-
製品とドキュメント Red Hat AI
ハイブリッドクラウドでの AI の開発とデプロイのための製品およびサービスのプラットフォーム。
Red Hat AI Enterprise
AI を活用したアプリケーションをハイブリッドクラウドのどこででも構築、開発、デプロイします。
-
学ぶ 基本
-
AI パートナー
AI 推論を重視すべき理由
簡単に言うと、推論を使わない AI は存在しません。
推論は生成 AI の中核です。しかし、大規模なモデルでさらに大規模な戦略を実行すると、状況が複雑化することがあります。
そのため Red Hat は、vLLM によるモデル最適化から llm-d のような最新のオープンソース分散フレームワークまで、AI 推論に伴う課題と機会を分析しています。
推論が重要な理由
推論は長く複雑な機械学習プロセスの最終ステップであり、モデルはここで目的の出力を提供します。
最も重要なのは、推論は AI の成功のために必要な機能だということです。
つまり AI 戦略の成否は、推論機能をサポートするハードウェアとソフトウェアによって決まります。

拡張を妨げる要素
推論は、巨大化し続けるモデルからの大きなプレッシャーにさらされます。モデルが複雑になるほど、推論の速度は遅くなるのです。
推論を成功させるには、AI モデルが短時間で多くの計算を行う必要があります。そのため、モデルサイズ、ユーザー数の多さ、レイテンシーなどの要因によってパフォーマンスが制限される可能性があります。
モデルがより多くのデータとメモリーを要求する場合、ハードウェアとアクセラレーターがそれに対応していくのは簡単なことではありません。
66%
推論によって消費される AI コンピューティングリソースの割合 (2026 年の予測値。2023 年 は 33%、2025 年は 50%)1
より優れた推論方法
推論を最適化すると、AI モデルをより高速かつスマートに実行できます。
最適化の方法としては、GPU 処理の効率化、投機的デコーディング、スパース性、量子化技法によるモデル圧縮、分散推論などがあります。
LLM Compressor などのツールは、最新のモデル圧縮研究を利用して、LLM をより小型化し、エネルギー効率を高め、高速化します。これにより、精度を犠牲にすることなく、ハードウェア要件が削減され、効率が向上します。
このような最適化により、AI 推論のコスト効率が維持され、チームの状況に合わせて拡張できるようになります。
99% 超
LLM Compressor を使用した最適化時の精度の維持率2

2 倍
圧縮モデルを使用することで、精度を犠牲にすることなく達成できる計算スループットの向上率3
50%
LLM Compressor を使用してモデルを最適化することで、パフォーマンスを犠牲にすることなく達成できるコスト削減率4

vLLM が推論を最適化する方法
モデルの最適化は戦いの半分に過ぎません。高性能な推論エンジンも必要です。そこで役立つのが vLLM です。
従来の LLM メモリー管理システムではメモリーが効率的に整理されないため、LLM の動作が遅くなります。それに対し、vLLM は繰り返し使用されるキー値を識別して LLM の余分な作業を削減する PagedAttention というメモリー管理手法を使用します。
これにより、vLLM は GPU メモリーをより有効に活用できるようになるため、生成 AI 推論が高速化されます。スループット (1 秒あたりの処理トークン) が最大化され、多くのユーザーに一度にサービスを提供できます。
アクセラレーターを効率的に使用すると、モデルは短時間でより多くの計算を実行できるため、チームは多くのユーザーとエージェントに迅速に対応できるようになります。
50%
スパース性構造を使用した場合のパラメーターの削減率5

2.1 倍
投機的デコーディング技法による推論のレイテンシー削減率6
24 倍
vLLM によるスループット・パフォーマンス向上率 (競合他社との比較)7
vLLM が人気の理由
vLLM は、GPU の効率的な使用に関する主な問題の解決に役立ってきました。オープンで可搬性のあるデプロイのアプローチで、トークンあたりのコスト削減やレイテンシーの大規模な安定化を実現します。
だからこそ、vLLM コミュニティは活発で活気に満ちているのです。このプロジェクトには、Hugging Face、UC Berkeley、NVIDIA、Red Hat などの熱心なグループが貢献しています。このコミュニティは、オープンソース・プロジェクトのソフトウェアに継続的に挑戦し、改善を続けています。
すべての主要モデルとアクセラレーターの Day 0 サポートが提供されており、そのアクセシビリティは産業界と学術界の両方にとって魅力的なものとなっています。
1 万以上
2025 年の vLLM GitHub のコミット数* (増加率 200%)
vLLM コミュニティの現状
50 万以上
年中稼働のデプロイ済み GPU 数8
200 以上
アクセラレーターのタイプ数9
500 以上
サポートされているモデルアーキテクチャ数9
2,200 以上
分散推論の役割
分散推論を使用すると、AI モデルは相互接続されたデバイスのグループの中で推論処理を分割できます。
1 つのモデルが複数の要求をすべて同時に処理できれば、必要なハードウェアが大幅に削減され、推論の効率が向上します。
分散推論では、テンソル並列処理、インテリジェントな推論スケジューリング、ディスアグリゲーションなどの手法が使用されます。vLLM を併用すれば、推論は非常に効率的なマルチタスクのマシンとなります。
これにより、推論の可観測性、スケーラビリティ、一貫性が維持されます。
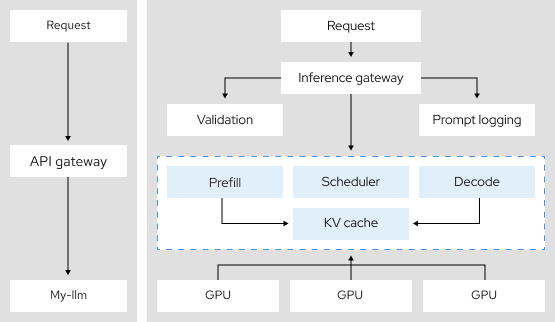
3.9 倍
分散推論アーキテクチャであるテンソル並列処理を使用した場合のトークンのスループット向上率10
オープンソース・コミュニティ
llm-d と呼ばれるコミュニティがあります。
llm-d は、大規模な分散推論を構築するための青写真を開発者に提供するオープンソース・フレームワークです。
モジュール式のアーキテクチャなので、高度な LLM の複雑なリソース要求をサポートし、手動の断片化されたプロセスを統合された「明るい道筋」に置き換えて、パイロットからプロダクションまでの時間を短縮できます。
llm-d を使うと Kubernetes で推論ができるようになるので、分散推論を独自のエンタープライズ・ユースケースに適用するのに役立つ標準化されたツールキットが得られます。
2 倍
llm-d が維持する 1 秒あたりのクエリ数 (QPS) のベースライン11
その他の AI 関連資料
Red Hat AI Inference Server
LLM をコードからプロダクションへと迅速に移行しましょう。
Red Hat のエンタープライズグレードの推論エンジンは vLLM を使用して構築されており、パフォーマンスを犠牲にすることなく推論を高速化します。
どのようなクラウド環境でどの AI アクセラレーターを使用していても、好みの最適化された生成 AI モデルを使用してハイブリッドクラウド全体を拡張できます。

引用の出典
[1] 「Why AI’s Next Phase Will Likely Demand More Computing Power—Not Less」、The Wall Street Journal、2026 年 1 月 22 日。
[2] Eldar Kurtić、他、「We ran over half a million evaluations on quantized LLMs—here's what we found」、Red Hat Developer ブログ、2024 年 10 月 17 日。
[3] Carlos Condado、 「AI 推論パフォーマンスへの戦略的アプローチ」、Red Hat ブログ、2025 年 9 月 15 日。
[4] Saša Zelenović、「LLM の潜在能力を最大限に引き出す:vLLM でパフォーマンスを最適化」、Red Hat ブログ、2025 年 2 月 27 日。
[5] Eldar Kurtić、他、「2:4 Sparse Llama:Smaller models for efficient GPU inference」、Red Hat Developer ブログ、2025 年 2 月 28 日。
[6] Alexandre Marques、他、「Fly Eagle(3) fly:Faster inference with vLLM & speculative decoding」、Red Hat Developer ブログ、2025 年 7 月 1 日。
[7] Woosuk Kwon、他、「vLLM:Easy, Fast, and Cheap LLM Serving with PagedAttention」、vLLM ブログ、2023 年 6 月 20 日。
[8] Michael Goin、「[vLLM Office Hours #38] vLLM 2025 Retrospective & 2026 Roadmap - December 18, 2025」、YouTube、2025 年 12 月 8 日。
[9] Woosuk Kwon、「Today, vLLM supports 500+ model architectures, runs on 200+ accelerator types, and powers inference at global scale」、X、2026 年 1 月 26 日。
[10] Michael Goin、「Distributed inference with vLLM」、Red Hat Developer、2025 年 2 月 6 日。
[11] Robert Shaw、「llm-d:Kubernetes-native distributed inferencing」、Red Hat Developers、2025 年 5 月 20 日。