

We work within IBM Services and spend most of our time in the field, working hands-on with our clients on delivering their projects. We have seen the adoption of event-driven and streaming architectures increase to the point where they are fast becoming the standard for use cases that are event-driven or require real-time stream processing.
In our client projects, we have found that in-memory data grids (IMDGs) play an important role in high-throughput and zero-data-loss event-driven architectures. In this article, we will share our view on the role data grids play in event-driven architectures and our lessons learned.
We continue to evolve this architecture as our clients add use cases to leverage the platform further and make it an integral part of their solutions.
What are in-memory data grids?
"The goal of [IMDGs] is to provide extremely high availability of data by keeping it in memory and in highly distributed (i.e., parallelized) fashion. By loading terabytes of data into memory, IMDGs are able to work with most of the big data processing requirements today."
Nikia's blog and GridGrain's IMDG white paper are good resources on IMDGs, so we won't duplicate them. Instead, we'll focus on their key characteristics:
- An IMDG has a data store where you can store objects.
- The data is stored in memory.
- The data is partitioned across the nodes of a cluster.
- Nodes can be added easily to add more memory to the grid.
With that context, we'll dig deeper into why IMDGs are important.
Why are IMDGs important?
Rapid advances in digital, social, and Internet of Things (IoT) capabilities are giving rise to innovative business applications. They are also fueling exponential growth in data volumes. Modern systems process millions of events and generate massive amounts of data. Organizations are also exposing their business functionality as APIs with stringent response times and larger throughput service-level agreements (SLAs). These modern applications and services require high-speed access to data to ensure engaging user experiences and meeting throughput and response time SLAs.
These application scenarios may put this in context:
- Trade processing applications: These applications have massive throughput requirements, and each trade-related event must be processed in the context of its history, investor profile, and financial position. At the same time, business operations users must have a real-time, aggregated view of key risk and financial metrics across geographies, clients, and types of securities.
- Payment processing systems: These also have massive throughput requirements. Each payment must be correlated to the previous transaction history, the customer's financial position, and regulatory checks, which might span multiple transactions.
- Online commerce applications: These applications require fast access to product catalogs to manage customers' shopping carts, make recommendations based on items in the shopping cart and other factors, adjust search results based on the user's past browsing and buying behavior, and other criteria.
- Open banking: In a typical open banking scenario, a bank exposes an API to provide a customer's account balance and other details. Third-party application developers then leverage this API to build rich mobile applications. This results in an exponential rise in the number of account-data queries.
Building these applications with traditional databases would involve substantial engineering complexities, especially those related to meeting non-functional requirements including response time and throughput.
IMDGs can create a fast data layer that will help with looking up data, storing states, and storing and maintaining business and operational metrics. They can also be used as a primary data store and then use its write-behind capability to write the data into back-end databases.
Populating IMDGs is not expensive in terms of performance and effort. It can be done concurrently and using established architectural patterns such as pub-sub (publish-subscribe) and change data capture (CDC).
A typical usage pattern that we have observed with IMDG and event-driven architecture is depicted below:
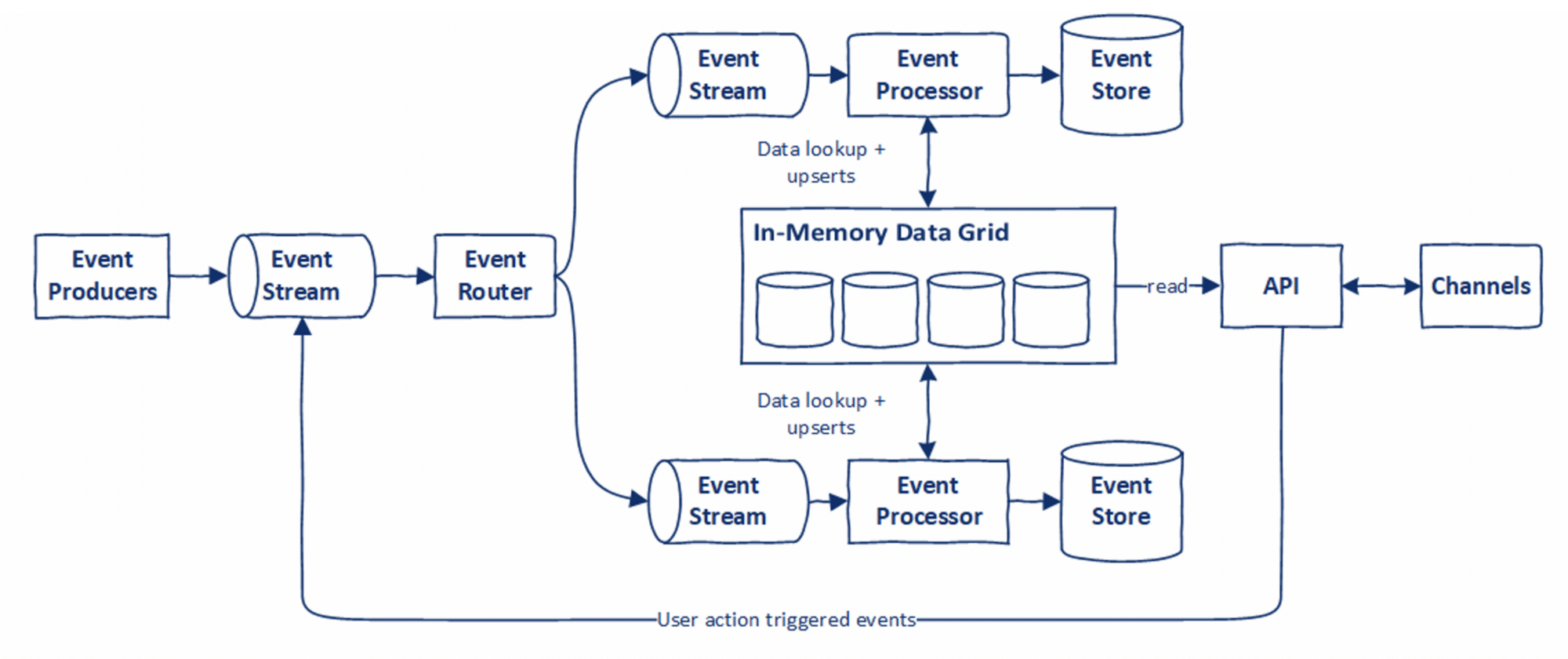
Some of the characteristics of IMDGs that we like a lot are:
- Fast and highly concurrent access to data
- Help reduce the load on systems of record
- Distributed and fault-tolerant nature
- Easy to scale as data volumes increase
- Support for cloud-based architectures
- Ease of setup and deployment
- Some (such as Apache Ignite) provide an ANSI-99 SQL-compliant interface with JDBC and ODBC drivers
- They are also rapidly becoming cost-effective as memory costs come down.
Where can you use IMDGs?
The following are four of the ways we think using an IMDG is beneficial.
1. Supporting high-performance computing
High-performance computing (HPC) is about aggregating compute and memory resources from multiple (commodity) servers to deliver higher performance and concurrency compared to a standalone server. The key principle is divide and conquer (MapReduce). That is, dividing the data and compute tasks into smaller segments, distributing them for parallel processing to different servers in the grid, and aggregating the results of these smaller segments to compute the outcome.
As data keeps growing at exponential speed, partitioning data and enabling distributed querying capabilities to provide high throughput are key to HPC. IMDGs are an essential building block for HPC. IMDGs use data partitioning to distribute data across multiple server nodes in the cluster. They also split and distribute queries across the cluster. This means the IMDG's performance can scale up to meet high throughput requirements.
Additionally, IMDG platforms (such as Apache Ignite) also provide distributed compute capability. This means the same nodes of their cluster can be used to schedule and execute concurrent compute tasks. They also provide "data and compute colocation," or running the distributed compute subtasks on the nodes. This also holds the data required by those subtasks, eliminating network latency and providing higher performance.
2. Acting as "query" in CQRS
In a typical application, there is a significant skew between read and write workloads. The "reads" outnumber the "writes" significantly. For example, a bank customer makes fewer payments compared to the number of times they check their account balance. Command Query Responsibility Segregation (CQRS) provides segregation of read and write workloads, thus ensuring write performance is not impacted adversely due to large volumes of reads.
We have seen these characteristics while working on projects with our clients:
- Reads are used more for recent data than older data.
- The user interface (UI) requires data to be represented in a different way from the underlying data model, typically showing an aggregation across multiple entities.
- Real-time aggregations need to be built for display on dashboards.
- Response time requirements for reads are aggressive.
- Read workload increases significantly during marketing initiatives and global political and market-related events.
IMDGs make sense for implementing the read part of CQRS for systems displaying the above characteristics because:
- It is easy to populate these grids in event-driven and stream processing applications. These data streams provide a mechanism to transform and enrich the data, which is aligned more to consumption requirements.
- Most IMDGs support different eviction policies.
- They offer faster performance and higher concurrency (through partitioning and appropriate colocation strategies) compared to traditional databases.
- Scaling is an important characteristic. IMDGs are inherently distributed in nature and can be scaled horizontally easily.
- IMDGs also support replication, thus making them more resilient to failure.
[ Learn more about event-driven architectures for a hybrid cloud blueprint. ]
3. Decoupling reporting workloads from systems of record
Once an IMDG is populated, it can be used to service reporting workloads. This would be particularly useful in cases where reports are generated directly from systems of record instead of from a data warehouse or data lake. However, this would require the IMDG to provide a connector interface that is compatible with the reporting tool. Apache Ignite provides ANSI-99 SQL-compliance and JDBC/ODBC drivers, which most of the reporting tools support. By leveraging the IMDG for reporting, you can reduce a significant amount of reporting workload from the systems of record.
There are a few things that need to be taken into account:
- If using the SQL interface (JDBC, ODBC drivers): a) queries need to be optimized for performance, b) proper indexes have to be created, c) you must try to store data in a denormalized form to avoid joins, d) if joins are unavoidable, try to ensure data being joined is collocated.
- The IMDG needs to be tuned to support concurrent online and reporting workloads. This could involve segregating the workloads using different thread pools and having a proper throttling mechanism in place.
- The IMDG can lose its data in case of a cluster-wide failure, and if the data is not backed up in a persistent store, the data needs to be recovered as part of recovery before reports can be generated.
4. Doing real-time analytics
Many metrics and insights need to be generated in near-real time. This is especially important for systems analyzing risk and detecting deviant behavior (fraud detection, anomaly detection, and in IoT-based systems). Some sample use cases are:
- Business dashboards that show metrics related to business key performance indicators (KPIs) or SLA aggregated across different dimensions
- Risk-assessment applications
- Pattern and anomaly detection applications, such as fraud detection, high-value payment processing, predicting failure, and more
- Machine learning inferencing, especially for models that require a large volume of near-real-time data
This entails:
- Correlating different types of events
- Aggregating events and data
- Running algorithms to identify patterns
- Fast access to near-real-time data to feed into machine-learning models
The key challenge in these use cases is to perform at scale and speed. Fast access to data is required. State needs to be maintained and continuously updated. Multiple datasets need to be joined to correlate events and identify patterns. All of this has to be done within stringent response time requirements and at scale. To add to the complexity, the data volume is continuously growing.
IMDGs are very helpful here. Using them, you can build a fast data layer to maintain state, history, and aggregated metrics. In event-driven and stream processing-based systems, the stream data-processing pipelines can populate the grid and publish aggregated metrics in near-real time. Event processors then reference the data in IMDGs as part of their execution instead of querying databases or making service calls to systems of record. Another advantage of IMDGs is their scalability. As data volumes grow, they can be easily scaled.
IMDGs such as Apache Ignite provide compute APIs that enable running compute tasks directly on the data nodes with MapReduce capability. They support the colocation of compute tasks and data. This means compute tasks are executed on the node where the relevant data resides, thus reducing network traffic and improving performance. This feature can be used to create compute tasks for data aggregation.
Note: If you are using an event streaming platform like Kafka, consider using the Kafka Streams API for real-time analytics and event correlation. This is an option you should evaluate for your particular use case or scenario. Results from Kafka Streams processors can be published to IMDGs for fast access.
[ Read the analyst paper Event-driven applications with Red Hat AMQ Streams for more on how you can leverage Apache Kafka's power. ]
What are typical challenges in IMDG implementation projects?
IMDGs are extremely beneficial for providing fast data access and reducing the load on traditional systems of record. However, there are certain challenges pertaining to their use that need to be considered as part of the design.
Without the persistence of in-memory data, there is a risk of data loss in IMDG cluster-wide failure: This can be addressed to a certain extent by having a cross-data center cluster setup and ensuring replicas are maintained across data centers. A more reliable solution is to have persistence enabled for the IMDG. However, persistence has performance and storage costs. Persistence can either be on a disk (for example, native persistence, in the case of Apache Ignite) or in a third-party database such as Cassandra or a relational database management system. IMDGs provide a "write-behind" pattern for persistence to improve performance. However, performance issues manifest when there are big bursts of inserts or updates happening on the IMDG.
Recovering from a cluster-wide crash: When the IMDG cluster crashes, data is lost. If this data is backed up on persistent storage, then it must be reloaded before allowing applications to access it. Having optimal recovery time is extremely important to ensure minimum disruption. Recovery time is proportional to the data volume and number of threads involved in recovery. If you are dealing with a large amount of data, it is highly advisable to test recovery scenarios as part of the development and tune the IMDG and the infrastructure to optimize recovery time.
Memory is still not cheap, and setting up an IMDG has cost implications: Increasing the cluster size as data volumes grow comes at a cost. It is prudent to set up limits on how many days' worth of data needs to be available in the IMDG. This decision needs to be made while taking into consideration the pattern and volume of queries being made on the IMDG.
The IMDG is an additional set of components in the architecture to manage and maintain: This adds maintenance and operating costs. IT management teams need to be enabled to manage and maintain these additional components. Development teams need to be educated on using an IMDG, especially on the differences between a database and an IMDG. We have noticed direct comparisons of IMDG with traditional databases. This should be avoided. Both have their own strengths and serve different purposes.
Lessons learned
Here are some of the many lessons we have learned in our client projects that leveraged an IMDG:
- Data replication and rebalancing are very important for IMDGs because, without them, even a single node failure can make the grid inconsistent.
- Automation of basic admin activities (such as start/stop) on the IMDG is important, especially when there are a large number of nodes in the cluster.
- You need to create monitoring dashboards and alerts for key IMDG metrics if out-of-the-box capabilities do not exist.
- Design data recovery mechanisms during the initial stages of development. Don't leave them for the last moment. Test the mechanisms with production-like volumes to benchmark data recovery times.
- Performance testing is important, especially in scenarios that result in massive bursts in insert and update rates, and it's even more critical when using persistence.
- Decide how much data you want to retain in the IMDG. Scaling the nodes is easy but costs money.
- Rolling upgrades of IMDG nodes is a must-have feature. Without rolling upgrade capability, every version upgrade would require you to restart the cluster, and data recovery would be necessary.
- A considerable amount of time needs to be spent optimizing and tuning the IMDG setup. This time needs to be factored into the overall project planning. Don't take it lightly.
- IMDGs have a long list of configuration options. You will need to make a lot of decisions related to IMDG configuration. Make sure they are well documented.
- It is important to educate development teams on the differences between a database and an IMDG, especially when using a SQL-compliant IMDG such as Apache Ignite. Relational databases support very advanced and complex SQLs that may not behave efficiently on an IMDG. Another aspect is data collocation, which is important to understand while creating data caches and designing queries that join multiple caches.
This article originally appeared on Medium and is republished with permission.
About the authors
Tanmay is an IT architect and technology leader with hands-on experience in delivering first-of-a-kind solutions on emerging technologies. With over 21 years of experience, he has a consistent track record of delivering multiple complex and strategic technology transformation programs for clients in banking and financial markets and telecom. His core areas of expertise include digital transformation, cloud-native development, cloud-based modernization, microservices, and event-driven architectures. He is known for developing IT architectures, performance engineering, troubled project recovery, and hands-on technology leadership during implementation.
Shahir A. Daya is an IBM Distinguished Engineer and Business Transformation Services Chief Architect in IBM Consulting in Canada, where he is responsible for overall solution design and technical feasibility for client transformation programs. He is an IBM Senior Certified Architect and an Open Group Distinguished Chief/Lead IT Architect with more than twenty-five years at IBM. Shahir has received the prestigious IBM Corporate Award for exceptional technical accomplishments. He has experience with complex high-volume transactional applications and systems integration. Shahir has led teams of practitioners to help IBM and its clients with application architecture for several years. His industry experience includes banking, financial services, and travel & transportation. Shahir focuses on cloud-native architecture and modern SW engineering practices for high performing development teams.
He has supported the design and stand-up of several joint clients and IBM delivery centers adopting modern SW engineering practices to deliver modernization programs. Shahir is also responsible for defining the sectors' technical strategy relating to asset development/harvesting, new technical areas of focus, and thought leadership for the specific technology area. He provides technical oversight and direction on critical projects.
Shahir holds a B.A.Sc. in Computer Engineering from the University of Toronto and has co-authored 3 IBM Redbooks on Microservices and Hybrid Cloud Integration. He is an inventor with several issued U.S. Patents. Shahir is a member of the Institute of Electrical and Electronics Engineers (IEEE) and the Association for Computing Machinery (ACM). Shahir is an active mentor in the University of Toronto Engineering Alumni Mentorship Program and the University of Toronto Women in Science and Engineering (WISE) Mentorship Program. He is also a coach for the FIRST LEGO Robotics Jr. League.
You can follow Shahir on Twitter and Medium.
More like this
Debunking IT automation myths: A strategic blueprint for healthcare payers
Introducing Red Hat build of Karpenter
Untangling Networks | Compiler
Operating System Management | Compiler
Browse by channel

Automation
The latest on IT automation for tech, teams, and environments

Artificial intelligence
Updates on the platforms that free customers to run AI workloads anywhere

Open hybrid cloud
Explore how we build a more flexible future with hybrid cloud

Security
The latest on how we reduce risks across environments and technologies

Edge computing
Updates on the platforms that simplify operations at the edge

Infrastructure
The latest on the world’s leading enterprise Linux platform

Applications
Inside our solutions to the toughest application challenges
Virtualization
The future of enterprise virtualization for your workloads on-premise or across clouds