Die Einführung und Entwicklung von KI hat sich beschleunigt, da generative und agentische KI ein breites Publikum erreicht haben. Während neue Märkte entstehen, haben Unternehmen Schwierigkeiten, die Vorteile von KI zu nutzen, um einen echten ROI (Return on Investment) zu erzielen. Obwohl GPUs die Infrastruktur dominieren, haben steigende Kosten und eine sinkende Verfügbarkeit aufgrund der Nachfrage führende Unternehmen dazu veranlasst, nach Alternativen zu suchen, die weiterhin die Performance-Anforderungen und Standards an Kundenzufriedenheit erfüllen.
Gleichzeitig stehen Entwicklungsteams und Engineers, die an KI arbeiten, vor Herausforderungen bei der komplexen und zeitaufwändigen Einrichtung der Infrastruktur und Schwierigkeiten beim Aufbau von Software-Stacks und Architekturen für eine optimale LLM-Inferenz (Large Language Model) mit Retrieval Augmented Generation (RAG). Benutzerfreundlichkeit, Sicherheit proprietärer Daten und selbst der Einstieg in die Entwicklung von KI sind technische Herausforderungen, die Entwicklungsteams am Einstieg in die KI hindern können.
Die Zusammenarbeit zwischen Intel und Red Hat kombiniert die Leistung von Xeon-CPUs mit der Skalierbarkeit von Red Hat OpenShift AI und bietet eine geschützte und flexible Basis für die Bereitstellung von agentischer KI im Unternehmen. Auf dieser Plattform können Kunden Modelle und Anwendungen für KI und Machine Learning sicherer und in großem Umfang in Hybrid Cloud-Umgebungen erstellen.
Um den Einführungsprozess zu vereinfachen, hat Intel eine Reihe von KI-Schnellstarts erstellt. KI-Schnellstarts sind Beispiele für reale geschäftliche Use Cases, die mit OpenShift schnell auf Xeon bereitgestellt werden können, wodurch die Entwicklung und die Markteinführung beschleunigt werden. Diese Schnellstarts sind über den KI-Schnellstartkatalog verfügbar.
Warum KI auf Xeon?
Obwohl GPUs Deep Learning, generative KI und agentische KI dominieren, kann die Inferenz kleinere und kostengünstigere Computing-Plattformen verwenden, um Funktions- und Performance-Anforderungen zu erfüllen. CPUs waren in der Vergangenheit die bevorzugte Plattform für Datenverarbeitung, Datenanalysen und klassisches Machine Learning. Dazu gehören Regression, Klassifizierung, Clustering und Entscheidungsbäume mit Methoden wie Support Vector Machines, XGBoost und K-Means. Zu den Use Cases gehören Finanz- und Einzelhandelsprognosen, Betrugserkennung und Optimierung der Lieferkette. Dies hilft, die Kosten für die KI-Infrastruktur langfristig zu bewältigen. Intel Xeon ist als Head-Node für diese Art von kleineren Plattformen gut positioniert.
Hardwarefunktionen von Intel Xeon
Es sind die Hardwarefunktionen, die Xeon als eine geeignete CPU-Plattform für KI qualifizieren. Der Befehlssatz Advanced Matrix Extensions (AMX) und die hohe Speicherbandbreite mit Multiplexed Rank Dual In-line Memory Modules (MRDIMMs) sind die wichtigsten Komponenten, die Xeon auszeichnen.
AMX wurde in den skalierbaren Intel® Xeon® Prozessoren der 4. Generation als integrierter KI-Beschleuniger eingeführt. Es handelt sich um einen dedizierten Hardwareblock auf den Kernen, um Matrixberechnungen durchzuführen, anstatt sich auf einen diskreten Beschleuniger zu verlassen. Es werden Datentypen mit niedrigerer Präzision wie Bfloat16 (BF16) und INT8 unterstützt. Ein wesentlicher Vorteil von BF16 ist die Verbesserung der Performance ohne Einbußen bei der Genauigkeit im Vergleich zu FP32. Beschleunigungen mit AMX reduzieren den Strom- und Ressourcenverbrauch und verkürzen die Entwicklungszeit, da Optimierungen in KI-Frameworks wie PyTorch und TensorFlow vorab integriert sind.
Empfehlungssysteme, Natural Language Processing, generative KI, agentische KI und Use Cases für Computer Vision (maschinelles Sehen) profitieren von AMX, was zu einem höheren Endnutzer- und Geschäftswert führt.

Abbildung 1: Intel® AMX bietet 2D-Register-Tiles mit TMUL-Tile-Matrix-Multiplikationsanweisungen, um große Matrizen in einem einzigen Vorgang zu berechnen.
Bei der KI- und LLM-Inferenz ist der Speicherengpass das Key-Value-Caching (KV) aufgrund des hohen Speicherbedarfs. MRDIMMS begegnet diesem Problem, indem es die Rechenkomplexität von quadratisch auf linear verlagert und eine um mehr als 37 % höhere Speicherbandbreite als RDIMMs bietet. Dies verbessert den Speicherdurchsatz und reduziert die Latenz bei der Bearbeitung datenintensiver Aufgaben während der KI-Inferenz. In Systemen mit begrenztem GPU-Speicher können Xeon CPUs KV-Daten auslagern, wodurch teure GPU-Ressourcen freigesetzt und gleichzeitig eine hohe Leistung aufrechterhalten wird.
Xeon bietet mehrere praktische Use Cases in den Bereichen KI: Inferenz, RAG und sichere Datenverarbeitung sowie agentische KI. Xeon ist sowohl funktional als auch leistungsfähig und bietet unterstützende Software, um die Anforderungen an die KI zu erfüllen, ohne dass GPUs erforderlich sind.
1. Use Case für Xeon: KI-Inferenz
LLM-Inferenz unterstützt Anwendungen wie Enterprise-Chatbots, Dokumentzusammenfassungen, Code-Assistenten und RAG-Pipelines. Für mittlere Unternehmen und Organisationen, die eine kostengünstige generative KI ohne große GPU-Investitionen suchen, kann Xeon eine praktikablere Option sein. Xeon funktioniert am besten mit kleinen bis mittelgroßen LLMs und Mixture-of-Experts (MOEs) mit bis zu 13 Milliarden Parametern und erfüllt dennoch Standards wie Time-to-First-Token (TTFT) von 3 Sekunden und Time-per-Output-Token von 100 ms.
Intel hat eng mit der Open Source Community zusammengearbeitet, um die KI-Inferenz, einschließlich vLLM und SGLang, zu optimieren. vLLM ist eine Inferenz-Serving-Engine für hohen Durchsatz und Speichereffizienz. Das vLLM-Dashboard für Xeon auf Pytorch.org enthält veröffentlichte Leistungszahlen beliebter LLMs wie Llama-3.1-8B-Instruct auf Xeon. Intel verbessert kontinuierlich die Leistung und erweitert die Unterstützung für eine Liste validierter Modelle. SGLang ist ein weiteres schnelles Serving-Framework, an dessen Integration Intel mit Xeon arbeitet.
Xeon unterstützt auch die verteilte LLM-Inferenz mit llm-d, wobei die Prefill- und Decode-Phasen auf mehrere Knoten verteilt werden, um eine höhere Skalierbarkeit zu erzielen. llm-d ist ein Kubernetes-natives Open Source Framework, das die verteilte LLM-Inferenz in großem Umfang beschleunigt.
2. Use Case für Xeon: RAG und sichere Datenverarbeitung
RAG ist effektiv, um genaue Ausgaben von LLMs zu erhalten, ohne Modelle neu trainieren zu müssen. Die Wissensbasis wird erstellt, indem Daten mithilfe von Dokumenten-Parsing, Chunking und Metadatenextraktion vorbereitet werden, um Einbettungen zu erstellen, die dann in einer Vektordatenbank gespeichert werden. Alle Vorgänge können sicher mit Intel® Trust Domain Extensions (TDX) durchgeführt werden, einer hardwarebasierten Technologie für Confidential Computing. TDX verwendet hardwareisolierte virtuelle Maschinen (VMs), um Daten und Anwendungen vor unbefugtem Zugriff zu schützen. Dies ermöglicht es Unternehmen, schnell verfügbare proprietäre Daten für die Automatisierung des Kundensupports, die Dokumentenabfrage und die juristische Recherche zu nutzen. Die Abruflatenz ist gering, und gleichzeitige Abfragen können mit Xeon verarbeitet werden.

Abbildung 2: Intel® TDX verwendet Hardwareerweiterungen für die Verwaltung und Verschlüsselung von Speicher, um die Vertraulichkeit und Integrität von Daten zu schützen.
3. Use Case für Xeon: Agentische KI
KI-Agenten folgen einer sequenziellen Logik aus Planen, Handeln, Beobachten und Reflektieren. Sie verwenden einen gemischten Workload, der LLM-Inferenz und Tool-Ausführung umfasst, von Datenbankabfragen und API-Aufrufen bis hin zum Dateizugriff. Xeon unterstützt Model Context Protocol (MCP)-Server, agentische LlamaStack-APIs, LangChain und CrewAI-Frameworks. Die Automatisierung von IT-Abläufen, die Unterstützung von Finanzentscheidungen und Agenten in der Lieferkette gehören zu den angestrebten Use Cases für Unternehmen.
Xeon auf OpenShift: Neuerungen
Red Hat OpenShift AI ist eine unternehmensgerechte KI-Plattform für die Verwaltung des gesamten Lebenszyklus von Entwicklung, Training und Bereitstellung von KI-Modellen und -Anwendungen in großem Umfang über die Hybrid Cloud, On-Premise- und Edge-Umgebungen hinweg. Zu den in OpenShift AI enthaltenen Technologien gehört vLLM, das eine optimierte Modellbereitstellung mit hohem Durchsatz und niedriger Latenz bietet und gleichzeitig die Hardwarekosten senkt. Es gibt eine Sammlung optimierter, produktionsbereiter und validierter Modelle von Drittanbietern, die Entwicklungsteams mehr Kontrolle über die Zugänglichkeit und Transparenz der Modelle gibt, um Sicherheits- und Richtlinienanforderungen zu erfüllen. Dies alles kann automatisch mit fortschrittlichen Tools bereitgestellt werden, um Ihre KI-Projekte zu beschleunigen und die betriebliche Komplexität zu reduzieren. Insgesamt können KI-Anwendungen schneller und in größerem Umfang in die Produktion überführt werden.
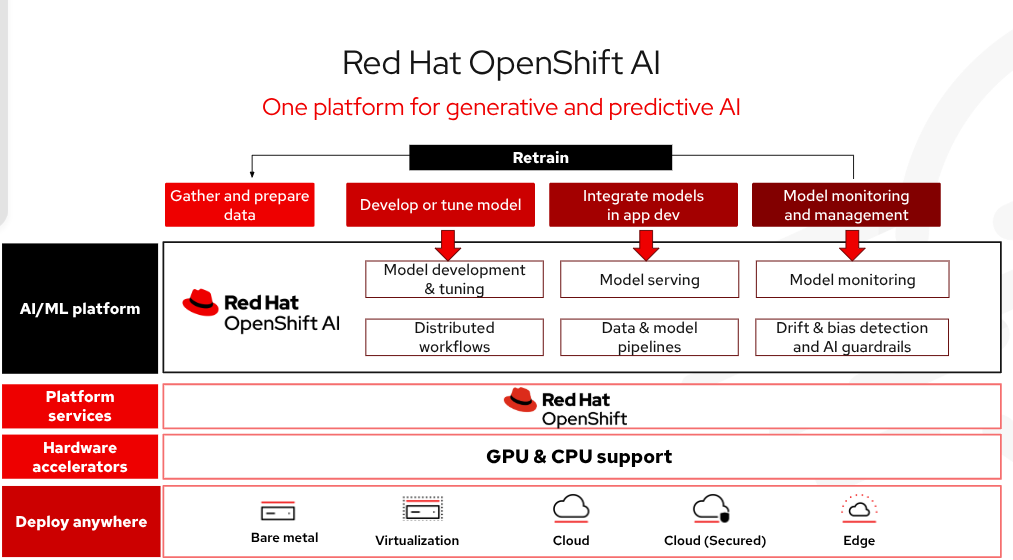
Abbildung 3: Red Hat OpenShift AI ist eine flexible, skalierbare Plattform für künstliche Intelligenz (KI) und maschinelles Lernen (ML), die es Unternehmen ermöglicht, KI-fähige Anwendungen in großem Umfang in Hybrid Cloud-Umgebungen zu erstellen und bereitzustellen.
Funktionen
Die Verwaltung der KI-Infrastruktur nimmt weniger Zeit in Anspruch, da leistungsstarke Modelle einfach mit Models as a Service (MaaS) bereitgestellt werden und mit API-Endpunkten darauf zugegriffen werden kann. Es bietet Flexibilität in der gesamten Hybrid Cloud als geschützte und flexible, selbst gemanagte Software auf Bare Metal, in virtuellen Umgebungen oder auf den wichtigen Public Cloud-Plattformen. Red Hat hat gängige Open Source-KI/ML-Tools und Modellbereitstellung getestet und integriert, so dass sie für Entwicklungsteams einfach zu verwenden sind. OpenShift AI umfasst auch llm-d, ein Open Source-Framework für verteilte KI-Inferenz in großem Umfang.
vLLM-CPU-Image
Intel hat ein vLLM-Image für CPU auf Dockerhub zur Verfügung gestellt, das auf dem Universal Base Image von Red Hat basiert. Das Image wird mit aktiviertem AMX erstellt. Daher sind für die Ausführung dieses Images skalierbare Xeon®-Prozessoren der 4. Generation oder neuer erforderlich. Viele Open Source-Modelle können jetzt schnell bereitgestellt werden und sofort mit hohem Durchsatz und geringer Latenz Inferenz betreiben.
KI-Schnellstarts
Im KI-Schnellstartkatalog auf redhat.com finden Sie sofort einsatzbereite Use Cases für Unternehmen, die Modelle mit vLLM auf Xeon, unterstützt von OpenShift AI, optimal ausführen. Entwicklungsteams können diese Beispiele als Ausgangspunkt nehmen und sie an ihre Bedürfnisse anpassen oder sie so verwenden, wie sie sind. Frühe Entwurfsversionen mehrerer KI-Schnellstarts sind auf GitHub verfügbar und können sofort auf Xeon ausgeführt werden, wobei alle endgültigen Schnellstarts über den KI-Schnellstartkatalog veröffentlicht werden.
- LlamaStack MCP Server – Stellt LLMs mit vLLM auf MCP-Servern wie Wetterberichte- und HR-Tools bereit.
- LLM CPU Serving –Ein schlanker Chat-Assistent für KI-Führung und Strategie, der ein kleines Sprachmodell bereitstellt.
- RAG – Verwenden Sie Retrieval Augmented Generation, um LLMs mit spezialisierten Datenquellen zu erweitern und so genauere und kontextbezogenere Antworten zu erhalten.
- vLLM Tool Calling – Stellt LLMs mit vLLM mit Funktionsaufruf bereit
Nächste Schritte
KI auf Xeon wird mit Red Hat OpenShift AI vereinfacht. Die gemanagte und geschützte Umgebung richtet die notwendige KI-Infrastruktur für Entwicklung, Bereitstellung und Beobachtbarkeit ein.
- Im vLLM-Dashboard für Xeon finden Sie Leistungszahlen und in der vLLM-Dokumentation Informationen zum Erstellen/Herunterladen der vLLM-Images für CPU mit AMX-Unterstützung.
- Verwenden Sie das vLLM für die CPU basierend auf dem Red Hat Universal Base Image von DockerHub.
- Überprüfen Sie die Liste der unterstützten Modelle für Xeon.
- Erkunden Sie den KI-Schnellstartkatalog nach sofort einsatzbereiten Beispielen. Besuchen Sie den AI Quickstart Github für KI-Schnellstarts, die sich noch in der Entwicklung befinden.
- Besuchen Sie die Website von Red Hat OpenShift AI.
Produkt
Red Hat AI
Über den Autor

Ähnliche Einträge
Red Hat and Netris bring multi-tenant networking to sovereign AI clouds and neoclouds
The agentic paradox and the case for hybrid AI
Technically Speaking | Build a production-ready AI toolbox
Technically Speaking | Platform engineering for AI agents
Nach Thema durchsuchen

Automatisierung
Das Neueste zum Thema IT-Automatisierung für Technologien, Teams und Umgebungen

Künstliche Intelligenz
Erfahren Sie das Neueste von den Plattformen, die es Kunden ermöglichen, KI-Workloads beliebig auszuführen

Open Hybrid Cloud
Erfahren Sie, wie wir eine flexiblere Zukunft mit Hybrid Clouds schaffen.

Sicherheit
Erfahren Sie, wie wir Risiken in verschiedenen Umgebungen und Technologien reduzieren

Edge Computing
Erfahren Sie das Neueste von den Plattformen, die die Operations am Edge vereinfachen

Infrastruktur
Erfahren Sie das Neueste von der weltweit führenden Linux-Plattform für Unternehmen

Anwendungen
Entdecken Sie unsere Lösungen für komplexe Herausforderungen bei Anwendungen
Virtualisierung
Erfahren Sie das Neueste über die Virtualisierung von Workloads in Cloud- oder On-Premise-Umgebungen