TL;DR: The same 16 GPUs, twice the users. Your GPU bill remains flat while capacity doubles. A cluster that handled 20 concurrent users now handles 200. These numbers are made possible by llm-d’s inference scheduler, built to route every request across a distributed cluster with visibility into every node, every queue, and every cache. Large language model (LLM) requests are slow, non-uniform, and expensive—the inference scheduler is built for exactly that.
The pattern that works everywhere else
Every GPU-hour has a price, the question is how much work you are getting out of it.
Kubernetes is how distributed services get built, deployed, and operated at scale. In a standard Kubernetes configuration, you define a deployment, set a replica count, and a Kubernetes service gives you a front door with round-robin load balancing across all your pods. For REST APIs, web services, and microservices, this pattern is essentially perfect. Requests are fast, uniform, and each one takes roughly the same sub-second time to complete.
But the moment you start serving large generative models at scale, such as Llama, Mistral, or GPT-class open source models, that assumption no longer holds.
Where round robin reaches its limits
LLM inference requests are not like normal HTTP requests, and the differences are what break standard load balancing:
- Time variability: A request can take less than a second or over a minute, depending on what the model is asked to do. Round robin distributes requests, not work. If one replica gets a sequence of long, expensive requests, it becomes a bottleneck while another sits largely idle.
- Shape variability: Short prompts with long generated responses behave differently from long prompts with short responses. The compute profile, the memory pressure, and the time to completion are all different.
- Phase variability: Every inference request has 2 internal phases: prefill, which processes the entire input prompt in one parallel sweep, and decode, which generates the response 1 token at a time. These 2 phases have different resource profiles, different durations, and different sensitivity to load. A system that can't tell them apart can't optimize for either.
Round robin was built for workloads where requests are short-lived, uniform, and cheap. A scheduler that can't see inside the request treats them as the same thing.
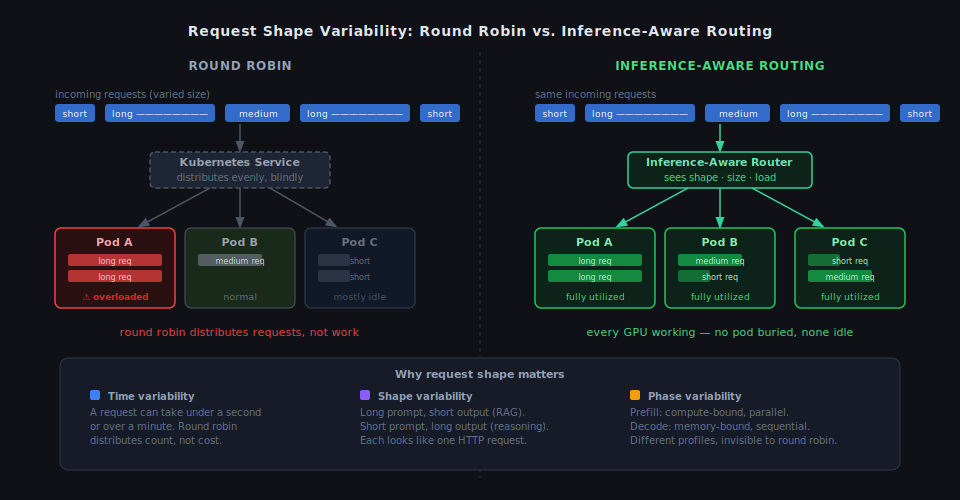
Figure 1: Round robin distributes request count, not work. The same 5 requests (varied in size and compute cost) land unevenly across pods. One pod is buried under 2 long requests while another sits mostly idle. Inference-aware routing sees shape, size, and load, and balances actual work instead.
A cache hit on the wrong pod is a cache miss
vLLM is the de facto standard inference engine for LLMs—every major hardware accelerator is optimized for it and new models ship with Day 0 vLLM support. It handles the mechanics of inference on a single node exceptionally well.
vLLM introduced prefix caching to address one of the most expensive parts of inference, reprocessing the same prompt prefixes over and over. When multiple requests share a common prefix (a system prompt, a document, a conversation history), vLLM can cache the Key-Value (KV) state from the first computation and reuse it for subsequent requests. On a cache hit, the prefill step is skipped entirely: time to first token (TTFT) drops proportionally to the share of the prompt that was already cached, but only if the request reaches the specific replica that holds that cache.
A request that would be nearly free on one replica gets routed to another where it starts from scratch. The optimization exists, but the round robin routing ignores it.
At low traffic this is a missed opportunity. At scale, you are paying twice for the same computation.
Taking it from node to cluster
Each pod only sees itself, even though each vLLM pod handles its share of requests well—managing memory, batching efficiently, serving tokens as fast as the hardware allows. It does not know what its peers are processing, which replicas are under load, or where prefix cache state lives across the cluster.
The coordination problem lives above the node and Kubernetes is the platform of choice for distributed infrastructure and orchestration at scale, so llm-d is built to be Kubernetes-native from the ground up to solve this exact problem.
The Inference Gateway (IGW) is how that shows up in practice—a traffic layer built on Envoy and the Kubernetes Gateway API that understands LLM workloads, not just HTTP. Behind it, the Inference Scheduler watches every pod in the InferencePool in real time—queue depth, KV cache state, load—and routes each request to the right instance rather than the next one in rotation.
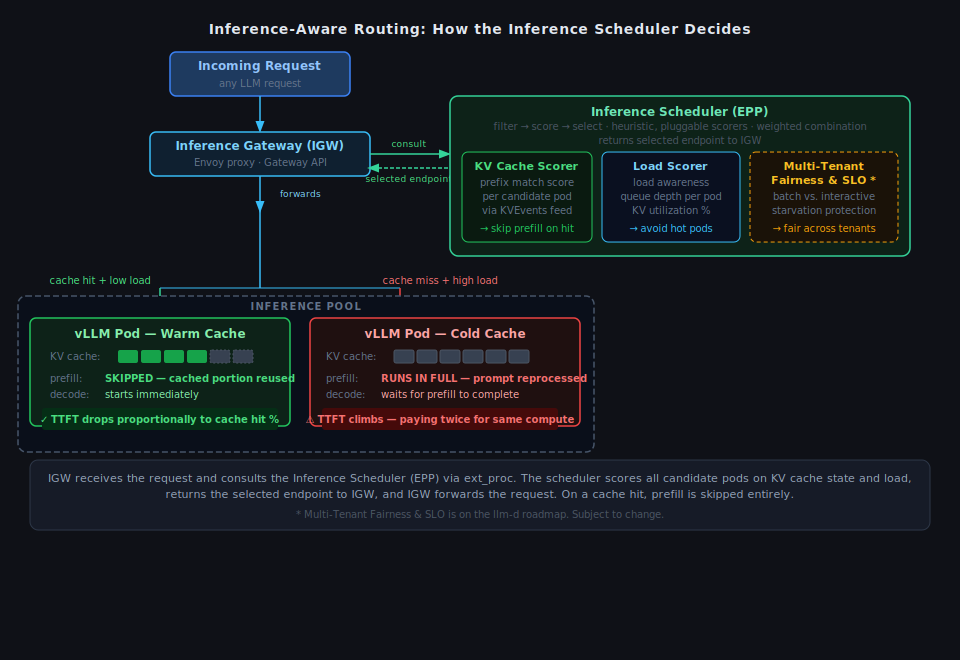
Figure 2: The Inference Gateway (IGW) receives each request and consults the Inference Scheduler (EPP) via ext_proc. The scheduler scores all pods in the InferencePool on 2 live signals (KV cache state and load), returns the selected endpoint to IGW, and IGW forwards the request. On a cache hit, the cached portion of prefill is reused and decode starts immediately. On a cache miss, prefill runs in full.
Inference scheduling at scale: Same hardware, twice the capacity
The inference scheduler (llm-d’s Inference Scheduler, or EPP) is what makes cluster-level coordination concrete. Rather than treating all pods as interchangeable, it routes each request based on real-time signals: KV cache state, queue depth, and load. Every request goes to the right instance, every time.
The benchmark results from llm-d v0.5 show what this delivers in practice.
Inference scheduling (Qwen3-32B, 8x vLLM pods, 16x NVIDIA H100):
- Up to 109% higher throughput vs a baseline Kubernetes service. The same 16 GPUs serve roughly twice as many concurrent users at their service level objective (SLO).
- Up to 99% lower time to first token (TTFT) under equivalent load. The benchmark shows baseline TTFT climbing to a painful ~80 seconds under high load. Intelligent scheduling holds it to ~150ms. That is the difference between a product that feels broken and one that feels instant.
- The benchmark sustains ~11,000 output tokens/sec on 16 GPUs. Assuming ~1,000 tokens per response and ~3 requests per minute per active user, that translates to roughly 200 concurrent users at SLO, on hardware that the baseline Kubernetes service stops serving usably past 20.
Every result is version-controlled and tied to a specific reproducible guide.

Figure 3: llm-d inference scheduling vs baseline Kubernetes — Mean TTFT and total throughput vs QPS. Topology: 8× vLLM pods, 16× NVIDIA H100 (TP=2). Workload: shared prefix synthetic, 150 groups × 5 prompts, 6k/1.2k/1k system/question/output length. Results: P50 TTFT 136–157ms, 4.5–11k output tok/s, up to 109% higher throughput and 99% lower TTFT vs baseline. Source: llm-d v0.5.
vLLM optimizes the node, llm-d optimizes the cluster
vLLM and llm-d are designed to work together, and the performance gap between running one without the other is measurable: 2x the users on the same hardware, 99% better latency under load, a cluster that holds up at 250 concurrent users as well as it did at 20.
If you are running 2 or more replicas, intelligent inference scheduling applies to your workload today. The performance gap is not incremental—it is the difference between a cluster that scales and one that struggles.
This is where distributed inference starts.
Experience the scale for yourself
The llm-d guides and benchmark configurations behind every number in this blog post are public and reproducible. A good starting point is the llm-d v0.5 release.
Red Hat AI Enterprise includes an enterprise-supported version of llm-d with a 60-day free trial of Red Hat AI Enterprise. This is a good place to start if you want to run this on your own infrastructure.
If you want to see the scheduler in action first, the Introduction to llm-d Interactive Demo walks through how requests get routed.
Author's Note: Benchmark data sourced from the llm-d v0.5 release. All results are reproducible using version-controlled configurations published in the llm-d guides.
リソース
AI 推論を始める
執筆者紹介

Naina Singh leads AI Inference Product Strategy at Red Hat, where she works with enterprises running LLM inference in production. She focuses on the operational and economic decisions that determine whether inference runs profitably at scale. She holds two patents and an MBA from UNC Kenan-Flagler.
類似検索
エージェント型のパラドックスとハイブリッド AI の事例
過去を管理するのをやめて、IT の未来を構築しましょう
Technically Speaking | Build a production-ready AI toolbox
Technically Speaking | Platform engineering for AI agents
チャンネル別に見る

自動化
テクノロジー、チームおよび環境に関する IT 自動化の最新情報

AI (人工知能)
お客様が AI ワークロードをどこでも自由に実行することを可能にするプラットフォームについてのアップデート

オープン・ハイブリッドクラウド
ハイブリッドクラウドで柔軟に未来を築く方法をご確認ください。

セキュリティ
環境やテクノロジー全体に及ぶリスクを軽減する方法に関する最新情報

エッジコンピューティング
エッジでの運用を単純化するプラットフォームのアップデート

インフラストラクチャ
世界有数のエンタープライズ向け Linux プラットフォームの最新情報

アプリケーション
アプリケーションの最も困難な課題に対する Red Hat ソリューションの詳細
仮想化
オンプレミスまたは複数クラウドでのワークロードに対応するエンタープライズ仮想化の将来についてご覧ください