.
Sehen wir uns das Verhalten dieser Architektur bei verschiedenen Fehlermodi an: OpenShift-Knotenausfall, Storage Array-Ausfall (Komponentenfehler) und Ausfall des gesamten Rechenzentrums (dies ist das eigentliche Disaster Recovery-Szenario).
Ausfall des OpenShift-Knotens
Bei einem Ausfall des OpenShift-Knotens (Komponente) ist der OpenShift Virtualization-Scheduler dafür verantwortlich, die VM automatisch auf dem nächsten, am besten geeigneten Knoten im Cluster neu zu starten. In diesem Szenario sollte keine weitere Aktion erforderlich sein.
Storage Array-Ausfall
Wenn ein Storage Array ausfällt, fallen auch alle VMs aus, die von dem Storage Array abhängig sind. In diesem Szenario muss der Disaster Recovery-Prozess durchgeführt werden. (Die erforderlichen Schritte finden Sie im Abschnitt Disaster Recovery-Prozess.)
Ausfall des Rechenzentrums
Bei Ausfall eines Rechenzentrums muss ein Disaster Recovery-Prozess durchgeführt werden, um die VMs im Rechenzentrum neu zu starten, die nicht vom Ausfall betroffen sind. Automatisierung spielt hier eine Schlüsselrolle. Der Prozess wird jedoch in der Regel von einer Person im Rahmen des Managements von schwerwiegenden Vorfällen initiiert. Der folgende Abschnitt bietet einen Überblick über die erforderlichen Schritte.
Disaster Recovery-Prozess
DR-Verfahren können sehr kompliziert werden, aber in einfachen Worten sollte ein DR-Prozess Folgendes berücksichtigen:
- Bei VMs, die Teil derselben Anwendung sind, sollten die Volumes konsistent repliziert werden. Dies bedeutet in der Regel, dass die Volumes dieser VMs Teil derselben Konsistenzgruppe sind.
- Es muss möglich sein, zu steuern, ob Volumes in einer Konsistenzgruppe repliziert werden sollen und in welche Richtung. Unter normalen Umständen werden Volumes vom aktiven Standort zum passiven Standort repliziert. Während eines Failovers werden Volumes nicht repliziert. Während der Vorbereitungsphase für das Failback werden Volumes vom passiven Standort zum aktiven Standort repliziert. Während des Failbacks werden Volumes nicht repliziert.
- Die VMs im anderen Rechenzentrum sollten neu gestartet werden können, und sie müssen eine Verbindung zum replizierten Storage-Volume herstellen können.
- Der VM-Neustart muss möglicherweise gedrosselt werden, um einen Restart Storm zu vermeiden. Darüber hinaus ist es häufig wünschenswert, die VM-Neustartreihenfolge zu priorisieren, damit die wichtigsten Anwendungen zuerst gestartet werden, oder sicherzustellen, dass Komponenten wie Datenbanken vor den Services gestartet werden, die auf sie angewiesen sind.
Kostenüberlegungen
Je nachdem, wie der OpenShift Cluster konfiguriert ist, kann er als „Warm“ oder „Hot“ DR-Standort betrachtet werden. Hot-Standorte benötigen eine vollständige Subskription, Warm-Standorte dagegen nicht (was potenziell Kosteneinsparungen ermöglicht).
Wenn am Disaster Recovery-Standort keine aktiven Workloads ausgeführt werden, kann dieser als „warm“ betrachtet werden. Insbesondere lassen sich persistente Volumes (PVs), persistente Volume Claims (PVCs) und sogar nicht laufende VMs konfigurieren, die im Falle einer Störung startbereit sind und dennoch als Warm-Standort dienen.
Symmetrisch aktiv/passiv
Es ist nicht gängige Praxis, dass sich 100 % der Workloads am aktiven Standort befinden. Stattdessen arbeiten Unternehmen mit einer Verteilung von bis zu jeweils 50 % auf primäre und sekundäre Rechenzentren. Dies ist ein praktischer Ansatz, der sicherstellt, dass bei einem Ausfall nie alle Services auf einmal ausfallen. Zudem wird der allgemeine Wiederherstellungsaufwand entsprechend reduziert.
Bei der Verteilung aktiver VMs in den einzelnen Rechenzentren wird jede Seite so konfiguriert, dass ein Failover zur anderen Seite durchgeführt werden kann. Dieser Aufbau wird manchmal auch als symmetrisch Aktiv/Passiv bezeichnet.
Der symmetrische Aktiv/Passiv-Ansatz funktioniert mit OpenShift Virtualization und der oben untersuchten Architektur. Denken Sie daran, dass bei symmetrischem Aktiv/Passiv beide Rechenzentren als aktiv betrachtet werden und daher alle OpenShift-Knoten abonniert werden müssen.
Symmetrische Replikation
Bei der symmetrischen Replikation werden Volumes synchron und in beide Richtungen repliziert. Infolgedessen können beide Rechenzentren über aktive Volumes verfügen und Schreibvorgänge auf diese Volumes vornehmen. Damit dies möglich ist, muss eine Organisation über 2 Rechenzentren verfügen, deren Netzwerklatenz sehr gering ist (etwa 5 ms). Dies ist in der Regel möglich, wenn sich die beiden Rechenzentren im selben Metropolraum befinden. Daher wird diese Architektur auch als Metro-DR bezeichnet. Unter diesen Umständen kann die folgende Architektur verwendet werden:

In dieser Architektur ist der von den VMs verwendete Storage (in der Regel ein SAN-Array) so konfiguriert, dass eine symmetrische Replikation zwischen den beiden Rechenzentren durchgeführt wird.
Dadurch wird ein logisches Storage-Array erstellt, das sich über die beiden Rechenzentren erstreckt. Um eine symmetrische Replikation zu ermöglichen, ist ein „Witness Site“ (Witness-Standort) erforderlich, der als unabhängiger Arbitrator fungiert, um „Split Brain“-Szenarien im Falle eines Netzwerk- oder Standortausfalls zu verhindern.
Die Witness-Site muss (im Hinblick auf die Latenz) nicht so nah wie die beiden Hauptrechenzentren liegen, da sie für die Erstellung eines Quorums und für Split Brain-Szenarien verwendet wird. Die Witness-Site muss eine unabhängige Verfügbarkeitszone sein, darf keine Anwendungs-Workloads enthalten und muss keine große Kapazität haben. Sie sollte aber dieselbe Servicequalität wie die anderen Rechenzentren hinsichtlich der Abläufe aufweisen (wie physisch/logisch, Sicherheit, Power Management, Kühlung).
Da sich der Storage über mehrere Rechenzentren erstreckt, erweitert sich auch OpenShift. Um dies in einer hochverfügbaren Architektur zu implementieren, sind 3 Verfügbarkeitszonen (Standorte) für die OpenShift-Control Plane erforderlich. Dies liegt daran, dass die interne etcd-Datenbank von Kubernetes mindestens 3 Ausfall-Domains erfordert, um ein zuverlässiges Quorum aufrechtzuerhalten. Dies wird in der Regel implementiert, indem die Storage Witness-Site für einen der Control Plane-Knoten genutzt wird.
Die meisten SAN-Anbieter (Storage Area Network) unterstützen die symmetrische Replikation für ihre Storage-Arrays. Allerdings bieten nicht alle Anbieter diese Funktion auf CSI-Ebene. Unter der Annahme, dass ein Storage-Anbieter die symmetrische Replikation auf CSI-Ebene unterstützt, und davon ausgehend, dass die erforderlichen Voraussetzungen erfüllt und Konfigurationen vorhanden sind, wird beim Erstellen eines PVC eine Multipath Logical Unit Number (LUN) bereitgestellt. Diese LUN enthält Pfade zu beiden Rechenzentren. Daher müssen alle OpenShift-Knoten so konfiguriert werden, dass sie eine Konnektivität zu beiden Storage-Arrays ermöglichen. Das Multipath-Gerät wird in der Regel entweder mit einer ALUA-Konfiguration (Asymmetric Logical Unit Access) (Pearson IT Certification, 2024) (d. h. aktiv/passiv, wobei der aktive Pfad derjenige zum nächsten Array ist) oder mit einem aktiv/aktiv-Pfad mit unterschiedlichen Gewichtungen erstellt, wobei das am nächsten liegende Array hohe Gewichtungen aufweist.
Einige Anbieter lassen diese Architektur sogar zu, wenn die Fiber Channel-Verbindungen nicht „einheitlich“ sind, d. h. Knoten an einem Standort können nur eine Verbindung zum lokalen Storage-Array herstellen. In diesem Fall wird die ALUA-Konfiguration natürlich nicht erstellt.
Diese Cluster-Topologie trägt zum Schutz sowohl vor Komponentenausfällen als auch vor Notfällen bei. Sehen wir uns das Verhalten dieser Architektur bei verschiedenen Fehlermodi an.
Ausfall des OpenShift-Knotens
Im Falle eines Knotenausfalls (Komponente) ist der OpenShift Virtualization Scheduler dafür verantwortlich, die VM automatisch auf dem nächsten, am besten geeigneten Knoten im Cluster neu zu starten. In diesem Szenario sollte keine weitere Aktion erforderlich sein.
Storage Array-Ausfall
Multipath-LUNs unterstützen die Servicekontinuität, falls eines der beiden Storage Arrays ausfällt oder zur Wartung offline geht. In einem Szenario mit einheitlicher Konnektivität wird der passive oder weniger gewichtete Pfad der Multipath-LUNs verwendet, um die VM mit den anderen Arrays zu verbinden. Dieser Ausfall ist für die VMs vollständig transparent und kann zu einem leichten Anstieg der Disk-I/O-Latenz führen. In einem Szenario mit uneinheitlicher Konnektivität muss die VM zu einem Knoten mit Konnektivität migriert werden.
Ausfall des Rechenzentrums
Wenn ein gesamtes Rechenzentrum nicht mehr verfügbar ist, wird dies von dem erweiterten OpenShift als Ausfall mehrerer Knoten gleichzeitig wahrgenommen. OpenShift beginnt mit der Planung von VMs für Knoten im anderen Rechenzentrum, wie im Abschnitt zu Ausfällen von OpenShift-Knoten beschrieben.
Vorausgesetzt, es ist genügend freie Kapazität für die Migration von Workloads vorhanden, werden schließlich sämtliche Maschinen im anderen Rechenzentrum neu gestartet. VMs, die neu gestartet wurden, haben einen RPO von genau null und einen RTO aus der Summe der folgenden Zeitenspannen:
- Die Zeitspanne, die OpenShift benötigt, um zu erkennen, dass sich Knoten in einem nicht bereiten Zustand befinden
- Die Zeitspanne, die für das Fencing der Knoten benötigt wird
- Die Zeitspanne, die für den Neustart der VMs benötigt wird
- Die Zeitspanne, die bis zum Abschluss des VM-Boot-Vorgangs benötigt wird
Dieser DR-Mechanismus ist im Wesentlichen vollständig autonom und erfordert kein menschliches Eingreifen. Das ist vielleicht nicht immer wünschenswert. Um einen Restart Storm zu vermeiden, ist es häufig besser zu steuern, welche VMs neu gestartet werden und wann dieser Prozess eingeleitet wird.
Überlegungen zum Metro-DR
Im Folgenden finden Sie einige der Überlegungen zu diesem Ansatz:
- Da VMs in der Regel mit VLANs verbunden sind, müssen die VLANs auch zwischen den Metro-Rechenzentren verteilt sein, damit sie zwischen Rechenzentren verschoben werden können. In einigen Fällen kann dies unerwünscht sein.
- Häufig befindet sich das Verwaltungsnetzwerk des Witness-Standorts (OpenShift-Knotennetzwerk) nicht im selben L2-Subnetz wie das Verwaltungsnetzwerk der Metro-Rechenzentren.
- Manche betrachten dies nicht als vollständige Disaster Recovery-Lösung, da die OpenShift-Control Plane und die Storage Array-Control Plane 2 Single Points of Failure (SPOF) darstellen. Dieser SPOF ist im logischen Sinne beabsichtigt, da aus physischer Perspektive natürlich Redundanz vorhanden ist. Es stimmt jedoch, dass ein einzelner fehlerhafter Befehl in OpenShift oder dem Storage Array theoretisch die gesamte Umgebung löschen kann. Aus diesem Grund wird diese Architektur manchmal für die wichtigsten Workloads mit einer traditionelleren, regionalen Disaster Recovery-Architektur verkettet.
- Bleibt OpenShift in einer DR-Situation sich selbst überlassen, plant es automatisch alle VMs im betroffenen Rechenzentrum gleichzeitig auf das intakte Rechenzentrum um. Dies kann zu einem Phänomen führen, das als „Restart Storm“ bezeichnet wird. Es gibt eine Reihe von Kubernetes-Funktionen, die dieses Risiko mindern, indem sie kontrollieren, welche Anwendungen wann ein Failover durchführen. Das Konzept der Restart Storms wird in späteren Abschnitten erläutert.
Kostenüberlegungen:
Für die symmetrische Replikation muss für beide Standorte eine vollständige Subskription bestehen, da sie zu einem einzelnen aktiven OpenShift-Cluster gehören. Wie bei der unidirektionalen Replikation müssen die einzelnen Standorte zu 100 % überprovisioniert sein, damit ein Failover von 100 % des anderen Standorts möglich ist.
Fazit
Die Entscheidung zwischen unidirektionalen und symmetrischen Replikationsarchitekturen schafft die Grundlage für die gesamte DR-Strategie in OpenShift Virtualization. Bei jedem Modell gibt es Kompromisse zwischen operativer Komplexität, Infrastrukturkosten, RPO-/RTO-Garantien und Automatisierungspotenzial. Unabhängig davon, ob Sie sich für ein Dual Cluster- oder ein Extended Cluster-Design entscheiden, muss die Basisarchitektur auf die Erwartungen in Bezug auf die Business Continuity und die Infrastrukturbeschränkungen abgestimmt sein. Mit dieser Grundlage verlagert sich der Schwerpunkt im 2. Teil von der Infrastruktur auf die Orchestrierung. Dabei wird über den Storage hinaus untersucht, wie VMs unter Disaster-Bedingungen platziert, neu gestartet und gesteuert werden.
Produkttest
Red Hat OpenShift Virtualization Engine | Testversion
Über die Autoren
Bryon is a skilled infrastructure and software engineering specialist with deep expertise in AI/ML, Kubernetes, OpenShift, cloud-native architecture, and enterprise networking. With a strong background in storage technologies, infrastructure, and virtualisation, Bryon works across domains including system administration, AI model deployment, and platform engineering. He is proficient in C#, Golang and Python, experienced in container orchestration, and actively contributes to Red Hat-based solutions. Passionate about education and enablement, Bryon frequently develops technical workshops and training programs, particularly in AI/ML and DevOps. He is also a practising musician, blending his technical acumen with creative expression.
Raffaele is a full-stack enterprise architect with 20+ years of experience. Raffaele started his career in Italy as a Java Architect then gradually moved to Integration Architect and then Enterprise Architect. Later he moved to the United States to eventually become an OpenShift Architect for Red Hat consulting services, acquiring, in the process, knowledge of the infrastructure side of IT.
Currently Raffaele covers a consulting position of cross-portfolio application architect with a focus on OpenShift. Most of his career Raffaele worked with large financial institutions allowing him to acquire an understanding of enterprise processes and security and compliance requirements of large enterprise customers.
Raffaele has become part of the CNCF TAG Storage and contributed to the Cloud Native Disaster Recovery whitepaper.
Recently Raffaele has been focusing on how to improve the developer experience by implementing internal development platforms (IDP).
Ähnliche Einträge
KI-Bedrohungen abwehren: Agile Security für Unternehmen
Flut an KI-generierte Sicherheitsschwachstellen erfordert menschliche IT-Expertise
Untangling Networks | Compiler
Technically Speaking | Defining sovereign AI with open source
Nach Thema durchsuchen

Automatisierung
Das Neueste zum Thema IT-Automatisierung für Technologien, Teams und Umgebungen

Künstliche Intelligenz
Erfahren Sie das Neueste von den Plattformen, die es Kunden ermöglichen, KI-Workloads beliebig auszuführen

Open Hybrid Cloud
Erfahren Sie, wie wir eine flexiblere Zukunft mit Hybrid Clouds schaffen.

Sicherheit
Erfahren Sie, wie wir Risiken in verschiedenen Umgebungen und Technologien reduzieren

Edge Computing
Erfahren Sie das Neueste von den Plattformen, die die Operations am Edge vereinfachen

Infrastruktur
Erfahren Sie das Neueste von der weltweit führenden Linux-Plattform für Unternehmen

Anwendungen
Entdecken Sie unsere Lösungen für komplexe Herausforderungen bei Anwendungen
Virtualisierung
Erfahren Sie das Neueste über die Virtualisierung von Workloads in Cloud- oder On-Premise-Umgebungen