En octobre dernier, nous avons annoncé la version préliminaire pour le développement de l'outil Power Monitoring for Red Hat OpenShift, dévoilant ainsi Kepler en tant que composante intégrale du projet communautaire en amont sustainable-computing. Ce projet permet aux premiers utilisateurs de tester cette technologie prometteuse. Depuis cette annonce, notre équipe a travaillé dur pour créer des pipelines et des outils qui respectent les normes de sécurité et de test des produits Red Hat.
Aujourd'hui, nous sommes ravis de vous présenter une nouvelle étape de notre parcours : la version préliminaire de l'outil Power Monitoring for Red Hat OpenShift. Nous tenons à remercier tous les premiers utilisateurs et les passionnés de technologies innovantes qui ont activement participé au déploiement de Power Monitoring et ont gracieusement fait part de leurs précieux retours d'expérience.
Si vous n'avez pas encore eu l'occasion de tester Power Monitoring for Red Hat OpenShift, il s'agit d'un ensemble d'outils qui vous permet de surveiller la consommation électrique des charges de travail exécutées dans un cluster OpenShift. Ces informations peuvent être utilisées à différentes fins, par exemple pour identifier les espaces de noms les plus énergivores ou élaborer un plan stratégique afin de réduire la consommation d'énergie.
Si vous souhaitez tester cette version préliminaire, nous vous invitons à découvrir ci-dessous la marche à suivre. Veuillez lire la déclaration de version préliminaire pour en savoir plus sur l'assistance officielle.
Installation de Power Monitoring for Red Hat OpenShift
Dans le but de fournir une expérience unifiée, ces étapes d'installation sont très similaires à celles de la précédente version de Power Monitoring qui reposait sur l'opérateur communautaire.
- Activez user-workload-monitoring en suivant les instructions fournies dans la documentation de Red Hat OpenShift.
- Pour éviter les conflits inutiles, commencez par désinstaller toute ancienne version de kepler-operator que vous auriez pu installer par le biais du catalogue des opérateurs communautaires.
- Installez l'opérateur à partir de la console OpenShift 4.14 (et versions ultérieures) en accédant à Operators (Opérateurs) -> OperatorHub. Utilisez ensuite la zone de recherche pour trouver Power Monitoring for Red Hat OpenShift, cliquez dessus et sélectionnez « Install » (Installer).
- Une fois l'opérateur installé, créez une instance de la définition de ressources personnalisées Kepler en cliquant sur « View Operator » (Voir l'opérateur), puis sur « Create instance » (Créer une instance) sous l'API Kepler.

Voilà. Une fois Kepler installé, deux nouveaux tableaux de bord sont disponibles sous l'onglet Observe (Observer)>Dashboards (Tableaux de bord) de l'interface utilisateur de la console OpenShift :
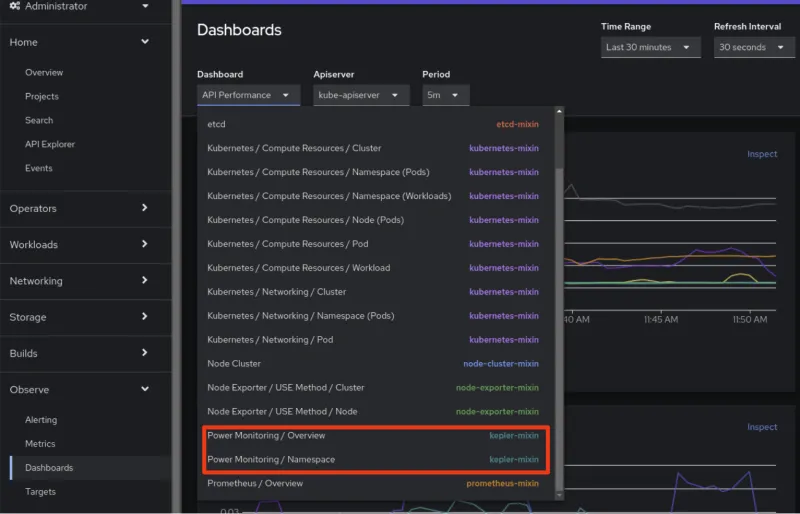
Pour obtenir plus d'informations sur l'outil Power Monitoring, lisez la documentation officielle dans les documents OpenShift.
La puissance de la surveillance
Ces tableaux de bord vous donnent accès aux renseignements suivants sur le cluster et ses charges de travail :
- Surveillance de l'énergie totale consommée par votre cluster au cours des 24 dernières heures, avec notamment une indication de l'architecture CPU sélectionnée et le nombre de nœuds surveillés
- Répartition des espaces de noms les plus énergivores
- Identification des conteneurs et des pods les plus énergivores : analyser les indicateurs de mesure fournis par Kepler sous l'onglet « Observe » -> « Metrics » (Indicateurs de mesure)
- Conseil : vous pouvez interroger tous les indicateurs de mesure de Power Monitoring en utilisant l'expression régulière { __name__ =~ "kepler.+"}
Comme mentionné précédemment, ces indicateurs de mesure sont disponibles grâce à l'intégration de Kepler à OpenShift. L'ensemble des indicateurs obtenu par Kepler dépend fortement du matériel sous-jacent et de la configuration du cluster. Actuellement, Kepler fournit des mesures précises à partir d'un ensemble spécifique de configurations cloud, en particulier celles basées sur du matériel Intel capable d'exposer Running Average Power Limit (RAPL) et Advanced Configuration and Power Interface (ACPI) dans les déploiements bare metal.
Pour les autres configurations, un modèle initial d'apprentissage automatique existe, et Red Hat travaille avec toute la communauté afin d'améliorer la précision des estimations basées sur l'apprentissage automatique. Actuellement, ces estimations sont cohérentes, ce qui vous permet de les utiliser pour mettre en évidence les variations entre les exécutions d'une même charge de travail. Il s'agit toutefois d'approximations de la consommation réelle d'énergie.
Pour que nos utilisateurs sachent plus facilement si Kepler fournit par défaut des valeurs basées sur des indicateurs de mesure ou sur des modèles, nous avons ajouté une colonne appelée « Components Source » (Source des composants) dans le panneau Node (Nœud) - CPU Architecture (Architecture CPU), sous la page Overview (Aperçu).
Cette amélioration améliore la transparence et permet aux utilisateurs de consulter la source de ces indicateurs de mesure, tels que rapl-sysfs ou rapl-msr. Si Kepler ne peut pas obtenir les indicateurs de consommation d'énergie du matériel, la source sera alors « estimator ». Dans ce cas, Kepler bascule vers le modèle d'apprentissage automatique et les estimations résultantes susmentionnées. Les projets de développement en cours visent à affiner ces modèles pour améliorer à la fois la précision et la portée des environnements qu'ils peuvent traiter.

Les indicateurs de mesure
Observons concrètement ces données avec un exemple. Après avoir installé Kepler conformément à la documentation officielle, nous avons installé un générateur de trafic HTTP/2 et un simulateur, et avons ajouté un peu de charge au système.
Voyons maintenant l'impact de la consommation d'énergie sur notre cluster OpenShift. En accédant à Observe -> Dashboards -> tableau de bord Power Monitoring Overview (Aperçu de Power Monitoring) dans la console OpenShift, nous pouvons désormais voir que :
- les nœuds affichés dans le panneau Architecture fournissent des résultats basés sur des indicateurs de mesure, car rapl-sysfs est affiché dans la colonne Components Source (Source des composants) ;
- le cluster est opérationnel depuis un certain temps, mais inactif, c'est pourquoi sa consommation n'est pas aussi importante ;
- les espaces de noms qui contribuent le plus à la facture énergétique s'affichent dans une liste.

Pour comprendre les profils de consommation d'énergie, passons au deuxième tableau de bord : « Power Monitoring / Namespace » (Espace de noms). Sélectionnons l'espace de noms qui nous intéresse (hermes-ns) :
- On voit tout de suite qu'après quelques pics, la consommation d'énergie en watts reste stable au fil du temps, et le principal contributeur est le composant PKG. Le domaine Package (PKG) mesure la consommation d'énergie de l'ensemble du socket. Il inclut la consommation de tous les cœurs, des graphiques intégrés ainsi que des composants non cœurs (caches de dernier niveau, contrôleur de mémoire, etc.). La consommation d'énergie correspond au taux d'énergie et aucune accumulation n'est trouvée.
- Nous constatons également que la consommation d'énergie augmente avec le temps. Dans ce cas, la contribution de la DRAM (qui mesure la consommation d'énergie de la RAM attachée au contrôleur de mémoire intégré) semble négligeable.

En faisant défiler la page vers le bas, nous pouvons approfondir l'analyse par conteneur des contributions de PKG et de la DRAM. Nous constatons immédiatement que les premiers pics semblent être causés par une charge de travail antérieure. Intéressant ! Nous pourrions avoir besoin d'effectuer un débogage dans notre application/simulation.
Une fois le deuxième déploiement terminé, nous voyons que les deux conteneurs contribuent de manière égale à la consommation d'énergie.

Qu'est-ce que cela signifie ? On pourrait en déduire qu'un générateur de trafic doté d'une logique complexe et d'une orchestration avec OpenTelemetry, des indicateurs de mesure et des traces consomme la même quantité d'énergie qu'une simple simulation affichant uniquement « 200 OK » sur la console. Mais même si nous sommes attachés à l'observabilité moderne, il est toujours nécessaire d'imprimer la sortie standard de temps en temps.
func exampleHandler(w http.ResponseWriter, r *http.Request) {
time.Sleep(2 * time.Millisecond)
fmt.Println("Request received. URI:", r.RequestURI, "Method:", r.Method)
w.WriteHeader(200)
}Le générateur de trafic est écrit en C++ et la simulation en Go. Des études récentes ont montré que C++ peut être plus économe en énergie que Go dans certaines conditions, avec un facteur de 2,5, mais cette réflexion ne relève pas du sujet de cet article. Nous aimons chaque langage, et chacun d'entre eux possède ses points forts. Nous avons hâte de voir comment vous utiliserez l'outil Power Monitoring. Peut-être même vous lancerez-vous dans une analyse des langages de programmation et de la consommation d'énergie en vous basant sur vos propres données.
Prochaines étapes
Nous nous engageons à prendre en compte vos commentaires, à procéder à des ajustements et à apporter des améliorations. Notre collaboration avec la communauté se poursuivra et contribuera à l'initiative mondiale visant à surveiller plus efficacement la consommation d'énergie. Les perspectives sont prometteuses, avec des projets tels que l'intégration de Power Monitoring à des initiatives de durabilité plus globales, l'observation du code sur la plateforme OpenShift ou l'exportation de données via OpenTelemetry.
Pour en savoir plus
- Documentation officielle de Red Hat OpenShift
- Article de blog : Présentation de la version préliminaire pour les développeurs de Kepler : Power Monitoring for Red Hat OpenShift
- https://sustainable-computing.io/
- Article de la CNCF : Exploring Kepler's potentials: unveiling cloud application power consumption
- Article de The New Stack : Which Programming Languages Use the Least Electricity?
- Article du portail client Red Hat : Étendue de l'assistance de la version préliminaire pour les développeurs
- Article du portail client Red Hat : Étendue de l'assistance pour les fonctions de la version préliminaire
- Article du portail client Red Hat : Comparaison de la version préliminaire et de la version préliminaire pour les développeurs
- Documentation Red Hat OpenShift Platform 4.14 : Activation de la surveillance des projets définis par l'utilisateur | Surveillance
À propos de l'auteur

Jose is a Senior Product Manager at Red Hat OpenShift, with a focus on Observability and Sustainability. His work is deeply related to manage the OpenTelemetry, distributed tracing and power monitoring products in Red Hat OpenShift.
His expertise has been built from previous gigs as a Software Architect, Tech Lead and Product Owner in the telecommunications industry, all the way from the software programming trenches where agile ways of working, a sound CI platform, best testing practices with observability at the center have presented themselves as the main principles that drive every modern successful project.
With a heavy scientific background on physics and a PhD in Computational Materials Engineering, curiousity, openness and a pragmatic view are always expected. Beyond the boardroom, he is a C++ enthusiast and a creative force, contributing symphonic and electronic touches as a keyboardist in metal bands, when he is not playing videogames or lowering lap times at his simracing cockpit.
Plus de résultats similaires
Red Hat to acquire Chatterbox Labs: Frequently Asked Questions
Key considerations for 2026 planning: Insights from IDC
Edge computing covered and diced | Technically Speaking
Parcourir par canal

Automatisation
Les dernières nouveautés en matière d'automatisation informatique pour les technologies, les équipes et les environnements

Intelligence artificielle
Actualité sur les plateformes qui permettent aux clients d'exécuter des charges de travail d'IA sur tout type d'environnement

Cloud hybride ouvert
Découvrez comment créer un avenir flexible grâce au cloud hybride

Sécurité
Les dernières actualités sur la façon dont nous réduisons les risques dans tous les environnements et technologies

Edge computing
Actualité sur les plateformes qui simplifient les opérations en périphérie

Infrastructure
Les dernières nouveautés sur la plateforme Linux d'entreprise leader au monde

Applications
À l’intérieur de nos solutions aux défis d’application les plus difficiles
Virtualisation
L'avenir de la virtualisation d'entreprise pour vos charges de travail sur site ou sur le cloud