The latest updates to Red Hat OpenShift bring significant enhancements to monitoring and troubleshooting directly within OpenShift. Red Hat OpenShift observability has evolved into a highly integrated ecosystem that combines metrics, logs, traces, and network telemetry into a single experience. It removes the tool sprawl typically associated with Kubernetes, replacing fragmented dashboards with a centralized, hardened, and supported platform.
Cluster observability operator 1.4
The cluster observability operator (COO) acts as a "meta-operator". Its primary job is to deploy and manage independent monitoring stacks that do not interfere with the core OpenShift metrics. In addition to this, the operator ships observability UI plugins and related advanced analytics features, including signal correlation (powered by Korrel8r) and incident detection for OpenShift. With the latest release, we announce the availability of two brand new features.
Customizable dashboards with Red Hat build of Perses (technology preview)
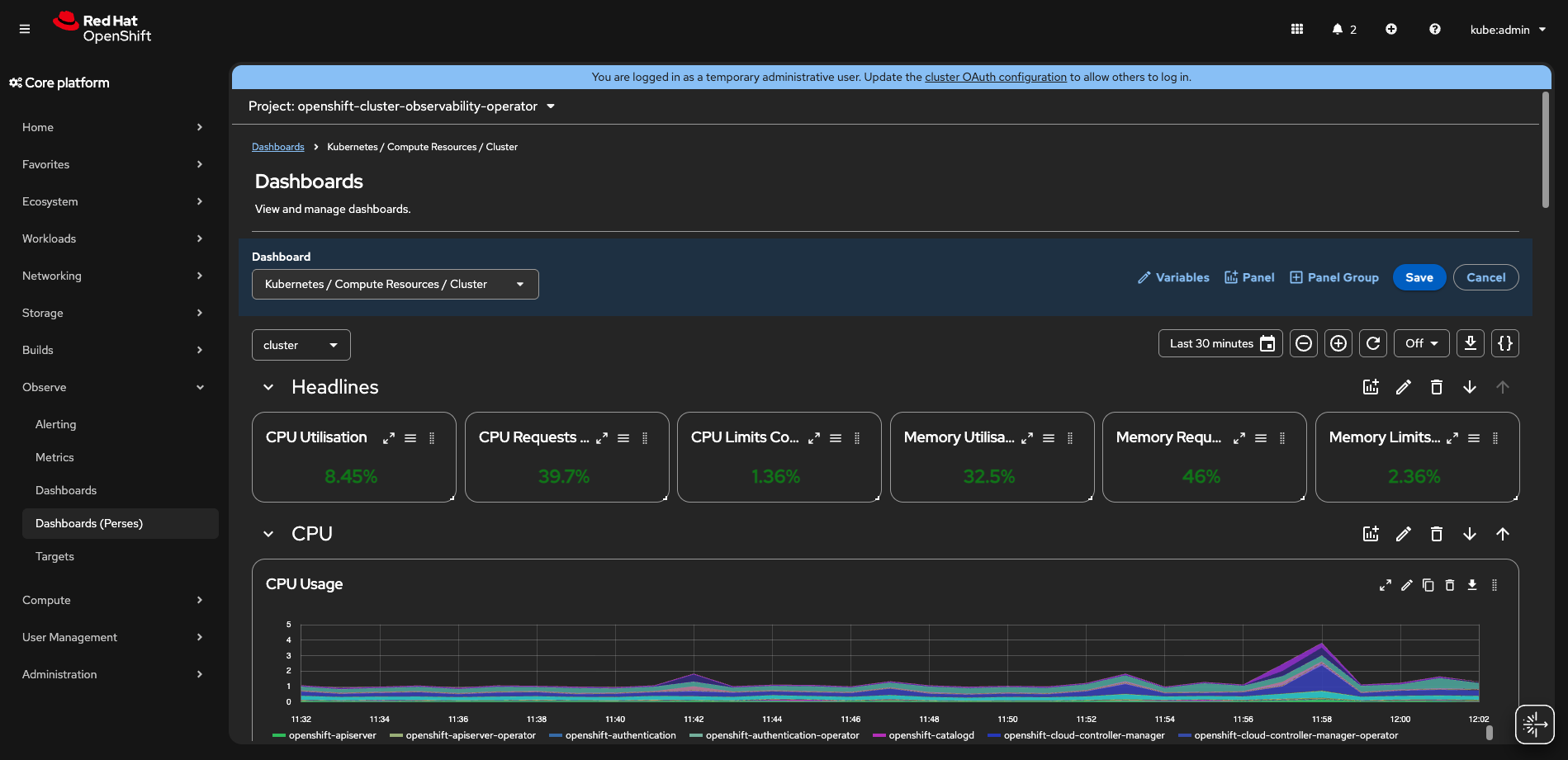
We are glad to announce a technology preview release of customizable dashboards options as part of the OpenShift web console with the cluster observability operator 1.4 (COO) release. The journey begins by selecting an OpenShift project, which then displays standard Prometheus metrics alongside new log additions backed by Loki and traces by Tempo.
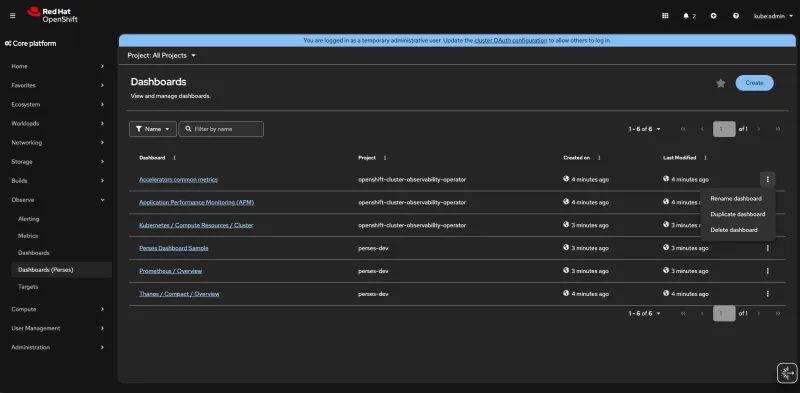
After this step, dashboards can be edited. While code-centric, Perses provides a fully functional web interface for layout and data exploration.
- Visualization variety: Supports standard panel types, including time series charts, gauge/multi-gauge, stat charts, and markdown panels.
- Intuitive layout: Features a grid-based system for arranging panels, which can be easily dragged and organized into collapsible panel groups (rows).
- Dynamic variables: A robust variable system allows for highly dynamic dashboards (for example, filtering by job or instance).
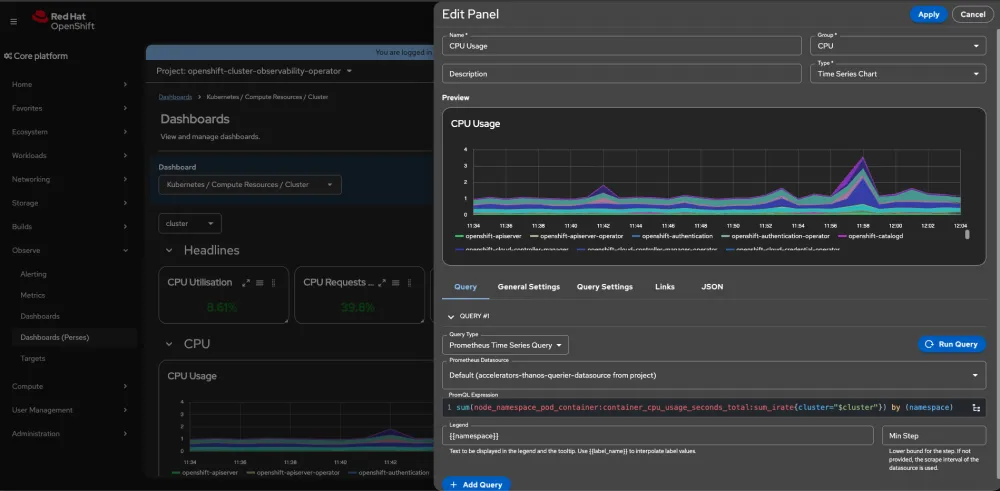
AI trace summarizer (developer preview)
Quickly summarize a trace with new functionality released as a developer preview. The traces UI front end is now integrated with OpenShift LightSpeed. A new "Ask OpenShift LightSpeed" button, now visible above the Gantt Chart, allows users to quickly get insights into their traces. When clicked, this button pre-populates a prompt and includes the trace in YAML format. Before sending, users can preview the trace, redact sensitive values, or opt not to send the information if it contains private data.
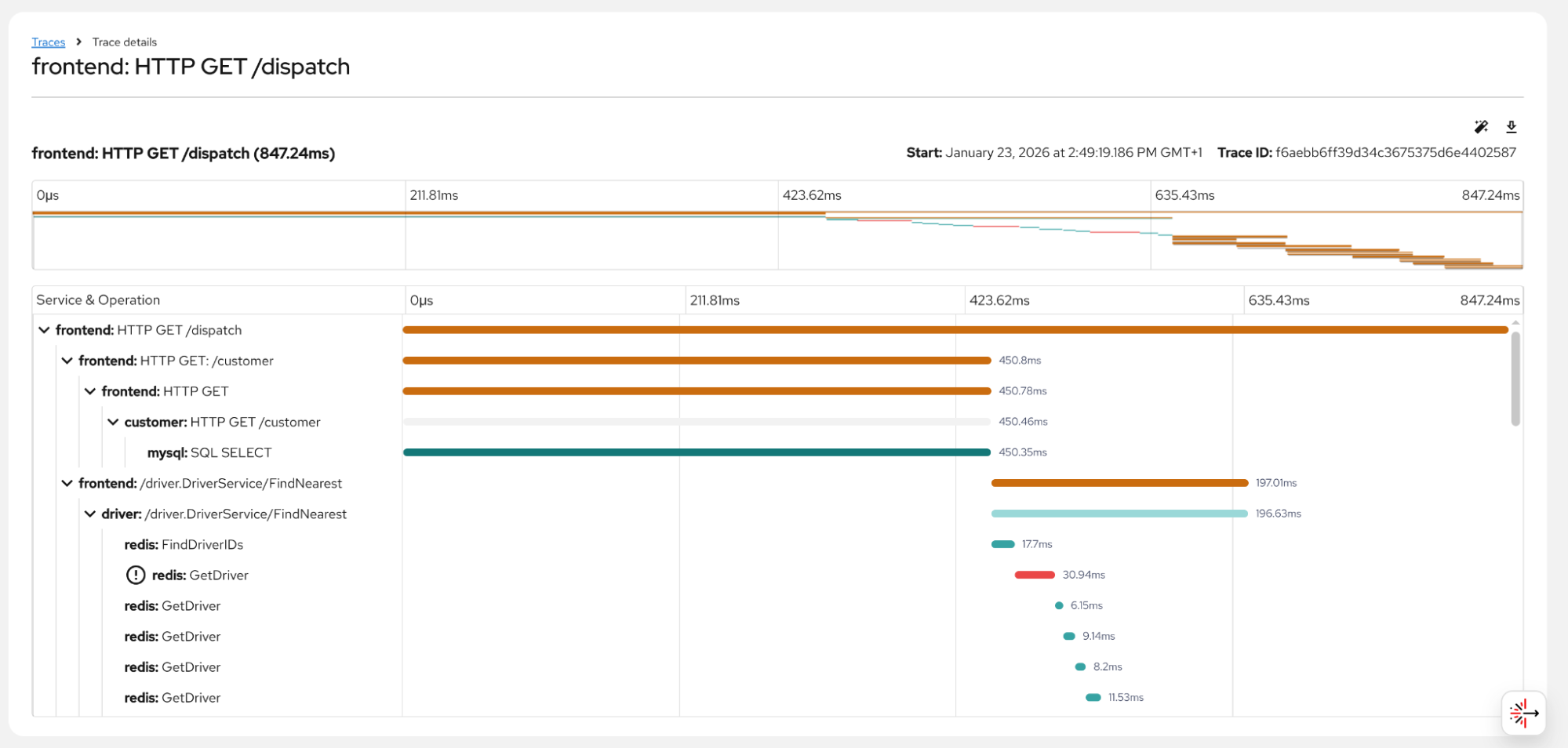
Upon submission, OpenShift LightSpeed provides a summary of the trace, emphasizing any detected errors. This interactive feature also supports follow-up questions, such as "How do I resolve the errors?".

OpenShift monitoring
OpenShift Monitoring continues to evolve to meet the demands of modern, large scale Kubernetes environments. This release introduces improvements focused on performance, standards alignment, and operational reliability, strengthening the Prometheus-based monitoring foundation.
Performance and standards
The Prometheus and Prometheus Operator stack includes upstream improvements to PromQL and the time series database (TSDB), delivering better query performance and more efficient storage. The platform also advances UTF-8 support, improving how labels and metadata are handled in diverse environments. These changes keep monitoring performance as clusters scale.
OpenTelemetry integration
Enhanced OTLP metrics ingestion improves standardized pipeline support, enabling hybrid observability architectures where Prometheus and OpenTelemetry coexist. This supports users adopting OpenTelemetry long-term while maintaining Prometheus stability.
Operational reliability
Thanos Ruler retention now aligns with Prometheus retention by default, fixing the previous 24-hour default that could cause alerting gaps. The monitoring stack has also been updated with newer versions of Prometheus, Prometheus Operator, Thanos, kube-state-metrics, and node-exporter bringing the latest upstream improvements and security patches.
Conclusion
These changes make OpenShift monitoring more robust, scalable, and standards-aligned. Whether operating single or multi-cluster environments, the platform is now easier to operate and better suited for modern cloud-native workloads.
OpenShift logging
OpenShift logging is constantly evolving to meet the demands of modern, distributed systems. In OpenShift 4.21, we're rolling out several major enhancements focused on improving resilience, streamlining operations, and boosting observability. From making it easier to scale Loki persistent storage to unlocking advanced correlation with OpenTelemetry, these updates make OpenShift logging a more robust, flexible, and powerful component of your observability stack.
Enhanced flexibility for Loki persistent volumes
Scaling your logging infrastructure is crucial, and recreating persistent storage to adjust Loki's scale can be a burden. With this new feature, the Loki operator introduces flexibility for persistent volumes (PVs).
Key benefit: You can now easily change Loki's scale (the "t-shirt sizes") without having to create a new PV. This change not only eases the operational burden of resizing Loki but also helps ensure a proper and efficient scale-down of ingesters, crucial for optimal resource management.
OpenTelemetry (OTLP) log export for advanced correlation
For developers and SREs working with complex, distributed systems, the ability to connect logs directly to tracing data is a game-changer. The new OTLP log export feature enhances observability and simplifies debugging by connecting your logs with the OpenTelemetry ecosystem.
Key benefit: The log collector can now enrich logs with essential trace attributes—specifically traceid, spanid, and the sampled flag—when forwarding them over OTLP. This allows you to:
- Immediately correlate a log entry with the full context, performance, and flow of the request it belongs to
- View the attributes using community semantic conventions
- Verify that you can opt-in to trace attributes via a filter, giving you control over the data being exported
Support for alternative authentication gateways
This enhancement is particularly important for customers utilizing multi-cluster observability add-on (MCOA) or other complex multi-tenant setups.
Key benefit: We have introduced an API to allow the LokiStack Gateway to be disabled. This enables the Loki stack to run securely behind an alternative authentication gateway (such as those used by RHOBS, MCOA, or CloudKitty), which can select a different set of Loki tenants. This capability is vital for flexible and secure multi-tenant deployments.
OpenTelemetry and tracing
The Red Hat Build of OpenTelemetry is proud to announce full support of all three observability signals by making log collection generally available (GA), with FileLog Receiver. The Filelog Receiver is useful when you have a workload that creates custom log files that are usually rotated. In this situation, you can deploy an OpenTelemetry Collector sidecar to collect these custom log files and then export them to an in-cluster installation of the Loki operator, or whatever external endpoint you have, in OTLP format. Also, with OpenTelemetry log collection, you have the opportunity to add valuable enrichment to the logs using the OpenTelemetry k8sAttributes processor. This helps you ensure that your metrics, traces, and logs collected by OpenTelemetry all have the same attributes, which creates better correlation of all three signals.
We have several OpenTelemetry Collector components also going GA in this release:
- Filter Processor: The OpenTelemetry Filter Processor allows you to create filters in the OpenTelemetry transformation language (OTTL) that drops unnecessary data from the signals you've collected. This is useful when you only need to export a portion of signals. Dropping what is not needed reduces your overall network bandwidth in sending signals, and also reduces the amount of storage you're using for signals.
- Transform Processor: The OpenTelemetry Transform Processor also uses OTTL, and allows you to write statements to modify your telemetry signals to match your business requirements. This processor is especially powerful when used in conjunction with the Filter Processor, because your signals are compact and in the format that best suits your needs.
- MetricsStartTime Processor: The MetricsStartTime processor is utilized to assign start times to metrics that do not have them. This ensures accurate metrics collection by fixing gaps in start times, and can be handy if you are forwarding metrics to a third party system that requires assigned start times to metrics.
We are also releasing a developer preview of the Tempo model context protocol (MCP) server with our Tempo operator. This server can provide AI agents and LLMs with standardized access to tracing data stored in Tempo, presenting a selection of APIs to your AI model in a natural language format. We'll continue to refine this and future MCP offerings, so that you can integrate AI applications with findings from valuable Tracing data.
New observability features in Red Hat Advanced Cluster Management for Kubernetes
Red Hat Advanced Cluster Management for Kubernetes is vital for organizations operating complex, distributed Kubernetes environments. A core benefit is its powerful multicluster observability, which is essential for managing the challenges that arise with disparate clusters. Observability is a critical feature within Red Hat Advanced Cluster Management for Kubernetes, and so we're pleased to announce a significant feature in the latest 2.16 release.
Right-sizing recommendations (generally available)
Right-sizing recommendations at the cluster, namespace, and virtual machine (VM) levels are all generally available with Red Hat Advanced Cluster Management for Kubernetes 2.16. Right-sizing for namespaces, clusters, and VMs is a powerful feature designed to optimize CPU and memory allocation across your managed Kubernetes clusters. This capability directly addresses both resource waste from over-provisioning and performance issues stemming from under-provisioning, leading to significant improvements in stability and efficiency. Key advantages and functionality include:
- Optimized resource utilization: Resources are precisely allocated based on actual usage, eliminating idle capacity, and maximizing infrastructure efficiency.
- Cost efficiency: By preventing unnecessary over-provisioning, organizations can substantially lower operational costs and make better use of existing hardware investments.
- Enhanced visibility and control: Red Hat Advanced Cluster Management for Kubernetes offers clear insights through recommended right-sizing actions. These recommendations are based on metrics derived from Prometheus recording rules and are visualized in dedicated Grafana dashboards within the Red Hat Advanced Cluster Management for Kubernetes console.
- Proactive management: Cluster administrators gain the ability to proactively manage resources by adjusting controls and policies for both namespaces and VMs, which helps enforce best practices and prevents resource wastage.
- Extended governance: Vertical pod autoscaler (VPA) focuses on right-sizing at the pod level, but the right-sizing capability for Red Hat Advanced Cluster Management for Kubernetes extends this principle to namespaces and VMs, offering a much broader scope of resource governance and efficiency across the cluster.
Start exploring
Ready to explore these new features? Visit the redhat.com/observability and documentation pages to learn more and get started with the latest observability tools in OpenShift. The Red Hat Developers Observability page also contains information to help you learn about and implement observability capabilities.
We value your feedback! Share your thoughts and suggestions using the Red Hat OpenShift feedback form.
About the authors

Roger Florén, a dynamic and forward-thinking leader, currently serves as the Principal Product Manager at Red Hat, specializing in Observability. His journey in the tech industry is marked by high performance and ambition, transitioning from a senior developer role to a principal product manager. With a strong foundation in technical skills, Roger is constantly driven by curiosity and innovation. At Red Hat, Roger leads the Observability platform team, working closely with in-cluster monitoring teams and contributing to the development of products like Prometheus, AlertManager, Thanos and Observatorium. His expertise extends to coaching, product strategy, interpersonal skills, technical design, IT strategy and agile project management.

Jamie Parker is a Product Manager at Red Hat who specializes in Observability, particularly in the Logging and OpenStack areas. At Red Hat, Jamie works with organizations and customers to learn about their needs within the ever changing Observability landscape, and based on their feedback, helps to guide upcoming products within the Red Hat Observability Platform. Jamie enjoys sharing lessons learned to the community by frequently speaking at meetups and conferences, and by blogging.

Vanessa is a Senior Product Manager in the Observability group at Red Hat, focusing on both OpenShift Analytics and Observability UI. She is particularly interested in turning observability signals into answers. She loves to combine her passions: data and languages.

More like this
Why building fast does not guarantee success
Red Hat Desktop brings Kubernetes-aligned development to the desktop
The CTO And The Vision | Compiler: Re:Role
Compiler: Re:Role | The Designer And The Blueprint
Browse by channel

Automation
The latest on IT automation that spans tech, teams, and environments

Artificial intelligence
Explore the platforms and partners building a faster path for AI

Cloud services
Get updates on our portfolio of managed cloud services

Security
Explore how we reduce risks across environments and technologies

Edge computing
Updates on the solutions that simplify infrastructure at the edge

Infrastructure
Stay up to date on the world’s leading enterprise Linux platform

Applications
The latest on our solutions to the toughest application challenges

Original shows
Entertaining stories from the makers and leaders in enterprise tech