
Edge computing is definitely a thing in today's technical landscape. The market size for edge computing products and services has more than doubled since 2017. And, according to the statistics site, Statista, it's projected to explode by 2025. (See Figure 1, below)
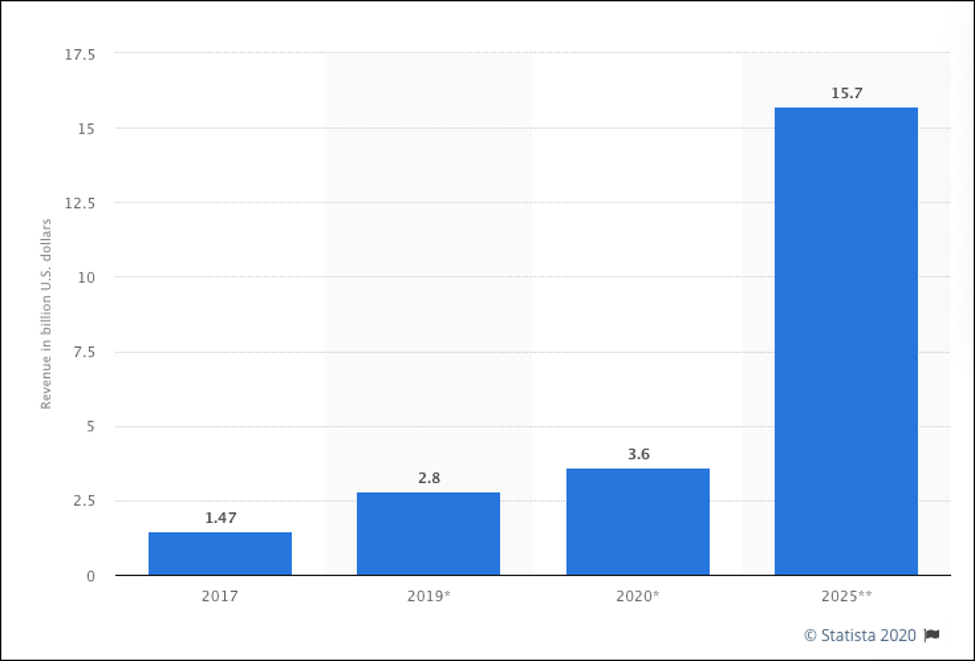
Figure 1: Edge computing market size forecast worldwide in 2017, 2019, 2020, and 2025 (in billions of USD) (Statista)
As computer technology continues to leave the desktop in favor of mobile devices and the Internet of Things, edge computing will play a greater role in enterprise architecture.
Given the evolution of technology and the growth expected in the coming years, having a basic understanding of edge computing is essential for the modern Enterprise Architect. The purpose of this article is to provide that basic understanding.
In this article, I cover four topics that are fundamental to technology. First, I will provide an introduction to the basic concepts of edge computing. Next, I'll discuss the essential value proposition for edge computing. I'll follow up by describing an emerging pattern in edge computing: The Fog vs. the edge. Finally, I'll look at how the adoption of artificial intelligence from an operational perspective has put edge computing at the forefront of modern architecture design.
I'll start by describing the basic behind the edge computing pattern.
Understanding the edge computing pattern
Edge computing is a distributed computing pattern. Computing assets on a very wide network are organized so that certain computational and storage devices that are essential to a particular task are positioned close to the physical location where a task is being executed. Computing resources relevant to the task, but not essential to it, are placed in remote locations.
In an edge computing scenario, edge devices such as a video camera or motion detector will have only the amount of computation logic and storage capacity required to do the task at hand. Usually, these edge devices will be very small systems such as Raspberry Pi or networkable appliances that have task-specific logic embedded in dedicated, onboard computers. (See Figure 2, below)

Figure 2: A grid of municipal traffic lights is an example of the edge computing pattern
The remote computers, to which the edge devices are connected, tend to be much more powerful and are provisioned to do more complex work. As such, these remote computers usually reside in a data center in the cloud.
While a lot of technology around edge computing is still evolving, the basic concept has been in play for a while in the form of Content Delivery Networks (CDN). A CDN is a network architecture in which content is pushed out to servers closest to the points of consumption, thus reducing latency and providing a high-quality experience to the consumer. (See Figure 3, below.)
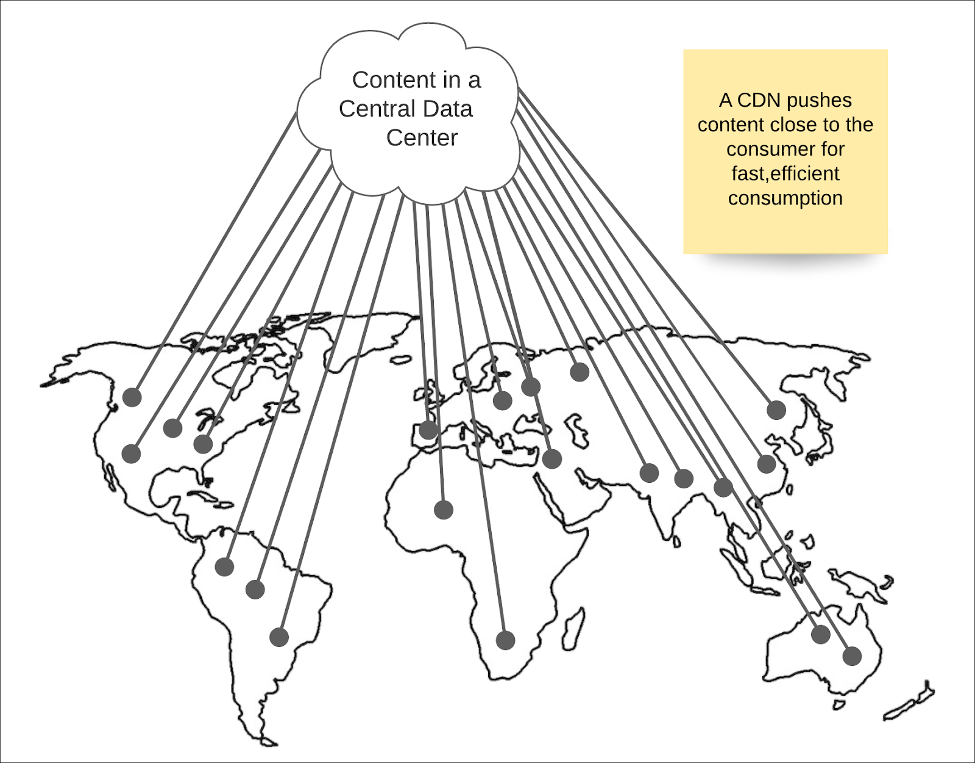
Figure 3: Content Delivery Networks are an early implementation of the edge pattern in distributed computing
For example, a company such as Netflix, which has viewers worldwide, will push content out to servers located at various locations across the globe. When a viewer logs in to Netflix and selects a film to view, the Netflix digital infrastructure's internals determine the point nearest the viewer from which to stream the movie and delivers the content accordingly. The process is hidden from the viewer. The internal mechanism that implements the content delivery network is the Open Connect system developed by Netflix.
The basic value proposition
The fundamental value proposition for edge computing is that it allows companies to provide digital services quickly in a cost-effective manner.
A physical analogy to understand the value of edge computing is to imagine the delivery operation of a fictitious national online retailer I'll call Acme Online. Acme Online is a central eCommerce system. It allows anybody in the USA to buy an item from its site and then have Acme Online deliver the purchased item anywhere in the USA. (See Figure 4, below.)
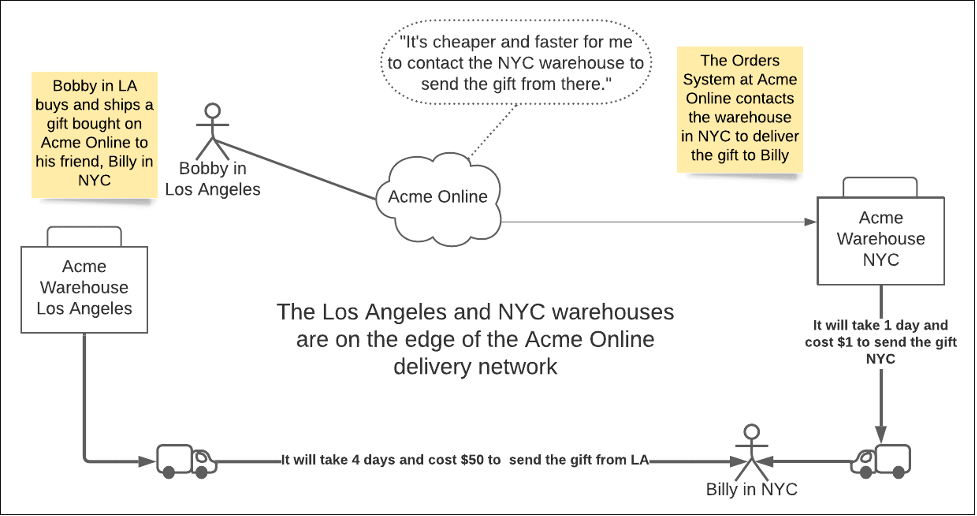
Figure 4: An online retailer is an example of edge computing in the physical world.
The scenario shown above in Figure 4 has Bobby in Los Angeles buying a gift for his friend Billy in New York City (NYC). Billy is over 3000 miles away from Bobby. Acme Online has several physical warehouses distributed nationwide. One of the warehouses is in Los Angeles. Another one is in NYC. After Bobby makes his purchase, the intelligence in the Acme Online central data center
handling purchases takes the order and analyzes it to determine the fastest, cheapest way to deliver the gift. Acme Online matches Billy's address—the gift recipient—to the nearest warehouse with the item. It turns out that the NYC warehouse has the gift item. Acme Online schedules the delivery from the NYC warehouse.
The efficiency is apparent. Executing the task of delivering the package is best performed from the distribution point nearest the recipient. The closer the delivery point is to the recipient, the less time and resources are required to do the task.
While this is an illustrative example, it might seem a bit trivial. However, there's more going on than is immediately apparent. Further analysis will reveal that there are really two types of computing entities in play in the warehouses. One type, in edge computing parlance, is called the Fog. The other type is the edge. You can think of the warehouse as the Fog and the truck that delivers the gift as the edge. Let's take a look at the difference.
The Fog vs. the edge
In the early days of edge computing, devices such as video cameras and motion detectors were directly hooked up to a central computing location, typically an in-house data center. As usage grew, however, a problem developed. The computing resources were stretched too thin. Too much data that was hard to process had to travel too far. (A video camera that records at 30 frames per second (fps), sending each frame back to a central server for storage will max out disk I/O and slow the network down in no time at all.)
Also, there is the problem of configuration. When a thousand video cameras send data to a central location at a specific IP address—which is not unusual for a municipal traffic system—just reconfiguring the IP address to another device is an arduous task. Clearly, something easier is needed. The easier thing is the Fog.
The Fog is a layer of computing that sits between the central cloud and the edge devices. Going back to the Acme Online analogy described above, the Acme Online architecture puts regional warehouses between the central cloud and the trucks delivering its goods. As mentioned above, the warehouses are the Fog, and the trucks are the edge. Logic is segmented accordingly. A truck has only the intelligence required to interact with the warehouse and do actual package delivery.
On the other hand, the warehouse knows how to receive and store inventory, fulfill orders, and assign orders to a truck. Also, the warehouse knows how to interact with the central data center at Acme Online as well as all the trucks stationed at the warehouse. In other words, the warehouse is the Fog layer that acts as the intermediary between the central data center and the edge.
This physical analogy holds true in a digital infrastructure. A high volume edge architecture puts a layer of computing between the edge devices and the cloud to improve the system's performance overall. Implementing a Fog layer between edge devices and the central cloud improves system security as well.
One emerging architectural style is to place the Fog layer of a distributed application intended to consume and process confidential information according to governance rules of the locale in a private cloud. One example is an architecture where a bank's Automated Tellers (ATMs) connect to the institution's private network. In this example, the ATMs are the edge devices, and the bank's private network is the Fog. The Fog handles authentication and verification relevant to simple transactions. However, when more complex analytic computation that requires enormous computing resources is needed, that work is passed off to a public cloud in a secure manner. Typically this type of intense computation is related to machine learning that powers artificial intelligence. In fact, the public cloud/private cloud (Fog)/edge segmentation found in edge architecture is well suited for applications that rely on a robust AI infrastructure.
Let's take a look at the specifics.
AI implementation patterns using edge computing
These days the modern cell phone has made us accustomed to using AI in our day-to-day lives, even if it's behind the scenes. Technologies such as Google Lens have image recognition built right into its Android phones. You can point the phone's camera at a bottle of your favorite brand of ketchup, and the application will go out to the Internet and find the store nearest you where you can buy that ketchup. It's a pretty amazing feat, especially when you consider that the cell phone's evolution is such that it actually has the computing power to do the initial image recognition. It wasn't always that way. In the past, this level of computing could only take place on very powerful computers.
Taking a photo and sending it in an email has been a cell phone feature for a while. As a result, billions of pet photos have become a permanent fixture on the Internet. In the past, a cell phone could take a picture of a dog, but it had no idea that the image was that of a dog. That work needed to be done by more powerful machines that understand what a dog looks like. This process of image identification is called modeling.
The way modeling works is that a computer program is fed a very large number of images that describe a thing of interest, in this case, a dog. The program has the logic to determine a generic pattern that describes the item of interest. In order words, after feeding a program a few million pictures of different dogs, eventually, it determines the common characteristics of dogs and is able to identify one in a random image. This general description is called a model.
It takes a lot of computing power to create a model but less power to use one. Initially, in the world of AI, both defining a model and using one was done in a data center. When it came to figuring out if a photo was that of a dog, a cell phone was nothing more than a dumb terminal, as shown in Figure 5 below.
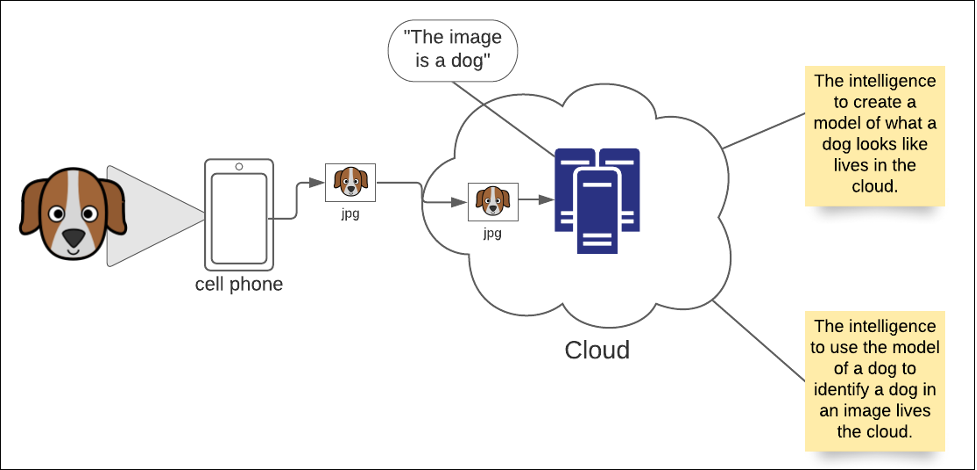
Figure 5: In standard cloud computing, all AI intelligence lives in the cloud
However, as cell phones became more powerful, they developed the capability to use models created in the cloud. Today, cell phones, which are inherently edge devices, download a model of a dog that is then used by intelligence in the cell phone to determine that a digital image is indeed that of a dog. The benefit is that more processing occurs on the edge device. In addition, the edge device does not need to have a continuous connection to the data center in the cloud. If, for some reason, the cell phone goes into an underground tunnel with no connectivity, it can still identify a dog in a photo. (See Figure 6, below)
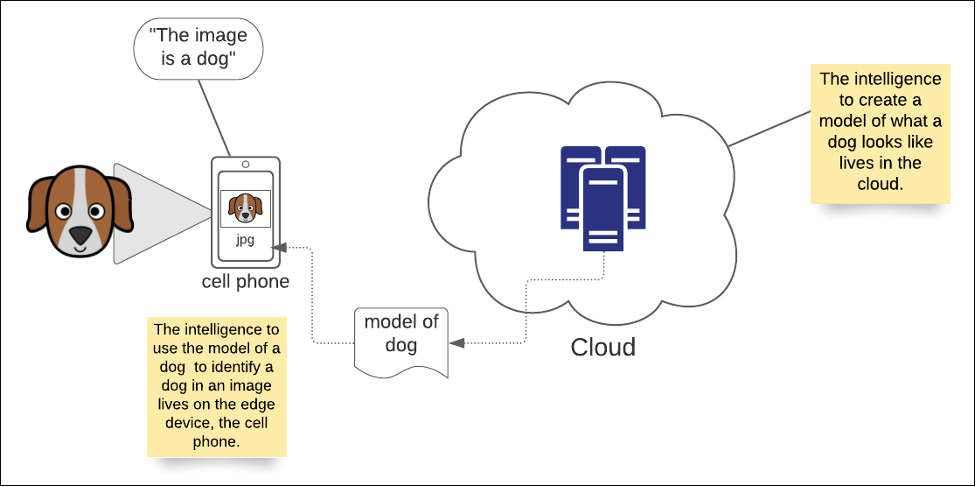
Figure 6: In edge computing, intelligence such as AI models are pushed into the edge device
Intelligent edge computing is relatively easy in devices such as cell phones, which have enough computing power to do various tasks. Things get tricky with devices that aren't as "smart," for example, a red light camera in a municipal traffic system.
Traffic-cams are commonplace these days. They monitor busy intersections and can catch a driver in the act of running a red light. However, for a traffic-cam system to work effectively, it requires more than simply having a video camera monitor an intersection. There not only needs to be coordination between the traffic light and the video camera there also needs to be intelligence available that will allow the system to specifically identify an automotive vehicle from other items at the intersection.
To be effective, a small-scale Fog architecture needs to be in play. The system requires just enough information to determine whether a moving violation occurred, but not so much as to compromise the driver's actual identity nor any subsequent actions in response to the violation.
The edge/Fog/cloud pattern is useful in this situation, as shown in Figure 7 below.

Figure 7: Adding a Fog perimeter to the cloud allows IoT devices to send data to a server in a local area network, which in turn gets processed before submitting to the cloud
In the traffic-cam scenario illustrated above, all the intelligence to determine that a moving violation occurred is stored in the Fog server. The server knows when the traffic light is red, it sees the images of vehicles moving through the restricted zone and thus can determine when a violation has occurred. When a driver runs a red light, it sends only the information relevant to the violation back to the cloud for processing.
Now granted, this is but one of many types of edge architectures that can be used to satisfy this particular use case. I can extend the scenario so that each traffic light and video camera pair connects to a Raspberry Pi device that contains the intelligence to determine a moving violation. The Raspberry Pi then forwards information onto a Fog layer that aggregates all the violation data into a batch submission to the cloud.
Determining the exact edge architecture to use is a matter of use case requirements and budget. The important thing to understand is that segmentation, both in terms of general computing and AI implementation, is an important aspect of edge architecture. There is no "one size fits all" approach. Thus, the modern Enterprise Architect needs to understand the benefits and tradeoffs of various edge computing methods.
Putting it all together
Edge computing will continue to grow in the IT landscape, particularly with the introduction of 5G networking. 5G networking is about network nodes being much closer together and thus reducing latency. This design translates into much faster data transmission rates. For now, most 5G activity will take place on cell phones. As the pattern reveals, technologies suited to general-purpose devices such as cell phones eventually find their way into specialized appliances such as driverless vehicles and mobile machines suited for industrial activity. In other words, robots.
There are many opportunities out there in the world for edge computing. Some people are saying it will be the next great paradigm. As the use of edge computing increases, so will the complexity that goes with it. Hopefully, the concepts and ideas presented in this piece will provide the basic information required to achieve eventual mastery.
About the author
Bob Reselman is a nationally known software developer, system architect, industry analyst, and technical writer/journalist. Over a career that spans 30 years, Bob has worked for companies such as Gateway, Cap Gemini, The Los Angeles Weekly, Edmunds.com and the Academy of Recording Arts and Sciences, to name a few. He has held roles with significant responsibility, including but not limited to, Platform Architect (Consumer) at Gateway, Principal Consultant with Cap Gemini and CTO at the international trade finance company, ItFex.
More like this
Physical AI: When machines start to think and act in the real world
Why Operational Resilience and Digital Sovereignty Top the CIO Agenda
Infrastructure At The Edge | Compiler
Open Curiosity | Command Line Heroes
Browse by channel

Automation
The latest on IT automation for tech, teams, and environments

Artificial intelligence
Updates on the platforms that free customers to run AI workloads anywhere

Open hybrid cloud
Explore how we build a more flexible future with hybrid cloud

Security
The latest on how we reduce risks across environments and technologies

Edge computing
Updates on the platforms that simplify operations at the edge

Infrastructure
The latest on the world’s leading enterprise Linux platform

Applications
Inside our solutions to the toughest application challenges
Virtualization
The future of enterprise virtualization for your workloads on-premise or across clouds