By Annette Clewett and Luis Rico
The snapshot capability in Kubernetes is in tech preview at present and, as such, backup/recovery solution providers have not yet developed an end-to-end Kubernetes volume backup solution. Fortunately, GlusterFS, an underlying technology behind Red Hat OpenShift Container Storage (RHOCS), does have a mature snapshot capability. When combined with enterprise-grade backup and recovery software, a robust solution can be provided.
This blog post details how backup and restore can be done when using RHOCS via GlusterFS. As of the Red Hat OpenShift Container Platform (OCP) 3.11 release, there are a limited number of storage technologies (EBS, Google Cloud E pDisk, and hostPath) that support creating and restoring application data snapshots via Kubernetes snapshots. This Kubernetes snapshot feature is in tech preview, and the implementation is expected to change in concert with upcoming Container Storage Interface (CSI) changes. CSI, a universal storage interface (effectively an API) between container orchestrators and storage providers, is ultimately where backup and restore for OCS will be integrated in the future using volume snapshots capability.
Traditionally, backup and restore operations involve two different layers. One is the application layer. For example, databases like PostgreSQL have their own procedures to do an application consistent backup. The other is the storage layer. Most storage platforms provide a way for backup software like Commvault or Veritas NetBackup to integrate, obtain storage level snapshots, and perform backups and restores accordingly. An application layer backup is driven by application developers and is application specific. This study will focus on traditional storage layer backup and restore using Commvault Complete™ Backup and Recovery Software for this purpose. Other backup software tools can be used in a similar manner if they supply the same capabilities as used with Commvault.
RHOCS can be deployed in either converged mode or independent mode, and both are supported by the process described in this article. Converged mode, formerly known as Container Native Storage (CNS), means that Red Hat Gluster Storage is deployed in containers and uses the OCP host storage and networking. Independent mode, formerly known as Container Ready Storage (CRS), is deployed as a stand-alone Red Hat Gluster Storage cluster that provides persistent storage to OCP containers. Both modes of RHOCS deployment use heketi in a container on OCP for provisioning and managing GlusterFS volumes.
Storage-level backup and restore for RHOCS
If a backup is performed at the Persistent Volume (PV) level, then it will not capture the OCP Persistent Volume Claim (PVC) information. OCP PVC to PV mapping is required to identify which backups belong to which application. This leaves a gap: Which GlusterFS PV goes with which OCP PVC?
In a traditional environment, this is solved by naming physical volumes such that the administrator has a way of identifying which volumes belong to which application. This naming method can now be used in OCP (as of OCP 3.9) by using custom volume naming in the StorageClass resource. Before OCP 3.9, the names of the dynamically provisioned GlusterFS volumes were auto-generated with random vol_UUID naming. Now, by adding a custom volume name prefix in the StorageClass, the GlusterFS volume name will include the OCP namespace or project as well as the PVC name, thereby making it possible to map the volume to a particular workload.
OCS custom volume naming
Custom volume naming requires a change to the StorageClass definition. Any new RHOCS persistent volumes claimed using this StorageClass will be created with a custom volume name. The custom volume name will have prefix, project or namespace, PVC name and UUID (<myPrefix>_<namespace>_<claimname>_UUID).
The following glusterfs-storage StorageClass has custom volume naming enabled by adding the volumenameprefix parameter.
# oc get sc glusterfs-storage -o yaml apiVersion: storage.k8s.io/v1 kind: StorageClass metadata: name: glusterfs-storage parameters: resturl: http://heketi-storage-app-storage.apps.ocpgluster.com restuser: admin secretName: heketi-storage-admin-secret secretNamespace: app-storage volumenameprefix: gf ❶ provisioner: kubernetes.io/glusterfs reclaimPolicy: Delete
❶ Custom volume name support: <volumenameprefixstring>_<namespace>_<claimname>_UUID
As an example, using this StorageClass for a namespace of mysql1 and PVC name of mysql the volume name would be gf_mysql1_mysql_043e08fc-f728-11e8-8cfd-028a65460540 (the UUID portion of the name will be unique for each volume name).
Note: If custom volume naming cannot be used, then it is important to collect information about all workloads using PVCs, their OCP PV associated, and the GlusterFS volume name (contained in Path variable in description of OCP PV).
RHOCS backup process
The goal of this blog post is to provide a generic method to back up and restore OCS persistent volumes used with OCP workloads. The example scripts and .ini files have no specific dependency on a particular backup and restore product. As such, they can be used with a product such as Commvault, where the scripts can be embedded in the backup configuration. Or, they can be used standalone, assuming that basic backup/recovery of the mounted gluster snapshots will be done via standard RHEL commands.
Note: The methods described here apply only for gluster-file volumes and currently will not work for gluster-block volumes.
For this approach, a "bastion host" is needed for executing the scripts, mounting GlusterFS snapshot volumes, and providing a place to install the agent if using backup and restore software. The bastion host should be a standalone RHEL7 machine separate from the OCP nodes and storage nodes in your deployment.
Requirements for the bastion host
The bastion host must have network connectivity to both the backup and restore server (if used), as well as the OCP nodes with the gluster pods (RHOCS converged mode) or the storage nodes (RHOCS independent mode). The following must be installed or downloaded to the bastion host:
- backup and restore agent, if used
- heketi-client package
- glusterfs-fuse client package
- atomic-openshift-clients package
- rhocs-backup scripts and .ini files
RHOCS backup scripts
The github repository rhocs-backup contains unsupported example code that can be used with backup and restore software products. The two scripts, rhocs-pre-backup.sh and rhocs-post-backup.sh, have been tested with Commvault Complete™ Backup and Recovery Software. The rhocs-pre-backup.sh script will do the following:
- Find all gluster-file volumes using heketi-client
- Create a gluster snapshot for each volume
- Mount the the snapshot volumes on the bastion host that has the backup agent installed
- Protect the heketi configuration database by creating a json file for the database in the backup directory where all gluster snapshots are going to be mounted
Once the mounted snapshot volumes have been backed up, the rhocs-post-backup.sh script will do the following:
- Unmount the snapshot volumes
- Delete the gluster snapshot volumes
The two .ini files, independent_vars.ini and converged_vars.ini, are used to specify parameters specific to your RHOCS mode of deployment. Following are example parameters for converged_var.ini.
## Environment variables for RHOCS Backup: ## Deployment mode for RHOCS cluster: converged (CNS) or independent (CRS) export RHOCSMODE="converged" ## Authentication variables for accessing OpenShift cluster or ## Gluster nodes depending on deployment mode export OCADDRESS="https://master.refarch311.ocpgluster.com:443" export OCUSER="openshift" export OCPASS="redhat" export OCPROJECT="app-storage" ## OpenShift project where gluster cluster lives ## Any of the Gluster servers from RHOCS converged cluster ## used for mounting gluster snapshots export GLUSTERSERVER=172.16.31.173 ## Directory for temporary files to put the list of ## Gluster volumes /snaps to backup export VOLDIR=/root export SNAPDIR=/root ## Destination directory for mounting snapshots of Gluster volumes: export PARENTDIR=/mnt/source ## Heketi Route and Credentials export USERHEKETI=admin ## User with admin permissions to dialog with Heketi export SECRETHEKETI="xzAqO62qTPlacNjk3oIX53n2+Z0Z6R1Gfr0wC+z+sGk=" ## Heketi user key export HEKETI_CLI_SERVER=http://heketi-storage-app-storage.apps.refarch311.ocpgluster.com ## Route where Heketi pod is listening ## Provides Logging of this script in the dir specified below: export LOGDIR="/root"
The pre-backup script, when executed, uses the heketi-client for the list of current gluster-file volumes. Because of this, for the script to work properly the heketi container must be online and reachable from bastion host. Additionally, for the scripts to work properly, all GlusterFS nodes or peers of RHOCS cluster must be online, as GlusterFS snapshot operation requires all bricks of a GlusterFS volume be available.
Manual execution of pre- and post-backup scripts
This section assumes that the bastion host has been created and has the necessary packages, scripts, and .ini files are installed on this machine. Currently, the pre- and post-backup scripts run as the root user. Because of this, backing up volumes for RHOCS independent mode will require that the bastion host can SSH as the root user with passwordless access to one of the GlusterFS storage nodes. This access should be verified before attempting to run the following scripts.
The scripts can be manually executed in the following manner for RHOCS converged mode:
sudo ./rhocs-pre-backup.sh /<path_to_file>/converged_vars.iniFollowed by this script to unmount the snapshot volumes and to remove the snapshot volumes from the RHOCS Heketi database and GlusterFS converged cluster:
sudo ./rhocs-post-backup.sh /<path_to_file>/converged_vars.iniA variation of these scripts for RHOCS independent mode can be manually executed in the following manner:
sudo ./rhocs-pre-backup.sh /<path_to_file>/independent_vars.iniFollowed by this script to unmount the snapshot volumes and to remove the snapshot volumes from the RHOCS Heketi database and GlusterFS independent cluster:
sudo ./rhocs-post-backup.sh /<path_to_file>/independent_vars.iniFor each execution of the pre- or post-backup script a log file will be generated and placed in the directory specified in the .ini file (default is /root).
Note: Pre-backup scripts can be modified as needed for specific scenarios to achieve application-level consistency, like quiescing a database before taking a backup. Also, if special features are used with RHOCS, like SSL encryption or geo-replication, scripts will have to be customized and adjusted to be compatible with those features.
Commvault backup process
Note that this blog post does not cover the tasks to install and configure Commvault to back up and restore data. In addition to having the Commvault Console and Agent in working order, this section also assumes that the bastion host has been created and has the necessary packages, scripts, and .ini files installed.
The use of these scripts to back up OCP PVs is compatible with any backup frequency or retention configured in the Commvault backup policy. But, as we are mounting gluster snapshots in newly created folders with date and time information, the backup application will always consider contents as new, so even if backup policy is incremental, it will effectively do a full backup. Also, the backup content will consist of dozens or even hundreds of very small filesystems (1-10 GB), that could run faster under a "always do full backup" strategy.
Detailed process for backup using Commvault
Once the scripts and .ini files are on the bastion host and a Commvault Agent is installed, a backup can be done using the Commvault Commcell Console or the Commvault Admin Console. The following views show how to do the backup using the Commcell Console and validate the backup using the Admin Console.
A Subclient must be created before a backup can be done and a unique name must be specified.
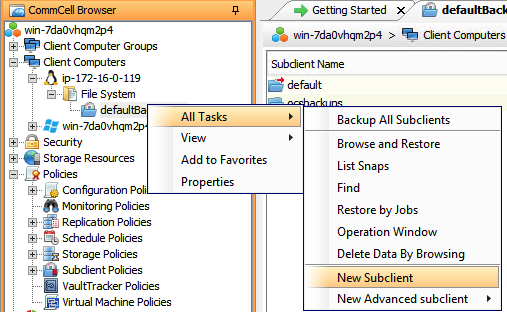
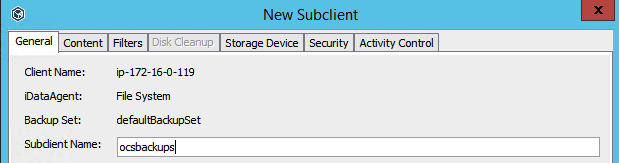
When creating a Subclient, you must input where on the bastion host you want the backup to be done from on the bastion host with Commvault Agent (e.g., /mnt/source).

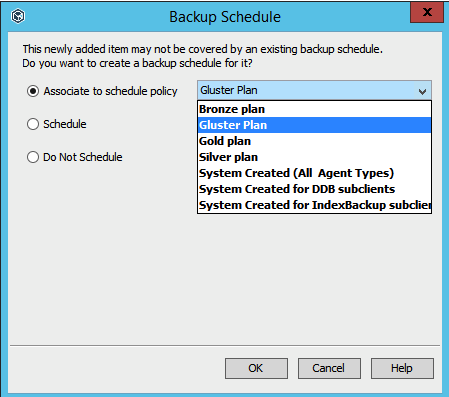
Choose what schedule you want the backup done on (or Do Not Schedule; start backup manually using Console instead).
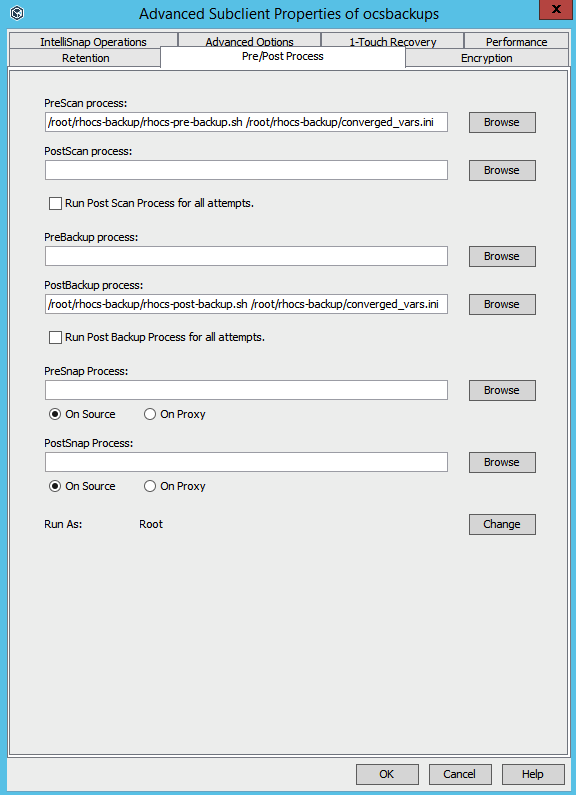
And last or the Subclient configuration, add the path to the pre- and post-backup scripts, as well as the path to the appropriate .ini file, converged_vars.ini or independent_vars.ini. Once this is done and the subclient has been saved, you are ready to take a backup of the gluster-file snapshot volumes.
The backup can then be done by selecting the desired subclient and issuing an immediate backup or letting the selected schedule do the backups when configured (e.g., daily).
For an immediate backup, you can choose full or incremental. As already stated, a full backup will be done every time, because the pre-backup script always creates a new directory to mount the gluster-file snapshot volume.

You can track backup progress using the Job Controller tab.

Once the backup is complete, in the Job Controller tab of the Commvault Commcell Console, verification can be done by logging into the Commvault Admin Console, selecting the correct subclient (ocsbackups), and viewing the backup content for the GlusterFS volumes and the heketi database.

RHOCS restore and recovery process
Now that there are backups for RHOCS snapshot volumes, it is very important to have a process for restoring the snapshot from any particular date and time. Once data is restored, it can be copied back into the OCP PV for a target workload in a way that avoids conflicts (e.g., copying files into running workload at same time updates are attempting to be made to same files).
To do this, we will use CLI command "oc rsync" and an OCP "sleeper" deployment. You can use the command "oc rsync" to copy local files to or from a remote directory in a container. The basic syntax is "oc rsync <source> <destination>". The source can be a local directory on the bastion host or it can be a directory in a running container, and similar is true for the destination.
In the case where the data in a PV must be completely replaced, it is useful to use a "sleeper" deployment as a place to restore the data so that the workload can essentially be turned off while the data is being restored to its volume, thereby avoiding any conflicts. The sleeper deploymentconfig will create a CentOS container and mount the workload PVC at a configured mount point in the CentOS container. This allows the backup gluster snapshot for the PV to then be copied from the directory where the snapshot was restored into the sleeper container (e.g., oc rsync <path to directory with restored data>/ sleeper-1-cxncv:/mnt --delete=true).
Simple restore or file-level recovery
This section details how to restore files or folders from a backup of a particular volume to a local working directory on the bastion host.
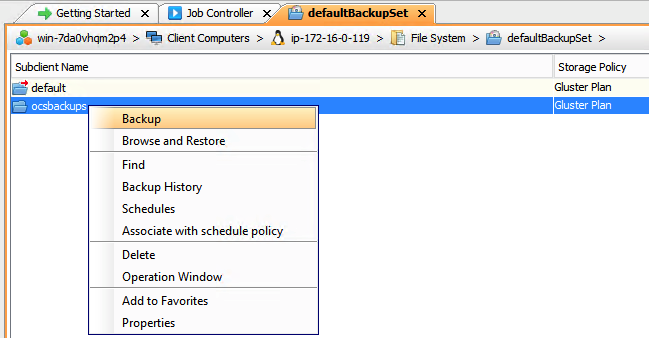
- Identify the desired backup of the gluster snapshot volume by date and time and volume name (see the following in Commvault subclient Restore view). Find the folder or files you want to restore, and check the appropriate boxes.
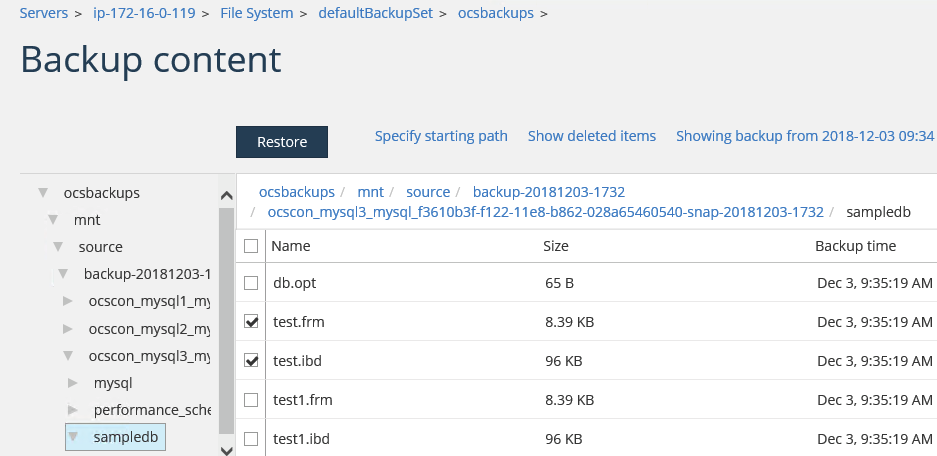
2. Restore the files to the same directory where the backup was taken or to any other directory on the bastion host.
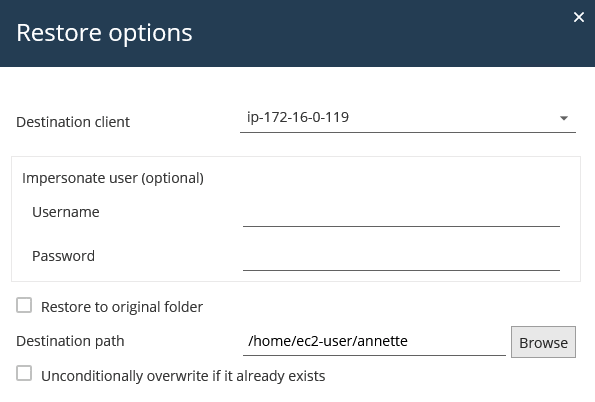
3. Verify that the files are in the specified directory for the Commvault Restore. They can now be copied into the
destination pod using "oc rsync" or the method described in the next section using a "sleeper" deployment.
$ pwd /home/ec2-user/annette $ ls -ltr test* -rw-r-----. 1 1000470000 2002 8590 Dec 3 17:19 test.frm -rw-r-----. 1 1000470000 2002 98304 Dec 3 17:19 test.ibd
Complete restore and recovery
This section details how to restore an entire volume. The process tested here will work for operational recovery (volumes with corrupted data), instances where volumes were inadvertently deleted, or to recover from infrastructure failures. The following example is for a MySQL database deployed in OCP.
- Identify the desired backup by date, time, and volume name (see the backup directory that is checked in Commvault Subclient Restore view).
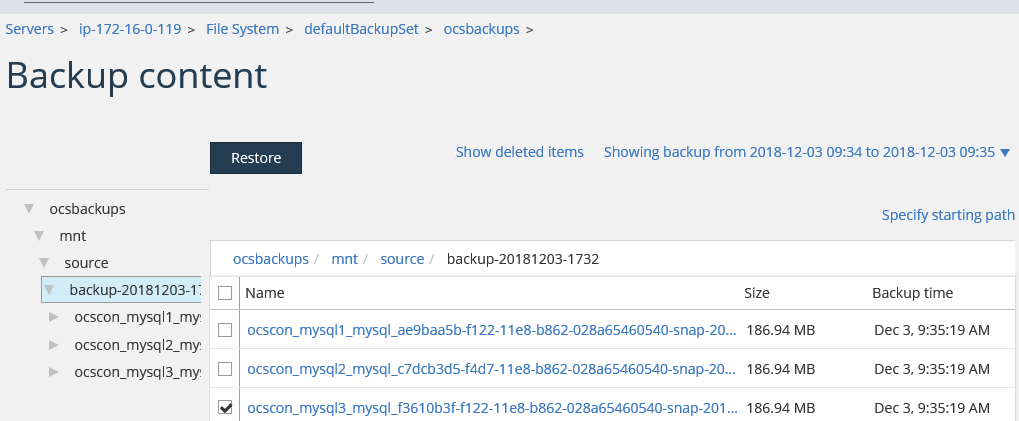
2. Restore the backup to original directory where backup was taken of mounted gluster snapshot volume or any other directory on the bastion host.
# ls /mnt/source/backup-20181203-1732/ocscon_mysql3_mysql_f3610b3f-f122-11e8-b862- 028a65460540-snap-20181203-1732 auto.cnf ca.pem client-key.pem ibdata1 ib_logfile1 mysql mysql_upgrade_info private_key.pem sampledb server-key.pem ca-key.pem client-cert.pem ib_buffer_pool ib_logfile0 ibtmp1 mysql-1-gs92m.pid performance_schema public_key.pem server-cert.pem sys
3. Change to the correct namespace or project (oc project msyql3).
4. Scale the mysql deploymentconfig to zero to temporarily stop the database service by deleting the mysql pod (oc scale --replicas=0 dc mysql).
5. Create a sleeper deployment/pod (oc create -f sleeper-dc.yml). The YAML file to create the “sleeper deployment/pod” can be found in the next section.
6. Copy the backup to the PVC mounted in sleeper pod (oc rsync <path to directory with restored data>/ sleeper-1-cxncv:/mnt --delete=true).
# oc rsync /mnt/source//backup-20181203-1732/ocscon_mysql3_mysql_f3610b3f-f122-11e8-b862- 028a65460540-snap-20181203-1732/ sleeper-1-f9lgh:/mnt --delete=true
Note: Disregard this message: WARNING: cannot use rsync: rsync not available in container.
7. Delete sleeper deploymentconfig (oc delete dc/sleeper)
8. Scale up the mysql deploymentconfig to recreate the mysql pod and start the service again. This will mount the mysql volume with the restored data (oc scale --replicas=1 dc mysql).
9. Log in to the mysql pod and confirm the correct operation of the database with the restored data.
Creating the Sleeper DeploymentConfig
Following is the YAML file to create the sleeper deployment (oc create -f dc-sleeper.yaml). This deployment must be created in same namespace or project as the workload you are trying to restore data to (e.g., the mysql deployment).
Note: The only modification needed for this YAML file it to specify the correct <pvc_name> below (e.g., mysql).
$ cat dc-sleeper.yaml --- apiVersion: apps.openshift.io/v1 kind: DeploymentConfig metadata: annotations: template.alpha.openshift.io/wait-for-ready: "true" name: sleeper spec: replicas: 1 revisionHistoryLimit: 10 selector: name: sleeper strategy: activeDeadlineSeconds: 21600 recreateParams: timeoutSeconds: 600 resources: {} type: Recreate template: metadata: labels: name: sleeper spec: containers: - image: centos:7 imagePullPolicy: IfNotPresent name: sleeper command: ["/bin/bash", "-c"] args: ["sleep infinity"] volumeMounts: - mountPath: /mnt name: data dnsPolicy: ClusterFirst restartPolicy: Always schedulerName: default-scheduler securityContext: {} terminationGracePeriodSeconds: 5 volumes: - name: data persistentVolumeClaim: claimName: <pvc_name> test: false triggers: - type: ConfigChange
SQL Server database point-in-time recovery example
To make sure there are no updates during the gluster-file snapshot, the following must be done for a mysql volume so that the backup is consistent.
- Log in to the mysql pod.
- Log in to mysql (mysql -u root).
- mysql>USE SAMPLEDB;
- mysql> FLUSH TABLES WITH READ LOCK;
- Take a gluster snapshot of the mysql volume by executing the rhocs-pre-backup.sh script manually for the correct RHOCS mode.
- mysql> UNLOCK TABLES;
- Remove the pre- and post-backup scripts in the Advanced tab for the Commvault subclient.
- Take a backup of the snapshot volume.
- Execute the rhocs-post-backup.sh script manually for the correct RHOCS mode (unmount and delete the gluster snapshot volumes).
- Continue with step 2 in the the "Complete restore and recovery" section.
Backup scripts on Github
Scripts and .ini files can be found here. You are more than welcome to participate in this effort and improve the scripts and process.
Want to learn more about Red Hat OpenShift Container Storage?
Get a more intimate understanding of how Red Hat OpenShift and OCS work together with a hands-on test drive, and see for yourself.
Still want to learn more? Check out the Red Hat OpenShift Container Storage datasheet.
À propos de l'auteur

Plus de résultats similaires
Friday Five — March 27, 2026 | Red Hat
Modernize virtual machines on Google Cloud with Red Hat OpenShift Virtualization
Keeping Track Of Vulnerabilities With CVEs | Compiler
Post-quantum Cryptography | Compiler
Parcourir par canal

Automatisation
Les dernières nouveautés en matière d'automatisation informatique pour les technologies, les équipes et les environnements

Intelligence artificielle
Actualité sur les plateformes qui permettent aux clients d'exécuter des charges de travail d'IA sur tout type d'environnement

Cloud hybride ouvert
Découvrez comment créer un avenir flexible grâce au cloud hybride

Sécurité
Les dernières actualités sur la façon dont nous réduisons les risques dans tous les environnements et technologies

Edge computing
Actualité sur les plateformes qui simplifient les opérations en périphérie

Infrastructure
Les dernières nouveautés sur la plateforme Linux d'entreprise leader au monde

Applications
À l’intérieur de nos solutions aux défis d’application les plus difficiles
Virtualisation
L'avenir de la virtualisation d'entreprise pour vos charges de travail sur site ou sur le cloud