一元化されたモデル運用で AI への共有アクセスを提供
- AI エンジニアは、MaaS を使用することで API を介して高性能なモデルにすばやくアクセスできるようになります。これにより、モデルのダウンロード、依存関係の管理、時間のかかる IT チケットによる GPU 割り当てリクエストが不要になります。
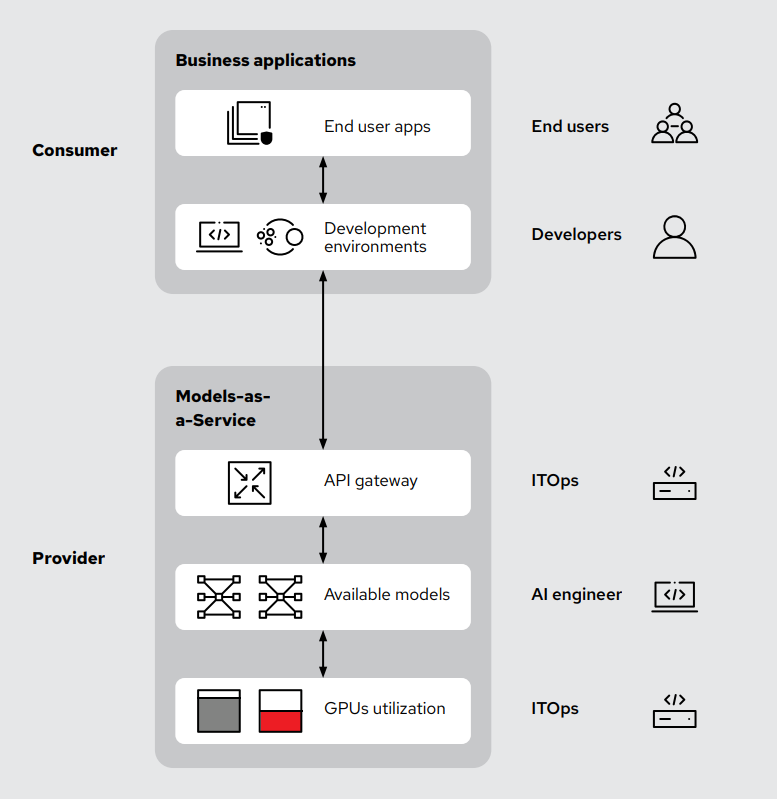
MaaS では、AI 運用チームが共有 AI リソースの一元化されたオーナーとなります。モデルは、スケーラブルなプラットフォーム (Red Hat® OpenShift® AI やその他の類似のプラットフォームなど) にデプロイされ、API ゲートウェイを介して公開されます。この設定により、複数のユーザー、開発者、事業部門がエンドユーザーに単純化されたアクセスを提供でき、IT チームと財務チームのセキュリティおよびガバナンスの優先事項に対応できます。この優先事項には、チャージバック機能や、ハードウェアへの直接アクセスや深い技術的専門知識を必要とせずにモデルを利用できることなどが含まれます。目標とするのは、GPU やテンソル・プロセッシング・ユニット (TPU) などのモデル実行に必要なリソースではなく、AI モデルに簡単にアクセスできるようにすることです。このすべてを、エンタープライズ・パフォーマンスとコンプライアンスの要件を満たしながら、エンドユーザーのアクセスを複雑にすることなく実現します。
実際には、ユーザーはモデルが生成した応答を提供する API とのみやり取りします。パブリック AI プロバイダーがハードウェアの複雑性を抽象化するのと同様に、MaaS の社内デプロイもエンドユーザーにシンプルさを提供します。ユーザーは、ハードウェアやソフトウェア・インフラストラクチャを直接管理することはなく、IT チケットが解決されるのを待ったり環境が構成されるのを待ったりすることもありません。IT 運用チームと AI チームは、モデルのライフサイクル、セキュリティ、更新、インフラストラクチャのスケーリングを一元的に管理し、最適化されながらも制御されたアクセスをユーザーに提供できます。
この一元化により、社内の AI 運用が効率化されるだけでなく、セキュリティ重視とガバナンスも強化されます。AI モデルへのアクセスは、API ゲートウェイを介した認証情報管理により厳密に制御されます。組織は容易に使用量を追跡し、社内のチャージバック・メカニズムを設定し、プライバシーのコンプライアンス・ガイドラインに準拠していることを確認し、明確な運用上の境界を確立できます。これにより、エンタープライズ AI は実用的で管理しやすいものになります。使用量の追跡は、トークンレベル (入力と出力) で行うのが最も正確で粒度の小さい方法で、GPU レベルのメトリクスよりもはるかに正確です。
使用量の制御、アクセスのスロットリング、コストの管理
- IT エンジニアやプラットフォームエンジニアは一元的な監視によるメリットを得られます。これにより、モデルの不正デプロイの防止、セキュリティおよびコンプライアンス標準の適用、ライフサイクルおよびインフラストラクチャ管理の単純化が実現します。
- 財務チームについては、一元化された使用量の追跡と社内チャージバック・メカニズムによって無駄が減り、GPU の使用の予測可能性と説明責任が向上します。これにより、使用率の低い、チームごとのハードウェア割り当てによる過剰な支出を回避できます。
MaaS における制御は、主に API ゲートウェイを AI インフラストラクチャに統合することで実現します。これにより、チームは AI の使用を粒度が極めて小さいレベルで管理および監視できます。
従来の AI のデプロイでは、管理されていない方法や非効率的な方法で使用されることが多く、それが課題となります。一元的に監視されることなく個人やチームが個別にモデルをデプロイするからです。このような断片化したアプローチでは、GPU リソースがアイドリング状態となったり、十分に活用されなかったりするため、コストがかかり非効率的になる可能性があります。API ゲートウェイを AI インフラストラクチャの中心に据えると、ユーザーとモデル間に制御されたアクセスポイントが生まれます。
この設定により、個々のトークンレベルまで、使用状況の正確な追跡が容易になります。チームは、各ユーザー、チーム、またはアプリケーションが消費する量を明確に特定し、GPU とインフラストラクチャのコストを正確に特定できます。たとえば、組織は特定のユーザーまたはアプリケーションがリソースを過剰に使用しているかどうかを判断して、使用量をスロットリングしたり社内のチャージバック・メカニズムを通じてコストを割り当てたりするなど、修正措置を講じることができます。
API ゲートウェイによるスロットリング機能は、一貫したパフォーマンスを確保してリソースの枯渇を防ぎます。スロットリングを使用すると、IT チームはアクセスの負荷を管理できます。これにより、1 人のユーザーが GPU リソースを独占したり、他のユーザーのパフォーマンスが低下したりするのを防ぐことができます。
さらに、API ゲートウェイによって認証情報のきめ細かい管理とアクセス制御が可能になります。社内ユーザーは認証情報を生成して個別に AI モデルにアクセスできるため、管理オーバーヘッドを最適化できます。また、セキュリティ要件や使用パターンの変化に対応して、認証情報の取り消しや修正を短時間で行うことができます。
これらはすべて、コスト管理の透明性と説明責任の向上につながります。IT チームは、GPU とインフラストラクチャの費用を、それらを使用するチームや事業部門に正確に割り当てることができます。
あらゆるモデル、アクセラレーター、クラウドをサポート
MaaS アプローチの中心的な原則は、制御性です。組織は幅広い AI モデルから選択してデプロイし、好みのハードウェア・アクセラレーターを選択し、既存のクラウド環境やオンプレミス環境内で運用することができます。このアプローチにより、組織は技術的なニーズ、セキュリティ要件、運用上の好みに応じて AI を自由に実装することができます。
- AI を導入する際、組織は厳しい制限に直面します。主な制限は次のようなものです。
- 特定のクラウドサービスに制限される
- プロプライエタリーなモデルのエコシステムに縛られる
- 固定されたハードウェア・インフラストラクチャの制約を受ける
- MaaS は、次のようなさまざまな方法でこれらの制限に対処します。
- オープンソースまたはプロプライエタリーなモデル、カスタムのトレーニングが実行されたモデル、一般的な LLM (Llama や Mistral など) のサポート
- テキストベースのモデルにとどまらず、予測分析、コンピュータビジョン、音声テキスト変換ツール、画像や動画生成などのマルチモーダル生成 AI のユースケースへの拡張
- MaaS はハードウェア・アクセラレーターに依存しないため、次のことが可能です。
- ワークロード、コスト構造、パフォーマンスのニーズに合わせて、GPU やその他のアクセラレーターを選択できる
- 一元化された AI チームでサイジングやデプロイに関する重要な意思決定を行うことができるため、効率が向上し、技術知識の乏しいユーザーによるエラーが減少する
- 一元管理により、次のことが可能になります。
- インフラストラクチャの最適な割り当てと使用
- 運用オーバーヘッドの削減とリソースの構成ミスの防止
- MaaS は、次のようなあらゆる環境でのデプロイをサポートします。
- オンプレミス、ハイブリッドクラウド、エアギャップ環境、パブリッククラウド。データ主権、法令順守、厳格なセキュリティ制御を必要とする、規制の厳しい業界では特に有益です。