
The newest release of Red Hat’s Reference Architecture “OpenShift Container Platform 3.5 on Amazon Web Services” now incorporates container-native storage, a unique approach based on Red Hat Gluster Storage to avoid lock-in, enable stateful applications, and simplify those applications' high availability.
In the beginning, everything was so simple. Instead of going through the bureaucracy and compliance-driven process of requesting compute, storage, and networking resources, I would pull out my corporate credit card and register at the cloud provider of my choice. Instead of spending weeks forecasting the resource needs and costs of my newest project, I would get started in less than 1 hour. Much lower risk, virtually no capital expenditure for my newest pet project. And seemingly endless capacity—well, as long as my credit card was covered. If my project didn’t turn out to be a thing, I didn’t end up with excess infrastructure, either.
Until I found out that basically what I was doing was building my newest piece of software against a cloud mainframe. Not directly, of course. I was still operating on top of my operating system with the libraries and tools of my choice, but essentially I spend significant effort getting to that point with regards to orchestration and application architecture. And these are not easily ported to another cloud provider.
I realize that cloud providers are vertically integrated stacks, just as mainframes were. Much more modern and scalable with an entirely different cost structure—but, still, eventually and ultimately, lock-in.
Avoid provider lock-in with OpenShift Container Platform
This is where OpenShift comes in. I take orchestration and development cycles to a whole new level when I stop worrying about operating system instances, storage capacity, network overlays, NAT gateways, firewalls—all the things I need to make my application accessible and provide value.
Instead, I deal with application instances, persistent volumes, services, replication controllers, and build configurations—things that make much more sense to me as an application developer as they are closer to what I am really interested in: deploying new functionality into production. Thus, OpenShift offers abstraction on top of classic IT infrastructure and instead provides application infrastructure. The key here is massive automation on top of the concept of immutable infrastructure, thereby greatly enhancing the capability to bring new code into production.
The benefit is clear: Once I have OpenShift in place, I don’t need to worry about any of the underlying infrastructure—I don’t need to be aware of whether I am actually running on OpenStack, VMware, Azure, Google Cloud, or Amazon Web Services (AWS). My new common denominator is the interface of OpenShift powered by Kubernetes, and I can forget about what’s underneath.
Well, not quite. While OpenShift provides a lot of drivers for various underlying infrastructure, for instance storage, they are all somewhat different. Their availability, performance, and feature set is tied to the underlying provider, for instance Elastic Block Storage (EBS) on AWS. I need to make sure that critical aspects of the infrastructure below OpenShift are reflected in OpenShift topology. A good example are AWS availability zones (AZs): They are failure domains in a region across which an application instance should be distributed to avoid downtime in the event a single AZ is lost. So OpenShift nodes need to be deployed in multiple AZs.
This is where another caveat comes in: EBS volumes are present only inside a single AZ. Therefore, my application must replicate the data across other AZs if it uses EBS to store it.
So there are still dependencies and limitations a developer or operator must be aware of, even if OpenShift has drivers on board for EBS and will take care about provisioning.
Introducing container-native storage
With container-native storage (CNS), we now have a robust, scalable, and elastic storage service out-of-the-box for OpenShift Container Platform—based on Red Hat Gluster Storage. The trick: GlusterFS runs containerized on OpenShift itself. Thus, it runs on any platform that OpenShift is supported on—which is basically everything, from bare metal, to virtual, to private and public cloud.
With CNS, OpenShift gains a consistent storage feature set across, and independent of, all supported cloud providers. It’s deployed with native OpenShift / Kubernetes resources, and GlusterFS ends up running in pods as part of a DaemonSet:
[ec2-user@ip-10-20-4-55 ~]$ oc get pods NAME READY STATUS RESTARTS AGE glusterfs-0bkgr 1/1 Running 9 7d glusterfs-4fmsm 1/1 Running 9 7d glusterfs-bg0ls 1/1 Running 9 7d glusterfs-j58vz 1/1 Running 9 7d glusterfs-qpdf0 1/1 Running 9 7d glusterfs-rkhpt 1/1 Running 9 7d heketi-1-kml8v 1/1 Running 8 7d
The pods are running in privileged mode to access the nodes' block device directly. Furthermore, for optimal performance, the pods are using host-networking mode. This way, OpenShift nodes are running a distributed, software-defined, scale-out file storage service, just as any distributed micro-service application.
There is an additional pod deployed that runs heketi—a RESTful API front end for GlusterFS. OpenShift natively integrates via a dynamic storage provisioner plug-in with this service to request and delete storage volumes on behalf of the user. In turn, heketi controls one or more GlusterFS Trusted Storage Pools.
Container-native storage on Amazon Web Services
The EBS provisioner has been available for OpenShift for some time. To understand what changes with CNS on AWS, a closer look at how EBS is accessible to OpenShift is in order.
- Dynamic provisioning
EBS volumes are dynamically created and deleted as part of storage provisioning requests (PersistentVolumeClaims) in OpenShift.
. - Local block storage
EBS appears to the EC2 instances as a local block device. Once provisioned, it is attached to the EC2 instance, and a PCI interrupt is triggered to inform the operating system.NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT xvda 202:0 0 15G 0 disk ├─xvda1 202:1 0 1M 0 part └─xvda2 202:2 0 15G 0 part / xvdb 202:16 0 25G 0 disk └─xvdb1 202:17 0 25G 0 part ├─docker_vol-docker--pool_tmeta 253:0 0 28M 0 lvm │ └─... 253:2 0 23.8G 0 lvm │ ├─... 253:8 0 3G 0 dm │ └─... 253:9 0 3G 0 dm └─docker_vol-docker--pool_tdata 253:1 0 23.8G 0 lvm └─docker_vol-docker--pool 253:2 0 23.8G 0 lvm ├─... 253:8 0 3G 0 dm └─... 253:9 0 3G 0 dm xvdc 202:32 0 50G 0 disk xvdd 202:48 0 100G 0 disk
OpenShift on AWS also uses EBS to back local docker storage. EBS storage is formatted with a local filesystem like XFS..
- Not shared storage
EBS volumes cannot be attached to more than one EC2 instance. Thus, all pods mounting an EBS-based PersistentVolume in OpenShift must run on the same node. The local filesystem on top of the EBS block device does not support clustering either.
. - AZ-local storage
EBS volumes cannot cross AZs. Thus, OpenShift cannot failover pods mounting EBS storage into different AZs. Basically, an EBS volume is a failure domain.
. - Performance characteristics
The type of EBS storage, as well as capacity, must be selected up front. Specifically, for fast storage a certain minimum capacity must be requested to have a minimum performance level in terms of IOPS.
This is the lay of the land. While these characteristics may be acceptable for stateless applications that only need to have local storage, they become an obstacle for stateful applications.
People want to containerize databases, as well. Following a micro-service architecture where every service maintains its own state and data model, this request will become more common. The nature of these databases differs from the classic, often relational, database management system IT organizations have spent millions on: They are way smaller and store less data than their big brother from the monolithic world. Still, with the limitations of EBS, I would need to architect replication and database failover around those just to deal with a simple storage failure.
Here is what changes with CNS:
- Dynamic provisioning
The user experience actually doesn’t change. CNS is represented like any storage provider in OpenShift, by a StorageClass. PersistentVolumeClaims (PVCs) are issued against it, and the dynamic provisioner for GlusterFS creates the volume and returns it as a PersistentVolume (PV). When the PVC is deleted, the GlusterFS volume is deleted, as well.
. - Distributed file storage on top of EBS
CNS volumes are basically GlusterFS volumes, managed by heketi. The volumes are built out of local block devices of the OpenShift nodes backed by EBS. These volumes provide shared storage and are mounted on the OpenShift nodes with the GlusterFS FUSE client.[ec2-user@ip-10-20-5-132 ~]$ mount ... 10.20.4.115:vol_0b801c15b2965eb1e5e4973231d0c831 on /var/lib/origin/openshift.local.volumes/pods/80e27364-2c60-11e7-80ec-0ad6adc2a87f/volumes/kubernetes.io~glusterfs/pvc-71472efe-2a06-11e7-bab8-02e062d20f83 type fuse.glusterfs (rw,relatime,user_id=0,group_id=0,default_permissions,allow_other,max_read=131072) ...
- Container-shared storage
Multiple pods can mount and write to the same volume. The access mode for the corresponding node is known as “RWX”—read-write many. The containers can run on different OpenShift nodes, and the dynamic provisioner will mount the GlusterFS volume on the right nodes accordingly. Then, this local mount directory is bind-mounted to the container.
. - Cross-availability zone
CNS is deployed across AWS AZs. The integrated, synchronous replication of GlusterFS will mirror every write 3 times. GlusterFS is deployed across OpenShift nodes in at least different AZs, and thus the storage is available in all zones. The failure of a single GlusterFS pod, an OpenShift node running the pod, or a block device accessed by the pod will have no impact. Once the failed resources come back, the storage is automatically re-replicated. CNS is actually aware of the failure zones as part of the cluster topology and will schedule new volumes, as well as recovery, so that there is no single point of failure.
. - Predictable performance
CNS storage performance is not tied to the size of storage request by the user in OpenShift. It’s the same performance whether 1GB or 100GB PVs are requested.
. - Storage performance tiers
CNS allows for multiple GlusterFS Trusted Storage Pools to be managed at once. Each pool consists of at least 3 OpenShift nodes running GlusterFS pods. While the OpenShift nodes belong to a single OpenShift cluster, the various GlusterFS pods form their own Trusted Storage Pools. An administrator can use this to equip the nodes with different kinds of storage and offer their pools with CNS as distinct storage tiers in OpenShift, via its own StorageClass. An administrator instance might, for example, run CNS on 3 OpenShift nodes with SSD (e.g., EBS gp2) storage and call it “fast,” whereas another set of OpenShift nodes with magnetic storage (e.g., EBS st1) runs a separate set of GlusterFS pods as an independent Trusted Storage Pool, represented with a StorageClass called “capacity.”
This is a significant step toward simplifying and abstracting provider infrastructure. For example, a MySQL database service running on top of OpenShift is now able to survive the failure of an AWS AZ, without needing to set up MySQL Master-Slave replication or change the micro-service to replicate data on its own.
Storage provided by CNS is efficiently allocated and provides performance with the first Gigabyte provisioned, thereby enabling storage consolidation. For example, consider six MySQL database instances, each in need of 25 GiB of storage capacity and up to 1500 IOPS at peak load. With EBS, I would create six EBS volumes, each with at least 500 GiB capacity out of the gp2 (General Purpose SSD) EBS tier, in order to get 1500 IOPS guaranteed. Guaranteed performance is tied to provisioned capacity with EBS.
With CNS, I can achieve the same using only 3 EBS volumes at 500 GiB capacity from the gp2 tier and run these with GlusterFS. I would create six 25 GiB volumes and provide storage to my databases with high IOPS performance, provided they don’t peak all at the same time.
Doing that, I would halve my EBS cost and still have capacity to spare for other services. My read IOPS performance is likely even higher because in CNS with 3-way replication I would read from data distributed across 3x1500 IOPS gp2 EBS volumes.
Finally, the setup for CNS is very simple and can run on any OpenShift installation based on version 3.4 or newer.
This way, no matter where I plan to run OpenShift (i.e., which cloud provider currently offers lowest prices), I can rely on the same storage features and performance. Furthermore, the Storage Service grows with the OpenShift cluster but still provides elasticity. Only a subset of OpenShift nodes must run CNS, at least 3 ideally across 3 AZs.
Deploying container-native storage on AWS
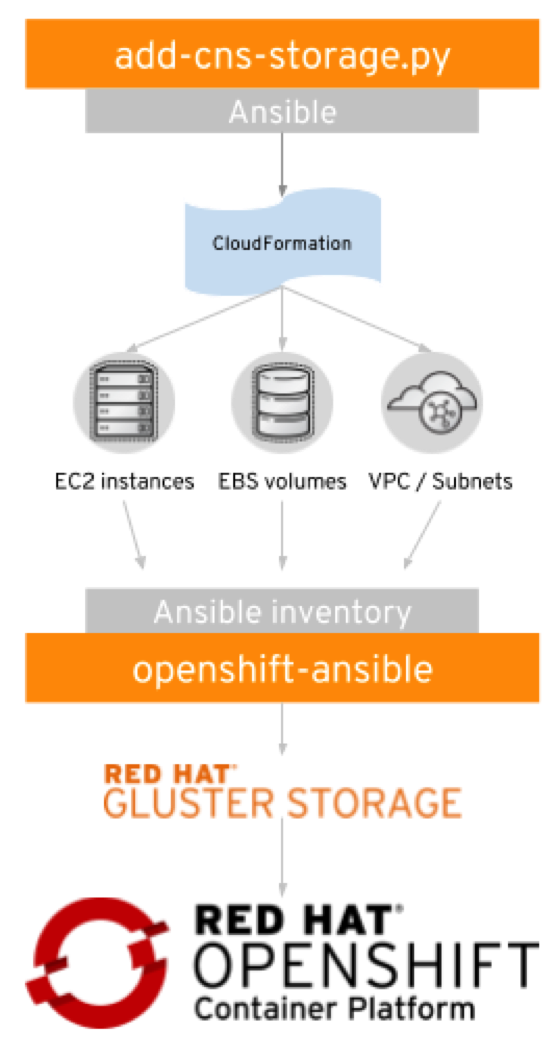
Installing OpenShift on AWS is dramatically simplified based on the OpenShift on Amazon Web Services Reference Architecture. A set of Ansible playbooks augments the existing openshift-ansible installation routine and creates all the required AWS infrastructure automatically.

A simple python script provides a convenient wrapper to the playbooks found in the openshift-ansible-contrib repository on GitHub for deploying on AWS.
All the heavy lifting of setting up Red Hat OpenShift Container Platform on AWS is automated with best practices incorporated.
The deployment finishes with an OpenShift Cluster with 3 master nodes, 3 infrastructure nodes, and 2 application nodes deployed in a highly available fashion across AWS AZs. The external and internal traffic is load balanced, and all required network, firewall, and NAT resources are stood up.
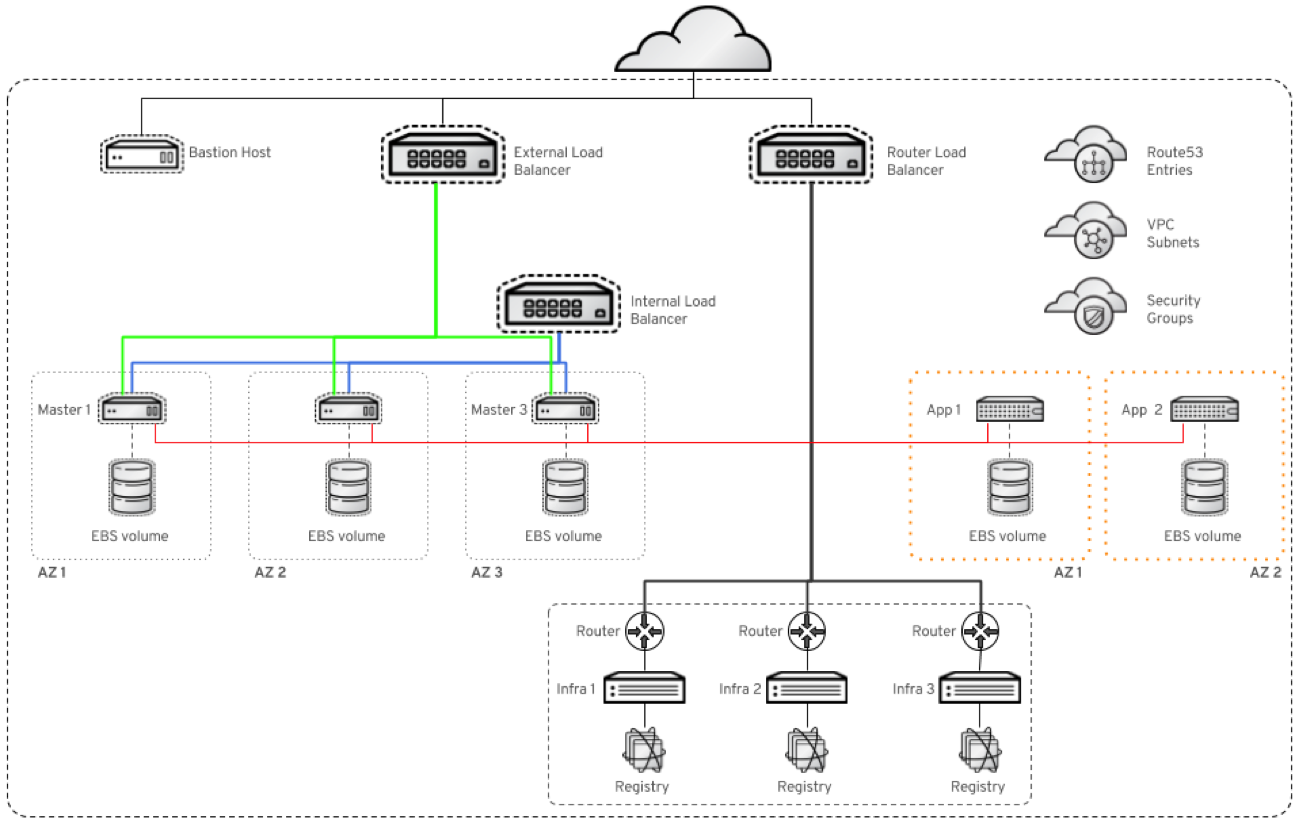
Since version 3.5, the reference architecture playbooks now ship with additional automation to make deployment of CNS as easy. Through additional AWS CloudFormation templates and Ansible playbook tasks, the additional, required infrastructure is stood up. This mainly concerns provisioning of additional OpenShift nodes with an amended firewall configuration, additional EBS volumes, and then joining them to the existing OpenShift cluster.
In addition, compared to previous releases, the CloudFormation templates now emit more information as part of the output. These are picked up by the playbooks to further reduce the information needed from the administrator. They will simply get the right information from the existing CloudFormation stack to retrieve the proper integration points.
The result is AWS infrastructure ready for the administrator to deploy CNS. Most of the manual steps of this process can therefore be avoided. Three additional app nodes are deployed with configurable instance type and EBS volume type. Availability zones of the selected AWS region are taken into account.
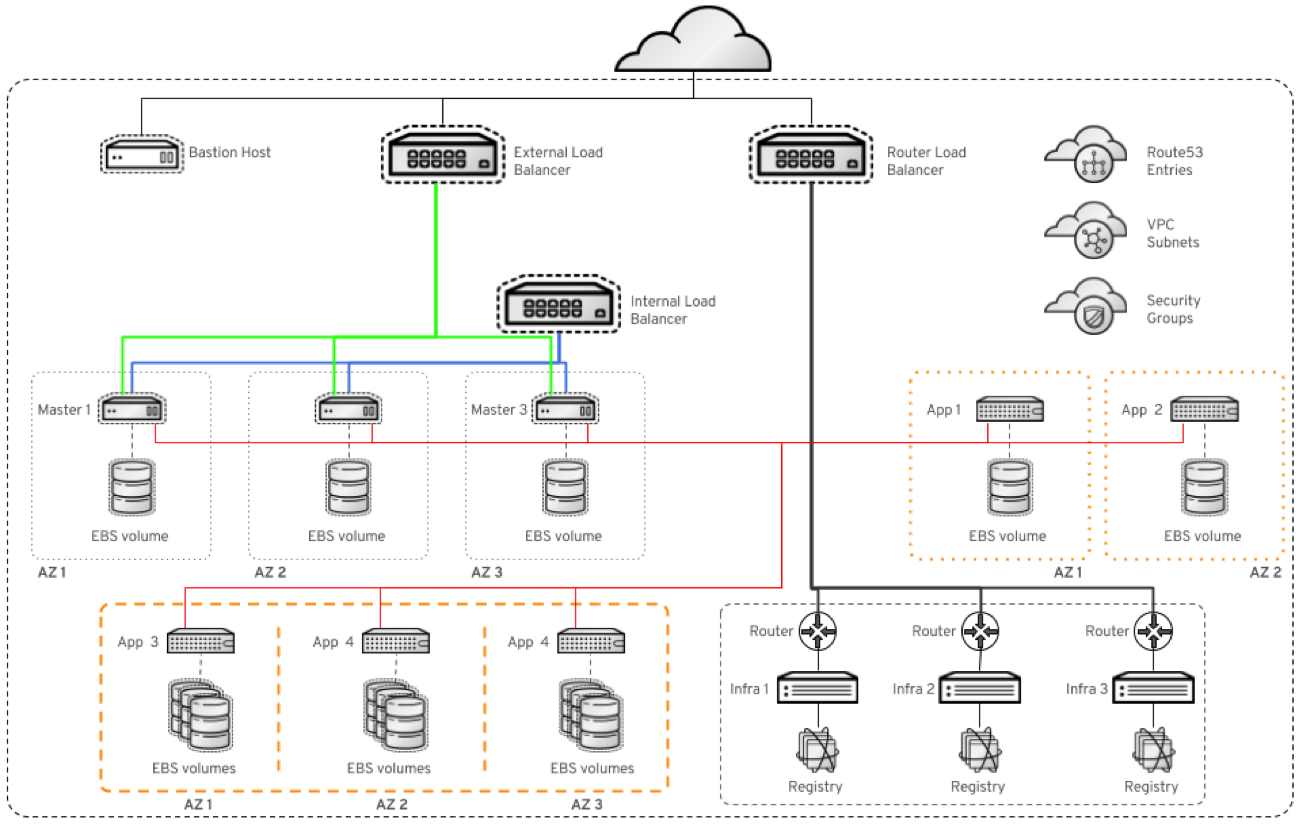
Subsequent calls allow for provisioning of additional CNS pools. The reference architecture makes reasonable choices for the EBS volume type and the EC2 instance with a balance between running costs and initial performance. The only thing left for the administrator to do is to run the cns-deploy utility and create a StorageClass object to make the new storage service accessible to users.
At this point, the administrator can choose between labeling the nodes as regular application nodes or provide a storage-related label that would initially exclude them from the OpenShift scheduler for regular application pods.
Container-ready storage
The reference architecture also incorporates the concept of Container-Ready Storage (CRS). In this deployment flavor, GlusterFS runs on dedicated EC2 instances with a heketi-instance deployed separately, both running without containers as ordinary system services. The difference is that these instances are not part of the OpenShift cluster. The storage service is, however, made available to, and used by, OpenShift in the same way. If the user, for performance or cost reasons, wants the GlusterFS storage layer outside of OpenShift, this is made possible with CRS. For this purpose, the reference architecture ships add-crs-storage.py to automate the deployment in the same way as for CNS.
Verdict
CNS provides further means of OpenShift Container Platform becoming an equalizer for application development. Consistent storage services, performance, and management are provided independently of the underlying provider platform. Deployment of data-driven applications is further simplified with CNS as the backend. This way, not only stateless but also stateful applications become easy to manage.
For developers, nothing changes: The details of provisioning and lifecycle of storage capacity for containerized applications is transparent to them, thanks to CNS’s integration with native OpenShift facilities.
For administrators, achieving cross-provider, hybrid-cloud deployments just became even easier with the recent release of the OpenShift Container Platform 3.5 on Amazon Web Service Reference Architecture. With just two basic commands, an elastic and fault-tolerant foundation for applications can be deployed. Once set up, growth becomes a matter of adding nodes.
It is now possible to choose the most suitable cloud provider platform without worrying about various tradeoffs between different storage feature sets or becoming too close to one provider’s implementation, thereby avoiding lock-in long term.
The reference architecture details the deployment and resulting topology. Access the document here.
Über den Autor
Ähnliche Einträge
KI-Bedrohungen abwehren: Agile Security für Unternehmen
Flut an KI-generierte Sicherheitsschwachstellen erfordert menschliche IT-Expertise
Untangling Networks | Compiler
Technically Speaking | Defining sovereign AI with open source
Nach Thema durchsuchen

Automatisierung
Das Neueste zum Thema IT-Automatisierung für Technologien, Teams und Umgebungen

Künstliche Intelligenz
Erfahren Sie das Neueste von den Plattformen, die es Kunden ermöglichen, KI-Workloads beliebig auszuführen

Open Hybrid Cloud
Erfahren Sie, wie wir eine flexiblere Zukunft mit Hybrid Clouds schaffen.

Sicherheit
Erfahren Sie, wie wir Risiken in verschiedenen Umgebungen und Technologien reduzieren

Edge Computing
Erfahren Sie das Neueste von den Plattformen, die die Operations am Edge vereinfachen

Infrastruktur
Erfahren Sie das Neueste von der weltweit führenden Linux-Plattform für Unternehmen

Anwendungen
Entdecken Sie unsere Lösungen für komplexe Herausforderungen bei Anwendungen
Virtualisierung
Erfahren Sie das Neueste über die Virtualisierung von Workloads in Cloud- oder On-Premise-Umgebungen