
Industrial environments often need deterministic instruction execution, which poses a challenge for general compute systems. Despite appearing to execute instructions instantly, a user process receives only a commitment for execution as soon as a CPU becomes available, which in a general compute system is dependent on other processes competing for the same resources (CPU, memory and others).
Although this is usually acceptable, extremely critical applications, such as stopping an industrial process or relocating a robotic arm, require a guarantee of when execution will occur. This problem is usually solved by using special purpose compute systems, which might have specially-built hardware and a tightly controlled software environment.
In electronics, jitter is the deviation from true periodicity of a periodic signal. For CPUs we can measure the execution time variation of a CPU test workload. The performance of the workload is impacted by kernel interrupts. Minimizing these interrupts also minimizes the jitter that applications could potentially experience. Intel’s caterpillar benchmark measures the execution time variation of a memory-intensive workload. Using Cache Allocation Technology (CAT) improves application performance by assigning CPU affinity to cache ways, which can be dedicated to real-time applications.
Benchmark scenarios
For this exercise, we’re running the same benchmark in four different configurations:
- Benchmark compiled and run on the host, standard kernel
- Benchmark running in a podman container, standard kernel
- Benchmark compiled and run on the host, application using CAT on a standard kernel
- Benchmark running in a podman container, using CAT on a standard kernel
The caterpillar binary does a function pointer chasing test and measures the execution time variation, as it reads data from memory. As long as the data is kept in the cache, the access time to memory is fast and execution time is short. If there is another process sharing the cache, heavily accessing memory and thus evicting benchmark cache lines (aka "trashing the cache"), the performance of the benchmark workload is impacted by these cache misses. The benchmark needs to wait until the data is fetched from RAM, significantly slowing memory access and increasing execution time. A Python script is used to launch caterpillar alongside a stress application (stress-ng, available in the Red Hat Enterprise Linux (RHEL) and Red Hat Device Edge standard repositories) simulating a noisy neighbor scenario.
For the bare metal benchmark, we’re using the following command line:
caterpillar/start-benchmark.py --test_core 1 --nn_core 2 --irq_core 3
For the podman benchmark, we’re using the following command line:
podman run --rm --privileged --name caterpillar --volume /sys/:/sys/ --volume /proc/:/proc/ --entrypoint /opt/benchmarking/caterpillar/start-benchmark.py --test_core 1 --nn_core 2 --irq_core 3
The arguments translate to:
test_core 1– spawn the caterpillar benchmark on core 1nn_core 2– spawn stress-ng on core 2 to simulate a noisy neighborirq_core 3– set the IRQ managing core to core 3
For all four test scenarios, the benchmark application, stress application and irq balancing are each pinned to a CPU core.
It’s also important to note that the benchmark application is spawned with chrt priority 95 and during each benchmark run, jitter is measured in CPU cycles. In total, 200 samples are measured for each benchmark run (pointer chasing test is executed 200 times and for each, the jitter value is recorded).
Please note the container needs access to proc and sys host filesystems.
Test environment
For the benchmarking, we’ve used a Vecow SPC-7100 computer with an 11th Generation Intel Core™ i5 CPU.
CPU: 11th Gen Intel(R) Core(TM) i5-1145GRE @ 2.60GHz RAM: 16GB DDR4 3200MHz
The notable CPU flags are:
rdt_1– Resource Director Technology Allocationcat_l2- Cache Allocation Technology Level 2cdp_l2- Code and Data Prioritization Level 2
The operating system deployed is Red Hat Device Edge 9.1 with kernel 5.14.0 with CONFIG_X86_CPU_RESCTRL=y config (default configuration). For an example of building a Red Hat Device Edge image, check out this very comprehensive guide.
In the BIOS settings, we’ve disabled hyperthreading as this tends to complicate cache allocation.
Baseline results
Without any performance tuning whatsoever on the host, these are the results:
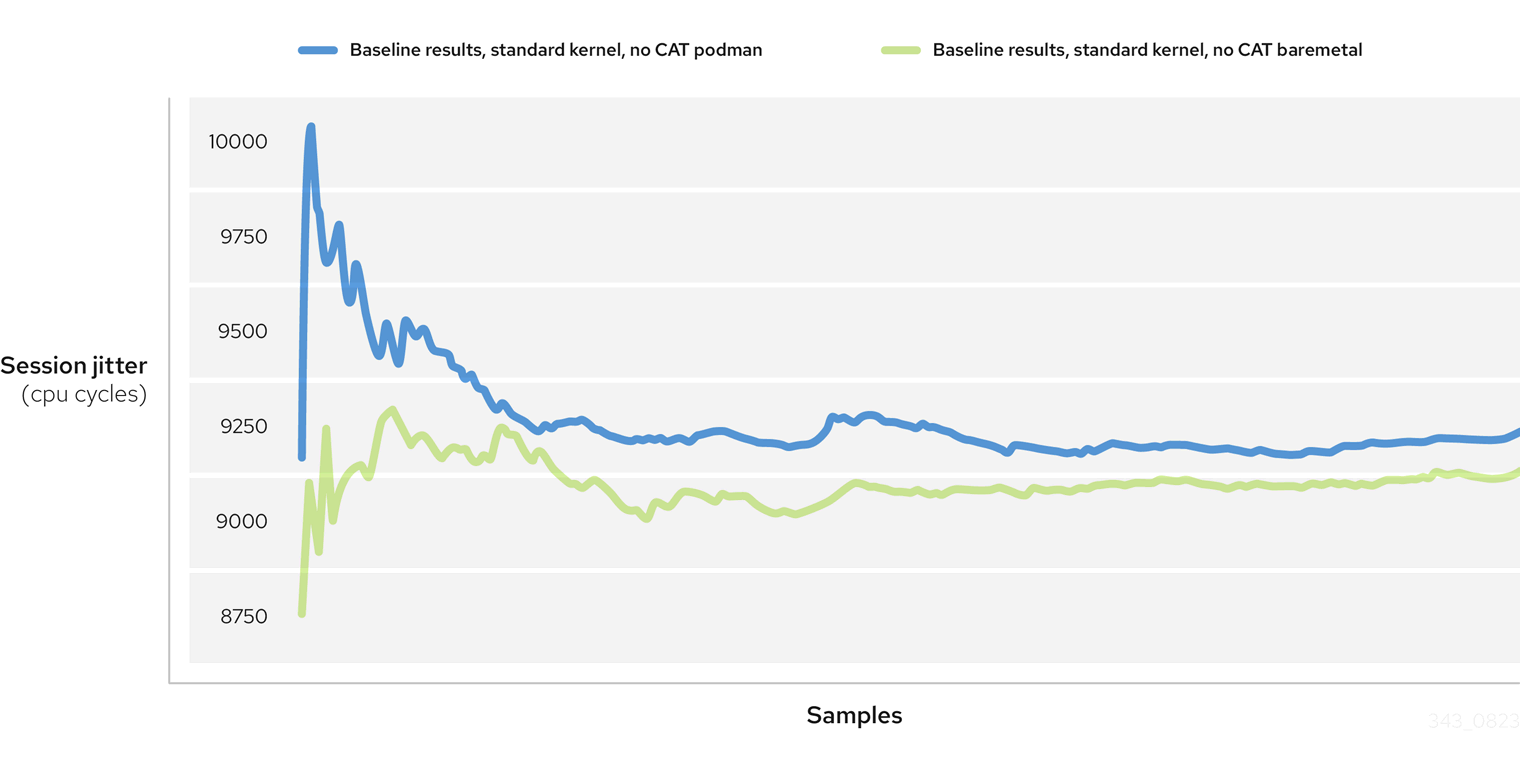
Figure 1: Baseline results, standard kernel, no CAT
The results are measured in CPU cycles and we can see the jitter is quite high, averaging between 9000 and 9500 cycles, and varies a lot between each sample, which is clearly not ideal for an application that needs a response time that's as low and as predictable as possible.
Performance tuning with CAT
Resource Control (resctrl) is a kernel interface for CPU resource allocation using Intel® Resource Director Technology. The resctrl interface is available in kernels 4.10 and newer. Currently, Resource Control supports L2 CAT, L3 CAT and L3 CDP, which allows partitioning L2 and L3 cache on a per core/task basis. It also supports MBA; the maximum bandwidth can be specified in percentage or in megabytes per second (with an optional mba_mbps flag).
Before we access the resctrl interface, we need to mount it. Create the file /etc/systemd/system/sys-fs-resctrl.mount with the following contents:
[Unit] Description=Mount resctrl sysfs at /sys/fs/resctrl Before=crio.service [Mount] What=resctrl Where=/sys/fs/resctrl Type=resctrl Options=noauto,nofail [Install] WantedBy=multi-user.target
Then reload systemd and enable the mount:
systemctl daemon-reload systemctl enable --now sys-fs-resctrl.mount
The pqos utility is used to query and monitor CPU resources and Intel Resource Director Technology. The package intel-cmt-cat provides it, either in standard RHEL or in Red Hat Device Edge. We can query the default state:
# pqos -s -I os
L2CA COS definitions for L2ID 0:
L2CA COS0 => MASK 0xfffff
L2CA COS1 => MASK 0xfffff
L2CA COS2 => MASK 0xfffff
L2CA COS3 => MASK 0xfffff
L2CA COS4 => MASK 0xfffff
L2CA COS5 => MASK 0xfffff
L2CA COS6 => MASK 0xfffff
L2CA COS7 => MASK 0xfffff
L2CA COS definitions for L2ID 1:
L2CA COS0 => MASK 0xfffff
L2CA COS1 => MASK 0xfffff
L2CA COS2 => MASK 0xfffff
L2CA COS3 => MASK 0xfffff
L2CA COS4 => MASK 0xfffff
L2CA COS5 => MASK 0xfffff
L2CA COS6 => MASK 0xfffff
L2CA COS7 => MASK 0xfffff
L2CA COS definitions for L2ID 2:
L2CA COS0 => MASK 0xfffff
L2CA COS1 => MASK 0xfffff
L2CA COS2 => MASK 0xfffff
L2CA COS3 => MASK 0xfffff
L2CA COS4 => MASK 0xfffff
L2CA COS5 => MASK 0xfffff
L2CA COS6 => MASK 0xfffff
L2CA COS7 => MASK 0xfffff
L2CA COS definitions for L2ID 3:
L2CA COS0 => MASK 0xfffff
L2CA COS1 => MASK 0xfffff
L2CA COS2 => MASK 0xfffff
L2CA COS3 => MASK 0xfffff
L2CA COS4 => MASK 0xfffff
L2CA COS5 => MASK 0xfffff
L2CA COS6 => MASK 0xfffff
L2CA COS7 => MASK 0xfffff
Core information for socket 0:
Core 0, L2ID 0, L3ID 0 => COS0
Core 1, L2ID 1, L3ID 0 => COS0
Core 2, L2ID 2, L3ID 0 => COS0
Core 3, L2ID 3, L3ID 0 => COS0
The allocation for caches is based on a 20-bit mask. In the default configuration, all resource groups have access to all caches – mask 0xfffff and all cores are bound to COS0, the default resource allocation group.
Our CPU has only one socket and only L2 CAT capabilities, so let’s see how to leverage it. First we reset the schemata for the default group so that the "upper" 50% of the L2 cache on socket 0 cannot be used by ordinary tasks – we’re using the mask 0x3ff, which translates to 00000000001111111111 in binary:
echo "L2:0=3ff" > /sys/fs/resctrl/schemata
Next, we create our own group for real time tasks called p0:
mkdir /sys/fs/resctrl/p0
In this newly created resource group, we set the schema to utilize only the “bottom” 50% of L2 cache – using the mask 0xffc00 11111111110000000000, which is the opposite of the mask used for the general schema:
echo "L2:0=ffc00;" > /sys/fs/resctrl/p0/schemata
Inside a resource group, the CPU file contains a mask of the CPUs associated with this resource group. To edit this association, simply echo the new mask into the CPU file. In our case, the system has four logical cores. The mask for all four will be 1111 in binary or F in hex and the mask for the first two cores in binary would be 0011 or 3 in decimal. To change the CPU association to the first two cores for p0:
echo 3 > /sys/fs/resctrl/p0/cpus
Let’s see what the PQoS summary looks like now: (note that our p0 group is translated to COS1, while COS0 is the default group):
# pqos -s
L2CA COS definitions for L2ID 0:
L2CA COS0 => MASK 0x3ff
L2CA COS1 => MASK 0xffc00
L2CA COS2 => MASK 0xfffff
L2CA COS3 => MASK 0xfffff
L2CA COS4 => MASK 0xfffff
L2CA COS5 => MASK 0xfffff
L2CA COS6 => MASK 0xfffff
L2CA COS7 => MASK 0xfffff
L2CA COS definitions for L2ID 1:
L2CA COS0 => MASK 0xfffff
L2CA COS1 => MASK 0xfffff
L2CA COS2 => MASK 0xfffff
L2CA COS3 => MASK 0xfffff
L2CA COS4 => MASK 0xfffff
L2CA COS5 => MASK 0xfffff
L2CA COS6 => MASK 0xfffff
L2CA COS7 => MASK 0xfffff
L2CA COS definitions for L2ID 2:
L2CA COS0 => MASK 0xfffff
L2CA COS1 => MASK 0xfffff
L2CA COS2 => MASK 0xfffff
L2CA COS3 => MASK 0xfffff
L2CA COS4 => MASK 0xfffff
L2CA COS5 => MASK 0xfffff
L2CA COS6 => MASK 0xfffff
L2CA COS7 => MASK 0xfffff
L2CA COS definitions for L2ID 3:
L2CA COS0 => MASK 0xfffff
L2CA COS1 => MASK 0xfffff
L2CA COS2 => MASK 0xfffff
L2CA COS3 => MASK 0xfffff
L2CA COS4 => MASK 0xfffff
L2CA COS5 => MASK 0xfffff
L2CA COS6 => MASK 0xfffff
L2CA COS7 => MASK 0xfffff
Core information for socket 0:
Core 0, L2ID 0, L3ID 0 => COS1
Core 1, L2ID 1, L3ID 0 => COS1
Core 2, L2ID 2, L3ID 0 => COS0
Core 3, L2ID 3, L3ID 0 => COS0
We can now run again the benchmark:
start-benchmark.py --test_core 0 --irq_core 1 --nn_core 3
Note that we’ve moved the actual benchmark to core 0 and the IRQ balancing to core 1 (these are the cores associated with the resource group defined above), leaving the noisy neighbor to one of the other two cores.
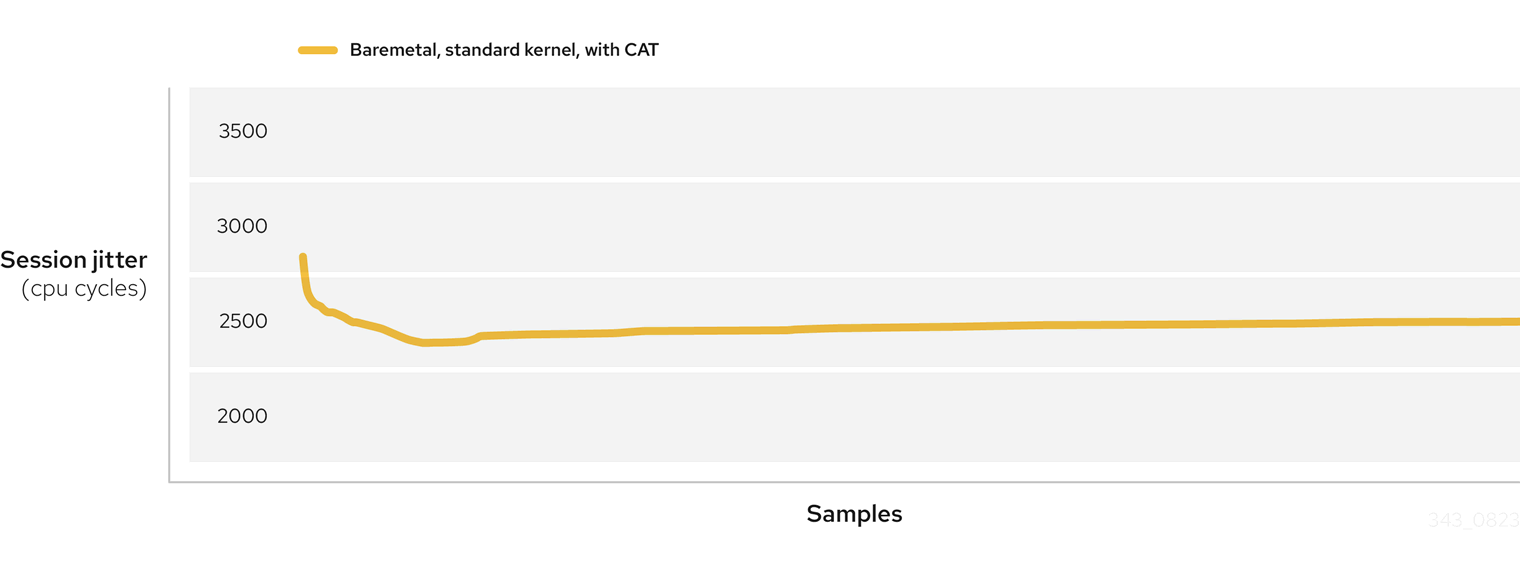
Figure 2: Baremetal, standard kernel, with CAT
The improvement is clear both in terms of average jitter and in terms of how stable jitter variance becomes with Cache Allocation Technology. There is a small increase in jitter over time, but this is expected and easily manageable in real-life applications.
Same run in podman:
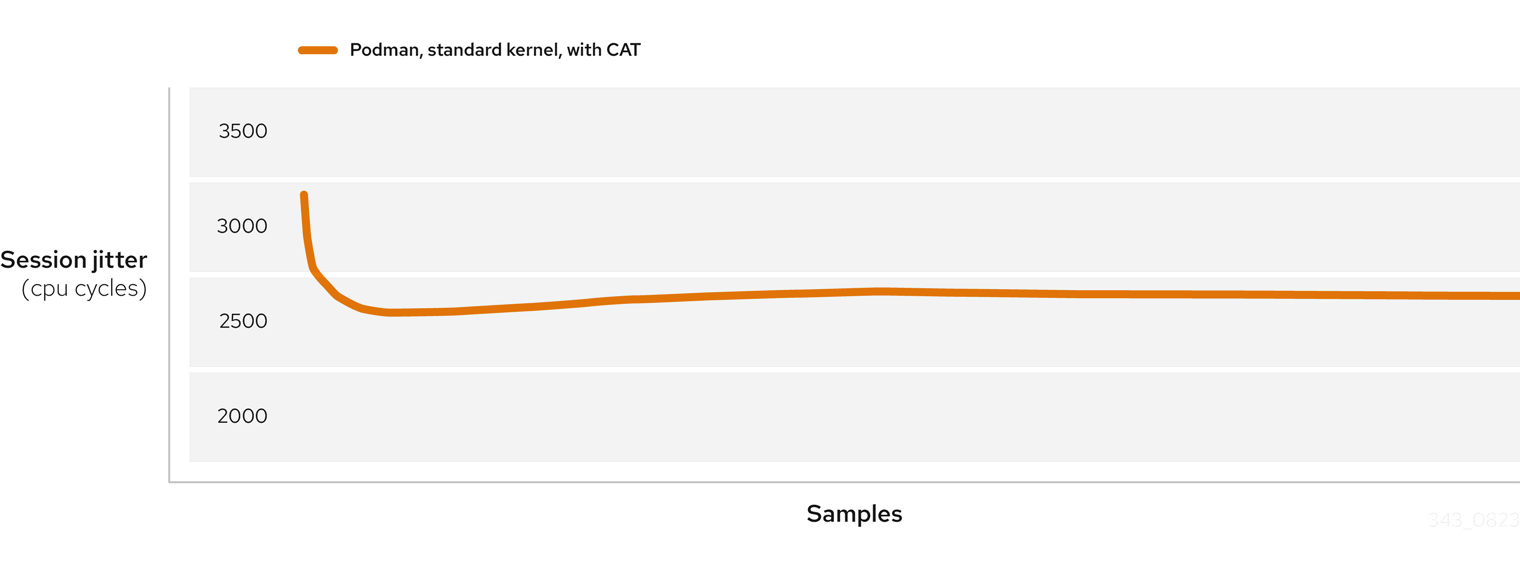
Figure 3: Podman, standard kernel, with CAT
The performance increase and stability is consistent with the first bare metal run, proving podman is an excellent replacement for distributing and running applications in an industrial environment.
Conclusion
By leveraging the combination of Red Hat Device Edge and Intel Resource Director Technology (RDT) along with Cache Allocation Technology (CAT), it becomes feasible to execute time-sensitive applications using a standard Linux kernel. This powerful integration allows users to employ the default scheduler provided by the Linux kernel while achieving remarkable levels of determinism and minimizing jitter.
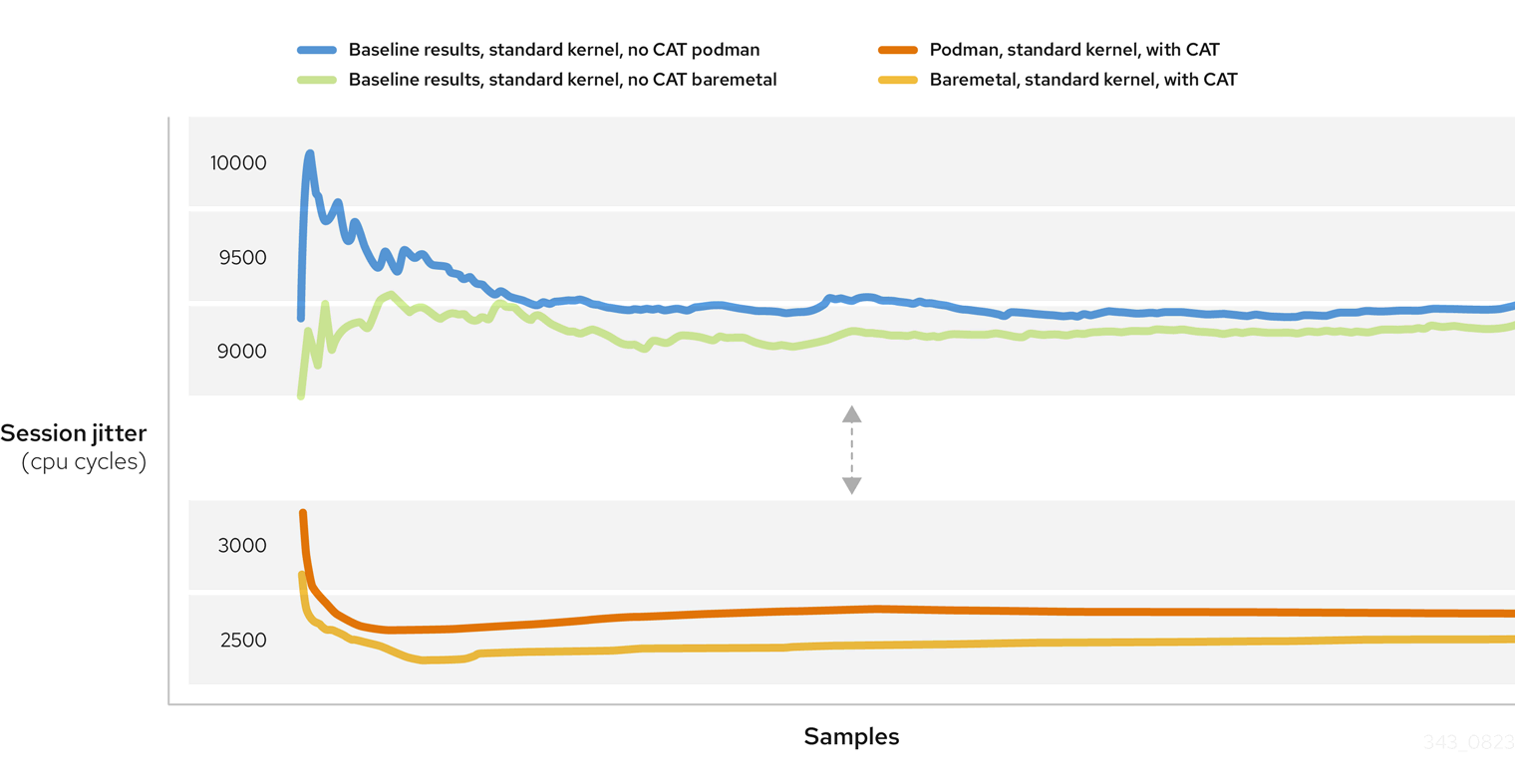
Figure 4: Baseline results compared to CAT performance tuning
RHEL provides a robust and reliable operating system foundation known for its stability and wide range of enterprise-grade features. Intel RDT introduces advanced capabilities at the hardware level, enabling fine-grained control over system resources. With RDT, administrators can allocate and manage resources such as CPU cache and memory bandwidth with precision, catering to the specific requirements of time-sensitive applications.
The combination of these technologies enables users to harness the power of a standard Linux kernel, leveraging its broad compatibility and extensive software ecosystem while still achieving the stringent requirements of time-sensitive applications. This approach not only simplifies the deployment and management of such applications but also provides a reliable and consistent environment for their execution.
Whether it involves real-time data processing, industrial control systems or any other time-critical workload, this integration empowers organizations to meet their objectives with deterministic and low-jitter performance.
Links
- Red Hat Device Edge
- Intel Cache Allocation Technology
- Kernel user interface for Resource Control feature
- Noisy neighbor in Kubernetes
Notices and disclaimers
- Performance varies by use, configuration and other factors. Learn more at www.Intel.com/PerformanceIndex.
- Performance results are based on testing as of dates shown in configurations and may not reflect all publicly available updates. See backup for configuration details. No product or component can be absolutely secure.
- Your costs and results may vary.
- Intel technologies may require enabled hardware, software, or service activation.
- Intel does not control or audit third-party data. Consult other sources to evaluate accuracy.
- This document contains information on products, services, and/or processes in development. All information provided here is subject to change without notice. Contact your Intel representative to obtain the latest forecast, schedule, specifications, and roadmaps.
- Any forecasts of goods and services needed for Intel’s operations are provided for discussion purposes only. Intel will have no liability to make any purchase in connection with forecasts published in this document.
- Code names are used by Intel to identify products, technologies, or services that are in development and not publicly available. These are not "commercial" names and not intended to function as trademarks.
- © Intel Corporation. Intel, the Intel logo, and other Intel marks are trademarks of Intel Corporation or its subsidiaries. Other names and brands may be claimed as the property of others.
Über den Autor
An old school Linux enthusiast, I joined Red Hat in 2021 and I've been helping our customers and partners integrate with Red Hat software ever since. Besides Linux and open source, I'm passionate about science and I've been occasionally known to cycle and hike around Switzerland.
Ähnliche Einträge
Red Hat Device Edge ist jetzt für NVIDIA Jetson Orin verfügbar
Die Lücke schließen: KI und Kubernetes an die Datenquelle bringen
Infrastructure At The Edge | Compiler
Open Curiosity | Command Line Heroes
Nach Thema durchsuchen

Automatisierung
Das Neueste zum Thema IT-Automatisierung für Technologien, Teams und Umgebungen

Künstliche Intelligenz
Erfahren Sie das Neueste von den Plattformen, die es Kunden ermöglichen, KI-Workloads beliebig auszuführen

Open Hybrid Cloud
Erfahren Sie, wie wir eine flexiblere Zukunft mit Hybrid Clouds schaffen.

Sicherheit
Erfahren Sie, wie wir Risiken in verschiedenen Umgebungen und Technologien reduzieren

Edge Computing
Erfahren Sie das Neueste von den Plattformen, die die Operations am Edge vereinfachen

Infrastruktur
Erfahren Sie das Neueste von der weltweit führenden Linux-Plattform für Unternehmen

Anwendungen
Entdecken Sie unsere Lösungen für komplexe Herausforderungen bei Anwendungen
Virtualisierung
Erfahren Sie das Neueste über die Virtualisierung von Workloads in Cloud- oder On-Premise-Umgebungen