
In diesem Artikel werden die technischen Maßnahmen von Red Hat zur Unterstützung der Ausführung einer Oracle Database 19c-Einzelinstanz auf Red Hat OpenShift Virtualization erläutert. Die Lösung bietet eine umfassende Referenzarchitektur, Validierungsergebnisse zu Funktionalität, Performance, Skalierbarkeit und Live Migration sowie Links zu Testartefakten, die auf GitHub gehostet werden.
Wir zeigen, dass OpenShift Virtualization eine robuste Performance für anspruchsvolle Produktions-Workloads wie Oracle-Datenbanken bietet und damit eine praktikable Virtualisierungsalternative darstellt, ohne Performance einzubüßen. Dies gilt insbesondere für Führungskräfte, Architektur-, Engineering- und Projektmanagementteams, die an der Evaluierung und Einführung einer Oracle Database-Einzelinstanz auf OpenShift Virtualization beteiligt sind.
Die Prinzipien des Architekturdesigns konzentrieren sich auf die Ressourcenzuweisung, Partitionierung und Optimierung der Abstraktionsschichten für Rechenleistung, Netzwerk und Storage. Performancetests mit HammerDB und dem TPC-C-Benchmark beweisen, dass Oracle Database erfolgreich auf OpenShift Virtualization mit lokalem NVMe-Storage ausgeführt werden kann und dabei eine bessere Performance bietet als Red Hat OpenShift Data Foundation. Dieser Artikel konzentriert sich auch auf Beobachtbarkeit und Monitoring mit Prometheus und Grafana für Infrastruktur- und Oracle-spezifische Insights.
Hintergrund
Viele Kunden suchen nach Virtualisierungsalternativen, ohne Performance einzubüßen. OpenShift Virtualization bietet eine robuste Performance für anspruchsvolle Produktions-Workloads, darunter auch Unternehmensdatenbanken.
Eine der häufigsten Komponenten in der traditionellen Softwarearchitektur ist Oracle Database. Red Hat unterstützt Kunden, die Oracle Database auf OpenShift Virtualization testen und einführen möchten, mit speziellen Engineering-Ressourcen, die ein optimiertes Erlebnis beim Betrieb von Oracle Database auf OpenShift Virtualization bieten.
In diesem Artikel wird angenommen, dass die Lesenden über Kenntnisse von Red Hat OpenShift Container Platform verfügen. Wir haben nicht vor, die generische Architektur von Oracle Database oder das Performance Tuning zu erörtern. Stattdessen erklären wir die Architekturoptionen zum Einrichten und Konfigurieren von OpenShift Virtualization, damit Oracle Database die bestmögliche Performance erzielen kann.
Dieser Beitrag richtet sich an folgende Fachleute, die an der Evaluierung, Validierung und Entscheidung über die Einführung von Oracle Single Instance Database auf OpenShift Virtualization beteiligt sind:
- IT-Führungskräfte (wie VPs, CTOs): Stakeholder, die für die Optimierung des ROI (Return on Investment) und TCO (Gesamtbetriebskosten) der täglichen Abläufe bei der Ausführung von Oracle Database-Workloads in Hybrid- oder On-Premise-Cloud-Szenarien verantwortlich sind.
- Architekturteams: Die Architekturteams von Kunden können die Referenzarchitektur und die Testergebnisse überprüfen, um zu beurteilen, ob OpenShift Virtualization eine geeignete Plattform für das Hosting von Oracle Database-Workloads in ihrem Unternehmen ist. Dieser Artikel enthält die Architekturanforderungen und ermöglicht Architekturteams das Ausführen unabhängiger Validierungen.
- Engineering-Teams: Engineering-Teams können die von Red Hat während dieser Evaluierung verwendeten Performancetests sowie die wiederverwendbaren Artefakte auf GitHub nutzen, um ihr Testsetup und die Automatisierung zu beschleunigen und den Validierungsprozess zu optimieren.
- Projektmanagementteams: Projektmanagementteams können die Referenzarchitekturen verwenden, um betroffene Komponenten und verantwortliche Teams zu ermitteln. Sie können auch die standardisierten Tests verwenden.
Architektur von OpenShift Virtualization – Überblick
OpenShift Virtualization ist die Red Hat Implementierung des Open Source-Projekts KubeVirt. Die Lösung baut auf der OpenShift-Standardplattform auf. Eine virtuelle Maschine (VM) wird in einem containerisierten Pod ausgeführt. OpenShift Container Platform verwaltet VMs genauso wie Pods, wobei eine VM-Instanz Zugriff auf dieselben Plattformservices (einschließlich Sicherheit, Netzwerk und Storage) hat wie eine normale Container-Anwendung. Der einzige Unterschied besteht darin, dass die VM im Gegensatz zu regulären Workload-Anwendungen, die in Containern ausgeführt werden, direkt auf Pod-Ebene verwaltet wird.
Komponenten der Architektur:
- Kernel-based Virtual Machine (KVM): Der VM-Hypervisor auf OpenShift ist Teil des Linux-Kernels.
- VMI (Virtual Machine Instance): Die einzelnen VMs, die durch eine VMI dargestellt werden, werden von QEMU mit KVM zur Emulation der Hardware erstellt. QEMU erstellt eine Isolation auf Benutzerbereichsebene.
- KubeVirt: Kubernetes-Add-on zum Verwalten von VMs als Kubernetes-Ressourcen, sodass VMs wie ein Pod aussehen.
virt-operator: Verwaltet Installation und Updates der KubeVirt-Komponenten.virt-controller: Übernimmt das VM-Lifecycle Management (wie etwa Neustart bei Fehlern, Skalierung).virt-handler: Ein Daemon auf einem KubeVirt-fähigen Knoten zum Verwalten von VMs auf Hosts mit KVM/QEMU.virt-launcher: Eine Instanz pro VM-Pod, fungiert als Orchestrator, der den QEMU/KVM-Prozess der virtuellen Maschine im Pod verwaltet.- Custom Resources (CRs): Stellen eine VM-Definition, die Ausführung einer VM-Instanz und die Planung/Richtlinien dar.
- Pod Wrapper: Dient als Wrapper für den QEMU-Prozess. VMI wird im Pod als virtualisiertes Guest-Betriebssystem ausgeführt.
- Storage: OpenShift Virtualization unterstützt eine Vielzahl von Storage-Lösungen, darunter zahlreiche Kubernetes-native Optionen wie OpenShift Data Foundation, Portworx und traditionellere Unternehmenslösungen wie iSCSI, Fiber Channel (FC) SAN Storage und andere. Die Kubernetes-native Storage-Lösung OpenShift Data Foundation, die auf dem Open Source-Projekt Ceph basiert, bietet skalierbaren, redundanten Storage mit einer Abstraktionsschicht, die für Kubernetes-Umgebungen optimiert ist. OpenShift Data Foundation unterstützt auch die dynamische Provisionierung von Persistent Volumes (PVs) und Persistent Volume Claims (PVCs) und vereinfacht so die Storage-Verwaltung.
Für dieses Projekt zur Validierung von Oracle Database werden mehrere Storage-Alternativen in Betracht gezogen. Aufgrund seiner nahtlosen Integration mit Kubernetes steht OpenShift Data Foundation im Rahmen dieses Dokuments im Vordergrund. Beim Deployment von Oracle Database-Workloads ist es wichtig, die Storage-Lösung zu evaluieren und auszuwählen, die Ihren Performance- und Betriebsanforderungen am ehesten entspricht.
Netzwerk: VMs greifen über Multus (CNI-Meta-Plugin) oder SR-IOV (Single Root I/O-Virtualisierung) auf das Netzwerk zu, wobei Multus auf Pod-Ebene definiert wird.
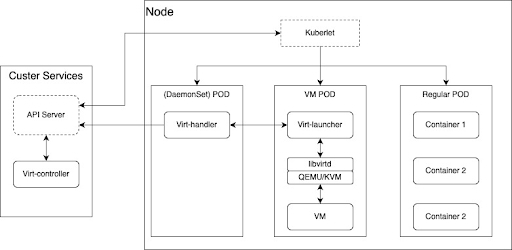

Designprinzipien von Oracle Database
Wenn eine Oracle Datenbase-Instanz auf einem virtualisierten Betriebssystem ausgeführt wird, ist die VM dafür verantwortlich, dass die Datenbank ausreichende Systemressourcen erhält, um effizient zu arbeiten und resilient zu bleiben. Da die Infrastrukturressourcen in der Praxis begrenzt sind, muss die Infrastrukturarchitektur sorgfältig konzipiert werden, um die Ressourcenzuweisung auszugleichen und den unterschiedlichen Anforderungen verschiedener Workloads gerecht zu werden.
Ein gängiger Architekturansatz zur Steigerung der Performance von Oracle Database auf Infrastrukturebene umfasst die folgenden Prinzipien:
- Ressourcenstandort: Weisen Sie ausreichende Ressourcen in Bezug auf Rechenleistung, Storage und Netzwerk zu, um Engpässe zu vermeiden.
- Ressourcenpartitionierung: Partitionieren Sie bei begrenzten Ressourcen den Ressourcenbedarf, und implementieren Sie maßgeschneiderte Lösungen, um spezifische Anforderungen zu erfüllen.
- Optimierung der Abstraktionsschicht: Vermeiden Sie unnötige oder geringwertige Abstraktionsschichten, und erhalten Sie im Gegenzug Flexibilität für Performancegewinne.
Oracle Database ist in hohem Maße von 3 primären Arten von Systemressourcen abhängig:
- Rechenleistung: Dazu gehören vCPUs, IO Threads, Arbeitsspeicher und die Fähigkeit zur knotenübergreifenden Skalierung.
- Netzwerk: Oracle Database reagiert sehr empfindlich auf die I/O-Performance. Client-Zugriff und Storage-Zugriff haben unterschiedliche Anforderungen an Durchsatz und Latenz. Daher werden bei Oracle Database-Architekturen häufig separate Netzwerke für verschiedene Datenverkehrstypen verwendet.
- Storage: Redo-Logs, Datenbanktabellen und Backups haben unterschiedliche Performanceanforderungen für Lese-/Schreibvorgänge. Wenn möglich, sollten Sie diese auf einem separaten physischen Storage platzieren, um eine optimale I/O-Performance sicherzustellen.
OpenShift Virtualization bietet die Funktionen und die Flexibilität, die zur Unterstützung verschiedener Ansätze für die Ressourcenzuweisung basierend auf den Partitionierungsanforderungen der Systemressourcen erforderlich sind.
Referenzarchitektur
In diesem Abschnitt werden die Aspekte und Lösungsoptionen für die Architektur beim Design von Oracle Database auf OpenShift Virtualization erläutert.
Rechenleistung
Stellen Sie sicher, dass Oracle Database über ausreichende Rechenressourcen verfügt und die OpenShift Virtualization-Plattform direkte Kontrolle über Folgendes bietet:
- Konfigurieren der vCPU- und RAM-Zuweisung für die vertikale Skalierung der Ressourcen
- Erweiterbarkeit des OpenShift Virtualization-Clusters für horizontale Skalierbarkeit
- Kontrolle der Zuweisung der VM-IO-Thread-Anzahl zur Vermeidung von I/O-Engpässen auf Pod-Ebene
- Vermeidung einer Überbelegung der Ressourcen für VMs, die Oracle Database-Workloads hosten, und Zuweisung von mehr virtualisierten CPUs oder Arbeitsspeicher, als physische Ressourcen im System vorhanden sind
Netzwerk
Der Datenverkehr von Oracle Database hat unterschiedliche Performanceanforderungen in Bezug auf Netzwerklatenz, Durchsatz und Zuverlässigkeit. Der OpenShift Container Platform-Pod Multus ist eine Funktion zum Partitionieren von Netzwerkdatenverkehr und zum Vermitteln mehrerer Netzwerkprotokolle. Beachten Sie Folgendes:
- Implementierung verschiedener Netzwerkpfade für OpenShift SDN, Storage und virtuelle Maschinen
- Bei Oracle RAC Database-Installationen Trennung des Netzwerkdatenverkehrs für die Interconnect-Kommunikation zwischen den RAC-Instanzen und die Kommunikation im „öffentlichen“ Netzwerk
- Bei geschäftskritischen Workloads, die empfindlich auf Latenz und Durchsatz reagieren, Nutzen von SR-IOV für virtuelle Netzwerkschnittstellen, um einen direkten Pfad von der VM zu den zugrunde liegenden physischen Ressourcen zu schaffen
Storage
Wie bereits erwähnt, unterstützt OpenShift Virtualization eine breite Palette an Storage-Lösungen, von Kubernetes-nativen Optionen wie OpenShift Data Foundation und Portworx bis hin zu traditionellen Unternehmenssystemen wie iSCSI und Fiber Channel (FC) SAN. Dank dieser Flexibilität können Nutzende den Storage wählen, der ihren Performance- und Betriebsanforderungen am ehesten entspricht.
Obwohl es keine allgemeine Regel für die Auswahl einer geeigneten Storage-Option gibt, können die folgenden Grundsätze als Richtlinien verwendet werden:
- Gleichgewicht zwischen der Notwendigkeit operativer Flexibilität (einfache Provisionierung, Integration in die Plattform) und den Anforderungen an die Performance (I/O-Latenz, Durchsatz)
- Unterstützung für Multi-Write-Option (Shared Volume zwischen 2 oder mehr VMs), die möglicherweise für Oracle RAC Database erforderlich sind
Hardwarekonfiguration
Die Gestaltung der anfänglichen Performancetests wurde auf derzeit verfügbare Hardwareressourcen beschränkt.
Cluster-Spezifikation:
- 4 x Dell R660-Server
- 128 CPU-Threads (2 Sockets von Intel Xeon Gold 6430)
- 256 GB Arbeitsspeicher
- 1 TB Root-Disk
- 4 x 1,5 TB NVME-Laufwerke
- 4 x 25 Gbit/s Broadcom-NIC
- 2 x 25 Gbit/s Intel 810-NIC
Konfiguration von OpenShift Virtualization
Während die Standardkonfiguration für OpenShift Virtualization und OpenShift Data Foundation Storage eine angemessene Performance bietet, wurden weitere Konfigurationsänderungen vorgenommen, um die Testplattform für I/O-intensive Workloads zu optimieren, die typisch für Datenbanken sind:
- OpenShift Data Foundation wurde für die Verwendung eines Performanceprofils konfiguriert.
- OpenShift Data Foundation und OpenShift Virtualization wurden so konfiguriert, dass der Datenverkehr von OpenShift Data Foundation Storage vom allgemeinen SDN-Datenverkehr (OpenShift Container Platform Software Defined Network) getrennt wurde. (Chapter 8. Network requirements | Planning your deployment | Red Hat OpenShift Data Foundation | 4.18)
- Der Datenverkehr für virtuelle Maschinen (Oracle Database und HammerDB-Testumgebung) wurde von OpenShift Data Foundation Storage und OpenShift Container Platform-SDN über separate physische Netzwerkschnittstellen getrennt. Um die Latenz zu reduzieren und den Durchsatz zu erhöhen, wurden Netzwerkschnittstellen mit SR-IOV (Single Root I/O-Virtualisierung) für die betroffenen virtuellen Maschinen verwendet (Abbildung 2).
Cluster-Spezifikation:
- OpenShift-Version: 4.18.9
- OpenShift Virtualization: Aktiviert über OperatorHub
- Knoten:
- 3 x Hybrid-Knoten (Control Plane/Worker/Storage).
- 1 x Workerknoten
- Networking (spezifisch für Oracle Database-VMs):
- LACP-Bond mit 4 Broadcom-NICs mit 25 Gbit/s, die zur Trennung von OpenShift SDN, OpenShift Data Foundation Storage-Client und OpenShift Data Foundation Storage-Replikationsdatenverkehr partitioniert sind.
- 2 Intel x810-NICs mit 25 GB für VM-Datenverkehr mit 2 verschiedenen Subnetzen (öffentlich und privat), die so konfiguriert sind, dass sie virtuellen Maschinen mit SR-IOV bereitgestellt werden.
- Storage (spezifisch für Oracle Database-VMs): OpenShift Data Foundation Storage (unterstützt von 4 NVMe-Laufwerken mit jeweils 1,5 TB), konfiguriert mit dem Performanceprofil und mit separatem Storage-Netzwerk.
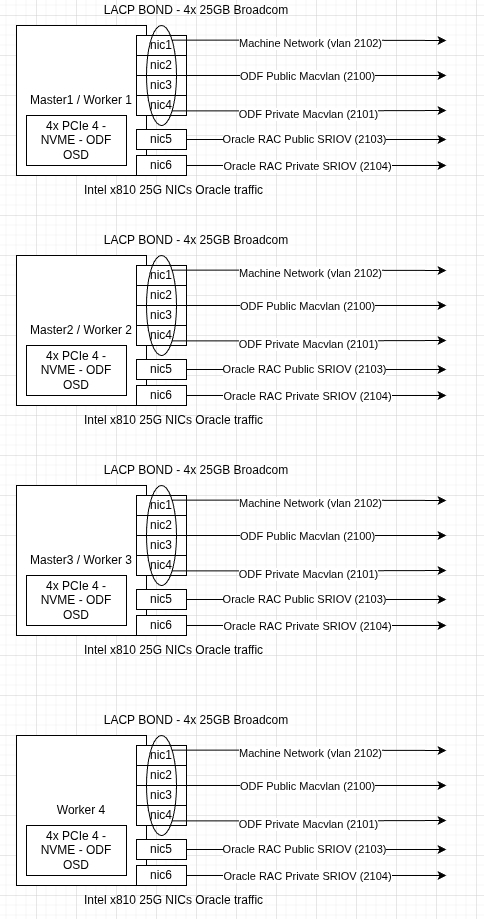

Konfiguration von Oracle Database
Die virtuelle Maschine (VM) zum Hosten von Oracle Database ist mittelgroß, um eine Überbelegung der Ressourcen zu vermeiden und Testergebnisse auf verschiedenen Hardwareoptionen zu vergleichen. Oracle Database wurde nicht speziell für den TPC-C-Test (Transaction Processing Performance Council Benchmark C) optimiert und verwendet größtenteils eine Standardkonfiguration, mit Ausnahme der wenigen allgemeinen Tuning-Änderungen, die auf Best Practices basieren.
Wir haben die Tuning-Parameter basierend auf der Größe der virtuellen Maschine, den Besonderheiten der Benchmark-Test-Workload und den Monitoring-Informationen ausgewählt. Wir haben die Effektivität der einzelnen Änderungen bewertet, indem wir die Testergebnisse mit den Baseline-Werten verglichen haben. Die Konfiguration von Oracle Database kann gemäß den Empfehlungen im Database Performance Tuning Guide weiter optimiert werden.
Abbildung 3 zeigt, dass der Zugriff auf den Oracle Database- und den HammerDB-Client im selben Netzwerk stattfand. Daten-Volumes für virtuelle Maschinen sind so konfiguriert, dass Disk-Speicherplatz vorab zugewiesen wird, um die Schreibvorgänge zu verbessern.
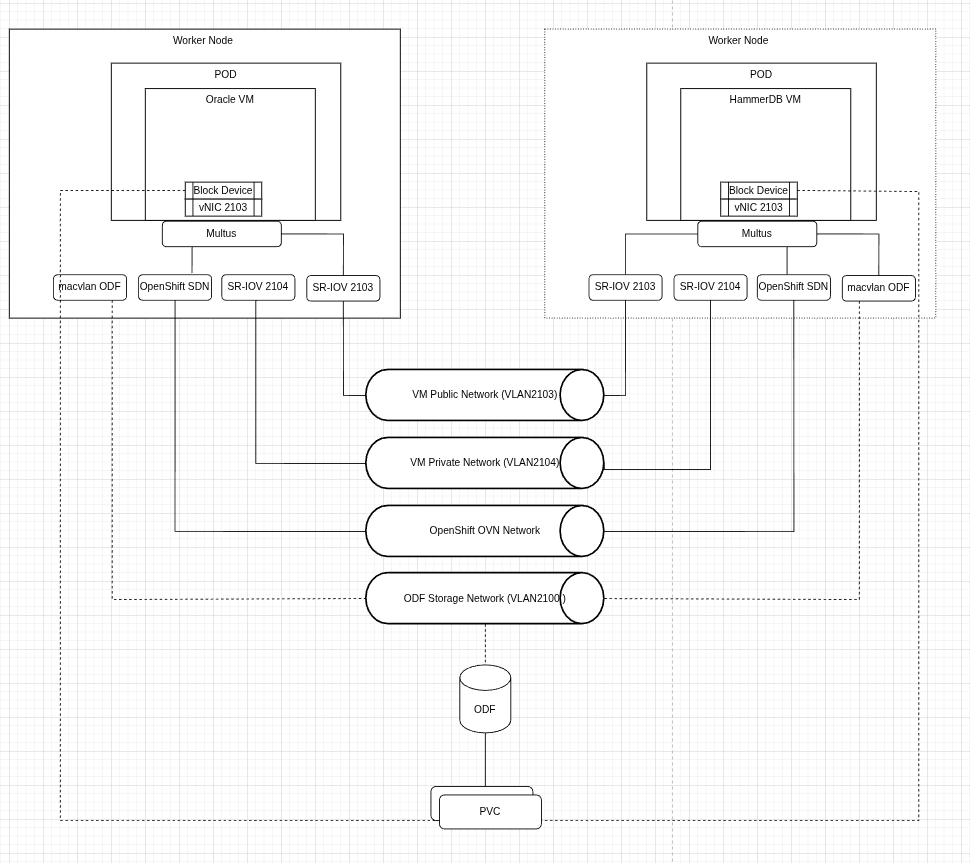
Wir haben separate Ad-hoc-Tests durchgeführt, um die Auswirkungen des Storage auf die Performance der Datenbank zu bewerten, indem wir NVMe-Storage mithilfe eines Local Storage Operators hinzugefügt haben.
VM-Spezifikation:
- Betriebssystem: RHEL 8.10
- VM-Anzahl: 1
- vCPU: 16
- Arbeitsspeicher: 48 GB
- Storage: 250 GB (Root- und DB-Daten befinden sich auf demselben Volume) als Blockgerät von RH ODF
- DataVolume: Erstellt mit „preallocation: true“ (Thick Provisioning)
- Netzwerk: Über SR-IOV mit dem öffentlichen Subnetz verbunden
Oracle Database-Einzelinstanzsetup:
Oracle Database-Version: 19c Enterprise Edition mit Release Update 26 (Version 19.26)
- Die Datenbank ist mit einem Dateisystem als Ziel für Datendateien (Root-Volume mit über OpenShift Data Foundation gesichertem Storage) unter Verwendung von OMF (Oracle Managed Files) eingerichtet.
- Um die Kompatibilität des Tests mit zukünftigen Versionen von Oracle Database sicherzustellen, wurde die Datenbank mit der CDB-Architektur (Container-Datenbank) erstellt.
- Bei der Speicherzuweisung wurden insgesamt 32 GB Speicher (totalMemory) als Eingabe für den DB-Erstellungsassistenten verwendet (damit die Oracle Database-Installation die SGA/PGA-Aufteilung automatisch ermitteln kann).
- Zusätzliche Tuning-Parameter:
- 4 Datendateien manuell auf 32 GB erweitert
- Größe des REDO-Logs auf 4 GB angepasst
- 4 REDO-Log-Disk-Gruppen
- FILESYSTEMIO_OPTIONS: SETALL (ermöglicht asynchrones I/O und direktes I/O)
- USE_LARGE_PAGES: AUTO (zur Optimierung der CPU-Auslastung bei großen SGA-Größen)
Hinweis: Für die Performancetests mit NVME-gestütztem Storage wurde ein separates Dateisystem mit einem NVME-Gerät gemountet und als Ziel für die Datendateien zugewiesen.
Beobachtbarkeit und Monitoring
OpenShift bietet eine leistungsstarke, integrierte Beobachtbarkeitsplattform, die das Monitoring auf den Infrastruktur- und Anwendungsschichten konsolidiert. Die Lösung unterstützt nativ die Erfassung von Metriken, Protokollierung und Alarmierung und kann um Beobachtbarkeitsdaten aus externen Anwendungen wie Oracle-Datenbanken erweitert werden. Durch diesen einheitlichen Ansatz wird die operative Komplexität reduziert und gleichzeitig eine End-to-End-Transparenz ermöglicht.
Die Beobachtbarkeit für OpenShift Virtualization ist nahtlos in dieselbe Plattform integriert und ermöglicht Ihnen so das Monitoring von virtuellen Maschinen, Systemressourcen und Workloads (d. h. Oracle-Datenbanken innerhalb eines einzigen, konsistenten Monitoring Stacks).
Der in OpenShift bereitgestellte Oracle Database Observability Exporter erfasst Performancemetriken und Metadaten von Oracle Database, die für Prometheus zur Verfügung gestellt werden. Grafana visualisiert diese Metriken und stellt Echtzeit-Dashboards bereit, um ungewöhnliche Muster, Ressourcendruck und Performanceprobleme in den Oracle Database- und VM-Schichten zu erkennen.
Zur Verbesserung der Analyse auf Datenbankebene können Sie HammerDB bei Performancetests nutzen, um Snapshots zu erfassen und AWR-Berichte (Automatic Workload Repository) zu generieren. In Kombination mit Metriken von Prometheus und Grafana bieten diese Berichte ein umfassenderes, multidimensionales Verständnis des Workload-Verhaltens und potenzieller Engpässe.
Oracle Database Enterprise Manager dient außerdem als ergänzendes Tool mit detaillierten Diagnosen und speziellen Monitoring-Funktionen, die auf Oracle-Datenbanken zugeschnitten sind. In Verbindung mit der einheitlichen Beobachtbarkeitsplattform von OpenShift lässt sich so eine umfassende Abdeckung für Infrastruktur- und Oracle Database-spezifische operative Insights sicherstellen.
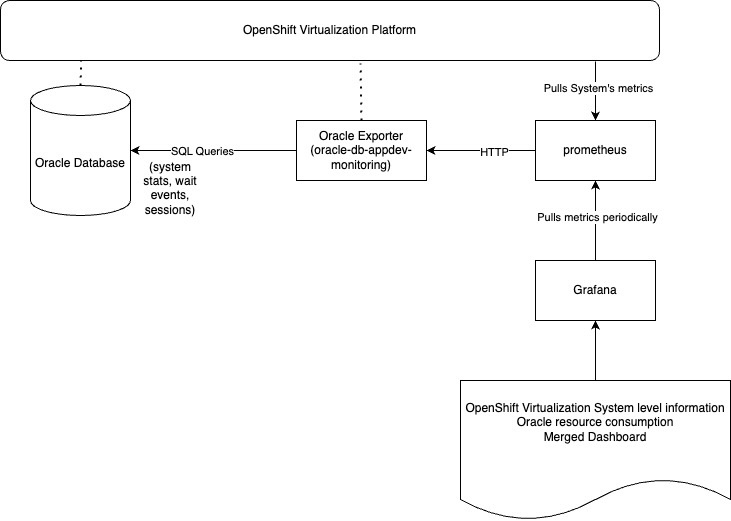

Abbildung 5 zeigt ein Beispiel für ein Grafana-Dashboard, das als Teil des Beobachtbarkeits- und Monitoring-Setups für die OpenShift Virtualization-Plattform bereitgestellt wird.
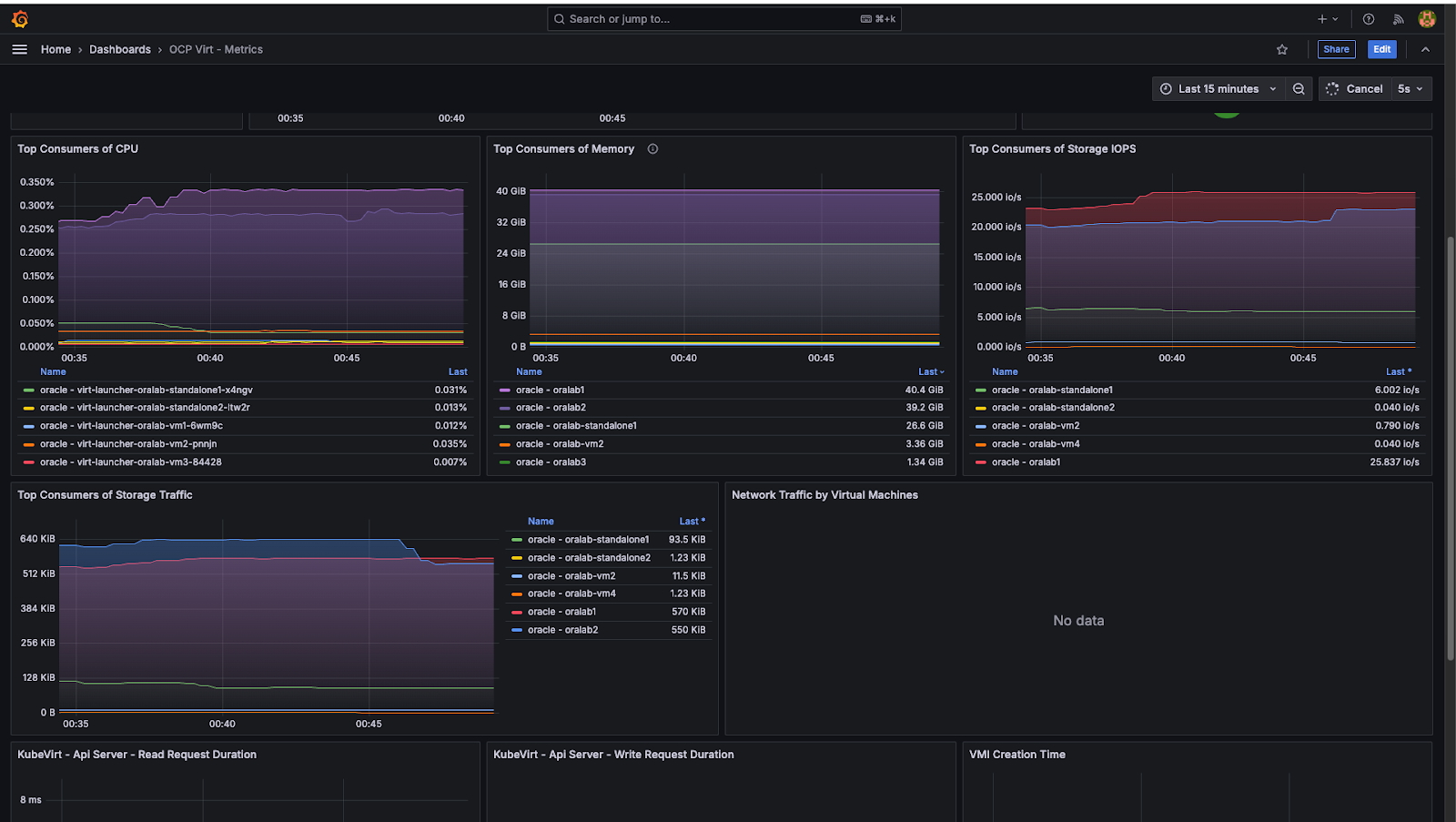

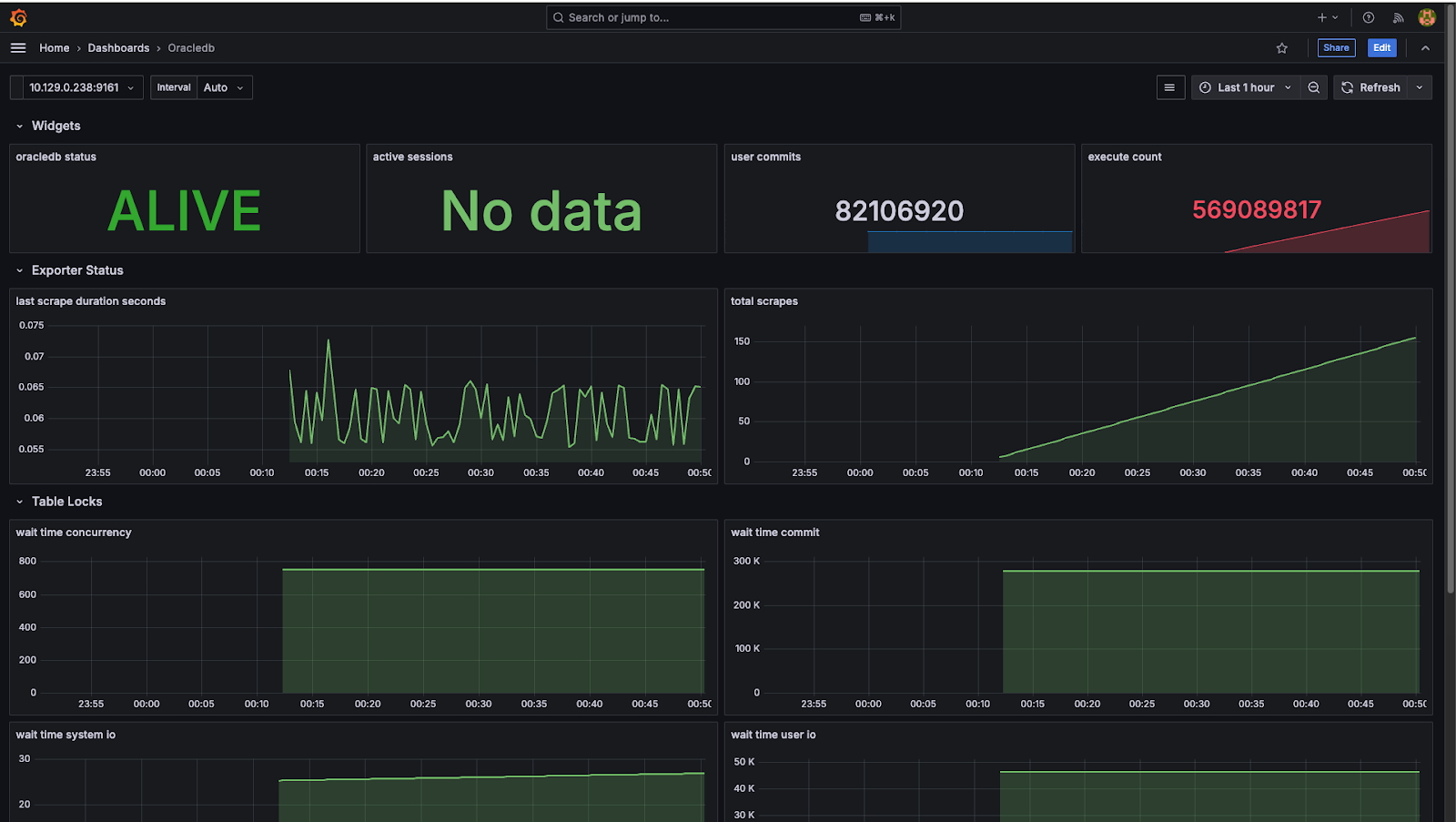
Abbildung 6 zeigt ein Beispiel für ein Grafana-Dashboard von Oracle Database, das auf der OpenShift Virtualization-Plattform bereitgestellt wird.

Evaluierung der Systemperformance
Der Performancetest wurde so konzipiert, dass der Durchsatz von Datenbanktransaktionen und die Abfragelatenz für OLTP-Workloads (Online Transaction Processing) gemessen werden. Wir haben HammerDB verwendet, eine Open Source-Software zum Testen der Datenbankperformance, um OLTP-Workloads mit dem TPC-C-Benchmark im Vergleich zu einer Oracle Database-Einzelinstanz und den zuvor genannten Systemdetails zu simulieren. Der TPC-C-Test simuliert ein reales Auftragsmanagementsystem mit einer Mischung aus 80 % Schreibvorgängen und 20 % Lesevorgängen, einschließlich sehr häufiger Kundenbestellungen, Zahlungen, Bestandsprüfungen und Batch-Lieferungen. Die Testausführung beinhaltet, dass HammerDB TPC-C-Workloads auf Oracle Database in OpenShift Virtualization generiert.
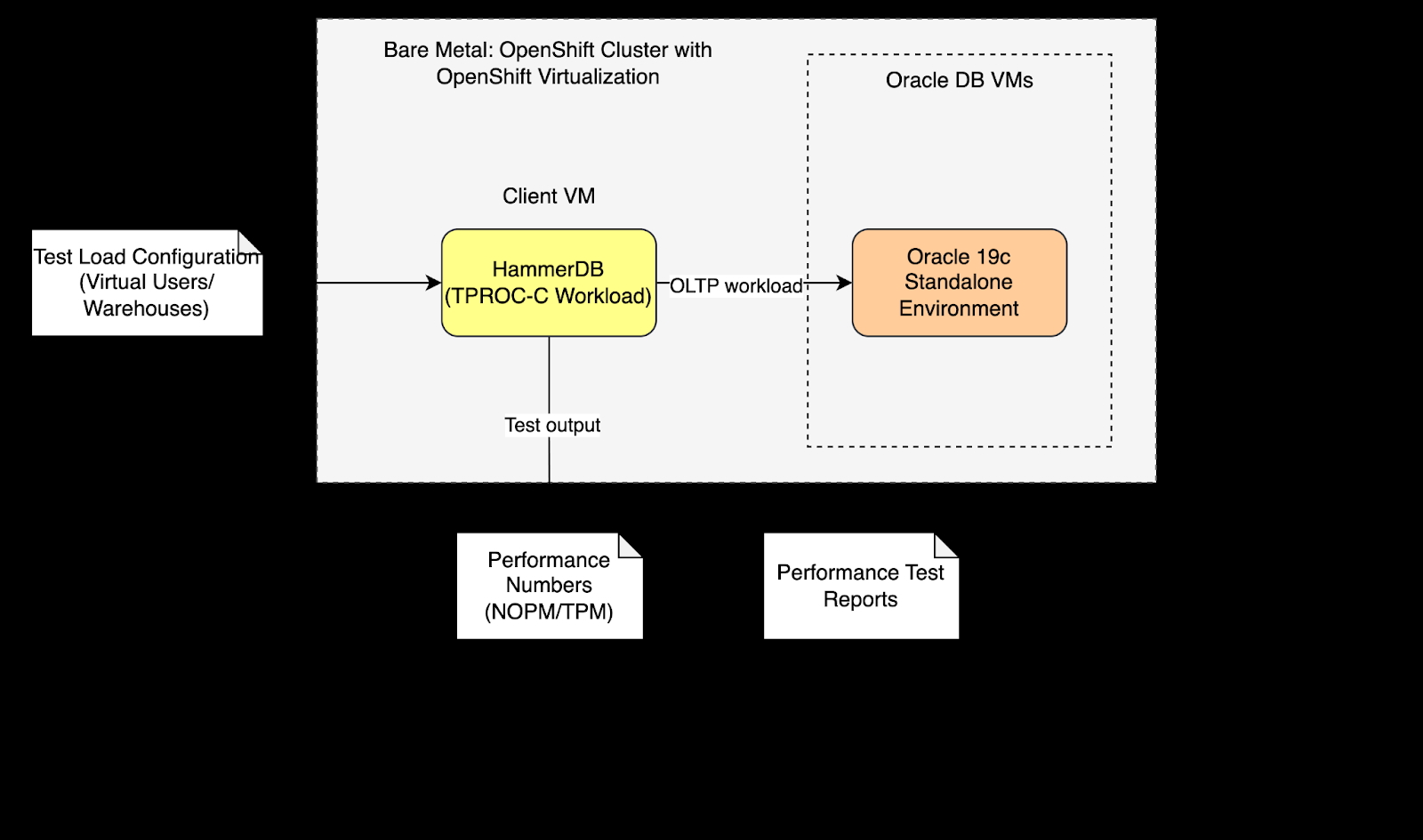

Zusammenfassung der Testabdeckung
Mit der HammerDB-Testumgebung wurde das Scale-Run-Profil so konfiguriert, dass es aussagekräftige Workloads mit einer Anzahl virtueller Nutzender von zunächst 20 bis maximal 100 simulierte, wobei 500 Warehouses bei einem jeweiligen Testlauf von 20 Minuten verwendet wurden. Wir haben dieses Setup entwickelt, um realistische Produktionsszenarien abzubilden und die Performance des Systems unter skalierten Transaktionslasten zu evaluieren.
Basierend auf der Referenzarchitekturkonfiguration zeigten die Testergebnisse starke Metriken für „Neubestellungen pro Minute“ (NOPM) und „Transaktionen pro Minute“ (TPM) für eine Oracle Database-Einzelinstanz und OpenShift Data Foundation Storage. Eine Oracle Database-Einzelinstanz mit lokalem NVMe-Storage bot jedoch eine bessere Performance im Vergleich zum OpenShift Data Foundation-Setup. Obwohl die durchschnittliche Latenz relativ stabil blieb, beobachteten wir gelegentliche Spitzen.
Zusammenfassung
OpenShift Virtualization ist eine realisierbare und funktionsfähige Plattform für das Deployment von Oracle Database 19c-Workloads. Das unkomplizierte Setup von OpenShift Virtualization bietet robusten Support für das Erstellen virtueller Maschinen. In Anbetracht dieser Faktoren ist OpenShift Virtualization ein ernsthafter Kandidat und eine Alternative zu konkurrierenden Angeboten für Virtualisierungstechnologien. Die aktuelle Performancevalidierung von Oracle Database 19c zeigt eine unternehmensgerechte Performance auf der OpenShift Virtualization-Plattform.
Durch Ad-hoc-Tests mit lokalem NVMe-Storage konnten wir die Auswirkungen von hochleistungsfähigen Storage-Optionen bewerten und deutliche Hinweise dafür finden, dass ein Upgrade zu hochleistungsfähigen Storage-Lösungen wie FC SAN die allgemeine Performance erheblich verbessern kann.
Ziehen Sie für leistungsstarke Workloads Folgendes in Betracht:
- Hochleistungsfähige Storage-Optionen wie FC SAN für Oracle Database-Datendateien und Redo-Logs zur Performanceoptimierung
- Segmentieren des Netzwerk für virtuelle Maschinen, OpenShift SDN und Storage-Netzwerk, vorzugsweise unter Verwendung separater physischer Geräte auf OpenShift Virtualization-Knoten
- SR-IOV (Single Root I/O-Virtualisierung), sofern von der Hardware unterstützt, zur Optimierung der Performance von virtuellen Netzwerkschnittstellen von virtuellen Maschinen, die Oracle Database-Workloads hosten
- HugePages mit der Oracle Database-Einstellung
USE_LARGE_PAGESbasierend auf Ihren Workload-Anforderungen: Bei dieser Konfiguration wird die Größe der Speicherseite angepasst. Sie wird für eine verbesserte Performance empfohlen, insbesondere bei SGAs, die größer als die Standardeinstellungen sind.
HammerDB-Testskripts finden Sie in diesem GitHub-Repository.
Das GitHub-Projekt oracle-db-appdev-monitoring zielt darauf ab, die Beobachtbarkeit für Oracle Database zu verbessern, damit Nutzende die Performance verstehen und Probleme in verschiedenen Anwendungen und Datenbanken leicht diagnostizieren können. Lesen Sie die Anweisungen zum Einrichten des Projekts auf der OpenShift-Plattform.
Produkttest
Red Hat Learning Subscription | Testversion
Über die Autoren
Ähnliche Einträge
IT-Stack vereinheitlichen: VMs, Cloud und KI vereint
Erlernen Sie OpenShift Virtualization: 7 Trainingsressourcen, die Ihnen den Einstieg erleichtern
Nach Thema durchsuchen

Automatisierung
Das Neueste zum Thema IT-Automatisierung für Technologien, Teams und Umgebungen

Künstliche Intelligenz
Erfahren Sie das Neueste von den Plattformen, die es Kunden ermöglichen, KI-Workloads beliebig auszuführen

Open Hybrid Cloud
Erfahren Sie, wie wir eine flexiblere Zukunft mit Hybrid Clouds schaffen.

Sicherheit
Erfahren Sie, wie wir Risiken in verschiedenen Umgebungen und Technologien reduzieren

Edge Computing
Erfahren Sie das Neueste von den Plattformen, die die Operations am Edge vereinfachen

Infrastruktur
Erfahren Sie das Neueste von der weltweit führenden Linux-Plattform für Unternehmen

Anwendungen
Entdecken Sie unsere Lösungen für komplexe Herausforderungen bei Anwendungen
Virtualisierung
Erfahren Sie das Neueste über die Virtualisierung von Workloads in Cloud- oder On-Premise-Umgebungen