Deliver shared access to AI with centralized model operations
- For AI engineers, MaaS provides quicker access to high-performing models via APIs, which eliminate the need to download models, manage dependencies, or request GPU allocations through lengthy IT tickets.
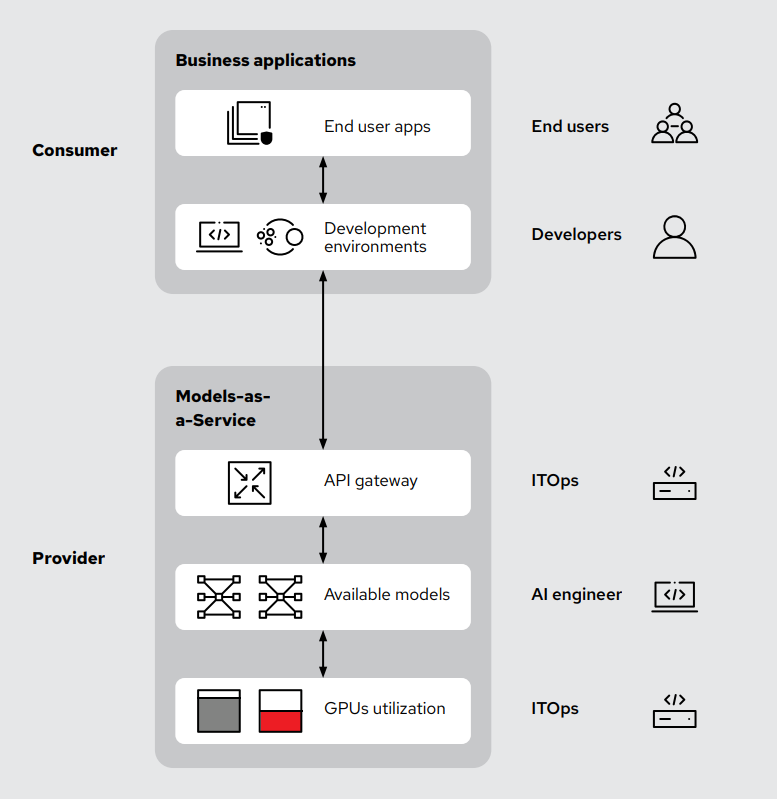
MaaS functions by setting up an AI operations team as the central owner of shared AI resources. Models are deployed on a scalable platform (such as Red Hat® OpenShift® AI or other similar platforms) and then exposed through an API gateway. This setup allows multiple users, developers, and business units to offer simplified access for end users while meeting security and governance priorities for IT and finance teams. This prioritization can include chargeback capabilities, consuming models without needing direct hardware access or deep technical expertise. The goal is to provide user-friendly access to the AI models and not to the required resources to run these models, such as GPUs and tensor processing units (TPUs). All this, while meeting enterprise performance and compliance requirements and without complicating access for end users.
In practice, users interact only with APIs that deliver model-generated responses. Just as public AI providers abstract away hardware complexities from end users, internal MaaS deployments offer the same simplicity. Users do not directly manage hardware or software infrastructure, wait for an IT ticket to be resolved on their behalf, or stand by while an environment is configured for them. Instead, IT operations and AI teams centrally manage model lifecycle, security, updates, and infrastructure scaling, offering users streamlined yet controlled access.
This centralization not only streamlines internal AI operations but also enhances security focus and governance. Access to AI models is tightly controlled through credential management via an API gateway. Organizations can readily track use, set up internal chargeback mechanisms, make sure privacy compliance guidelines are being followed, and establish clear operational boundaries, which makes enterprise AI both manageable and practical. Tracking usage at the token level (in and out) is the most accurate and granular way to do so, and much more precise than any GPU-level metric.
Control use, throttle access, and manage costs
- IT and platform engineers benefit from centralized oversight, which prevents unauthorized model deployments, enforces security and compliance standards, and simplifies lifecycle and infrastructure management.
- For finance teams, centralized use tracking and internal chargeback mechanisms reduce waste and make GPU use more predictable and accountable, avoiding overspending from underused, team-specific hardware allocations.
Control in a MaaS is primarily delivered through integrating an API gateway with the AI infrastructure, which allows teams to manage and monitor AI use at a very granular level.
Traditional AI deployments often suffer from unmanaged or inefficient use, as individuals or teams independently deploy models without centralized oversight. This fragmented approach can lead to costly inefficiencies, with GPU resources idling or underused. Placing an API gateway at the heart of the AI infrastructure creates a controlled access point between users and models.
This setup facilitates precise use tracking, down to the individual token level. Teams can clearly identify how much each user, team, or application consumes, attributing GPU and infrastructure costs accurately. For example, organizations can determine whether a particular user or application is using resources excessively and take corrective action—such as throttling use or allocating costs through internal chargeback mechanisms.
Throttling capabilities provided by the API gateway make sure there is consistent performance and prevent resource exhaustion. Use throttling allows IT teams to manage access intensity, preventing any single user from monopolizing GPU resources or degrading the performance experienced by others.
Additionally, API gateways offer fine-grained credential management and access control. Internal users can generate credentials to access AI models independently, streamlining administrative overhead. Credentials can also be revoked or modified in less time to respond to changing security requirements or use patterns.
This all means that cost management becomes more transparent and accountable. IT teams can allocate GPU and infrastructure expenses accurately to the teams or business units that consume them.
Support any model, any accelerator, and any cloud
A core tenet of the MaaS approach is control. It allows organizations to select and deploy a broad range of AI models, choose their preferred hardware accelerators, and operate within their existing cloud or on-premise environments. This approach gives organizations the freedom to implement AI precisely according to their technical needs, security requirements, and operational preferences.
- Organizations face rigid limitations when adopting AI. They are often:
- Restricted by specific cloud services.
- Locked into proprietary model ecosystems.
- Constrained by fixed hardware infrastructures.
- MaaS addresses these limitations in a number of ways, including:
- Supporting open source or proprietary models, custom-trained models, and popular LLMs such as Llama and Mistral.
- Extending beyond text-based models to include predictive analytics, computer vision, audio transcription tools, and other multimodal gen AI use cases like image or video generation.
- MaaS remains agnostic to hardware accelerators, so:
- Organizations can select GPUs or other accelerators that align with their workloads, cost structures, and performance needs.
- Centralized AI teams can make critical sizing and deployment decisions, improving efficiency and reducing errors from less technical users.
- Centralized management allows:
- Optimal allocation and use of infrastructure.
- Reduced operational overhead and prevention of resource misconfiguration.
- MaaS supports deployment across any environment, including:
- On-premise, hybrid cloud, air-gapped environments, and public clouds, which is especially valuable for highly regulated sectors that require data sovereignty, regulatory compliance, or strict security controls.