
Making applications that run at web-scale is hard work. Risks are everywhere—everything from having an application stop dead in its tracks due to network overload to having a competitor take your market share because it's getting more code to demanding users faster than you can. Any advantage you can muster to create working code better and faster at web-scale is to your benefit.
[ You might also be interested in reading 12 Factor App meets Kubernetes: Benefits for cloud-native apps. ]
Fortunately, the problems of operating at web-scale are well-known. There are solutions. One of them is The 12 Factor App, published in 2011 by Adam Wiggins. The 12 Factor App is a set of principles that describes a way of making software that, when followed, enables companies to create code that can be released reliably, scaled quickly, and maintained in a consistent and predictable manner.
The following is a brief synopsis of the principles of The 12 Factor App.
I. Codebase
One codebase tracked in revision control, many deploys
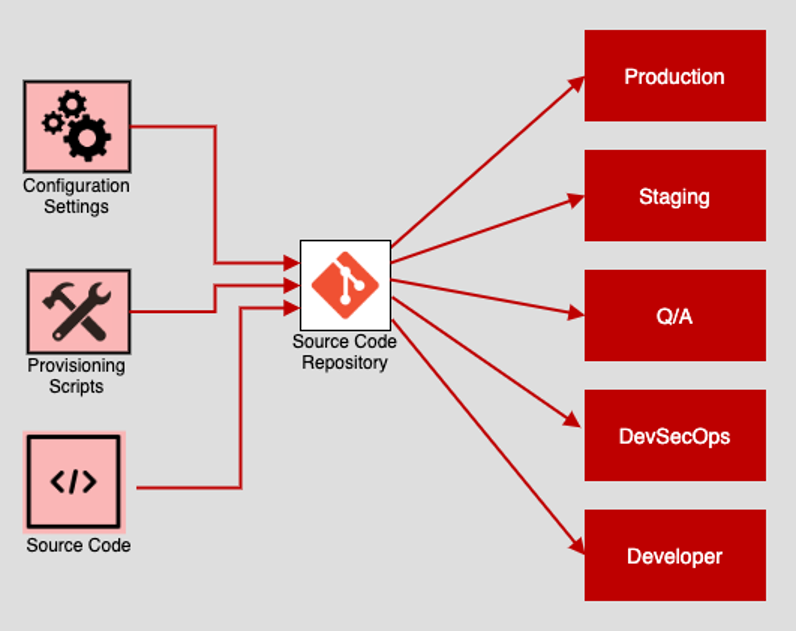
The Codebase principle states that all assets related to an application, everything from source code, the provisioning script, and configuration settings, are stored in a source code repository that is accessible to development, testing, and system administration staff. The source code repository is also accessible to all automation scripts that are part of the Continuous Integration/Continuous Delivery (CI/CD) processes that are part of the enterprise's Software Development Lifecycle. (SDLC).
[ Learn how IT modernization can help alleviate technical debt. ]
II. Dependencies
Explicitly declare and isolate dependencies
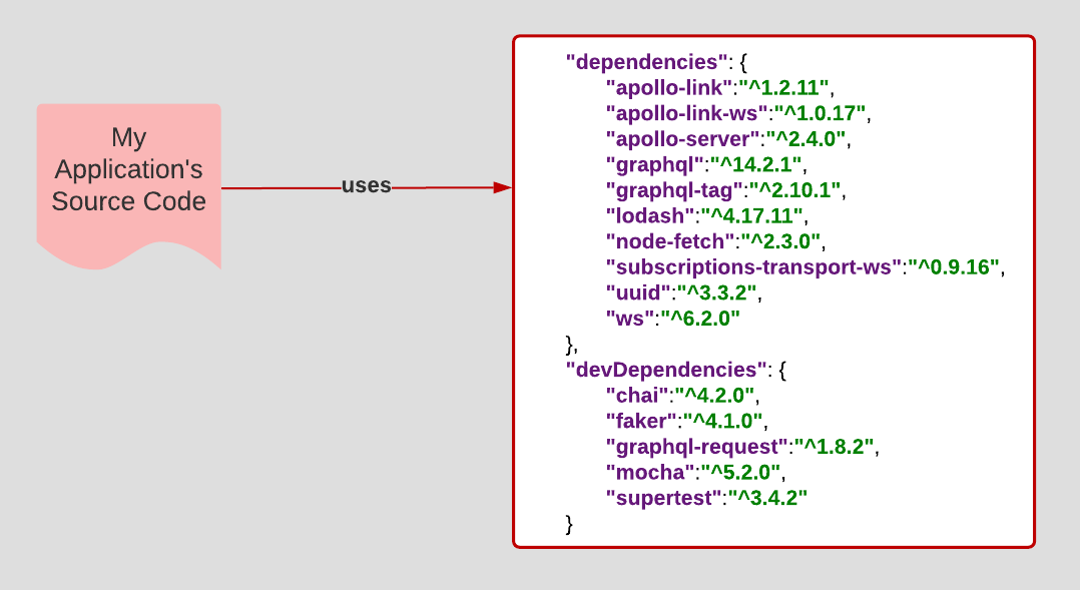
The principle of Dependencies asserts that only code that is unique and relevant to the purpose of the application is stored in source control. External artifacts such as Node.js packages, Java .jar files, or .NET DLLs should be referenced in a dependencies manifest loaded into memory at development, testing, and production runtime. You want to avoid storing artifacts along with source code in the source code repository.
III. Config
Store config in the environment

The Config principle states that configuration information is injected into the runtime environment as environment variables or as settings defined in an independent configuration file. While, in certain cases, it's permissible to store default settings that can be overridden directly in code, settings such as port number, dependency URLs, and state settings such as DEBUG should exist separately and be applied upon deployment. Good examples of external configuration files are a Java properties file, a Kubernetes manifest file, or a docker-compose.yml file.
The benefit of keeping configuration settings separate from application logic is that you can apply configuration settings according to the deployment path. For example, you can have one set of configuration settings for a deployment intended for a testing environment and a different set for a deployment designed for a production environment.
[ Learn four focus areas to maintain momentum on digital transformation. ]
IV. Backing Services
Treat backing services as attached resources
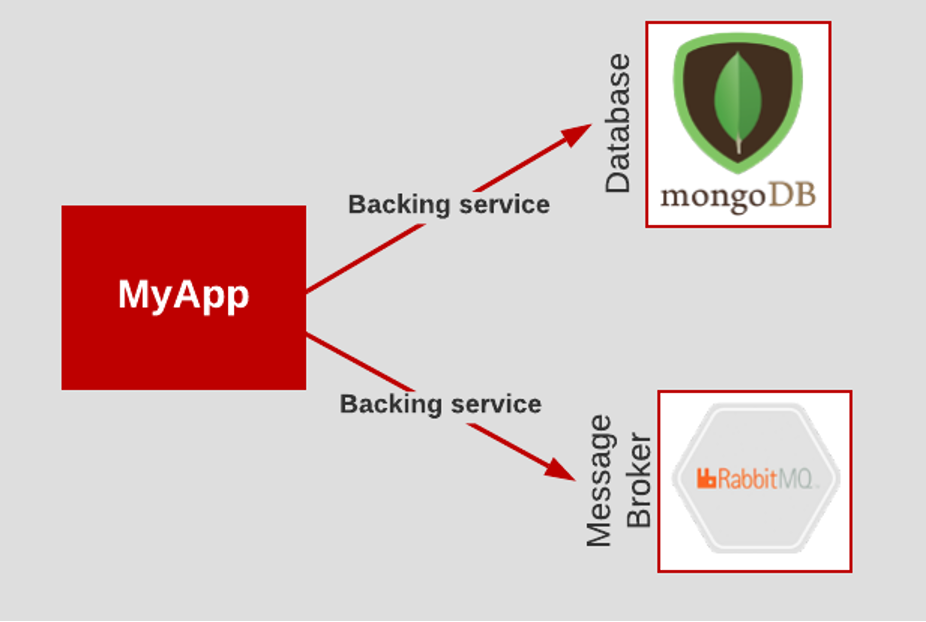
The Backing Services principle encourages architects to treat external components such as databases, email servers, message brokers, and independent services that can be provisioned and maintained by systems personnel as attached resources. Treating resources as backing services promotes flexibility and efficiency in the software development lifecycle (SDLC).
V. Build, Release, Run
Strictly separate build and run stages

The principle of Build, Release, and Run breaks the deployment process down into three replicable stages that can be instantiated at any time. The Build stage is where code is retrieved from the source code management system and built/compiled into artifacts stored in an artifact repository such as Docker Hub or a Maven repository. After the code is built, configuration settings are applied in the Release stage. Then, in the Run stage, a runtime environment is provisioned via scripts using a tool such as Ansible. The application and its dependencies are deployed into the newly provisioned runtime environment.
The key to Build, Release, and Run is that the process is completely ephemeral. Should anything in the pipeline be destroyed, all artifacts and environments can be reconstituted from scratch using assets stored in the source code repository.
VI. Processes
Execute the app as one or more stateless processes

The principle of Processes, which can be more accurately termed stateless processes, asserts that an application developed under The 12 Factor App structure will run as a collection of stateless processes. This means that no single process keeps track of the state of another process and that no process keeps track of information such as session or workflow status. A stateless process makes scaling easier. When a process is stateless, instances can be added and removed to address a particular load burden at a given point in time. Since each process operates independently, statelessness prevents unintended side effects.
VII. Port Binding
Export services via port binding
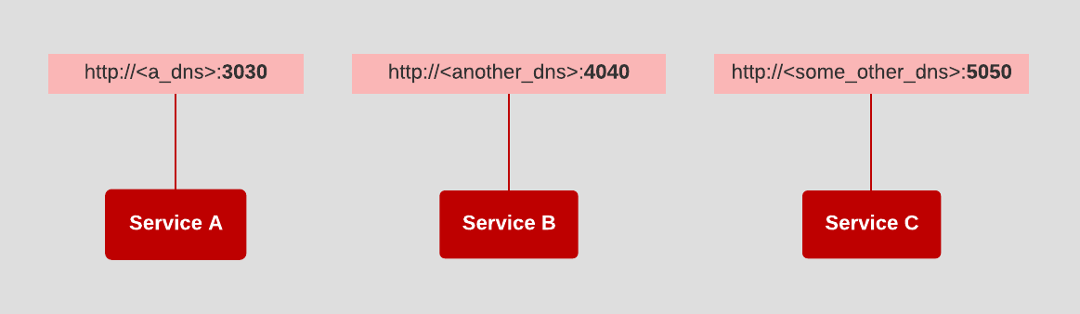
The principle of Port Binding asserts that a service or application is identifiable to the network by port number, not a domain name. The reasoning is that domain names and associated IP addresses can be assigned on-the-fly by manual manipulation and automated service discovery mechanisms. Thus, using them as a point of reference is unreliable. However, exposing a service or application to the network according to port number is more reliable and easier to manage. At the least, potential issues due to a collision between port number assignment private to the network and public use of that same port number by another process publicly can be avoided using port forwarding.
The essential idea behind the principle of port binding is that the uniform use of a port number is the best way to expose a process to the network. For example, the patterns have emerged in which port 80 is conventional for web servers running under HTTP, port 443 is the default port number for HTTPS, port 22 is for SSH, port 3306 is the default port for MySQL, and port 27017 is the default port for MongoDB.
VIII. Concurrency
Scale-out via the process mode

The principle of Concurrency recommends organizing processes according to their purpose and then separating those processes so that they can be scaled up and down according to need. As shown in the illustration above, an application is exposed to the network via web servers that operate behind a load balancer. The group of web servers behind the load balancer, in turn, uses business logic that is in Business Service processes that operate behind their own load balancer. Should the burden on the web servers increase, that group can be scaled up in an isolated manner to meet the demands at hand. However, should a bottleneck occur due to a burden placed on the Business Service, that layer can be scaled up independently.
Supporting concurrency means that different parts of an application can be scaled up to meet the need at hand. Otherwise, when concurrency is not supported, architectures have little choice but to scale up the application in its entirety.
[ Free guide: How to explain DevOps in plain English. ]
IX. Disposability
Maximize robustness with fast startup and graceful shutdown
const shutdown = async (signal) => {
logger.info(`Disconnecting message broker at ${new Date()}`);
messageBroker.disconnect();
logger.info(`Disconnecting database at ${new Date()}`);
database.disconnect();
let shutdownMessage;
if (!signal) {
shutdownMessage = (`MyCool service shutting down at ${new Date()}`);
} else {
shutdownMessage = (`Signal ${signal} : MyCool service shutting down at ${new Date()}`);
}
const obj = {status: "SHUTDOWN", shutdownMessage, pid: process.pid};
await server.close(() => {
console.log(obj);
process.exit(0);
});
};
The principle of Disposability asserts that applications should start and stop gracefully. This means doing all the required "housekeeping" before an application is made accessible to consumers. For example, a graceful startup will ensure that all database connections and access to other network resources are operational. Also, any other configuration work that needs to take place has taken place.
In terms of shutdown, disposability advocates ensuring that all database connections and other network resources are terminated properly and that all shutdown activity is logged, as shown in the code example shown above.
X. Dev/Prod Parity
Keep development, staging, and production as similar as possible
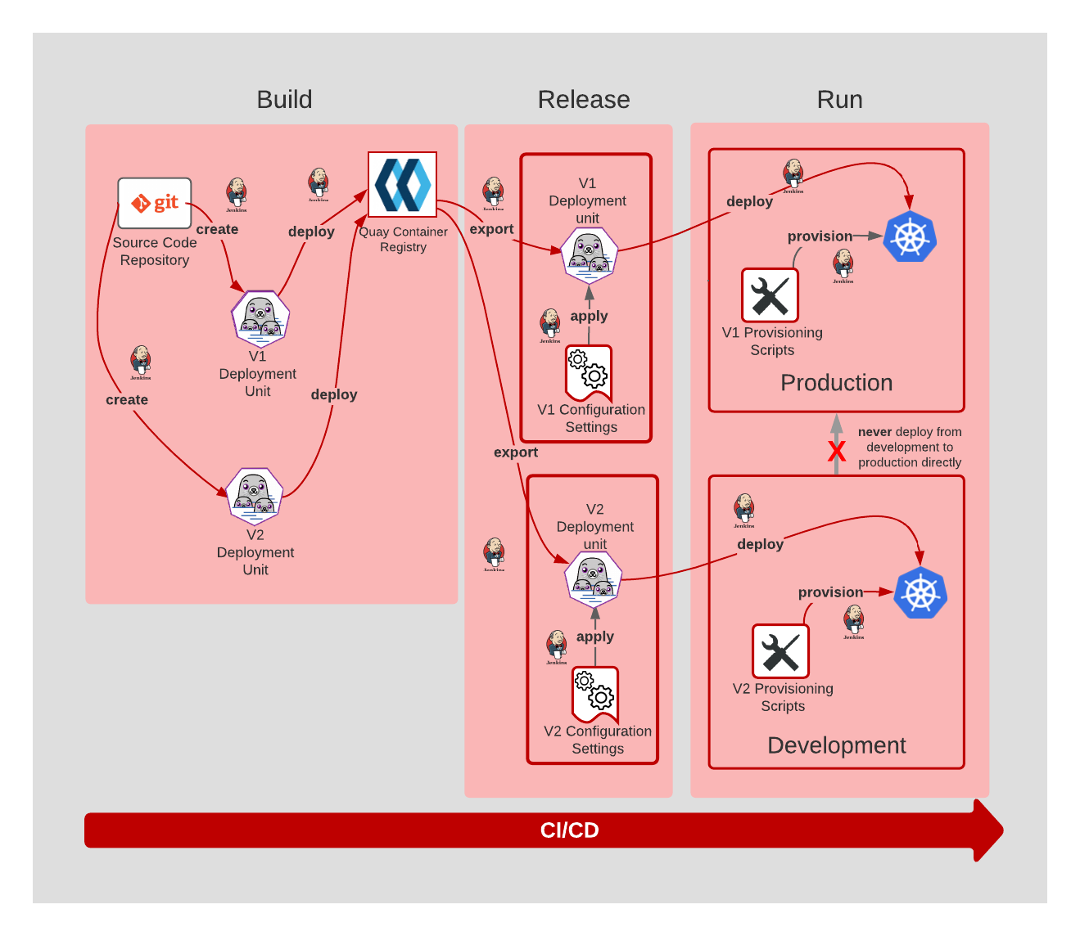
The Dev/Prod Parity principle means all deployment paths are similar yet independent and that no deployment "leapfrogs" into another deployment target.
The figure above shows two versions of an application's code. The V1 version is targeted for release to the Production environment. A new version, V2, is targeted for a Development environment. Both V1 and V2 follow a similar deployment path, from Build to Release and then Run. Should the V2 version of the code be deemed ready for Production, the artifacts and settings relevant to V2 will NOT be copied into the Production environment.
Rather, the CI/CD process will be adjusted to set the deployment target of V2 to Production. The CI/CD process will follow the expected Build, Release, and Run pattern towards that new target.
As you can see, Dev/Prod Parity is very similar to Build, Release, and Run. The important distinction is that Dev/Prod Parity ensures the same deployment process for Production as it does Development.
XI. Logs
Treat logs as event streams
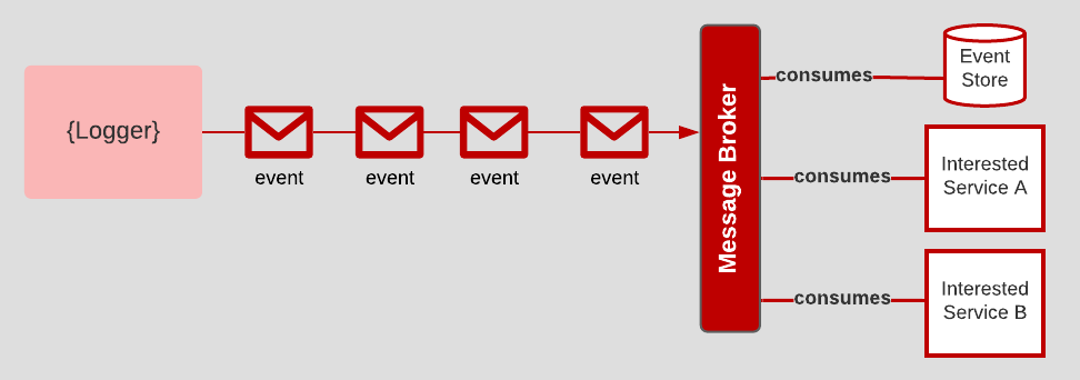
The Logs principle advocates sending log data in a stream that a variety of interested consumers can access. The process for routing log data needs to be separate from processing log data. For example, one consumer might only be interested in Error data, while another consumer might be interested in Request/Response data. Another consumer might be interested in storing all log data for event archiving. An added benefit is that even if an app dies, the log data lives on well afterward.
XII. Admin Processes
Run admin/management tasks as one-off processes
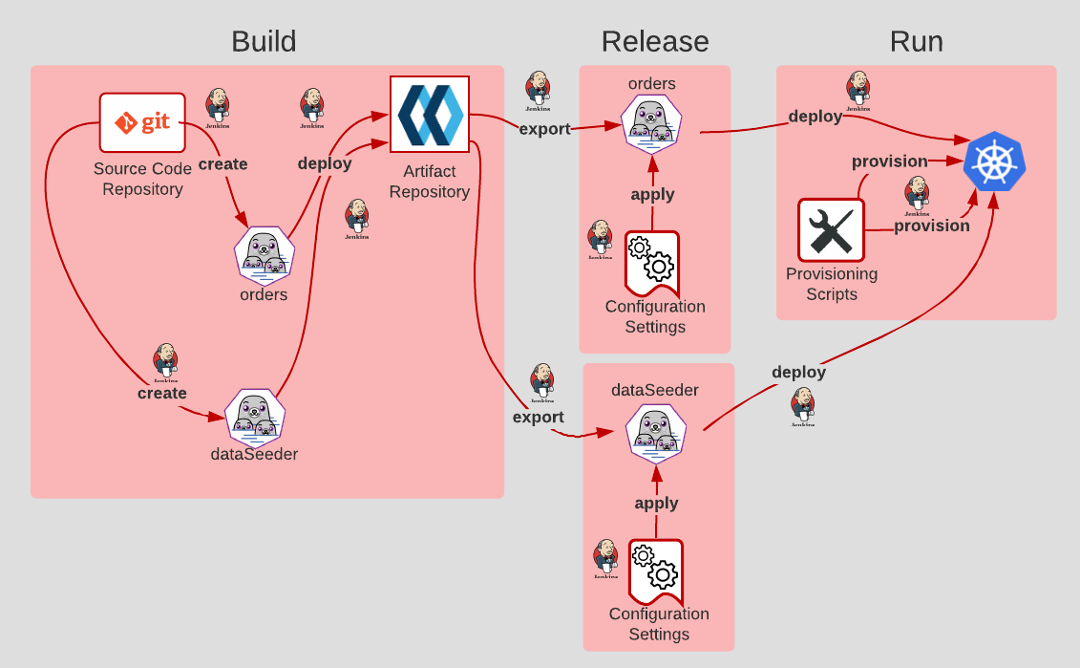
The principle of Admin Processes states that admin processes are first-class citizens in the software development lifecycle and need to be treated as such. The illustration above shows a service named Orders that is deployed as a Docker container. Also, there is an admin service name dataSeeder, which can seed data into the Orders service. The service, dataSeeder, is an admin process that is intended to be used with Orders, as shown in the diagram below.

However, even though dataSeeder is an admin process, it is given a Build, Release, and Run deployment path similar to the Orders service. Also, it is released according to the principles of Codebase and Dev/Prod Parity. The admin process, dataSeeder, is not separate from the overall SDLC, but rather part of it.
Putting it all together
The 12 Factor App principles are designed to allow developers to create applications intended to run at web-scale. They can seem overwhelming at first, and in many ways, they are. Having to rethink the very nature of how you make software can be a daunting task.
Fortunately, implementing the principles of The 12 Factor App is not an all or nothing deal. You can take them in small digestible chunks, starting with the first one and then progressing through the remaining. The trick is to commit to following the principles and then taking that first step.
Many companies have found value in adopting the principles and practices that drive The 12 Factor App. They've done the heavy lifting. They've seen the light. If The 12 Factor App works for them, the principles can work for you too. As mentioned above, all you need to do is take the first step.
About the author
Bob Reselman is a nationally known software developer, system architect, industry analyst, and technical writer/journalist. Over a career that spans 30 years, Bob has worked for companies such as Gateway, Cap Gemini, The Los Angeles Weekly, Edmunds.com and the Academy of Recording Arts and Sciences, to name a few. He has held roles with significant responsibility, including but not limited to, Platform Architect (Consumer) at Gateway, Principal Consultant with Cap Gemini and CTO at the international trade finance company, ItFex.
More like this
Meet the latest Red Hat OpenShift Superheroes
Bringing H.E.A.R.T. to the Red Hat Customer Experience
Container Roundup | Compiler
Untangling Networks | Compiler
Browse by channel

Automation
The latest on IT automation for tech, teams, and environments

Artificial intelligence
Updates on the platforms that free customers to run AI workloads anywhere

Open hybrid cloud
Explore how we build a more flexible future with hybrid cloud

Security
The latest on how we reduce risks across environments and technologies

Edge computing
Updates on the platforms that simplify operations at the edge

Infrastructure
The latest on the world’s leading enterprise Linux platform

Applications
Inside our solutions to the toughest application challenges
Virtualization
The future of enterprise virtualization for your workloads on-premise or across clouds