

昨今の顕著な傾向として、大規模言語モデル (LLM) インフラストラクチャを社内に導入する組織が増えています。オープンソースモデルと自社のハードウェアを使用したセルフホスティングにより、レイテンシー、コンプライアンス、データプライバシーといった AI の導入に伴う課題を制御できます。しかし、LLM を実験の段階からプロダクション対応のサービスへと拡張するには、相当なコストが必要になり、その複雑さにも対処する必要があります。
Red Hat、IBM、Google などの強力なコントリビューターが支援する新しいオープンソース・フレームワークである llm-d は、これらの課題に対処するよう設計されています。llm-d は、問題の核となる AI 推論に焦点を当てています。AI 推論とは、プロンプト、エージェント、検索拡張生成 (RAG) などに関連して、モデルが結果を生成するプロセスです。
llm-d は、スマートなスケジューリング決定 (ディスアグリゲーション) と AI 固有のルーティングパターンにより、LLM のワークロードを動的かつインテリジェントに分散させます。では、これがなぜ重要なのでしょうか。llm-d の仕組みと、llm-d がどのようにしてパフォーマンスの向上と AI コストの削減に役立つかを見ていきましょう。
LLM 推論のスケーリングに関する課題
Kubernetes などのプラットフォームで従来の Web サービスをスケーリングする場合は、確立されたパターンに従います。通常、標準的な HTTP リクエストは高速で均一、かつステートレスです。しかし、LLM 推論のスケーリングはそれとは根本的に異なる問題です。
その主な理由の 1 つは、リクエストの特性にばらつきがあることです。たとえば RAG パターンでは、ベクトルデータベースから取得したコンテキストを含めた長い入力プロンプトを使用して、短い一文の回答を生成する場合があります。反対に、推論タスクは短いプロンプトから始まり、長い複数ステップの応答を生成する場合があります。この差異により、負荷分散が不均一になり、それがパフォーマンスの低下とテールレイテンシー (ITL) の増加につながります。また、LLM 推論は中間結果の保存を、LLM の短期メモリーであるキー値 (KV) キャッシュに大きく依存しています。従来の負荷分散はこのキャッシュの状態を認識しないため、リクエストのルーティングが非効率的になり、コンピューティング・リソースが十分に活用されません。

Kubernetes を使用する現在のアプローチは、LLM をモノリシックなコンテナ、つまり可視性も制御性もない大規模なブラックボックスとしてデプロイするというものでした。これでは、プロンプト構造、トークン数、応答レイテンシーの目標 (サービスレベル目標または SLO)、キャッシュの可用性、その他多くの要素が無視されるほか、効果的なスケーリングが困難になります。
つまり、現在の推論システムは効率が悪く、必要以上のコンピューティング・リソースを使用しているのです。
llm-d は推論の効率とコスト効率を向上させる
vLLM はさまざまなハードウェアで広範なモデルをサポートしますが、llm-d はさらに一歩先を進みます。既存のエンタープライズ IT インフラストラクチャ上に構築される llm-d は、高度な分散型の推論機能を提供し、リソースの節約とパフォーマンスの向上に役立ちます。たとえば、最初のトークンまでの時間が 3 倍向上したり、レイテンシー (SLO) の制約下におけるスループットが倍増したりします。llm-d は強力なイノベーション・スイートを提供しますが、その主な焦点は、推論の向上に役立つ次の 2 つのイノベーションにあります。
- ディスアグリゲーション:プロセスを分離することで、推論時にハードウェア・アクセラレーターをより効率的に使用できます。具体的には、プロンプト処理 (プリフィルフェーズ) とトークンの生成 (デコードフェーズ) を Pod と呼ばれる個別のワークロードに分離します。フェーズごとに計算需要が異なるため、このように分離することで、それぞれのフェーズで独立したスケーリングと最適化が可能になります。
- インテリジェントなスケジューリング・レイヤー:これにより Kubernetes Gateway API が拡張され、受信要求に対してより詳細なルーティングが可能になります。これは、KV キャッシュ使用率や Pod 負荷などのリアルタイムデータを活用することで、リクエストを最適なインスタンスに送り、キャッシュヒットを最大化しつつクラスタ全体のワークロードをバランス良く分散させます。

再計算を防ぐためにリクエスト全体で KV ペアをキャッシングするなどの機能に加えて、llm-d は LLM 推論をモジュール式のインテリジェントなサービスに分割し、スケーラブルなパフォーマンスを実現します (vLLM 自体が提供する広範なサポートをベースとします)。これらの各テクノロジーについてもう少し詳しく説明しましょう。llm-d でそれらのテクノロジーがどのように使用されるかについて、いくつかの実例で見ていきます。
ディスアグリゲーションによって低レイテンシーとスループットがどのように向上するか
LLM 推論のプリフィルフェーズとデコードフェーズには根本的な違いがあり、それによって均一なリソース割り当てに課題がもたらされます。入力プロンプトを処理するプリフィルフェーズは通常、計算量が非常に多く、初期の KV キャッシュエントリーを作成するために高い処理能力を必要とします。反対に、トークンが 1 つずつ生成されるデコード フェーズでは、主に、比較的少ない計算量で KV キャッシュからの読み取りと書き込みを行うため、メモリー帯域幅に制限されることがよくあります。
llm-d では、ディスアグリゲーションを実装することで、これら 2 つの異なる計算プロファイルを個別の Kubernetes Pod で提供できます。つまり、処理負荷の高いタスク用に最適化されたリソースでプリフィルの Pod をプロビジョニングし、メモリー帯域幅の効率に合わせた構成で Pod をデコードできます。
LLM 対応の推論ゲートウェイの仕組み
llm-d によるパフォーマンス向上は、主に推論リクエストを処理する場所と方法を調整するインテリジェントなスケジューリング・ルーターによって可能になります。推論リクエストが llm-d ゲートウェイ (kgateway がベース) に到達すると、そのリクエストは単純に次の利用可能な Pod に転送されることはありません。その代わりに、llm-d スケジューラーのコアコンポーネントであるエンドポイントピッカー (EPP) が、複数のリアルタイムの要因を評価して最適な宛先を決定します。
- KV キャッシュ対応:スケジューラーは、実行中のすべての vLLM レプリカにおいて、KV キャッシュステータスのインデックスを維持します。新しいリクエストが、特定の Pod 上のすでにキャッシュされたセッションと共通のプレフィックスを共有している場合、スケジューラーはその Pod へのルーティングを優先します。これにより、キャッシュのヒット率が大幅に向上し、冗長なプリフィル計算が回避され、それが直接レイテンシーの短縮に貢献します。
- 負荷認識:リクエストの単純なカウント以外にも、スケジューラーは各 vLLM Pod の実際の負荷を評価し、GPU メモリー使用率と処理キューを考慮してボトルネックの回避に貢献します。
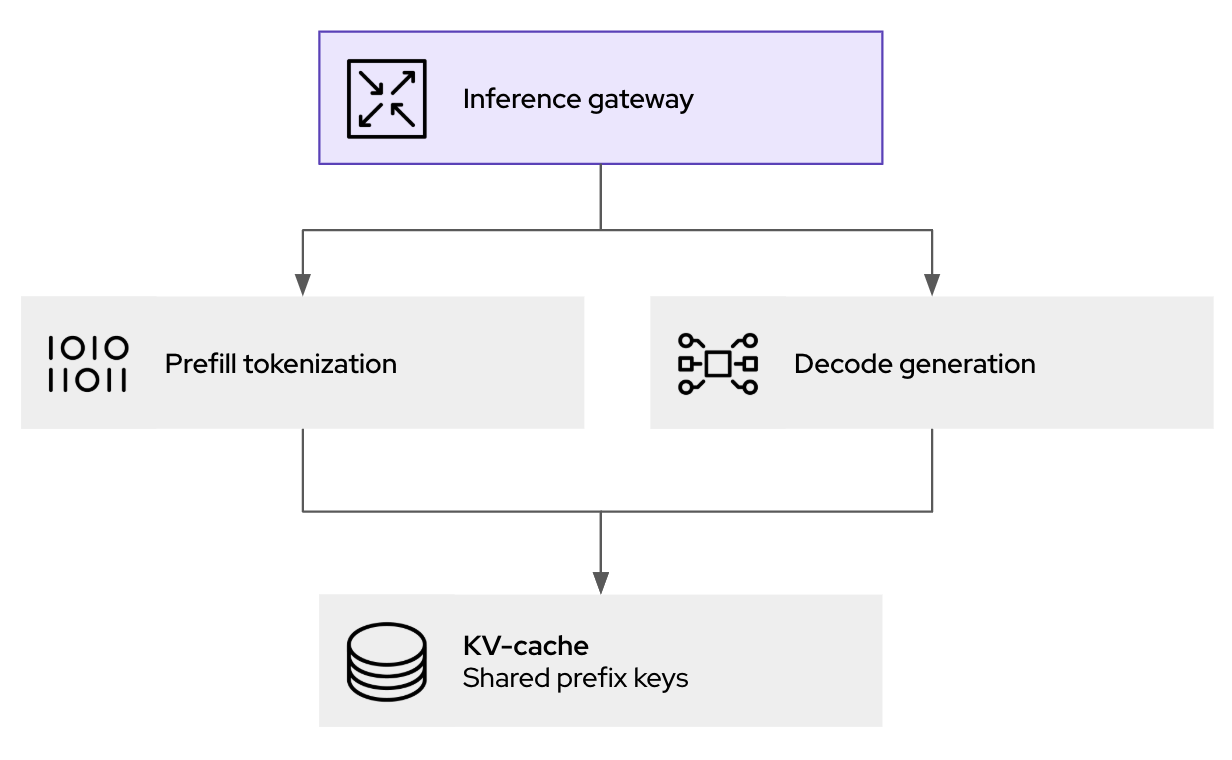
Kubernetes ネイティブのアプローチは、生成 AI 推論のためのポリシー、セキュリティ、可観測性レイヤーを提供します。これはトラフィックの処理に役立つだけでなく、プロンプトのロギングと監査 (ガバナンスとコンプライアンス向け) が可能になり、推論に転送する前のガードレールとしても機能します。
llm-d を使い始める
llm-d プロジェクトには多くのエネルギーが秘められています。vLLM は単一サーバーのセットアップに最適ですが、llm-d はクラスタを管理する Operator 向けに構築されており、パフォーマンスとコスト効率に優れた AI 推論を目的としています。実際に試されたい場合は、GitHub の llm-d リポジトリをチェックアウトし、Slack での会話に参加してください。ぜひ、質問をしたり、プロジェクトに参加したりするためにご活用ください。
AI の未来は、オープンでコラボレーティブな原則に基づいて構築されます。Red Hat は、vLLM などのコミュニティや llm-d などのプロジェクトを通じて、すべての開発者にとって AI をよりアクセスしやすく、手頃な価格で、かつ強力なものにする取り組みを進めています。
リソース
エンタープライズ AI を始める:初心者向けガイド
執筆者紹介
Cedric Clyburn (@cedricclyburn), Senior Developer Advocate at Red Hat, is an enthusiastic software technologist with a background in Kubernetes, DevOps, and container tools. He has experience speaking and organizing conferences including DevNexus, WeAreDevelopers, The Linux Foundation, KCD NYC, and more. Cedric loves all things open-source, and works to make developer's lives easier! Based out of New York.
Christopher Nuland is a Principal Technical Marketing Manager for AI at Red Hat and has been with the company for over six years. Before Red Hat, he focused on machine learning and big data analytics for companies in the finance and agriculture sectors. Once coming to Red Hat, he specialized in cloud native migrations, metrics-driven transformations, and the deployment and management of modern AI platforms as a Senior Architect for Red Hat’s consulting services, working almost exclusively with Fortune 50 companies until recently moving into his current role. Christopher has spoken worldwide on AI at conferences like IBM Think, KubeCon EU/US, and Red Hat’s Summit events.
類似検索
AI の未来にはハイブリッド基盤が必要
Fragnesia およびこれに類する攻撃:ページキャッシュの脆弱性が再発し続けるケース
Technically Speaking | Defining sovereign AI with open source
Technically Speaking | Inside open source AI strategy
チャンネル別に見る

自動化
テクノロジー、チームおよび環境に関する IT 自動化の最新情報

AI (人工知能)
お客様が AI ワークロードをどこでも自由に実行することを可能にするプラットフォームについてのアップデート

オープン・ハイブリッドクラウド
ハイブリッドクラウドで柔軟に未来を築く方法をご確認ください。

セキュリティ
環境やテクノロジー全体に及ぶリスクを軽減する方法に関する最新情報

エッジコンピューティング
エッジでの運用を単純化するプラットフォームのアップデート

インフラストラクチャ
世界有数のエンタープライズ向け Linux プラットフォームの最新情報

アプリケーション
アプリケーションの最も困難な課題に対する Red Hat ソリューションの詳細
仮想化
オンプレミスまたは複数クラウドでのワークロードに対応するエンタープライズ仮想化の将来についてご覧ください