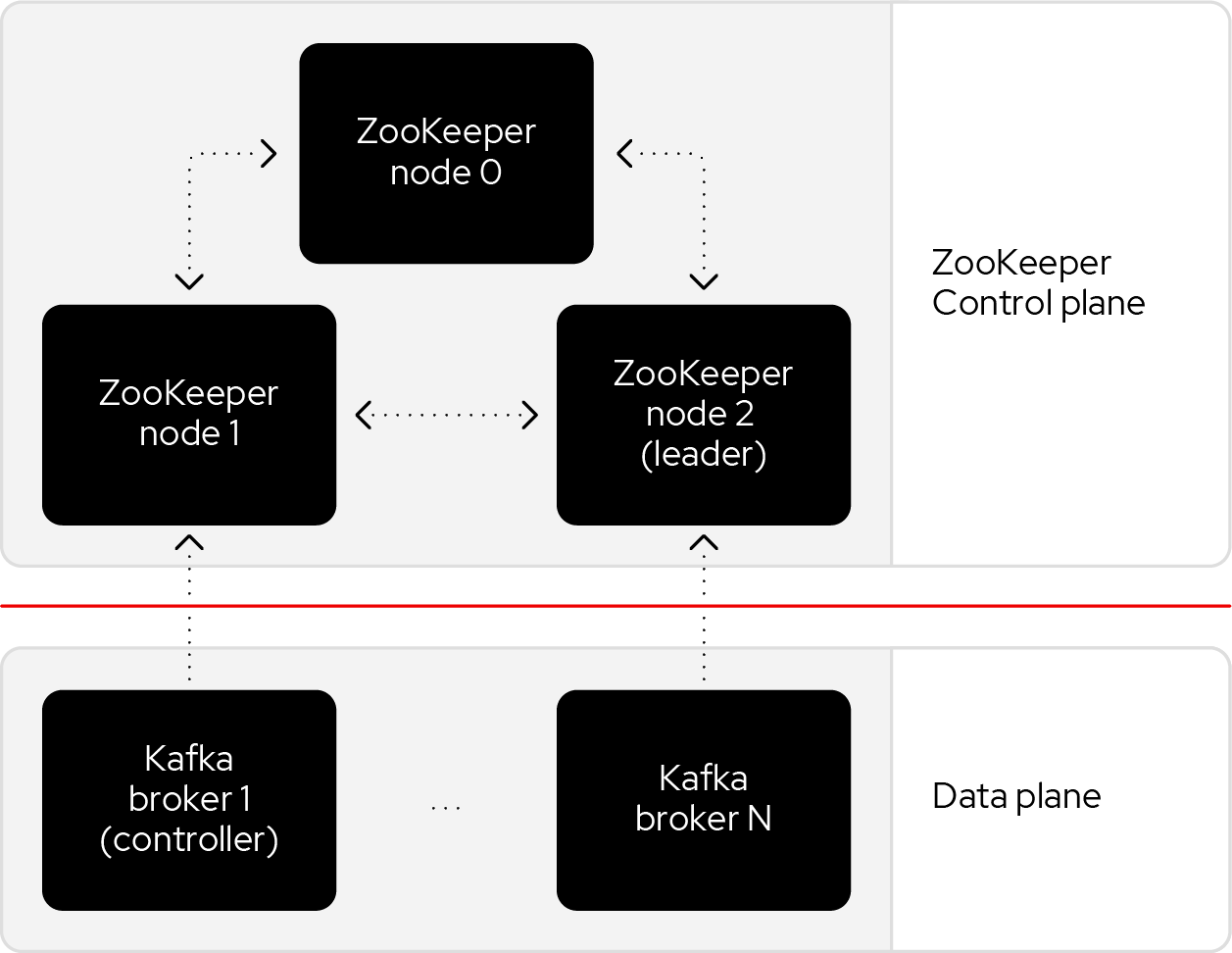
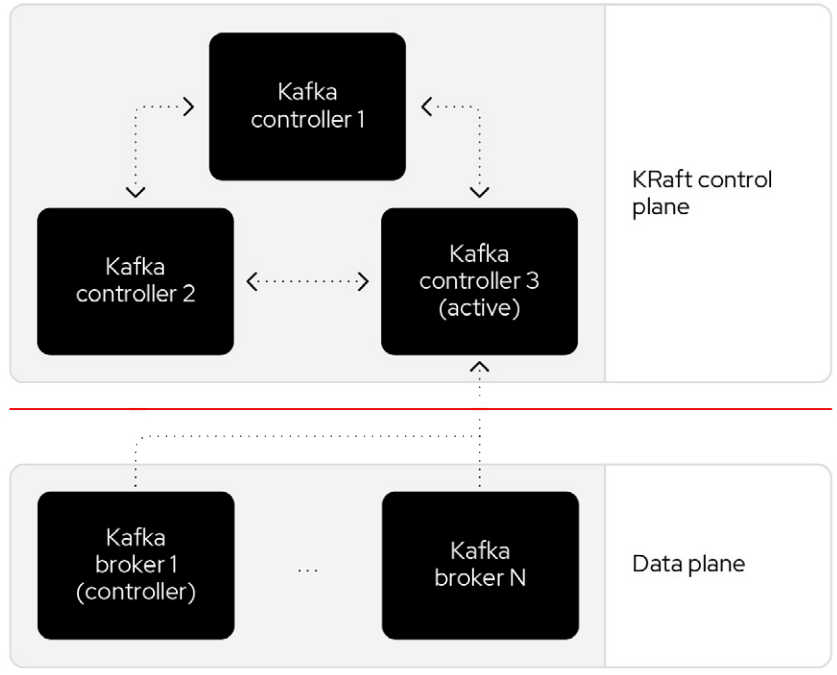
For record data, Kafka uses its own log replication protocol, rather than the quorum-based replication used in the control plane.
One broker is elected as the leader of a partition. The other brokers with replicas are called followers. Because brokers can crash or be restarted, Kafka needs to account for things like followers falling behind the leader or the leader ceasing to be available. To do this, Kafka distinguishes between followers that can keep up as new records are appended, and those that cannot. The replicas that are keeping up are in a subset of all the replicas of the partition, known as the insync replicas (ISR). A follower has in-sync status while it is regularly fetching all the latest records.
When a producer attempts to send some records to the leader to be appended, it should wait for the leader to acknowledge that the records have been appended, and be prepared to resend those messages if an acknowledgement is not received, or does not indicate success.
When a follower fails to make sufficient fetch requests to the leader to keep up, the leader removes it from the ISR—a fact that is persisted in the partition metadata in the control plane. This is controlled using the replica.lag.time.max.ms broker configuration parameter. If the leader should crash or be shut down, the control plane will choose another replica from the ISR to become the new leader.
Producers wanting to append records to the partition's log must talk to the new leader. Followers will refuse to append records from producers, forcing the producer to find the current leader and resend the records.
Combining durability and availability guarantees
Kafka provides another configuration that allows the producer to choose when the broker should send acknowledgements (acks) of produce requests, which corresponds to a commitment of durability.
- acks=0 means the producer does not want acknowledgements. This is useful for messages that can be lost without affecting business activity. In this case high availability is not a consideration because whether records can be produced or consumed is nonessential.
- acks=1 means the broker will send acknowledgements to the producer once it has appended the records to the log, regardless if the other replicating brokers have already done so. Acknowledged records can still be lost, because of a broker crash or network partition. For example, if the leader crashes immediately after its local append, but before followers have received the appended records, then the new leader would never have received the acknowledged records.
- acks=all (or acks=-1) means that the leader sends an acknowledgement only when all the brokers in the ISR have appended the records to their log.
High availability without high durability
It is possible for a topic not to have a high durability guarantee and still require high availability. For those applications, acks=1 should be sufficient. More common is a requirement for a high availability and high durability guarantee. Acks=all has the potential to provide this requirement, but it is not sufficient on its own. There is nothing preventing the ISR from being the set that contains only the leader. In this case, acks=all will be the same as acks=1.
The min.insync.replicas topic configuration (sometimes referred to as min ISR) can put a lower bound on how large the ISR must be for an acknowledgement to be sent to an acks=all producer. Using min.insync.replicas greater than 1 in combination with acks=all allows you to prevent the singleton ISR case and provide a meaningful durability guarantee.
Delaying the sending of the acknowledgement to the producer means the producer might not make progress. For example, where the producer limits the number of inflight requests or buffer sizes. Combining durability and availability guarantees is a tradeoff between the ability of the producer to send records, sometimes known as producer availability and ability of the replicas to store those records with high durability.
What does appended mean?
The meaning of the phrase “appended the records to the log” depends on how the log is configured. By default, records are appended when the memory-mapped write has returned. Once the broker process has passed responsibility to the operating system kernel to update the bytes on disk. However, this does not mean that the actual bytes on disk have been updated. The data must pass through several layers in the kernel and disk firmware before that happens. If the machine hosting a broker crashes, then those records will not make it to the disk. If the leader sent an acknowledgement to a producer based on false information that the records were safely stored, then it is possible the record could be lost.
Assuming acks=all and min ISR is greater than 1 then Kafka’s log replication protocol ensures if this happens to a single broker it will not be a problem. For example, assuming one broker in the ISR crashed this way, when it rejoined the cluster (as a follower) it would start fetching from the last valid record that was on the disk. A cyclic redundancy check (CRC) is used to detect partially written, corrupted records. Its log would be a consistent copy of the logs of other replicas.
This safety property rests on several assumptions, including:
- That crashes will not affect all members of the ISR at the same time.
- That crashes will result in replicas being removed from the ISR.
- That the CRC check is strong enough to detect partially written records.
For some high availability use cases, these are assumptions that cannot be made. Instead, you can configure the broker to flush writes to the log rather than letting the kernel decide when to flush. The topic configurations flush.messages and flush.ms can put a bound on how often to flush—based on the number of messages or elapsed time. With flush.messages=1, the broker will flush after every write to disk, so that the leader only sends acknowledgements when the records have arrived on the storage device. This additional safety causes increased latency and decreased throughput.
It is unimportant to consider that drives can report bytes as being written before they have actually hit the persistent media, but usually if they are cached on the device in volatile memory, the device will be battery-backed to allow writes to complete in the event of power failure.
Together, the replication factor,min.insync.replica, acks and flush can provide configurable high availability and durability for records. But note that the required durability affects high availability from the producers point of view.
Configurations required for high availability, include:
- The topic having a replication factor greater than 1 (3 is typical).
- The topic having a min.insync.replicas greater than 1 (2 is typical).
- The producer using acks=all (the default in Kafka 3, but not earlier versions).
- Being suitable to set flush.messages for the topic.
The replication factor (RF)=3, min ISR=2 configuration is really the starting point for a highly available topic, but it might not be enough for some applications. For example, if a broker crashes then it means that neither of the other brokers with replicas can be restarted without affecting producers with acks=all. Using RF=4 and min ISR=3 would avoid this, but would increase producer latency and lower throughput. Setting RF and min ISR to the same value should be avoided since it means producers with acks=all will be blocked if any replicating brokers go down.
Availability for consumers
Because of the need to replicate records to the ISR, producers can be affected if the size of the ISR is smaller than min.insync.replicas. But what about consumers? A consumer only requires a partition leader to make fetch requests. A consumer that is reading historical data (that is not current through to the end of the log) can make progress if there is a leader, even when a partition is under its min ISR. However, most Kafka consumers also append to a log.
These appends happen to partitions of the __consumer_offsets topic if offsets are being committed to Kafka, or if the consumer is part of a consumer group. It is important to bear this in mind when reasoning about high availability.
Alternatively, consumers can fetch records from any of the insync replicas. Although by default, the insync replicas will also use the leader.
Rack-aware replicas
The configuration parameters described so far are not enough to guarantee high availability. This is because there is nothing that forces the replicas to be assigned to brokers in different racks or AZs. Problematic assignments are not possible for clusters of three brokers in different zones. Each replica of a partition with three replicas is necessarily in a different AZs in that case. The problem manifests with larger Kafka clusters using multiple brokers in the same zone.
Kafka has some rack-awareness support that can spread replicas across zones when topics or new partitions of existing topics are created. This best-effort is only honored during creation. A later reassignment of partitions to brokers, which places replicas in the same rack or AZ, will not be rejected by the controller.
Kafka cluster management systems, such as cruise control, make certain the rack-aware placement of replicas is used. Whether such systems are used, it is good practice to monitor for, and schedule alerts for partitions which are not spread over racks or AZs.