
By any means you choose to measure, Kubernetes is one of the most popular and comprehensive open source projects in the container space. It is a unique community of individuals and corporations coming together to solve some of the most complex problems in the containerization of cloud native and stateful application services. Red Hat continues to be a thought leader in the community and a company that offers robust and enterprise-ready solutions based on the platform. Today we announce OpenShift Container Platform 3.4! Let Red Hat help you get on a successful path with your container project today.

(Image by: ccPixs.com under creative commons)
With every release of OpenShift, comes new opportunities to push container orchestration further into our datacenters and cloud infrastructures. Version 3.4 (based on Kubernetes 1.4) is exceptional in the following areas:
- Cluster Storage
- Workload Automation
- Container Networking
Let's take a closer look at these three areas.
Cluster Storage
Dynamic Provisioning of Storage
One of the bedrock features of OpenShift is our ability to run applications that require storage. Be that file or block backed file systems, we can orchestrate application services the need state. Up until today, in order to get that storage into the cluster for use, we required an administrator to pre-create the volumes on the backend storage systems and register them with the cluster as available for use. The only problem with that is the fact it is difficult to know beforehand the variety of sizes you should create. Most tenants don't know what size storage volumes they will use someday in the future. That ends today! OpenShift 3.4 brings the dynamic provisioning of those storage volumes to the table. Now an administrator only needs to configure the cloud provider for the cluster that matches the storage backends available for dynamic provisioning (AWS, OpenStack Cinder, GCE, GlusterFS, Ceph RBD) and create storage classes that the tenants will select. At that point, the tenant can carve out any size (size options governed by the backend) without having anyone pre-create the volumes. This feature has been a long time coming in the upstream communities and we are glad it has finally arrived!
Storage Classes
In order to allow tenants to automatically consume storage from the backend systems, we needed a way to expose them to different configuration options without making it too cumbersome. We have introduced a new concept called storage classes. After the cluster has been registered with a storage provider backend, the administrator will create storage classes. Within these storage class definitions, the administrator is declaring an end-user-friendly name and configuration options. For example, let's look at AWS EBS. There are a number of options the administrator can choose from while creating the storage class:
- type: io1, gp2, sc1, st1. See AWS docs for details. Default: gp2.
- zone: AWS zone. If not specified, a random zone from those where Kubernetes cluster has a node is chosen.
- iopsPerGB: only for io1 volumes. I/O operations per second per GiB. AWS volume plugin multiplies this with size of requested volume to compute IOPS of the volume and caps it at 20 000 IOPS (maximum supported by AWS).
- encrypted: denotes whether the EBS volume should be encrypted or not. Valid values are true or false.
- kmsKeyId: optional. The full Amazon Resource Name of the key to use when encrypting the volume. If none is supplied but encrypted is true, a key is generated by AWS. See AWS docs for valid ARN value.
-
storageclass.beta.kubernetes.io/is-default-class: annotation that if set to "true" for a storage class will become the default storage class selected if a tenant forgets to select one
What that ends up looking like to the end user on the platform is the following:
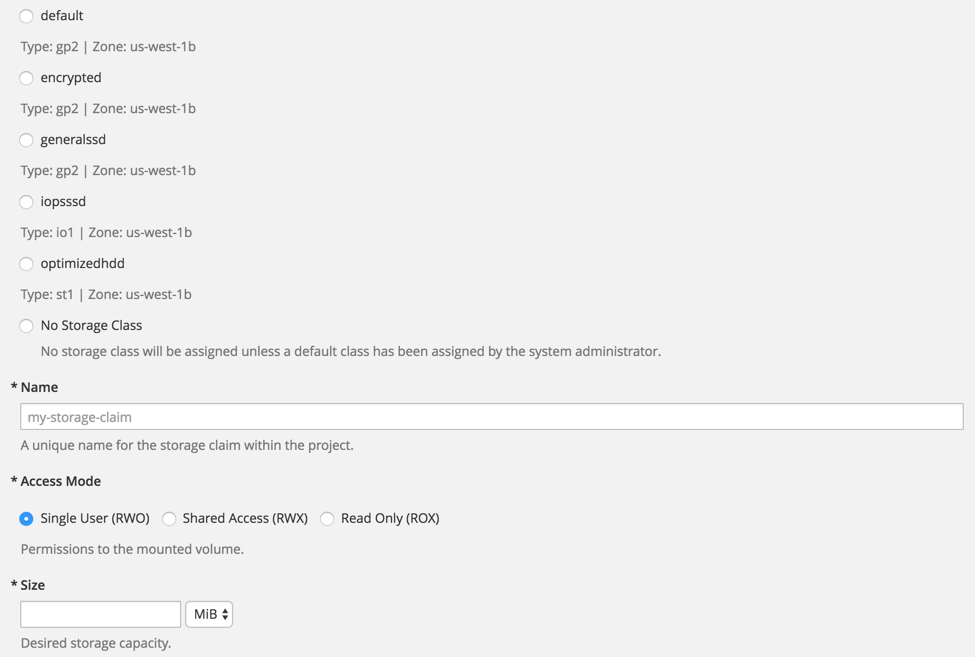
Storage Size Quota
Now that tenants can drink directly from the storage faucet, we need to control them better :) Previously in OpenShift, you could place a quota on how many remote persistent volumes claims (PVC) they were allowed to have in a given project. That was great, but it did not limit the size of volumes. It did not have to because only pre-created volumes of a specific size were available. Now with dynamic provisioning of storage, we need to control the total amount of storage we want tenants to be able to create. In this command line example, I will tell this project that I want the tenants within to be able to use 500gb of storage. They can carve it up however they like, but I only want to them to be able to use a max of 50 volumes when doing so. I've basically told them the total size of the cake and the maximum number of slices I'll allow them to use while eating it.
$ oc create quota my-quota --hard=requests.storage=500Gi,persistentvolumeclaims=50
Pretty simple!
Workload Automation
Job Scheduler
OpenShift allows you to run a variety of application workloads on the platform. Most of the time that conversation will lead to cloud native, microservices, or stateful applications. If you peel that onion back a layer, you will find a need to tell the orchestration system to behave differently depending on the need of the service. In Kubernetes we have controllers to assist with describing how the platform should treat the pods. If I want Kubernetes to always make sure a process it up and looks exactly as I have described it at time of deployment, I use a replication controller. If I want Kubernetes to always make sure a service is running on particular nodes with a given label, I might use a daemonSet controller. If I want to run short lived tasks in batches and capture their run control, I'll use a job controller. It is extremely easy to select which personality behavior I want for my application. In this release of OpenShift, we release a tech preview look at a new scheduler for the job controller workloads. This new scheduler allows you to run until a declared number of PODs terminate successfully and choose to run PODs in parallel or serially. These short-lived tasks should be independent, but related work items. The scheduler leverages an easy to use and familiar cron syntax.
Pod Disruption Budget
Another excellent feature that has reached tech preview are pod disruption budgets. As the owner of the cluster, it takes effort to figure out which pods on which nodes make up an application. Administrators will find themselves looking up this information when they want to perform voluntary maintenance on the platform, such as patching or upgrades, without causing application service downtime. It would be nice if you didn't have to worry about the relationships at all. What if the platform just protected you from accidentally taking down too many pods for a particular service? In comes pod disruption budgets to save the day. They allow you to limit the number of pods that are down simultaneously. The PodDisruptionBudget for the application is considered healthy when there are at least minAvailable pods running in the system, as specified by application owner. Evictions that want to honor the disruption budget must call the /eviction subresource. Super easy to use, application owners just declare their selector (group of pods) and the minimum allowed available pods in a percentage or a straight number.
Disk Based Eviction
Most distributed resources systems have eviction policy and Kubernetes is no exception. In 2016 we delivered a lot of automation around memory. Should containerized workloads on a node start causing the node memory starvation issues, we handle eviction of containers from the node in a graceful manner and allow the scheduler to rebalance the deployment of the affected applications. When you work with containers, the other significant resource you want to keep an eye on is disk utilization. New in this release is an ability to perform evictions based on available file system space and the amount of free inodes. It is a clever design in that it allows you to treat these thresholds differently for the two primary file systems on a container host:
- nodefs: filesystem that kubelet uses for volumes, daemon logs, etc.
- imagefs: is filesystem that container runtimes uses for storing images and container writable layers
If nodefs and imagefs filesystem has met eviction thresholds, Kubernetes will free up disk space in the following order:
- Delete logs
- Delete unused images
- Evict pods from the node
As is the case with all eviction on the cluster, Kubernetes will implement an eviction strategy based on the pod quality of service class (such as best effort, burstable, or guaranteed).
Scopes
Scopes have been around for awhile now in Kubernetes, but we haven't spoken about them as much as we should. For OpenShift 3.4 we spent some cycles documenting them and cleaning up the usability. As the name implies, what if you want to want to make large generic statements or rules that govern how resources are controlled on the system, but then scope that down further only for certain named conditions to be different? You use a scope. For example, let’s say you want to make it so work coming from a given project can only use the resources that are slack on the cluster. Basically let them use the leftover cycles that no one is using, but still make it so those resources can be reclaimed should they become needed by other more important people. In the project you would issue:
$ oc create quota not-best-effort --hard=pods=0 --scopes=NotBestEffort
This will make it so the project cannot have more than 0 pods in the categories that are NotBestEffort. We have scoped the quota to match a specific attribute of the resource. NotBestEffort is really the other two service levels for workloads on the cluster, Burstable and Guaranteed.
Designated Build Nodes
One extremely important workload that we run on Kubernetes for the tenants of OpenShift are builds. In OpenShift, you don't need to work with dockerfiles and docker images if you don't want. Developers can simply give OpenShift code and we will compile or build it if needed and make it run on the cluster in a docker image for you. At the same time, users can also work with docker images and perform docker builds directly. We perform these building actions with "builder pods" on the cluster. Now in OpenShift 3.4 an administrator can set up nodes to only run builder pods. This allows them to resource and configure those nodes differently. They may choose to isolate them more aggressively, offer them faster IO profiles, or seed them will locally cached runtime dependencies. Being able to control this specific workload more granularity is a great change.
Container Networking
CNI Support
Container Networking Interface (CNI) has been a hot topic in the container space for the last 1-2 years. OpenShift has always shipped an openvswitch (OVS) implementation for network control on Kubernetes. But our work on the plugin pre-dated (existed longer) than the CNI solution found in Kubernetes. New in OpenShift 3.4 we have converted the openshift-sdn to be a CNI plugin to Kubernetes. This has little to no effect on users but keeps OpenShift up to date with the growing catalog of network options available to Kubernetes.
Subdomain Wildcard Support
Sometimes application owners will want to send all their traffic for a given URL to a common backend service in cases they might have a store front or similar design. In those cases, they want an option to use a wildcard route for their application wherein they register foo.com and it routes all traffic destined for *.foo.com to the same backend service, which is configured to handle all the subdomains. New in OpenShift 3.4, users can annotate their route and the haproxy router will expose the route to the service per the route’s wildcard policy. Once annotated, the most specific path wins (e.g. bar.foo.com is matched before foo.com).
F5 Integration
In this release we were able to partner with F5 Networks and enhance the out of the box integration with F5 routers. Specifically, the extra "ramp" node is no longer required to bridge the F5 to OpenShift. The F5 gets an SDN IP from the OpenShift cluster CIDR. This allows OpenShift to communicate directly with the F5 about current information regarding the nodes, hostsubnets, services, routes, endpoints, and VNIDs. This makes the integration more stable and open to more commonly found F5 customizations at customer sites.
Conclusion
OpenShift 3.4 just took containerized application platforms to the next level. Come check out the view!
Sobre o autor
Mike Barrett is the Vice President and General Manager of Red Hat Hybrid Platforms. He looks after Red Hat OpenShift, Red Hat Cloud Services, and most of Red Hat’s Cloud Native Computing Foundation investments.
He joined Red Hat in 2013 and specializes in accelerating application platforms through the use of operating systems, cloud, and hardware technologies. Mike has more than 25 years of experience in datacenter architecture. He previously worked in both services and product management roles at Sun Microsystems and Oracle before joining Red Hat.
Mais como este
O paradoxo agêntico e o argumento a favor da IA híbrida
Pare de gerenciar o passado e comece a construir o futuro da TI
Crack the Cloud_Open | Command Line Heroes
Edge computing covered and diced | Technically Speaking
Navegue por canal

Automação
Últimas novidades em automação de TI para empresas de tecnologia, equipes e ambientes

Inteligência artificial
Descubra as atualizações nas plataformas que proporcionam aos clientes executar suas cargas de trabalho de IA em qualquer ambiente

Nuvem híbrida aberta
Veja como construímos um futuro mais flexível com a nuvem híbrida

Segurança
Veja as últimas novidades sobre como reduzimos riscos em ambientes e tecnologias

Edge computing
Saiba quais são as atualizações nas plataformas que simplificam as operações na borda

Infraestrutura
Saiba o que há de mais recente na plataforma Linux empresarial líder mundial

Aplicações
Conheça nossas soluções desenvolvidas para ajudar você a superar os desafios mais complexos de aplicações
Virtualização
O futuro da virtualização empresarial para suas cargas de trabalho on-premise ou na nuvem