Businesses often face challenges in maintaining high availability (HA) and managing seamless application deployments across diverse environments. By leveraging per-application multi-cluster ingress with F5 BIG-IP and Red Hat OpenShift, organizations can more effectively address these issues and provide the following functionalities to multicluster environments:
- Flexible application placement: Allows applications to be distributed across various clusters with a single multicluster ingress
- Per-application deployment strategies: Supports blue-green and A/B testing strategies on a per-application basis
- Increase application capacity and performance: Tailor performance and capacity for each application.
- Disaster recovery: Supports disaster recovery (DR) with single-active application configurations
- Cluster scalability and availability: Divide standalone large clusters into multiple smaller ones, making them more manageable and increasing infrastructure uptime
- Flexible OpenShift migrations: Enables partial migrations and upgrades, avoiding “all or nothing" scenarios
- Layer 4 load balancing: Provides multi-cluster load balancing capabilities for non-HTTP L4 traffic
How does BIG-IP work?
F5 BIG-IP employs a Container Ingress Services (CIS) controller to enable interaction between BIG-IP and OpenShift. The configuration of BIG-IP is managed through Kubernetes manifests, which are text-based YAML files that define the resources and configurations needed to run applications in a Kubernetes environment.
For the data plane, BIG-IP supports both a one-tiered and a two-tiered configuration. In a one-tier setup, BIG-IP directs traffic directly to the workload pod IP. In a two-tier setup, it is routed to an ingress controller, service mesh, API manager, or a combination of these. In this configuration, it is also possible to pod IPs to connect to the second tier, such as the OpenShift router. NodePort and hostNetwork can also be used.
BIG-IP is an external load balancer (LB) that can serve as Layer 7 (L7) ingress, due to its application awareness. This is facilitated by Ingress, Routes, and F5 VirtualServer Custom Resources (CR). This allows BIG-IP to monitor the health of OpenShift applications across multiple clusters and make load-balancing decisions based on their availability on a per-route basis.
The figure shows a one-tier multi-cluster arrangement where BIG-IP sends the traffic directly to the workload pods:
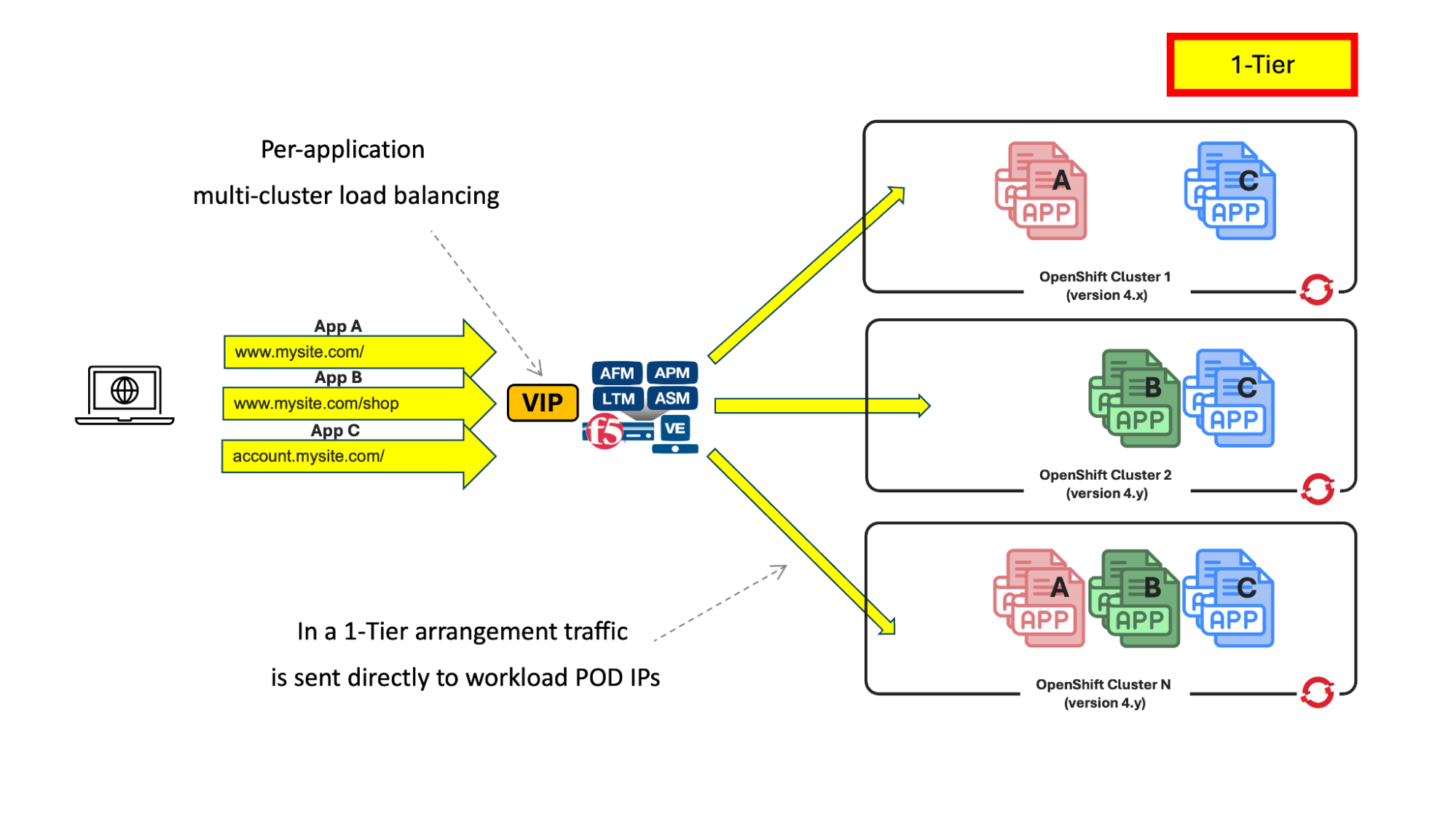
Fig 1. One-tier multi-cluster arrangement
Please note that the different clusters don’t need to run the same OpenShift version, nor do they have to have the same applications in them. This flexibility greatly enhances deployment options.
This figure shows a multi-cluster arrangement using a two-tier arrangement:
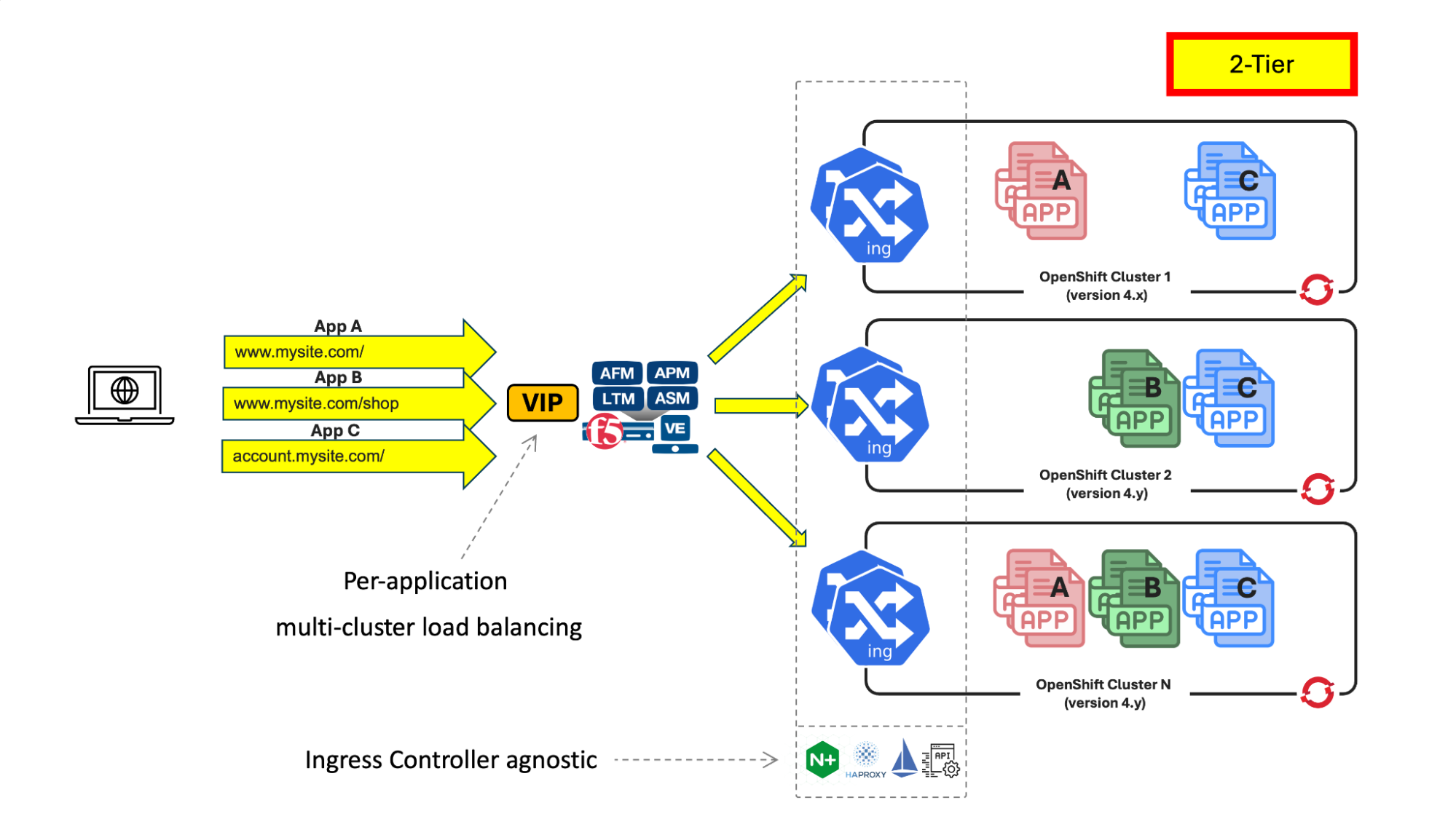
Fig 2. Two-tier multi-cluster arrangement
A two-tier configuration sends traffic to the external load balancer, in this case BIG-IP (first tier), which then directs traffic to another load balancer within the OpenShift cluster. This could be the default OpenShift router, often HAProxy, another ingress controller, a service mesh, API manager, or some combination of these.
Typically, first-tier load balancers are limited to Layer 4 (L4) and lack L7 awareness, while second-tier load balancers handle L7 operations. BIG-IP, however, when used as an external load balancer, is fully L7-aware. This enables additional use cases, such as combining different ingresses behind a single virtual IP (VIP) with the same hostname. BIG-IP can direct traffic to the appropriate second-tier load balancer based on the HTTP route.
This figure shows how this two-tier fully L7-aware arrangement works:
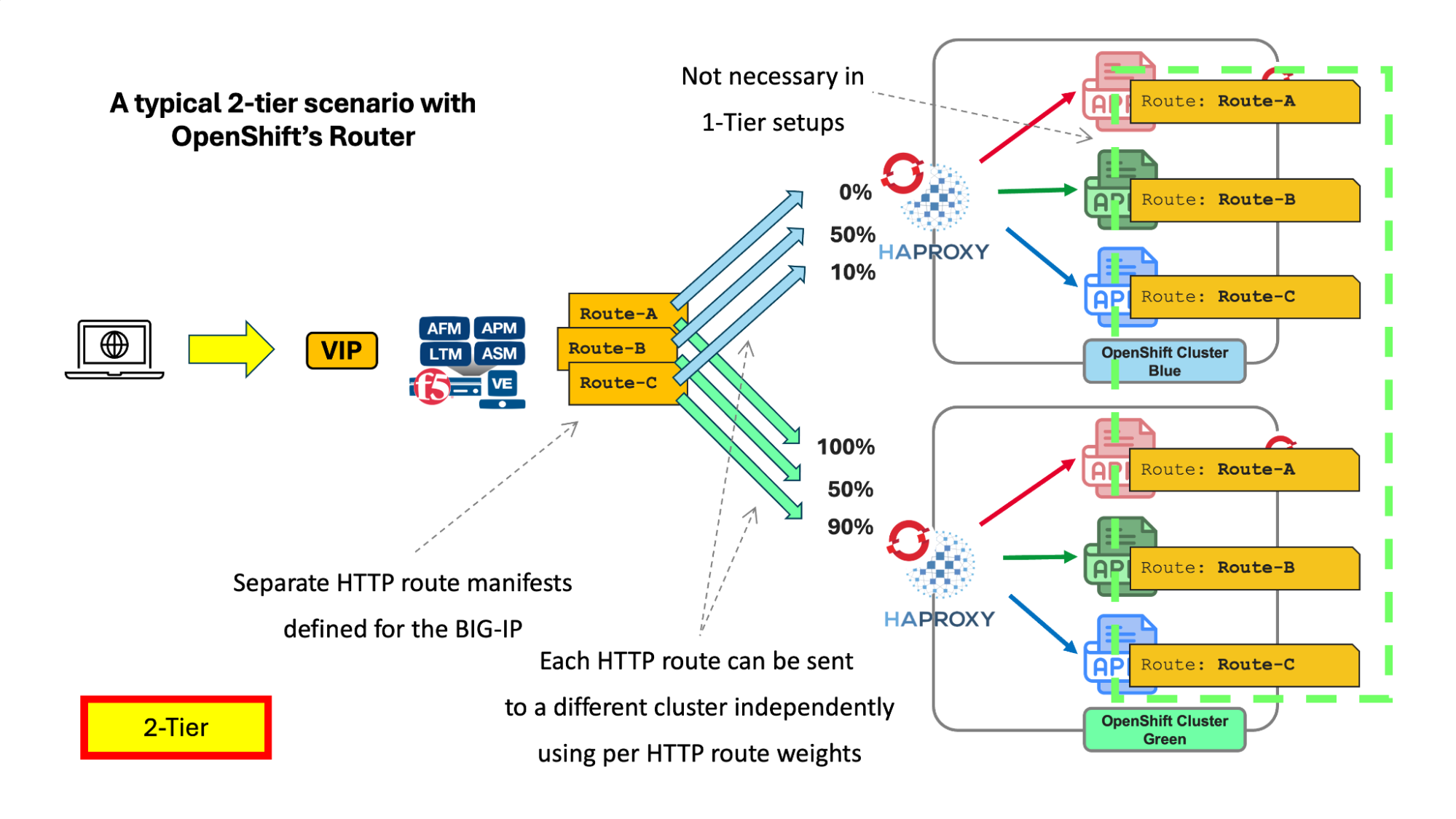
Fig 3. Two-tier application manifests configuration
In a two-tier arrangement, the routes of the second tier remain unchanged. To bring L7 awareness to the first-tier, BIG-IP uses its own manifest. These define the traffic routing to the ingress controllers and include health checks for the OpenShift application pods. It is important to note that in a one-tier setup, only the route manifests for the BIG-IP are necessary.
How traffic is sent to multiple clusters
There are three multi-cluster load balancer methods: Active-Active, Ratio and Active-Standby.
Once a pool is selected, standard BIG-IP load balancer methods, such as round-robin, least-connections and fastest member are used.
Active-Active
Pods from all the clusters are placed in a single pool, and the specified load balancer method for the pool is used, regardless of the cluster where the destination pod is located.
Blue-Green and A/B strategies can be used to direct traffic to a specific cluster for a given application, enhancing control over traffic during updates or other testing.
Ratio
A ratio is set for how much traffic to send to each OpenShift cluster and is applicable to all services simultaneously. This involves a two-tier system where the set ratio guides the selection of the cluster and then standard load balancing is carried out within the pool of that cluster.
Active-Standby
Pods from a cluster where the CIS is on standby are not included, which is useful for applications that can be active in only one cluster at a time.
How it is used
Using this multi-cluster solution is relatively straightforward for DevOps teams. Existing OpenShift route resources can be used without any modification. Service discovery will automatically work across all clusters, and it is only needed to define the clusters in a CIS ConfigMap. In addition to the route resource type, DevOps can use F5 Custom Resources which provide additional HTTP functionalities or handle Layer 4 traffic for multi-cluster in-memory databases.
This figure represents multi-cluster manifest configuration:
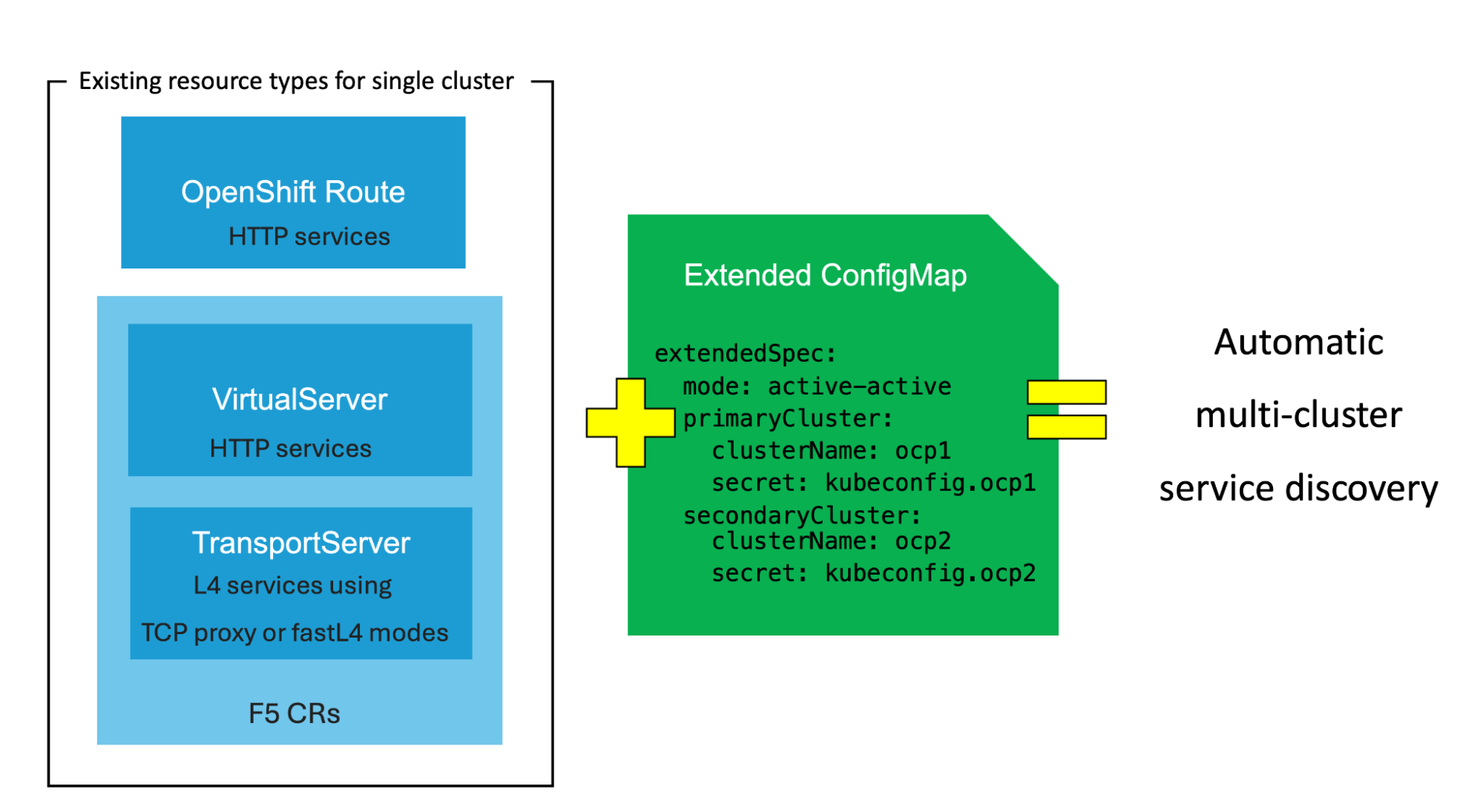
Fig 4. Multi-cluster manifest configuration
F5 BIG-IP provides additional features such as IP Address Management (IPAM), IP intelligence, visibility of SSL/TLS traffic for inspection using third party solutions, identity aware ingress (SSO, federation, MFA), Advanced WAF, credentials, bot protections, etc. These can be used directly using F5 CRs or with Routes and this same Extended ConfigMap.
Manifests and High Availability
Manifests for the Service resources are deployed across all clusters where we want the applications to be reachable. If a Service manifest is deleted by mistake or its cluster cannot be reached using the Kubernetes API, this workload will not be taken into account and workloads will be taken from all other clusters.
The manifests for the HTTP routes or L4 services will be defined only in the clusters where CIS instances are deployed. Thus these manifests have a 2-cluster redundancy.
For each BIG-IP, there are two instances of CIS for redundancy—Primary CIS and Secondary CIS. By default, the Primary will be the one responsible for pushing configuration changes and events to the BIG-IP. The Secondary will take over this task if it fails to get successful replies from Primary's readiness endpoint. Note that when using more than two clusters, these additional clusters will not have a CIS instance running in them. In total there will be 4 CIS instances regardless of the number of clusters.
This figure represents the manifest's source of truth and HA:
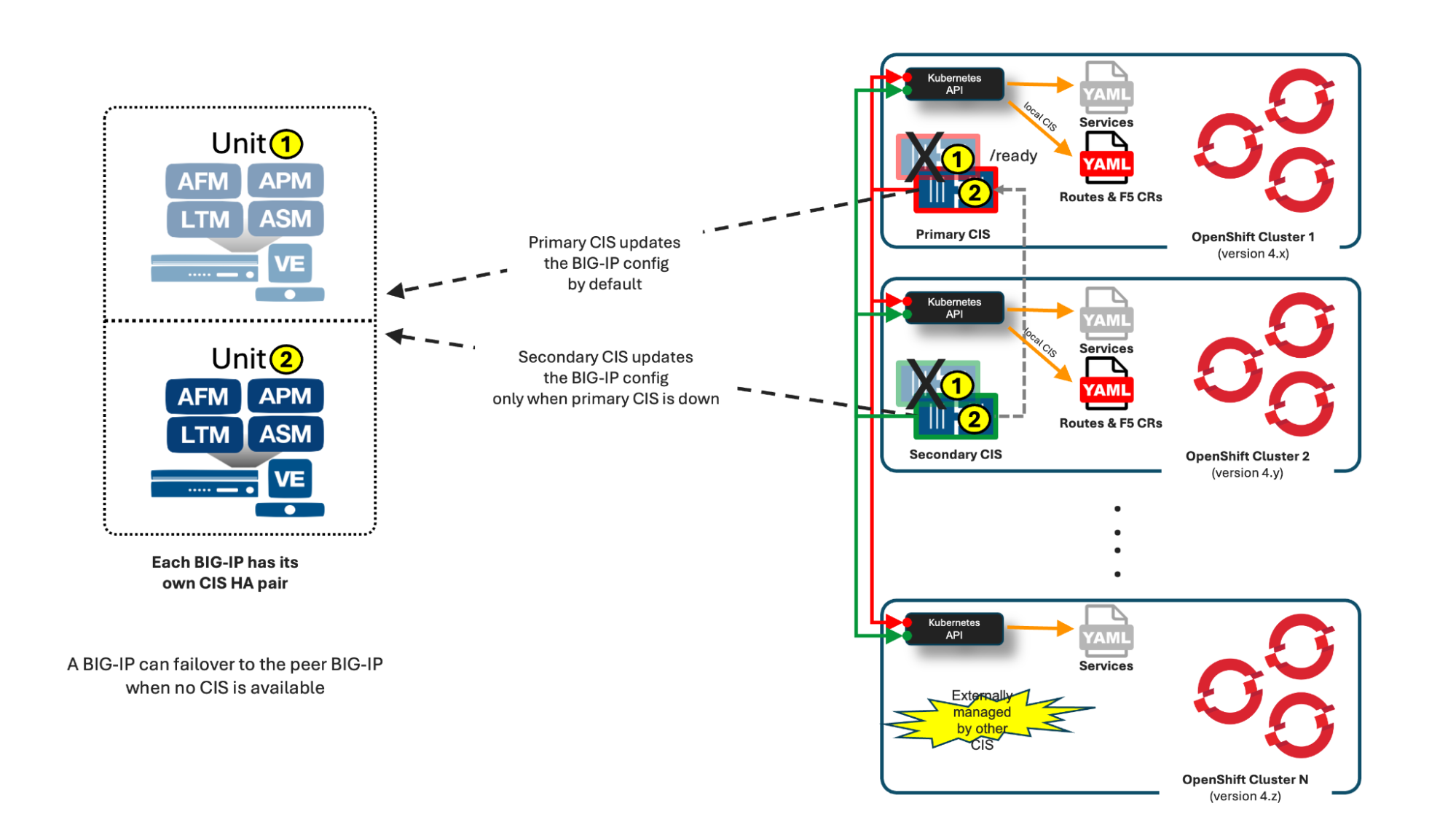
Fig 5. Manifest’s source of truth and HA
As mentioned above, each BIG-IP will have its own pair of Primary and Secondary CIS. In the case that both Primary and Secondary CIS of the Active BIG-IP fail, this BIG-IP can promote itself to Standby if the peer BIG-IP has at least one CIS instance running. With this we close the loop for all cases required to achieve High Availability.
Wrap up
As more applications are modernized and refactored into OpenShift, enterprises will need additional clusters and flexible application placement. Organizations want to avoid complexity and it is crucial that it is transparent in which cluster an application is hosted.
The CIS multi-cluster feature is unique in the market, fulfilling multi-cluster use cases and allowing simplified OpenShift migrations with little to no application down time, eliminating the need for in-place upgrades.
Learn more
For more information, watch these videos and access these links:
- Multi-Cluster OpenShift with F5 BIG-IP - Demonstrates the overall functionality and how high availability works
- F5 BIG-IP per application OpenShift cluster migrations - Demonstrates a migration between two clusters using a per-application blue/green strategy
If you are already an existing F5 BIG-IP customer, CIS is open source software and support is included with any support entitlement.
Über die Autoren


George James came to Red Hat with more than 20 years of experience in IT for financial services companies. He specializes in network and Windows automation with Ansible.
Ähnliche Einträge
IT-Stack vereinheitlichen: VMs, Cloud und KI vereint
Red Hat Skills Bundle: Der neue Standard für KI-Agenten
The C Change | Command Line Heroes
The Ground Floor | Compiler: Tales From The Database
Nach Thema durchsuchen

Automatisierung
Das Neueste zum Thema IT-Automatisierung für Technologien, Teams und Umgebungen

Künstliche Intelligenz
Erfahren Sie das Neueste von den Plattformen, die es Kunden ermöglichen, KI-Workloads beliebig auszuführen

Open Hybrid Cloud
Erfahren Sie, wie wir eine flexiblere Zukunft mit Hybrid Clouds schaffen.

Sicherheit
Erfahren Sie, wie wir Risiken in verschiedenen Umgebungen und Technologien reduzieren

Edge Computing
Erfahren Sie das Neueste von den Plattformen, die die Operations am Edge vereinfachen

Infrastruktur
Erfahren Sie das Neueste von der weltweit führenden Linux-Plattform für Unternehmen

Anwendungen
Entdecken Sie unsere Lösungen für komplexe Herausforderungen bei Anwendungen
Virtualisierung
Erfahren Sie das Neueste über die Virtualisierung von Workloads in Cloud- oder On-Premise-Umgebungen