Présentation
Tous les environnements et applications ne sont pas conçus pour répondre aux exigences des charges de travail légères et distribuées. L'edge computing désigne le traitement informatique qui s'effectue à l'emplacement physique de l'utilisateur ou de la source des données, ou à proximité, c'est-à-dire en dehors du datacenter ou du cloud centralisé traditionnel. Il couvre divers types d'infrastructures. D'une part, on trouve les appareils portables et économiques situés à la périphérie du réseau, qui disposent de ressources de calcul limitées (par exemple, les appareils d'edge computing mobile tels que les smartphones et les tablettes). C'est ce qu'IDC appelle le « light edge ». D'autre part, dans ce que l'on appelle le « heavy edge » se trouvent notamment les datacenters/bureaux à distance qui hébergent de très grands serveurs avec de nombreux utilisateurs (et transactions de données).
Toutes les infrastructures partagent certaines attentes et des besoins communs, quel que soit leur type. Les utilisateurs et les appareils ont principalement besoin de pouvoir réaliser des transactions en temps réel, afin de répondre aux attentes des clients et de respecter les contrats de niveau de service (SLA) concernant les performances. Les applications utilisées dans ces environnements doivent donc être en mesure d'atteindre des valeurs de performances très spécifiques. C'est ce que l'on appelle des applications sensibles à la latence.
Terminologie
Avant de parler plus en détail des applications sensibles à la latence, définissons quelques termes de base :
- Latence : période qui s'écoule entre le moment où un événement survient et celui où il est traité par le système, ou, plus simplement, le temps nécessaire pour aller d'un point A à un point B.
- Bande passante (ou bande réseau) : volume de données pouvant être transportées au cours d'une période donnée. On l'exprime généralement en mégaoctets ou gigaoctets par seconde. On appelle débit le volume de données transporté en un temps donné. Il est difficile d'obtenir à la fois une bande passante élevée (ou un débit élevé) et une latence faible, donc il faut parfois faire des compromis.
- Paquet : élément de données transporté.
- Gigue : variabilité de la latence, généralement lorsque la communication réseau perd de sa stabilité ou subit des lenteurs intermittentes.
- Temps réel : signifie qu'une opération est effectuée au cours d'une période définie et précise, généralement de l'ordre de la milliseconde ou microseconde. On confond souvent « temps réel » avec « ultra-rapide ». Le temps réel implique plutôt une idée de déterminisme : l'opération est garantie avec un ensemble de contraintes données, indépendamment des autres opérations ou charges. Avec le traitement en temps réel, chaque transaction est distincte, contrairement au traitement par lots qui collecte plusieurs transactions simultanément.
- Nœud périphérique : désigne généralement tout appareil ou serveur capable de prendre en charge l'edge computing.
Ressources Red Hat
Définition
La latence est un indicateur de mesure temporel qui calcule le temps de réponse réel d'un système par rapport au temps de réponse prévu. Les performances du réseau, du matériel, du micrologiciel et du système d'exploitation sont ainsi évaluées, à la fois individuellement et collectivement à l'échelle du système. Pour les applications sensibles à la latence, une faible latence est préférable, car le délai entre le début d'une opération et la réponse obtenue est court. Une latence élevée est moins avantageuse, car la réponse est lente et des paquets sont potentiellement ignorés ou perdus (en fonction du type de données). La latence doit également être stable : une gigue trop prononcée altère la fiabilité du réseau, même si la latence moyenne semble bonne.
Prenons un exemple d'application sensible à la latence exécutée en périphérie du réseau : un véhicule autonome conduit par une IA. L'ordinateur de bord n'a que quelques millisecondes pour détecter un piéton ou un autre objet sur la route, et corriger la trajectoire en conséquence. Le traitement des données et l'intelligence artificielle doivent être contenus dans le véhicule, de même que la télémétrie en direct qui renvoie des données vers une passerelle ou un datacenter. Il s'agit d'une application critique. Si les utilisateurs s'impatientent parfois lorsque le traitement d'une transaction par carte bancaire prend trop de temps ou qu'une visioconférence n'est pas fluide, les conséquences sont bien moins dramatiques que celles d'une panne lors de la conduite autonome. L'IEEE (Institute of Electrical and Electronic Engineers) souligne la dépendance de nombreuses technologies modernes aux applications sensibles à la latence.
La latence est généralement perçue comme un facteur de vitesse, mais il serait plus exact de la considérer comme un aspect des performances d'un système dans son ensemble. La latence correspond à la durée écoulée entre le déclenchement d'un événement et le terme de sa réalisation. Ces limites de temps peuvent être flexibles en fonction de l'application. Le véhicule autonome est un exemple de limite ferme : le traitement doit être instantané pour éviter toute panne critique du système.
Certaines charges de travail ne nécessitent pas de latence faible. En d'autres termes, le temps entre le déclenchement d'une opération et sa réponse peut être élevé sans que cela soit problématique. Ces charges de travail sont asynchrones, ce qui signifie que le temps entre le déclenchement et le terme de la réalisation n'est pas observable par les utilisateurs ni pertinent dans leur cas. Une latence élevée n'est pas problématique avec des services comme les e-mails, par exemple, car le temps nécessaire pour recevoir un e-mail après son envoi n'est pas facilement observable par l'utilisateur final.
Dans les environnements complexes, qu'il s'agisse d'un système seul ou de plusieurs systèmes qui interagissent, les effets de la latence se cumulent. Que les opérations aient besoin d'être réalisées de manière séquentielle ou en parallèle, l'efficacité globale du système peut être compromise par la latence des opérations clés. Dans ce cas, l'indicateur de mesure le plus important n'est pas la vitesse, mais la stabilité. C'est ce que l'on appelle la latence déterministe : la latence attendue pour une opération donnée (ou la latence totale de toutes les opérations) est prévisible et stable. Cet aspect est essentiel lorsque plusieurs appareils doivent être synchronisés, par exemple des antennes à commande de phase, des équipements de télécommunication ou du matériel de fabrication.
En bref, une application sensible à la latence est essentiellement une application en temps réel. Il peut s'agir de toute application dont les performances peuvent être réduites en raison d'une latence élevée ou variable, ce qui signifie que les opérations doivent être réalisées dans la fenêtre déterministe, souvent mesurée en microsecondes. On les appelle également « applications à faible latence ».
On peut aussi différencier le niveau de sensibilité : les applications peuvent être considérées comme sensibles à la latence, par exemple lorsque la latence affecte les performances sans altérer le fonctionnement de l'application, et comme extrêmement sensibles à la latence, lorsqu'une latence trop élevée entraîne une panne.
Latence, virtualisation et services cloud
Bien que la latence soit souvent décrite en termes de performances du réseau, la qualité du réseau n'en est souvent pas la seule cause. Les facteurs qui ont une incidence sur le délai de traitement influent aussi sur la latence.
Avec la virtualisation et les machines virtuelles, différents processus virtuels se font concurrence pour l'utilisation des ressources du processeur et des ressources partagées telles que la mémoire et le stockage. Certains paramètres du système comme la gestion de l'alimentation et le traitement des transactions peuvent influer sur la manière dont différents processus accèdent aux ressources.
Des défis similaires peuvent se présenter avec les environnements de cloud computing. Plus un environnement matériel contient de couches d'abstraction, plus il est difficile d'allouer des ressources partagées et réservées au traitement, d'une manière qui puisse optimiser la durée de traitement et minimiser la latence pour les applications principales. Les fournisseurs de cloud tels que Amazon Web Services (AWS) proposent des déploiements et des optimisations pour les applications sensibles et extrêmement sensibles à la latence.
Pour les applications sensibles à la latence, l'environnement d'exploitation global et le matériel qui le compose sont tout aussi importants que l'infrastructure et la configuration réseau pour obtenir de la fiabilité.
Rôle des applications sensibles à la latence dans le domaine de l'edge computing
Une architecture d'edge computing est souvent décrite comme une sorte d'oignon dont les cercles concentriques (couches matérielles) s'éloignent de plus en plus du datacenter central. Chaque couche possède sa propre architecture et ses propres aspects, et différentes solutions sont requises pour ces cas d'utilisation variés.
Les parties en périphérie d'une architecture d'edge computing sont au plus près des interactions qui génèrent des données, notamment celles des clients/utilisateurs ou des appareils gérés. Ces éléments périphériques doivent réagir rapidement aux conditions changeantes et aux nouvelles données, car c'est souvent là que les applications sensibles à la latence ou en temps réel sont déployées. Il s'agit également des couches les plus éloignées des magasins de données partagés, et c'est là que se trouve le plus souvent le matériel léger et déployé à petite échelle, tel que les tablettes ou les appareils IoT (Internet des objets).
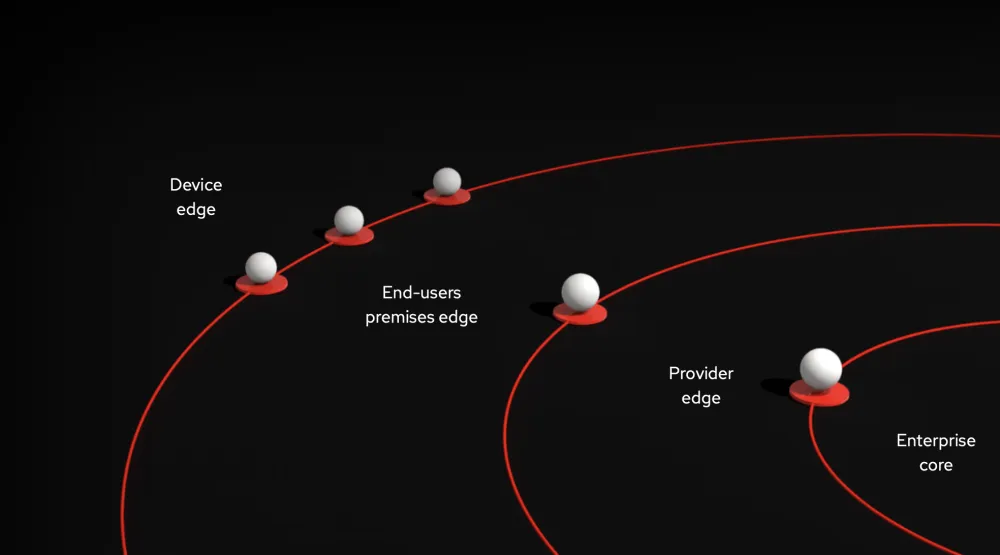
Dans ce contexte, les responsables informatiques peuvent développer des processus et des politiques efficaces pour s'assurer de préserver les performances de leurs applications sensibles à la latence et de leurs environnements d'edge computing dans leur ensemble. Ils doivent notamment :
- disposer de pipelines de développement et de déploiement clairs et centralisés ;
- pouvoir appliquer des politiques de gestion et de mise à jour cohérentes pour les logiciels et le matériel ;
- intégrer les tests des performances à tous les pipelines ;
- avoir recours à l'automatisation dès que possible ;
- définir des environnements d'exploitation standard pour assurer la cohérence au niveau de la périphérie du réseau ;
- utiliser des normes et des méthodes cohérentes et ouvertes pour garantir l'interopérabilité.
Ces meilleures pratiques sont comparables à celles qui s'appliquent à l'Internet industriel des objets (IIoT), au calcul haute performance et aux autres architectures distribuées. L'edge computing et l'IoT ne sont pas une finalité : ce sont des moyens d'atteindre un objectif précis. De même, les applications sensibles à la latence ne sont pas seulement avantageuses du fait de leur rapidité. Elles sont utiles lorsque le traitement rapide des données permet de créer des expériences client puissantes, de gérer des équipements de grande taille de manière efficace et sécurisée, de réagir aux changements des conditions d'exploitation et de s'adapter à de nouvelles mutations.
Nos solutions
Le système d'exploitation est aussi important dans les environnements cloud ou d'edge computing que dans les datacenters et les salles de serveurs physiques. En effet, il fournit des fonctionnalités centrales telles que le provisionnement et la gestion des ressources, qui sont essentielles pour les applications sensibles à la latence, ainsi que d'autres paramètres informatiques nécessaires tels que la sécurité et la configuration réseau.
Avec les applications sensibles à la latence, la question est de savoir quel volume de données il faut analyser dans le datacenter ou le cloud, ou s'il faut basculer une partie de l'activité en local. Il s'agit de trouver l'équilibre entre quantité de données et rapidité.
Si les risques de latence sont liés au traitement local, il existe des outils spécifiques qui peuvent améliorer les performances du système. Il est également possible de concevoir une architecture à l'aide de divers outils et technologies qui atténuent les effets de la latence.
Gérer la latence au sein de l'architecture
En fonction de l'approche choisie, la priorité peut être donnée aux exigences relatives à la latence au sein du réseau, ce qui signifie que l'architecture d'edge computing est essentielle à la bonne exécution des services. Avec la latence du réseau, l'architecture d'edge computing doit être en mesure de traiter les données localement, au niveau de la périphérie, plutôt que d'envoyer des données brutes vers un datacenter, de les traiter, puis d'envoyer une réponse. En forçant le traitement des applications en périphérie, il est possible de réduire la dépendance envers les réseaux à latence élevée.
La solution Red Hat® Enterprise Linux® for Distributed Computing offre des fonctions optimisées pour l'edge computing qui permettent de déployer des charges de travail d'applications au sein d'une architecture de cloud hybride distribuée, notamment dans un datacenter, sur un serveur cloud et en périphérie du réseau, à l'aide d'un environnement d'exploitation ouvert et cohérent. Elle peut être installée sur des points de terminaison en périphérie et sur des passerelles pour permettre aux applications d'analyser et de traiter des données localement, tout en transmettant les mises à jour et les informations sur les données pertinentes aux serveurs dans le cloud ou le datacenter. Cette approche réduit ainsi la dépendance envers les réseaux à latence élevée qui offrent une bande passante instable ainsi que des connexions intermittentes.
Gérer la latence au sein du système
La gestion du temps est essentielle pour les environnements sensibles à la latence. Même avec des architectures bien conçues, il peut être judicieux de disposer d'un système très performant en périphérie pour effectuer le traitement local.
Les applications sensibles à la latence requièrent un environnement d'exploitation hautement configurable. La solution Red Hat Enterprise Linux for Real Time est un paquet spécial conçu pour mettre en œuvre des changements au niveau des algorithmes et des sous-systèmes, et spécialement créé pour les environnements sensibles à la latence dans lesquels les besoins en matière de prévisibilité et de vitesse vont au-delà de la configuration normale des performances.
Red Hat Enterprise Linux for Real Time inclut des outils de base qui prennent en charge les configurations clés pour de meilleures performances en temps réel :
- Optimisation de la configuration du matériel et de la mémoire, ainsi que des applications écrites à l'aide de plusieurs techniques de programmation
- Contrôle de l'exécution des applications multithread et multiprocessus
- Vérification de la compatibilité d'un système matériel
- Définition du comportement en matière de cache
S'appuyer sur un écosystème étendu
Dans ce contexte, l'écosystème Red Hat se montre particulièrement puissant. Nous donnons accès à des configurations et des fournisseurs de matériel certifiés pour Red Hat Enterprise Linux for Real Time et Red Hat Enterprise Linux for Distributed Computing qui garantissent que les applications d'edge computing seront exécutées conformément aux spécifications.
De plus, Red Hat Enterprise Linux s'utilise avec Red Hat® OpenShift® pour le déploiement et l'orchestration des conteneurs Kubernetes, avec Red Hat® Ansible® Automation Platform pour l'automatisation et avec les technologies Red Hat Middleware pour la gestion des décisions et des processus, les flux de données, l'intégration et d'autres outils.
L'edge computing est une stratégie qui permet de fournir des informations et des expériences au moment le plus opportun. Avec les solutions Red Hat Enterprise Linux for Real Time, Red Hat Enterprise Linux for Distributed Computing et les autres produits de notre gamme, vous disposez d'une base solide qui vous aidera à mettre en œuvre cette stratégie.
Le blog officiel de Red Hat
Découvrez les dernières informations concernant notre écosystème de clients, partenaires et communautés.