An architecture is wishful thinking until we understand how information is transferred across systems. That means whether you are an application architect or an enterprise architect, it's essential that you understand the tradeoffs at hand when considering a particular method for moving information between systems. Thankfully, the process of transforming data from one schema to another has always been a part of IT architecture, known as data exchange.
[ A free guide from Red Hat: The automation architect's handbook. ]
This article looks at the history of data exchange and how SOAP, REST, GraphQL, and gRPC APIs compare to each other.
Understanding APIs as data exchange
Data exchange has been a critical aspect of enterprise architecture since the dawn of digital computing. Take a moment to review the concept of data exchange if you're not already familiar with it.
While it's true that a lot of data exchange went on within the internals of a company's mainframe, at some point, that information had to be shared with another computer. Early forms for data exchange were physical. Operators downloaded data onto reels of magnetic tape. These tapes were then transported from one facility to another one miles away. (Transporting computer tapes to and fro was a job I had in graduate school.) As network communication became standardized, information was exchanged digitally over phone lines and network wires using general-purpose protocols such as Telnet, SMTP, FTP, and HTTP.
Yet, while the means of data exchange was standardizing, the actual data coming in over the wire was a lot less uniform. There were no generally accepted data formats. Every company and technology had its own way of structuring data.
But, as they say, necessity is the mother of invention. The industry needed to standardize—so it did. Today, there are several conventional data formats on the landscape. Early on, we started with XML, which is still used. However, for the most part, text-based JSON and a few binary formats such as Protocol Buffers and Thrift have become the lingua franca of data exchange.
This standardization of data formats has led to the proliferation of an architectural design that positions APIs as the linchpin in application architecture. Today's trend is to have clients interacting with an API layer representing the application on the server-side.
The benefit of taking an API-based approach to application architecture design is that it allows a wide variety of physical client devices and application types to interact with the given application. One API can be used not only for PC-based computing but also for cellphones and IoT devices. Communication is not limited to interactions between humans and applications. With the rise of machine learning and artificial intelligence, service-to-service interaction facilitated by APIs will emerge as the Internet's principal activity.
[ Download An architect's guide to multicloud infrastructure. ]
APIs bring a new dimension to architectural design. However, while network communication and data structures have become more conventional over time, there is still variety among API formats. There is no "one ring to rule them all." Instead, there are many API formats, with the most popular being SOAP, REST, GraphQL, and gRPC. Thus a reasonable question to ask is, as an Enterprise Architect, how do I pick the best API format to meet the need at hand? The answer is that it's a matter of understanding the benefits and limitations of the given format. The purpose of this article is to highlight the benefits and tradeoffs of the most popular API formats: SOAP, REST, GraphQL, and gRPC. The sections that follow are a discussion of the details.
SOAP
Simple Object Access Protocol (SOAP) is a protocol for exchanging information encoded in Extensible Markup Language (XML) between a client and a procedure or service that resides on the Internet. The specification was made public in 1999 and is published by the W3C as an open standard.
SOAP can be used by a variety of transport protocols in addition to HTTP, for example, FTP and SMTP. (A conventional pattern is to use HTTP for synchronous data exchange and SMTP or FTP for asynchronous interactions).
In order to support consistency when structuring data, SOAP uses a standard XML schema (XSL) to encode XML. In addition, developers can create their own XML schemas to add custom XML elements to SOAP messages.
SOAP is typically used with the Web Service Description Language (WSDL). The significance of using WSDL is that developers and machines can inspect a web service that supports SOAP to discover the specifics of the information exchange over the network. In addition, the WSDL describes how to structure the SOAP request and response messages that the given service supports. Discovery via WSDL simplifies programming web services using SOAP.
The structure of a SOAP message
A SOAP message is a hierarchical structure in which the root element is the <soap:Envelope>. The root element can have three child elements. These child elements are <soap:Header>, <soap:Body> and <soap:Fault>.
The element <soap:Body> is required. The elements <soap:Header> and <soap:Fault> are optional. When the optional element, <soap:Header> is used, it must be the first child element within the parent element, <soap:Envelope> and when the optional element <soap:Fault> is used, it must be a child of the element, <soap:Body>.
As mentioned previously, the element <soap:Envelope> is the root element for the entire SOAP message. The element <soap:Header> provides header information relevant to the message. The element <soap:Body> describes the payload of the message. The element <soap:Fault> contains error information that’s occurred during the transmission and consumption of the message. Listing 0 below shows an example of a SOAP message, including the definition of the HTTP POST request that sends the message to the target destination.
1| POST /BobsTickers HTTP/1.1
2| Host: www.example.org
3| Content-Type: application/soap+xml; charset=utf-8
4| Content-Length: 275
5| SOAPAction: "http://cooltickers.org/soap"
6|
7| <?xml version="1.0"?>
8|<soap:Envelope xmlns:soap="http://www.w3.org/2003/05/soap-envelope" xmlns:m="http://www.exampletickers.org">
9| <soap:Header>
10| </soap:Header>
11| <soap:Body>
12| <m:GetStockPriceRequest>
13| <m:StockName>IBM</m:StockName>
14| </m:GetStockPriceRequest>
15| </soap:Body>
16|</soap:Envelope>
Listing 0: An example of a SOAP message.
Let’s do an analysis of the message shown above in Listing 0.
Lines 1 to 5 describe the header information of the originating POST request.
- Line 1 declares the HTTP method, access endpoint for the message once it arrives at the webserver, and the transport protocol, in this case HTTP/1.1.
- Line 2 declares the DNS name of the target destination.
- Line 3 declares that the Content-Type of the request contains XML that is encoded according to the SOAP specification.
- Line 4 is the length of the request body.
- Line 5 contains a name-value pair describing SOAPAction, which we'll discuss later in the section, Specifying Behavior in SOAP.
Lines 1 - 4 are typical in an HTTP header. Things get SOAP specific starting at line 8, which defines the XML root element, Envelope, that contains the entirety of the SOAP message.
Notice that at Line 9 an XML namespace named m is declared. In this case, the namespace variable is bound to a fictitious URL that is supposed to contain the element definitions defined by the namespace URL. The namespace m declares the fictitious elements, GetStockPriceRequest and StockName, that are used at lines 13 and 14, respectively. The code in Listing 0 is telling the host that the SOAP message is a request for a stock price for the ticker symbol, IBM.
Given the information provided in the SOAP message, a reasonable question to ask is, How does the host receiving the SOAP message make sense of it all? To answer this question, we need to go back to the HTTP header attribute SOAPAction, shown above in Listing 0 at Line 5.
[ Download now: Enterprise automation DevOps checklist. ]
Specifying behavior in SOAP
SOAPAction is an HTTP header attribute that tells the host that the incoming request is a SOAP message. Also, the URL associated with the SOAPAction attribute provides a reference that describes general information about the message. Many times, web services that support SOAP will route the request to a service's internals based on the information referenced in the SOAPAction header. As far as the particular behavior to execute as described in a SOAP message, that’s up to the host receiving the message. In the case of the example shown above in Listing 0, the assumption in play is that the intelligence at the endpoint, BobsTickers know how to parse the incoming SOAP message, and when it comes across the element, <m:GetStockPriceRequest>, it will know how to do a lookup for the symbol described in the element, <m:StockName> and thus, act accordingly. While SOAP is a powerful API format, it is not magical. The actual behavior associated with a SOAP message is particular to the host receiving the information. Thus, those creating the SOAP message need to make sure that all the information required to execute the behavior desired is provided.
REST
REST is an acronym for Representational State Transfer. REST is an architectural style devised by Roy Fielding in his 2000 Ph.D. thesis. The basic premise is that developers use the standard HTTP methods, GET, POST, PUT and DELETE, to query and mutate resources represented by URIs on the Internet. (See Figure 1, below)
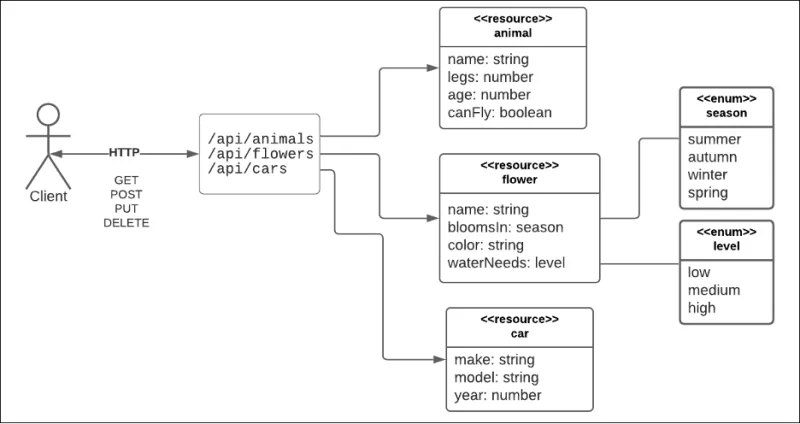
You can think of a resource as a very big dataset that describes a collection of entities of the type, for example, animals, flowers, and cars. REST is neutral in terms of the format used to structure the response data from a resource. Using text-based data formats has become the convention. JSON is the most popular data format, although you can use others, such as XML, CSV, and even RSS.
HTTP/1.1 is the protocol used for a REST data exchange. Thus, the stateless request-response mechanism is intrinsic to the style. Also, the REST specification supports the concept of Hypermedia as the Engine of Application State (HATEOAS). Operationally, this means that a REST response can contain links that describe operations or followup workflow steps relevant to the given resource. (See Listing 1, below.)
{
"car": {
"vin": "KNDJT2A23A7703818",
"make": "kia",
"model": "soul",
"year": 2010,
"links": {
"service": "/cars/KNDJT2A23A7703818/service",
"sell": "/cars/KNDJT2A23A7703818/sell",
"clean": "/cars/KNDJT2A23A7703818/sell"
}
}
}Listing 1: REST uses HATEOAS to define operations and workflow tasks that are relevant to a resource
REST is a self-describing format. This means that you can figure out the fields and values in the response just by looking at the response results. For example, in Listing 1, above, you can figure out the VIN value in the response because there is actually a property named "VIN." You don't need any external dictionary to determine the meaning and position of properties. Self-description is a useful feature, and one that is also shared by GraphQL, which we'll look at next.
GraphQL
GraphQL is a technology that came out of Facebook but is now open-source. GraphQL is a specification. Because GraphQL is a specification, it is inherently language neutral. There are many implementations of the specification in a variety of programming languages. There are implementations in Go, .NET/C#, Node.js, and Python, to name a few.
The underlying mechanism for executing queries and mutations is the HTTP POST verb. This means that a GraphQL client written in Go can communicate with a GraphQL server written in Node.JS. Or, you can execute a query or mutation from the curl command.
There are a few things that make GraphQL special. First, as the name implies, GraphQL is intended to represent data in a graph. Instead of the columns and rows found in a relational database or the collection of structured documents found in a document-centric database such as MongoDB, a graph database is a collection of nodes and edges. You can think of a graph database as a vast array of objects (nodes) related in a distinct way (edges). For example, the objects Fido (node) and Kitty (node) are related to the object Bob (node) as his pets (edge). GraphQL is very good at capturing this complexity.
A graph is defined according to a schema language that is particular to GraphQL. Developers use the schema language to define the types as well as the query and mutation operations that will be published by the GraphQL API. (Go here to view an example of a simple GraphQL schema.)
Once types, queries, and mutations are defined in the schema, the developer implements the schema using the language framework of choice.
Want to view a fully functional GraphQL demonstration API?
If you want to view a completely functional GraphQL API, look at the IMBOB demonstration project on GitHub. You can see it here. The project is programmed in Node.js and demonstrates all the major features of GraphQL.
The second thing that makes GraphQL special is that it's very flexible in defining the structure of the data that's returned when making a query against the API. Unlike REST, in which the caller has no control over the structure of the returned dataset, GraphQL allows you to define the structure of the returned data explicitly in the query itself. For example, take a look at Listing 2 below. It's a query in the GraphQL query language asking for information about venues. (The GraphQL query language is similar to, but not exactly like JSON.) Notice that the GraphQL statement defines three fields -- name, city, and state_province -- that are to be returned from the venue's graph.

The GraphQL statement shown in Listing 3 is querying venues for only two fields: name and postal_code.

Were you to query the venue's resource under REST, you would get back every field associated with that resource. Under GraphQL, you have a lot of flexibility in terms of defining the result data. This is a significant benefit for frontend developers. Being able to define only the data you want, as you want it, saves the labor, memory, and CPU consumption that goes with parsing and filtering out useless data from enormous result sets.
The third feature that GraphQL offers that makes it special is Subscriptions. (See Figure 2, below.) Subscriptions open the door to asynchronous messaging.

Query and mutation data exchange under GraphQL is synchronous due to the request-response pattern inherent in the HTTP/1.1 protocol. However, GraphQL allows users to receive messages asynchronously when a specific event is raised on the server-side. Let's take a look at a use case.
Imagine that you have a GraphQL API that allows customers to buy seats to a concert at a particular venue. The workflow logic is that the customer will inspect the seats in the venue to determine which one(s) to buy. The customer clicks the seats of interest in the application's UI and then purchases the tickets. However, there is a problem. There can be a significant amount of time between selecting the seat and actually paying for it. The customer has to get his or her credit card and submit the information in the UI. Then, there is the work to be done on the backend, making sure the credit card number is valid and can make the purchase. In some cases, this transaction can take a minute or two. Unless the seat is put on "hold," another customer can come along and attempt to purchase that seat, too. Clearly, a race condition exists.
This is a problem in which a GraphQL Subscription is a useful solution. A developer can make it so that once a payment submission is received on the server, a "seat reserved" message is emitted on the backend before the payment transaction starts. (See Figure 2, above.) The internals of the GraphQL API implementation respond to the event by asynchronously forwarding the "seat reserved" message back to all clients using the API. All the clients using the ticketing site receive the "seat reserved" message and mark the particular seat(s) unavailable. Should the purchase transaction succeed, a "seat bought" message is sent out to all client UIs. If the transaction fails, a "seat open" message is sent to all client UIs and their UI code will show the seat(s) as once again available for purchase.
The caveat is that all client UIs need to register with the GraphQL API for each subscription of interest. But, this is a client-side programming task that's easy to implement.
Want to know more about GraphQL?
Read an in-depth examination of GraphQL here.
The GraphQL hybrid model provides a great deal of flexibility. Combining synchronous and asynchronous capabilities into a single API adds a new dimension to backend capabilities. GraphQL is powerful, but it's not perfect. Synchronous and asynchronous activities are distinct. In fact, when you look under the covers, you'll see that there are actually two servers in play in a typical GraphQL API. There's the synchronous HTTP server and also an asynchronous subscription server. Is the separation a showstopper? Not really. But there is another technology that combines both synchronicity and asynchronicity seamlessly into a programming framework. That technology is gRPC.
gRPC
gRPC is a data exchange technology developed by Google and then later made open-source. Like GraphQL, it's a specification that's implemented in a variety of languages. Unlike REST and GraphQL, which use text-based data formats, gRPC uses the Protocol Buffers binary format. Using Protocol Buffers requires that both the client and server in a gRPC data exchange have access to the same schema definition. By convention, a Protocol Buffers definition is defined in a .proto file. (See Figure 3, below.)
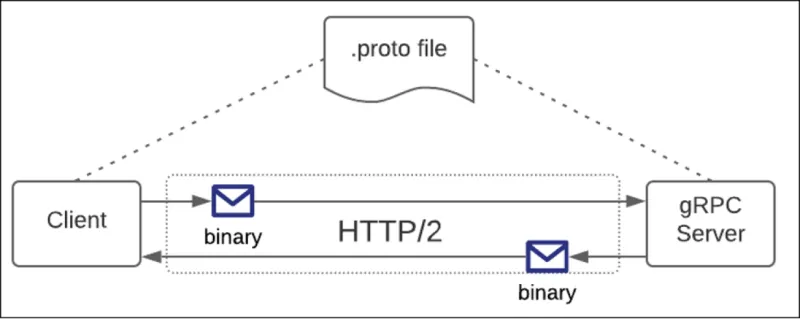
The .proto file provides the "dictionary" by which data is encoded and decoded to and from the Protocol Buffers binary format. (You can view an example of a simple .proto file on as Gist on GitHub here.)
The benefit of using a binary format as the means of data exchange is that it increases performance. Unlike REST and GraphQL, which use text-based data formats that tend to be bulky, data encoded in binary format is compact. It's the difference between a mail carrier delivering a one-ounce letter and a four-pound package.
In addition to using Protocol Buffers to encode data and thus increase performance, gRPC has another benefit. It supports bidirectional, asynchronous data exchange. This is because gRPC is based on the HTTP/2 protocol.
Unlike HTTP/1.1, which supports only a request-response interaction over a single connection, HTTP/2 supports any number of requests and responses over a single connection. Connections can also be bidirectional. In other words, under HTTP/2, a client opens a connection to a target server, and that connection stays open until either the client or server closes it. This means that not only does gRPC allow requests and responses to move through the connection, but data streams as well. The steam can emanate from the client or from the server.
Take a look at Listing 4 below. It is an excerpt from an example gRPC schema that you can view here. The excerpt shows multiple messages: CarResponse (line 7) that has a field, car which is an array of Car messages, as indicated by the gRPC reserved word, repeated. There is the message AnimalResponse (line 2), which describes a response message that contains an Animal message. (The Animal and Car messages are described fully in the Gist document here.) The excerpt shows the operations supported by the particular gRPC API under services on line 12.
Notice that the return type of the method GetAnimals is (stream Animals). This means that when a client calls that gRPC method, the data will be returned as a continuous stream of Animal messages over a single, open connection.

Now, take a look at the method, GetCars() at line 19 above in Listing 4. Notice that the return type is CarResponse. CarResponse contains a single field, car, that is an array of Car messages. This is an important distinction from the GetAnimals() response. Let me explain why.
When GetCars() is called, the backend code will create an array and then add cars to it. That populated array will be assigned to the car field of the CarResponse message. The CarResponse message will be returned to the caller. In other words, all the work of creating the array, finding the cars, and adding them to the array is done before the response is executed.
On the other hand, when GetAnimals() is called, the backend code will construct an AnimalResponse message for each animal discovered and return each message over a stream that flows through the HTTP/2 connection. If 1000 animals are found, then each animal will be returned, one at a time, through the steam. The caller does not need to wait for all the Animals to be aggregated into a single array. Instead, each is sent back to the caller as it's available.
Returning data in streams is particularly beneficial when you're working with time-sensitive data, such as stock exchange activity. Also remember, streaming is bidirectional. This means that a client can keep sending data to the server in a continuous stream. As that data is processed, it's returned in a stream to the client. Executing this scenario under HTTP/1.1 would require opening and closing 1000 connections between client and server. The efficiency is apparent.
Which API format is for you?
All the API formats described above have benefits and challenges. Let's examine those we've covered.
SOAP
SOAP has many benefits. It can be implemented using a variety of protocols, not only HTTP but SMTP and FTP as well. SOAP supports discovery via WSDL and it's language neutral. Being able to use SOAP in an assortment of programming languages has particular benefit to large companies that have applications created in different programming languages yet to have to support communication between these disparate programs in a standard manner.
SOAP has been around for a while. There is still a good deal of legacy SOAP implementations that need to be maintained. Thus, for those who know SOAP, there will continue to be employment opportunities maintaining a codebase that uses the protocol. But SOAP also has its disadvantages. SOAP can be considered a complex message format with a lot of ins and outs to the specification. Also, the verbose nature of XML which is the format upon which SOAP is based, coupled with the reliance on external namespaces to extend the basic message format makes the protocol bulky and at times difficult to manage. SOAP messages can get quite large. Moving bulky, text based, SOAP messages between source and target takes a long time in comparison to binary messaging protocols such as gRPC and Thrift. When the efficiency of messaging protocols is measured in milliseconds sadly, most times SOAP messages won’t pass muster.
Finally, SOAP is a legacy protocol. While there’s a lot of maintenance work to be done with those systems that use it, new architectures are taking a more modern approach to inter-service communication. Nonetheless, SOAP was a real breakthrough when it first appeared. It provided a standard way to do structured messaging. It supported discovery and in the scheme of things, it was relatively easy protocol for developers to use.
SOAP’s contribution to communication across domains and services is not to be underestimated. It’s the starting point for a good many of the information exchange technologies we have today. SOAP made IT better.
REST
REST is simple, well-known, and widely used. You make a call on a resource represented by a URL on the Internet using an HTTP verb and get a response back in JSON or XML. Productivity under REST is almost immediate.
However, REST does have challenges. It's clunky and immutable in terms of the data structure of a response. Also, given the response/response aspect of HTTP/1.1, REST can be slow.
GraphQL
GraphQL is flexible and growing in popularity. The latest version of GitHub's API is published using GraphQL. Yelp publishes its API in GraphQL, as does Shopify. These examples are but a few of many. The list continues to grow.
The fundamental challenge that goes with GraphQL is that it's a way of life. The GraphQL specification covers every aspect of API implementation, from Scalars, Types, Interfaces, Unions, Directives, the list goes on. While the specification allows for customization, the basic framework cannot be avoided. You have to do things according to the GraphQL way. REST, on the other hand, has a limited rule set to follow. It's the difference between making a skateboard and making an automobile. No matter what, you need four wheels as well as a way to start and stop, but a skateboard (REST) is far easier to make and operate than an automobile (GraphQL). However, once GraphQL is implemented, users find it a better developer experience than REST. It's a question of tradeoffs and making sure the benefits of use outweigh the cost of implementation.
gRPC
gRPC is exact and wicked fast. According to many, it's become a de facto standard for inter-service data exchange on the backend. Also, the bidirectional streaming capabilities that are provided by HTTP/2 allow gRPC to be used in situations where REST or GraphQL can't even be considered.
There are a few challenges that go with using gRPC. The first is that both client and server need to support the same Protocol Buffers specification. This is a significant undertaking in terms of version control. Under REST or GraphQL, one can add a new attribute(s) to a resource (REST) or type (GraphQL) without running much risk of breaking the existing code. However, making such additions in gRPC can have a detrimental impact. Thus, updates to the .proto file need to be carefully coordinated.
Another challenge is that HTTP/2 does not have universal support for public-facing client-server interactions on the Internet. As of this writing, only 48.2% of the websites on the Internet support HTTP/2. Thus, gRPC is best suited to situations where developers control both client and server data exchange activities. Typically such boundaries exist on the backend. Hence, the prominence of gRPC as a backend technology.
The third challenge that comes with using gRPC is that it takes time to attain mastery. Some time can be saved by using the protoc tool. protoc will auto-generate gRPC client and server code according to a particular programming language based on a specific .proto file. It's useful for creating boilerplate code, but doing more complex programming requires a lot more work.
Finally, there is the challenge that goes with using the Protocol Buffers binary data format. The benefit of Protocol Buffers is that it allows data to move fast. However, companies that use gRPC can become spoiled by the gratification that gRPC brings concerning satisfying their need for speed. They tend to keep wanting more efficiency. One technique that developers use to save processing time is to avoid deserializing the binary data altogether. Instead, they work with Protocol Buffers directly at the bit level.
The Protocol Buffers specification allows discoverability of a field's position and the type of data associated with that field within a binary message. Thus, to eke out as much speed as possible, developers will go right into the bits of the binary message and pull out only the data of interest. It's not a universal practice, but it's not a rarity either. This sort of programming is very exact and can be very brittle should the .proto file change. If the order of the fields in a message is altered, any code parsing a binary message at the bit level will break.
In short, gRPC is a very particular API format that provides lightning-fast execution at the expense of flexibility. Yet, if you have an application in which nanoseconds count, gRPC includes speed that is hard to match when using REST or GraphQL.
Putting it all together
Choosing the right API format for an enterprise architecture is a big decision. The choice will determine how the architecture works and the talent and budget that will be needed to implement and maintain the application through its lifetime.
For a company that is risk-averse and wants to use a proven format, REST is probably best-suited to meet the need at hand. If a company needs to provide maximum flexibility to frontend developers to support both synchronous and asynchronous interactions between client and server, GraphQL is a good bet. Should the architecture require a fast data exchange that can take place in one-way or two-way streams between client and server over a single connection, gRPC is probably the way to go.
Each API format has its benefits and challenges. No one size will fit all. The trick is to put together a team of open-minded collaborators from across the company to take a thoughtful, analytic approach when considering an API format. After all, architecture is only as good as the code that realizes it. The API format chosen today will live on well after the architectural diagrams used in the decision-making process are archived away.
Editorial note: This article was updated to include SOAP on December 10, 2020.
About the author

Bob Reselman is a nationally known software developer, system architect, industry analyst, and technical writer/journalist. Over a career that spans 30 years, Bob has worked for companies such as Gateway, Cap Gemini, The Los Angeles Weekly, Edmunds.com and the Academy of Recording Arts and Sciences, to name a few. He has held roles with significant responsibility, including but not limited to, Platform Architect (Consumer) at Gateway, Principal Consultant with Cap Gemini and CTO at the international trade finance company, ItFex.
More like this
Looking ahead to 2026: Red Hat’s view across the hybrid cloud
Red Hat to acquire Chatterbox Labs: Frequently Asked Questions
Crack the Cloud_Open | Command Line Heroes
Edge computing covered and diced | Technically Speaking
Browse by channel

Automation
The latest on IT automation for tech, teams, and environments

Artificial intelligence
Updates on the platforms that free customers to run AI workloads anywhere

Open hybrid cloud
Explore how we build a more flexible future with hybrid cloud

Security
The latest on how we reduce risks across environments and technologies

Edge computing
Updates on the platforms that simplify operations at the edge

Infrastructure
The latest on the world’s leading enterprise Linux platform

Applications
Inside our solutions to the toughest application challenges
Virtualization
The future of enterprise virtualization for your workloads on-premise or across clouds